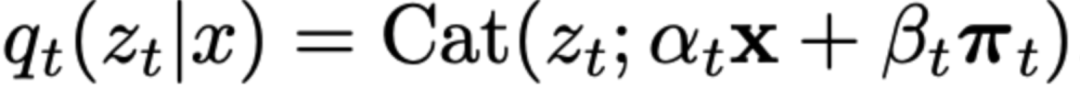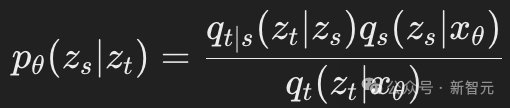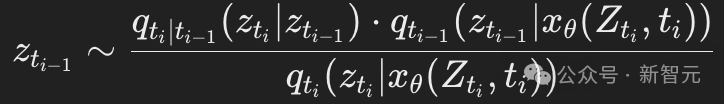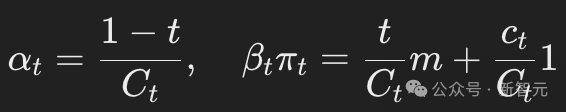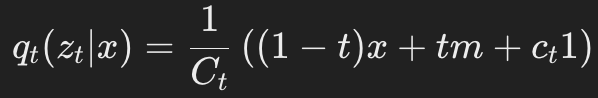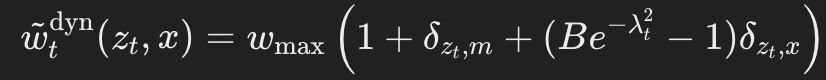【新智元导读】Diffusion模型,学会了自我纠正!无需强化学习等后训练,扩散在语言建模中实现了自我纠错,达到了计算效率匹配的最优性能,找到了证据下界(ELBO)的理论上的闭式解,在实验中将样本质量最高提升了55%。
如果大语言模型(LLMs)能够发现并纠正自己的错误,那岂不是很好?
而且,如果能够直接从预训练中实现这一点,而无需任何监督微调(SFT)或强化学习(RL),那会怎样呢?
最新提出的离散扩散模型,称为GIDD,它能够做到这一点。
在语言建模中,GIDD实现了计算效率匹配的最优性能!
无条件生成与自我纠错算法的比较
来自苏黎世联邦理工学院ETH Zurich等组织的研究团队,推广了掩码扩散(masked diffusion),并推导出一系列广义插值离散扩散模型(general interpolating discrete diffusion,GIDD)的理论基础。
GIDD不仅更灵活,而且在理论上得到了证据下界(evidence lower bound,ELBO)的闭式解。
实验结果表明:GIDD样本质量(生成困惑度,PPL)最高可提升55%。
1、推广性强:GIDD适用于多种扩散过程,不局限于掩码扩散。
2、混合扩散训练:训练了一个结合掩码(masking)和均匀噪声(uniform noise)的混合扩散模型。
3、双重能力:不仅可以填补空缺(填充被掩盖的token),还可以评估已填充token的正确性,并在必要时用更合理的 token替换错误的部分。
论文链接:https://www.arxiv.org/abs/2503.04482
项目地址:https://github.com/dvruette/gidd/
预测下一个token,虽然成果显著,但存在固有的局限性,例如无法修改已经生成的token。
这促使研究者探索替代方法,如离散扩散。
然而,由于简单性和有效性,掩码扩散(masked diffusion)成为流行选择,但重新引入了无法修改token的这种局限性。
基于对扩散模型添加噪声的重要性认识,新研究旨在探索离散扩散模型的设计空间,并尝试不同的扩散过程。
广义插值离散扩散(GIDD)是新的离散扩散方法,将掩码扩散推广到任意插值噪声过程。
在扩散过程中,GIDD可以在任何时刻灵活地选择添加不种类型的噪声。
有趣的是,任何边际分布符合上述方程的扩散过程,都可以推导出证据下界(ELBO)。
只需将 πt设为 one_hot([MASK]),然后在GIDD的ELBO上进行训练即可。
不幸的是,掩码扩散无法进行自我纠正。就像自回归模型一样,一旦token被确定,就无法再更改。
因此,如果模型在某个步骤出错,就没有办法进行修正。
为了解决这个问题,从BERT中汲取了灵感:如果除了掩码token外,随机用其他token替换一部分token,会怎么样?
这样,模型不仅需要学会「填空」,还要学会识别并修正错误的token。
由于GIDD的ELBO具有高度的灵活性,只需选择合适的 πt来捕捉所需的动态特性。
设定 πt使得均匀噪声的比例随着噪声水平的变化而上升或下降,并在 t=0.5时达到峰值。
第一次实验结果有些让人失望,因为使用均匀噪声训练的模型,其困惑度比仅使用掩码的模型要差。
但考虑到这些模型除了需要填补缺失的token外,还要修正错误的token,这并不令人感到意外。
下图发现发现生成性PPL(使用Gemma-2-9b测量)有了显著的改进,特别是对于使用均匀噪声训练的模型来说更是如此,尤其是在推理预算紧张的情况下!
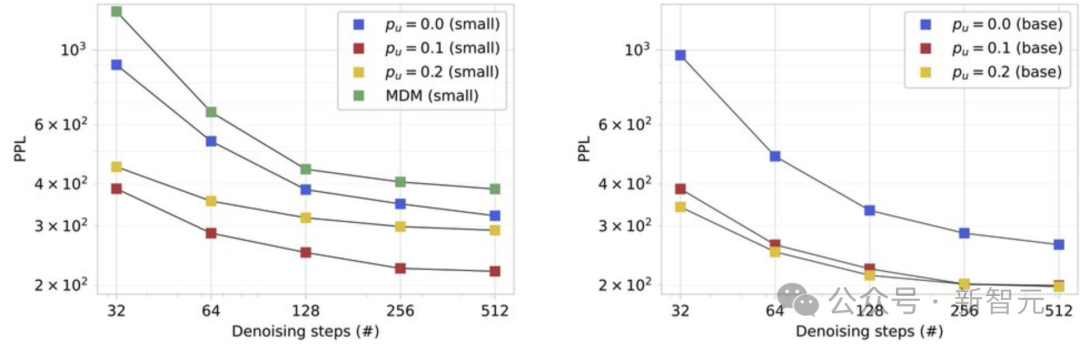
为了弄清楚这一点,提出了一种自我纠正算法,通过一次修复一个token(使用模型)来改进已经生成的样本,直到收敛到一个稳定点。
这样可以不断提高样本质量(以生成PPL衡量),甚至超越仅仅通过增加去噪预算所能达到的水平,提供了一种简单的方法来扩展测试时计算资源!
值得注意的是,仅在去掩码任务上训练的模型不具备这种能力。
在理论和实践上,新研究的主要贡献包括以下两方面:
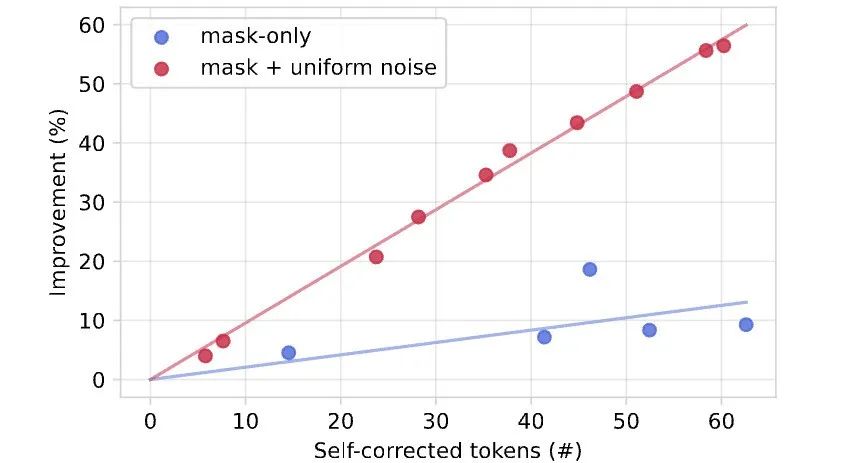
图1.在训练过程中,使用GIDD结合掩码和均匀噪声,可以让扩散模型学会识别并纠正自身错误。

表1.使用20%均匀噪声训练的GIDD+BASE模型进行自我纠正的例子(绿色替换红色)。
GIDD模型能够在未明确训练的情况下纠正语法错误、改进词汇选择,甚至提升事实准确性。
从观察中提取世界的结构是智能的基本机制。
生物体可以自然而然地做到这一点,而机器在这方面的能力直到最近才取得重大突破。
顾名思义,生成模型生成新的、逼真的样本,其中「逼真」通常指的是样本在某个参考分布下具有较高的概率。
对于某些数据分布(例如自然图像或自然语言),单个样本所包含的信息量可能非常庞大。
为了降低生成模型的计算负担,一种常见策略是将生成单个样本的任务拆分为多个推理步骤。
每个步骤本身相对简单,但当所有步骤组合在一起时,能够恢复完整的分布。
在自然语言处理领域,最典型的方法是自回归建模(autoregressive modeling)。

自回归语言建模经典之作:https://www.jmlr.org/papers/v3/bengio03a.html
在此类方法中,生成一个句子(或序列)的过程被拆解为逐个生成单词(或token),并使用已生成的单词作为上下文,来预测下一个单词。
自回归模型存在一些天生的缺陷:(1)计算成本高;(2)长程依赖与连贯性(long-term dependencies and coherence)问题。
例如,通过强化学习(RL)进行后训练,让模型在多个自回归步骤中学会序列推理,从而提升连贯性。
去噪扩散模型,提出了不同的生成任务分解方式,可以解决这两个限制。
在图像生成上,扩展模型取得了成功,其中添加的高斯噪声。

使用Stable Diffusion Ultra生成建的图像,由Stable Diffusion 3.5提供支持
然而,比如自然语言上,扩散方法并不如在图像上如意。
掩码扩散(masked diffusion)技术虽广泛应用,但仍存在根本性局限。
主要问题源于其底层Markov链设计:一旦token被填充,便无法修改,可能导致错误累积或token不兼容,且缺乏修正机制,直接影响结果质量。
另一个局限是,仅掩码token贡献损失信号,未掩码token保持无噪声状态,减少了有效批大小。
一种有效解决方案是借鉴BERT,将掩码机制与均匀噪声结合。这种方法不仅能解决上述问题,还带来额外优势:
-
采样阶段,模型不仅能填充空白,还能修改已解码token,提升灵活性和准确性。
-
训练任务更全面复杂,因为每个token都可能受噪声影响,模型需具备纠错能力,从而提高整体性能。
通过这种方式,模型学会识别「正确」与「错误」token后,可能发展出自我校正\自我纠错能力。
然而,在特定理想扩散路径上训练扩散模型时,仍面临技术挑战,需进一步研究。
标准的训练目标——扩散证据下界(diffusion ELBO)—— 需要已知Markov状态转移才能推导出来。
但构造具有特定性质的Markov链通常是复杂的逆问题,并不容易直接求解。
研究人员将插值扩散(interpolating diffusion)扩展到任意(随时间变化的)插值策略,避免了单独求解特定的掩码与均匀噪声组合的逆问题,同时提升了模型设计的灵活性,
具体来说,提出了广义插值离散扩散(GIDD),是一类具有边际前向转移(marginal forward transitions)的扩散模型,其形式如下:
值得注意的是,当π_t=m时,GIDD便退化为掩码扩散的特例。
可以证明,在适当选择αt和πt的情况下,确实存在一个Markov链可以产生这些边际分布,并推导其条件转移关系以及训练所需的ELBO公式。
GIDD旨在提供最大程度的灵活性,使得在任意时间点都可以对数据添加不同类型的噪声。
1)混合率αt:定义了随时间变化的信噪比(signal-to-noise ratio)。
2)混合分布πt:决定了数据在某一时刻被噪声化后的目标分布。
研究人员将这两个函数的组合称为扩散过程的「混合调度」(mixing schedule)。
定义 3.1(混合速率):设(累积)混合速率αt和βt(其中βt=1−αt)为时间可微且递减的函数αt:[0,1]→[0,1],满足初始条件α0=1(表示无混合状态)和最终条件α1=0(表示完全混合状态)。
这一设定决定了信噪比(SNR),即 SNR=αtβt。随着t的增加,αt减小,表明信号成分逐渐减少,而噪声成分逐渐增加。
定义 3.2(混合分布):设混合分布πt是一个依赖于时间的概率向量,即时间可微函数 πt:[0,1]→Δ∣V∣−1,这里 Δ∣V∣−1表示 ∣V∣维单纯形。
混合分布πt描述了在任意给定时间点 tt添加到数据中的噪声类型。因此,π1特别地代表了扩散过程的先验分布,它刻画了在时间 t=1时的数据噪声特性。
在此过程中,研究人员已经成功构建了一个马尔可夫链,其边缘分布按边际前向转移公式所述。
为了后续推导ELBO(证据下界),还需要定义相应的连续时间马尔可夫链(CTMC)的转移速率,具体如下。
扩散模型的标准分布pθ(zs∣zt)由以下公式给出:
这里,xθ(Zt,t)是一个神经网络,用于预测在噪声序列Zt条件下的x的分布。
此外,ELBO(证据下界)的推导涉及连续时间马尔可夫链(CTMC)的反向速率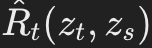 。
为了训练GIDD模型,需要一种可微分的方法来估计其似然函数(likelihood)。
证据下界(ELBO)正是用于此目的:通过最大化ELBO,实际上也是在最大化模型的(最坏情况下的)似然函数。
在计算ELBO时,需要用到GIDD的前向速率(forward rate)和反向速率(backward rate),这些已在前文推导完成。
然后,基于Campbell等人提出的ELBO形式进行一定修改,并将GIDD的前向速率和反向速率代入,经过化简后得到了定理3.7。
深入分析GIDD的ELBO(证据下界),可以发现它实际上是在同时优化两个任务:
这意味着,如果模型能够完美优化ELBO,它就能同时满足这两个目标。这一特性对于理解ELBO的全局最小值及其优化过程具有重要意义。
给定一个采样时间表0≈t0<t1<⋯<tT≈1和神经网络xθ,在选定的时间网格上对时间进行离散化,并采用祖先采样(ancestral sampling)方法。
具体来说,从一个全掩码token的序列开始,即所有ztT都设为掩码tokenm。
。
为了训练GIDD模型,需要一种可微分的方法来估计其似然函数(likelihood)。
证据下界(ELBO)正是用于此目的:通过最大化ELBO,实际上也是在最大化模型的(最坏情况下的)似然函数。
在计算ELBO时,需要用到GIDD的前向速率(forward rate)和反向速率(backward rate),这些已在前文推导完成。
然后,基于Campbell等人提出的ELBO形式进行一定修改,并将GIDD的前向速率和反向速率代入,经过化简后得到了定理3.7。
深入分析GIDD的ELBO(证据下界),可以发现它实际上是在同时优化两个任务:
这意味着,如果模型能够完美优化ELBO,它就能同时满足这两个目标。这一特性对于理解ELBO的全局最小值及其优化过程具有重要意义。
给定一个采样时间表0≈t0<t1<⋯<tT≈1和神经网络xθ,在选定的时间网格上对时间进行离散化,并采用祖先采样(ancestral sampling)方法。
具体来说,从一个全掩码token的序列开始,即所有ztT都设为掩码tokenm。
自校正步骤(Self-Correction Step)
此外,提出了一种不动点迭代方法,通过重新采样部分token来改进生成结果,使其更符合模型的判断。
具体而言,将完全去噪后的样本Z_{t_0}输入模型,并以温度参数τ进行采样。
这个过程会持续进行,直到结果收敛(详细内容见附录C)。
自校正算法是一种不动点迭代方法,可以应用于任何已经(部分)去噪的生成样本。
其核心思想是查询模型以识别模型认为错误并应该替换的token,并且一次只替换一个token以避免重新引入冲突token。
在实际操作中,发现收敛往往表现为在两个或多个同样优良状态(就自准确性而言)之间的振荡,因此额外基于自准确性实现了提前停止机制。
虽然GIDD可以用于掩码扩散,但最初提出这一广义框架的动机是探索掩码与均匀噪声的结合。
为此,研究团队设计了一种混合策略(mixing schedule),在保持掩码先验分布的同时,允许在不同阶段引入可调节比例的均匀噪声。
为了保证可解释性,设定在数据和噪声的中点(t=1/2)时,均匀噪声token的期望比例达到最大值p_u。
基于这一目标,定义了混合速率(mixing rate)和混合分布(mixing distribution)(定义3.1和3.2)。
其中: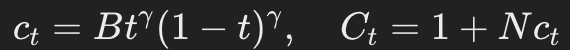 ,N表示词汇表的大小,B是一个常数,选取它的值可以保证均匀噪声的比例达到目标水平。
由此,得到边际前向分布(marginal forward distribution):
为了在t=1/2处使均匀噪声比例达到p_u,需要设定:
,N表示词汇表的大小,B是一个常数,选取它的值可以保证均匀噪声的比例达到目标水平。
由此,得到边际前向分布(marginal forward distribution):
为了在t=1/2处使均匀噪声比例达到p_u,需要设定: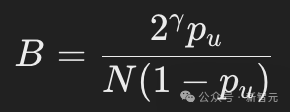 。
GIDD的ELBO计算涉及额外的常数和因子,需要推导相应的时间导数。
值得注意的是,当p_u=0.0时,GIDD退化回掩码扩散(masked diffusion)。
在的实验中,设定γ=1,但本节引入的超参数仍有许多其他可能的选择。
。
GIDD的ELBO计算涉及额外的常数和因子,需要推导相应的时间导数。
值得注意的是,当p_u=0.0时,GIDD退化回掩码扩散(masked diffusion)。
在的实验中,设定γ=1,但本节引入的超参数仍有许多其他可能的选择。
在开始实验之前,需要解决最后一个关键问题,这一改进将带来显著的性能提升。
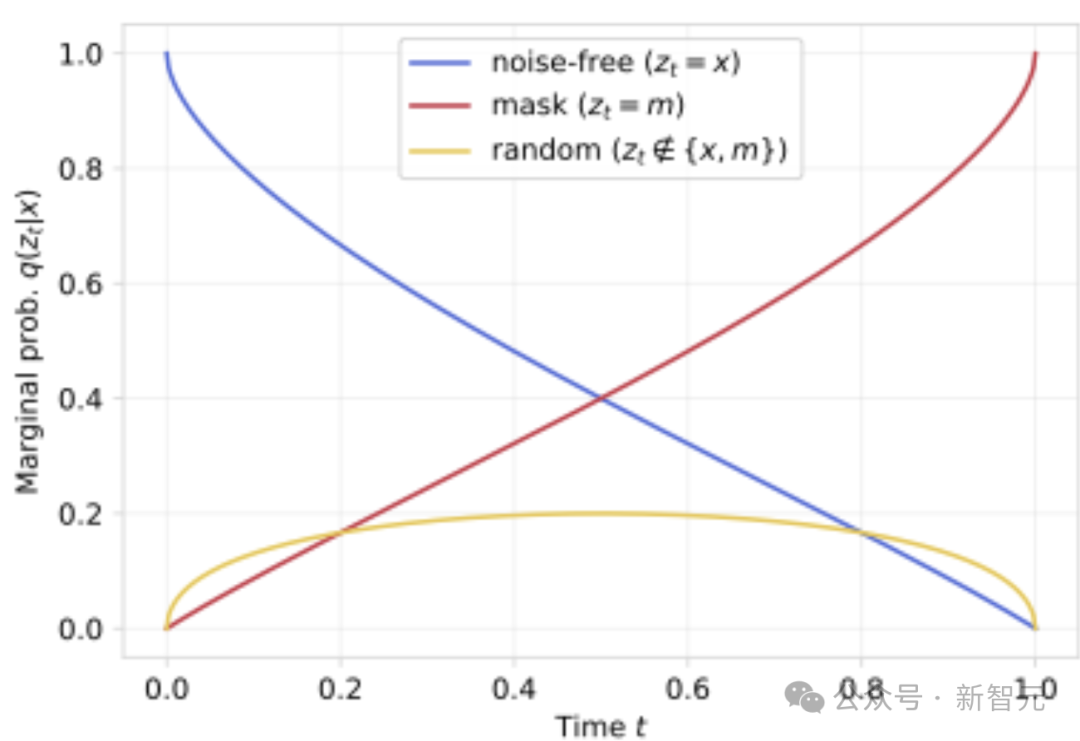
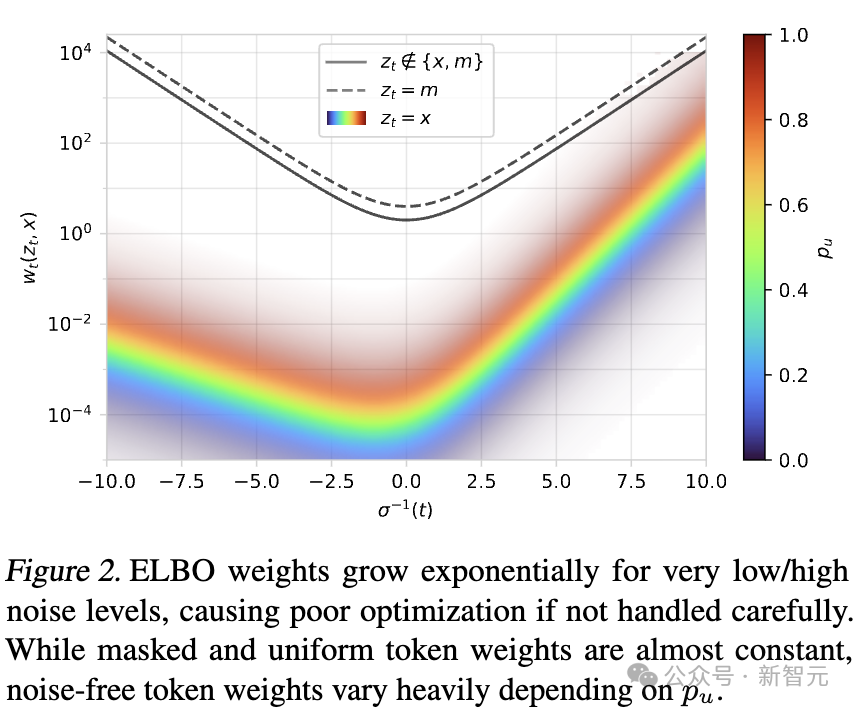
仔细分析扩散证据下界(ELBO)的权重wt(zt,x)后,发现当t→0或t→1时,权重的变化非常极端。
考虑以下三种可能情况:(1)z_t=x(未被噪声污染的token);(2)z_t=m(掩码token);(3)zt∉{x,m}(其他随机噪声token)
绘制w_t(z_t,x)随时间的变化曲线后(见图2),可以观察到在极低或极高噪声水平下,权重呈指数级增长。
解决方案:权重裁剪(Weight Clamping)
为了解决这个问题,提出了两种权重调整方案,以减少极端样本的影响,并强调中等噪声水平的样本,因为这些样本提供了最有价值的训练信号。
最简单直接的方法是对权重设置一个最大值w_{max},即:
根据初步实验,发现设定 wmax=1效果最佳,因此这一设定将在后续实验中被采用。
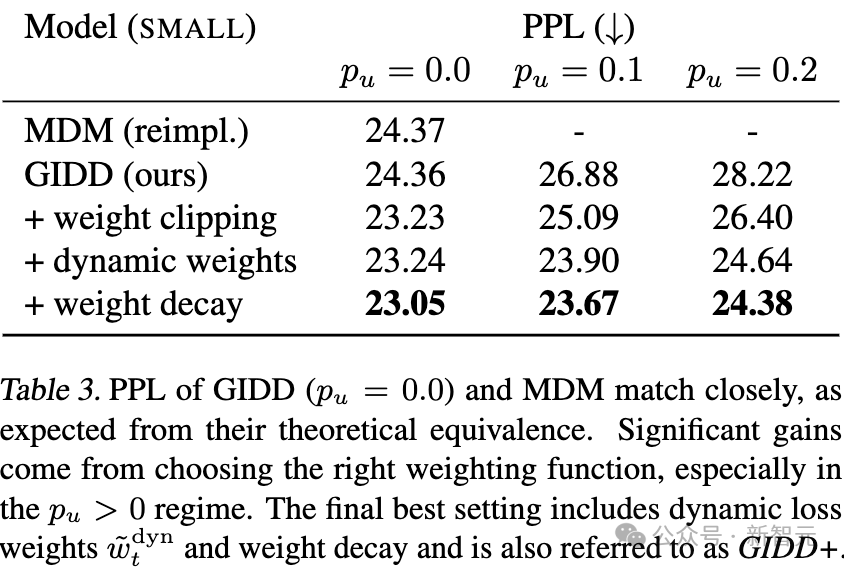
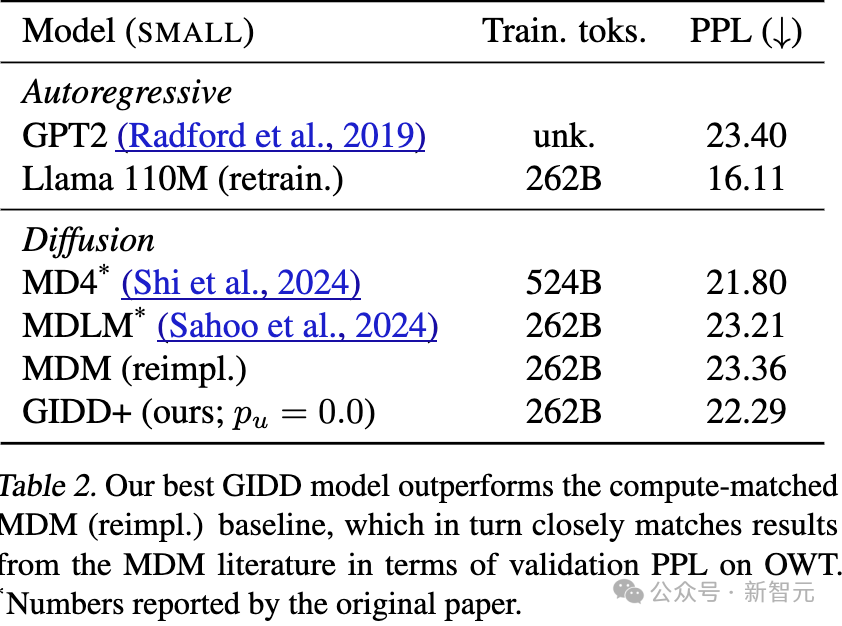
表3:GIDD(p_u = 0.0)和MDM的困惑度(PPL)非常接近,这与它们的理论等价性一致。
显著的效果提升来自于选择正确的权重函数,尤其是在p_u > 0的情况下。
最终的最佳设置包括动态损失权重和权重衰减,该设置也被称为 GIDD+。
上述权重裁剪(clamping)方法主要影响掩码token和均匀噪声token的权重。
然而,一个更系统的方法是:在保持最大损失权重恒定的同时,仍然保留掩码token、均匀噪声token和无噪声token之间的相对权重关系。
动态权重调整(Dynamic Weighting)
提出了一种动态加权函数(dynamic weighting function),其定义如下:
其中,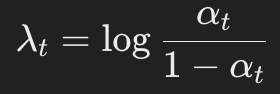 表示对数信噪比(log-SNR)。
该方法的相对权重关系(掩码token/均匀噪声token/无噪声token=2/1/Be^{-λ_t^2})是通过实验经验确定的。
需要注意的是,这种ELBO重加权方法等效于从一个非均匀分布中采样t。
表示对数信噪比(log-SNR)。
该方法的相对权重关系(掩码token/均匀噪声token/无噪声token=2/1/Be^{-λ_t^2})是通过实验经验确定的。
需要注意的是,这种ELBO重加权方法等效于从一个非均匀分布中采样t。
目前为止,观察到仅使用掩码训练的模型往往优于结合均匀噪声的模型,但尚未讨论引入均匀噪声的核心动机:让模型学会区分「正确」与「错误」token,希望它能够具备自我纠正能力。
为了评估生成样本的质量,采用生成困惑度(generative perplexity,PPL)这一指标。
具体而言,PPL计算的是生成样本在更强大模型下的似然值,在的实验中,使用Gemma 2 9B作为评估模型。
虽然PPL作为指标存在诸多局限性,但它在文献中被广泛采用,并且在相对比较不同模型的质量时依然具有参考价值。
除了PPL,还评估了模型的自我准确率(Self-Accuracy)。
即模型在生成过程中,对其认为「正确」的token(即在整个序列中赋予某个token最高概率)所占的比例。
值得注意的是,在进行自我纠正之前,训练时加入均匀噪声的模型样本质量已经更高。
尤其是在低计算量推理(low inference-compute)设置下,相较于仅使用掩码的模型,其生成困惑度(generative PPL)提升尤为显著。
这表明,训练时加入均匀噪声可以稳定生成过程,特别是在模型将自身生成的输出作为输入时,使得样本质量更高——即使其验证困惑度(validation PPL)略有下降。
这一发现引发了一个重要问题:自我纠正的效果是否只是因为额外的去噪迭代次数?
换句话说,模型在去噪过程中可能已经在执行一定程度的自我纠正,因此自我纠正步骤带来的提升,是否仅仅是因为额外的计算次数?
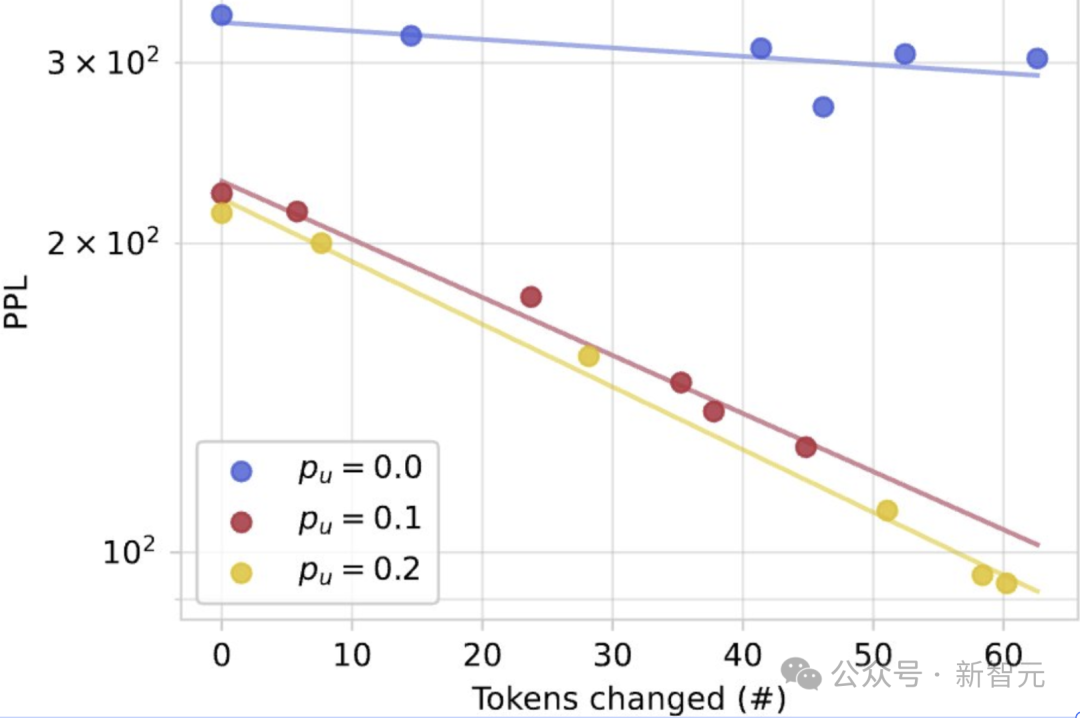
从实验来看,虽然增加去噪步骤确实会单调提升样本质量,但这种提升最终会趋于饱和(对于BASE模型,PPL约停留在200)。
然而,当引入自我纠正机制后,PPL可以进一步降低到100以下,这表明自我纠正带来的改进并非仅仅是更多去噪迭代的结果,而是一种额外的、非平凡(non-trivial)的提升。
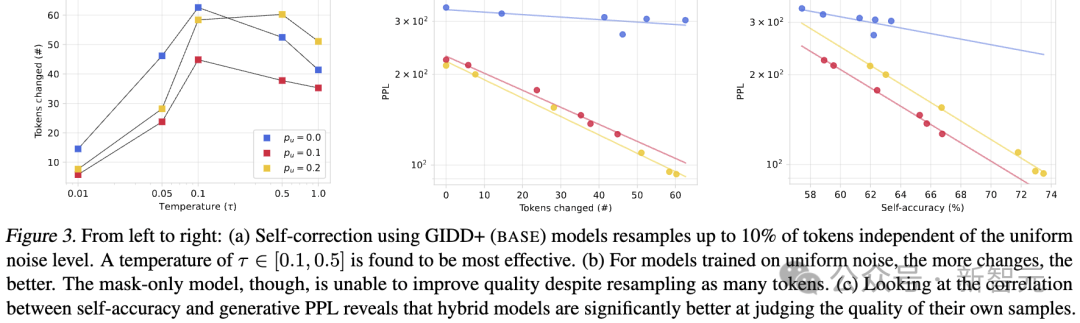
图3|从左到右(a)不同温度下token数变化;(b)token变化数与PPL的关系;(c)自我准确性与生成困惑度之间的相关性.
(a) 使用 GIDD+ (BASE) 模型进行自我纠正时,可以重新采样最多10%的token,这一过程与均匀噪声水平无关。研究发现,温度参数τ取值在 [0.1, 0.5] 之间时效果最佳。
(b) 对于在均匀噪声上训练的模型来说,采样的token数量越多,效果越好。然而,仅使用掩码(mask-only)的模型即使重新采样了同样数量的token,也无法提升质量。
(c) 通过分析自我准确性(self-accuracy)与生成困惑度(generative PPL)之间的相关性,发现混合模型在评估自身生成样本的质量方面明显更具优势。
在一系列基准测试中评估了模型的语言理解能力。基于混合噪声设置p_u > 0的更高难度,预计这些模型不会超过仅使用掩码噪声p_u = 0的情况,实验结果也证实了这一点。
因此,研究人员将重点放在比较最佳的 SMALL GIDD+ 模型与MDM以及自回归基线模型(即 GPT2(和重新训练的 Llama上。
作为参考,还纳入了两个 1.1B 参数模型,一个是自回归模型,另一个是掩码扩散模型。
基准测试包括ARC-e和ARC-c、BoolQ、Hellaswag、PIQA、OpenBookQA以及WinoGrande。
实验发现,平均准确率与验证困惑度(PPL)通常有很好的相关性(见表4)。
在扩散模型中,表现最好的是仅训练了131B token的GIDD+(p_u=0.0),超过了训练时间两倍的模型。
这可能是由于模型在训练数据中的虚假模式上过拟合,虽然验证损失仍然下降,但并未转化为下游任务的性能提升。
值得注意的是,最佳扩散模型GIDD+的表现优于自回归模型 GPT2,尽管训练数据的差异使得公平比较有些困难。实际上,最佳自回归模型 Llama(重新训练版本) 仍然在总体上表现最佳,但平均差距不到一个百分点。
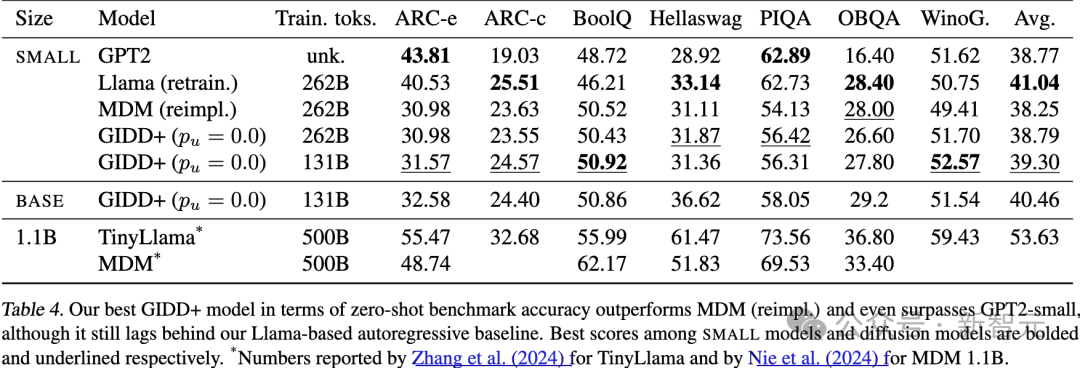
表4:不同模型的零样本(Zero-shot)基准准确率。在小型模型和扩散模型中分别用粗体和下划线_标出了最佳分数。
对于使用均匀噪声训练的 GIDD 模型,其趋势与验证困惑度一致,更多的均匀噪声通常会降低准确率。
下表5中列出了三种规模(TINY、SMALL、BASE)和所有均匀噪声水 0.0, 0.1, 0.2的GIDD+模型的基准测试准确率。
无论均匀噪声水平如何,模型的性能都随着规模的增加而持续提升。然而,使用均匀噪声训练的模型,在性能上略微但持续落后于仅使用掩码噪声的模型。
然而,随着模型规模的增加,性能持续提升,初步迹象表明,随着规模的扩大,差距可能会缩小。
直观地说,均匀噪声让训练任务变得更难:模型不能再理所当然地认为每个未掩码的token都是正确的,而是必须考虑上下文中的每个token,并在必要时将其替换为正确的token。
这种直观的解释表明,观察到的性能差异可能是由于模型容量不足,在这种情况下,预计更大的模型受均匀噪声的影响会更小。
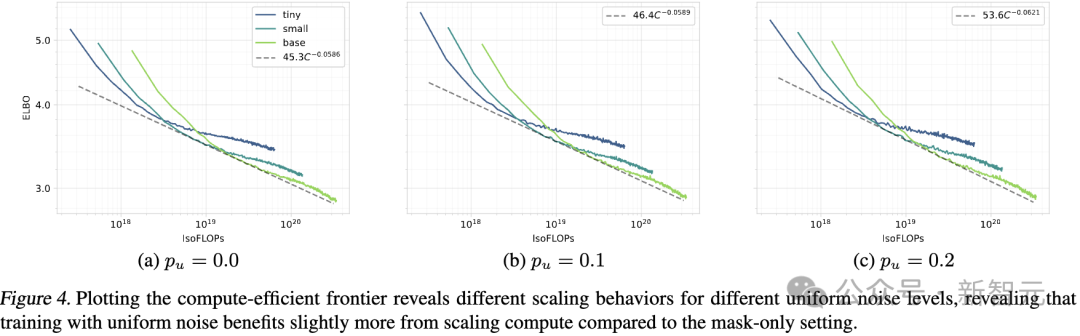
为了验证这一假设,在保持训练时长不变的情况下扩展了参数数量,并训练了不同规模(TINY、SMALL 和 BASE)的模型,分别在不同的均匀噪声水平0.0, 0.1, 0.2下进行训练。
然后,通过指数拟合绘制了计算效率前沿,反映帕累托最优的验证 ELBO(见图 4)。
每个噪声水平的样本量仅限于三种不同的计算预算,其中最大的计算预算仍然相对较小,仅为3.3*10^{20} FLOPs。
作为参考,现代大语言模型的许多标志性能力通常需要达到 10^{22} FLOPs 左右才会开始显现,这仍然比我们最大的计算预算高出两个数量级。
尽管如此,确实观察到了一个一致的趋势,即随着计算资源的增加,较高水平的均匀噪声表现更好,尽管这一趋势的幅度较小。
在仅使用掩码噪声的设置p_u = 0.0中,扩展指数为-0.0586,而加入均匀噪声后,p_u = 0.1和p_u = 0.2 的扩展指数分别提高到-0.0589和-0.0621。
外推这一趋势预测,p_u = 0.2的设置将在10^{21}FLOPs 左右超过 p_u = 0.0,这一计算预算在中到大规模的训练中通常可以达到。
然而,必须强调的是,这次的实验设置的局限性使得这种预测的可靠性较低。
尽管如此,观察到的扩展行为是令人鼓舞的,值得进一步研究。
(文:新智元)