


主要特点
-
全能创新架构:提出了一种全新的Thinker-Talker架构,这是一种端到端的多模态模型,旨在支持文本/图像/音频/视频的跨模态理解,同时以流式方式生成文本和自然语音响应。一种新的位置编码技术,称为TMRoPE(Time-aligned Multimodal RoPE),通过时间轴对齐实现视频与音频输入的精准同步。 -
实时音视频交互:架构旨在支持完全实时交互,支持分块输入和即时输出。 -
自然流畅的语音生成:在语音生成的自然性和稳定性方面超越了许多现有的流式和非流式替代方案。 -
全模态性能优势:在同等规模的单模态模型进行基准测试时,表现出卓越的性能。Qwen2.5-Omni在音频能力上优于类似大小的Qwen2-Audio,并与Qwen2.5-VL-7B保持同等水平。 -
卓越的端到端语音指令跟随能力:Qwen2.5-Omni在端到端语音指令跟随方面表现出与文本输入处理相媲美的效果,在MMLU通用知识理解和GSM8K数学推理等基准测试中表现优异。
Qwen2.5-Omni-7B demo
以下内容转载自官方稿件,略有调整。

-
高浓度的主流模型(如 DeepSeek 等)开发交流;
-
资源对接,与 API、云厂商、模型厂商直接交流反馈的机会;
-
好用、有趣的产品/案例,Founder Park 会主动做宣传。
01
模型架构
Qwen2.5-Omni采用Thinker-Talker双核架构。Thinker 模块如同大脑,负责处理文本、音频、视频等多模态输入,生成高层语义表征及对应文本内容;Talker 模块则类似发声器官,以流式方式接收 Thinker实时输出的语义表征与文本,流畅合成离散语音单元。
Thinker 基于 Transformer 解码器架构,融合音频/图像编码器进行特征提取;Talker则采用双轨自回归 Transformer 解码器设计,在训练和推理过程中直接接收来自 Thinker 的高维表征,并共享全部历史上下文信息,形成端到端的统一模型架构。
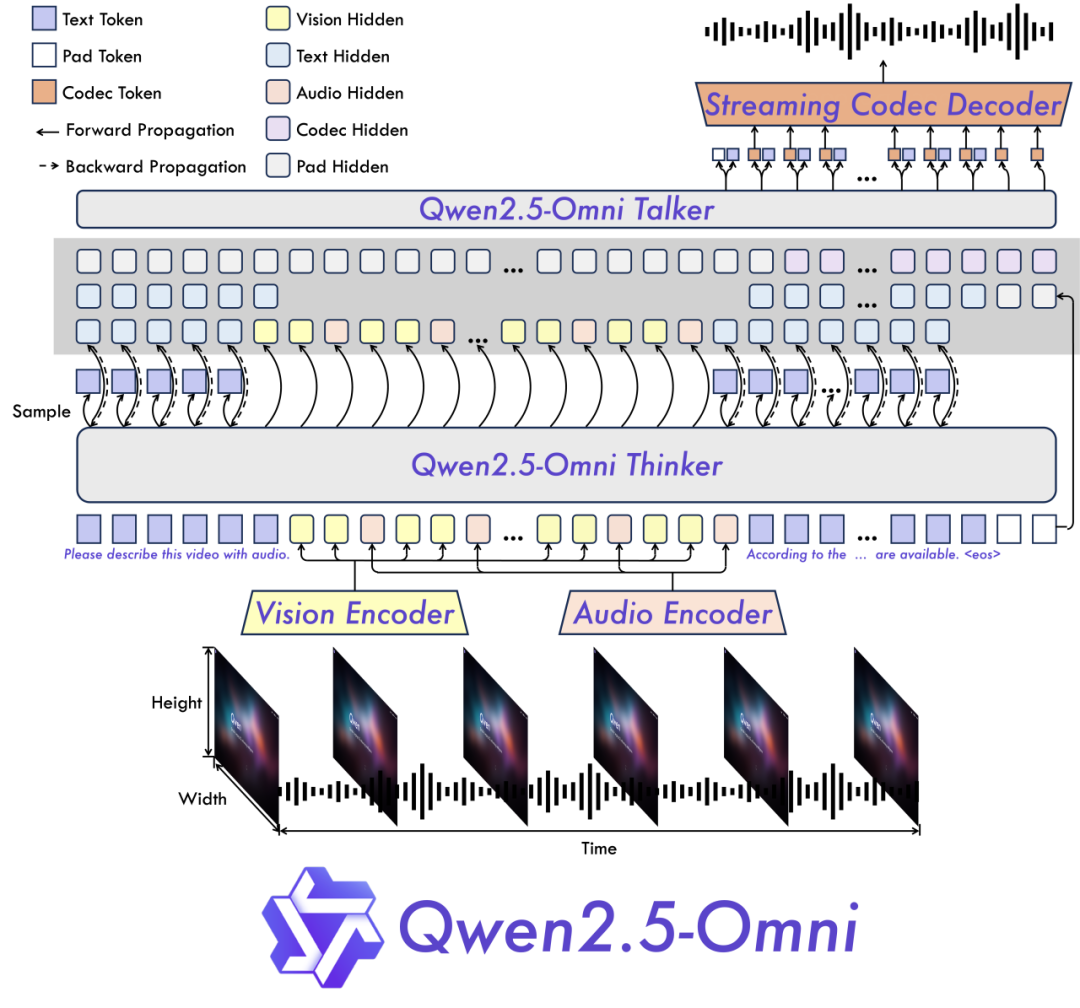
模型架构图
02
模型性能
Qwen2.5-Omni在包括图像,音频,音视频等各种模态下的表现都优于类似大小的单模态模型以及封闭源模型,例如Qwen2.5-VL-7B、Qwen2-Audio和Gemini-1.5-pro。
在多模态任务OmniBench,Qwen2.5-Omni达到了SOTA的表现。此外,在单模态任务中,Qwen2.5-Omni在多个领域中表现优异,包括语音识别(Common Voice)、翻译(CoVoST2)、音频理解(MMAU)、图像推理(MMMU、MMStar)、视频理解(MVBench)以及语音生成(Seed-tts-eval和主观自然听感)。
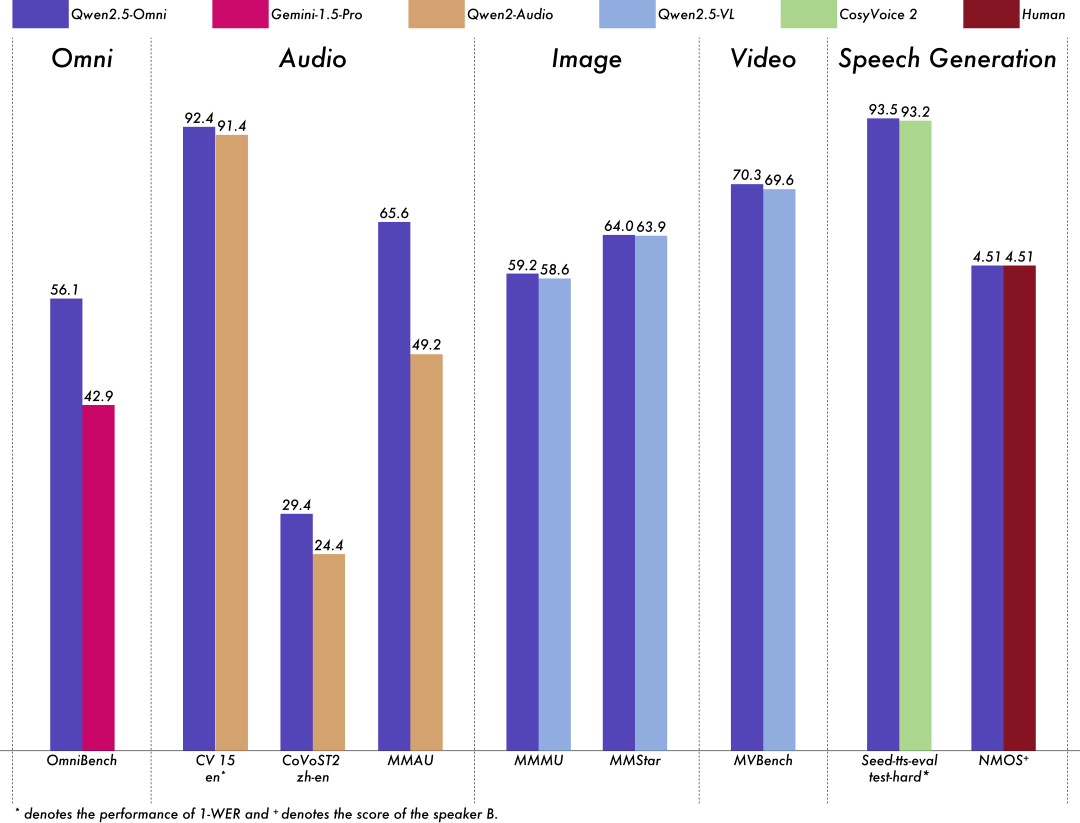
模型性能图
03
首创Thinker-Talker双核架构
该部分内容转自「量子位」文章。
目前官方已放出Qwen2.5-Omni技术Blog和论文。
Qwen2.5-Omni采用通义团队首创的全新架构——Thinker-Talker双核架构。
其中,Thinker就像“大脑”,负责处理和理解来自文本、音频、视频等多模态的输入信息,生成高层语义表征以及对应的文本内容。
Talker则更像“嘴巴”,以流式的方式接收由Thinker实时输出的语义表征与文本,并流畅地合成离散语音tokens。
具体来说,Thinker基于Transformer解码器架构,融合音频/图像编码器进行特征提取。
而Talker采用双轨自回归Transformer解码器设计,在训练和推理过程中直接接收来自Thinker的高维表征,并共享Thinker的全部历史上下文信息。因此,整个架构作为一个紧密结合的单一模型运行,支持端到端的训练和推理。
与此同时,团队还提出了一种新的位置编码算法TMRoPE(Time-aligned Multimodal RoPE)以及Position Embedding (位置嵌入)融合音视频技术。
TMRoPE编码多模态输入的三维位置信息,即多模态旋转位置嵌入(M-RoPE),并结合绝对时间位置,通过将原始旋转嵌入分解为时间、高度和宽度三个部分实现。
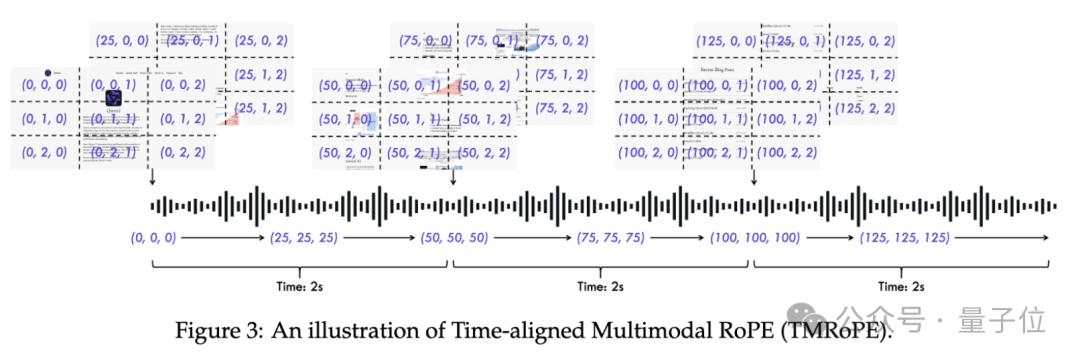
另外值得一提的是,从技术层面来看,Qwen2.5-Omni和一般的视频/语音理解模型以及其相应的视频/语音对话的AI功能,也有本质性区别。
在传统语音理解大模型的人机交互场景里,一般运用 ASR(Automatic Speech Recognition,自动语音识别)技术,把人类语音转换为文字文本,随后将其交给大语言模型处理,最终生成的内容借助 TTS(Text-to-Speech,语音合成)技术转化为语音反馈给用户。
而视频理解模型是基于图片、视频进行大模型理解,并以文字形式输出反馈。
这两种模型均属于相互独立的单链路模型。在一些AI应用中,甚至会串联多个模型来实现类似功能,如此一来,链路变得更长,效率大打折扣。
Qwen2.5-Omni-7B的特点在于,它原生支持视频、图片、语音、文字等多模态输入,并能原生生成语音及文字等多模态输出。
也就是说,一个模型就能通过“看”、“听”、“阅读”等多种方式来综合思考。
所以Qwen2.5-Omni得以在一系列同等规模的单模态模型权威基准测试中,拿下最强全模态性能,在语音理解、图片理解、视频理解、语音生成等领域的测评分数,均领先于专门的音频(Audio)或视觉语言(VL)模型
-
Qwen Chat:https://chat.qwenlm.ai
-
Hugging Face:https://huggingface.co/Qwen/Qwen2.5-Omni-7B
-
ModelScope:https://modelscope.cn/models/Qwen/Qwen2.5-Omni-7B
-
DashScope:https://help.aliyun.com/zh/model-studio/user-guide/qwen-omni
-
GitHub:https://github.com/QwenLM/Qwen2.5-Omni
-
Demo体验:https://modelscope.cn/studios/Qwen/Qwen2.5-Omni-Demo
(文:Founder Park)