



源神启动
又是深夜,中国源神再次出击。
今天凌晨1点,阿里发布了他们最新的全模态模型——Qwen2.5-Omni-7B。
在OmniBench多模态基准上刷新了世界纪录,在seed-tts-eval语音生成基准上更是直接媲美人类水平。

新模型发布不到12个小时,已经在huggingface上冲到了前六。
不是,这Qwen2.5-Omni到底什么东西,一下子这么NB了?
我仔细看了他们的技术论文,Omni就是全能的意思,全模态是指模型能够自适应文本、图像、音频和视频等多模态输入,并实时输出文本与语音。

论文地址:
https://github.com/QwenLM/Qwen2.5-Omni/blob/main/assets/Qwen2.5_Omni.pdf
说人话就是,Qwen2.5-Omni可以像人一样运转,多感官「立体」式感知世界。
更NB的是,这玩意只有7B,而且开源,可免费商用的那种。也就是说,我这张4080的垃圾卡也能跑了,再次感谢源神「Qwen」哥。

这是开源链接。
Hugging Face:
https://huggingface.co/Qwen/Qwen2.5-Omni-7B
魔搭社区:
https://modelscope.cn/models/Qwen/Qwen2.5-Omni-7B
百炼平台模型调用:
https://help.aliyun.com/zh/model-studio/user-guide/qwen-omni
如果想直接上手体验,官方也给出了在线体验渠道。
体验链接:https://chat.qwen.ai
微信/电脑里访问这个网址,看到右下角有一个紫色声波的图标。

点击这个声波图标,就可以体验了,可以与Qwen Chat进行语音通话或视频通话。

一手实测
模型发布后,我也第一时间进行了体验。
首先,测的是语音通话功能,主打一个“已读乱回”——不等她说完,我就提下一个问题,以此来考验模型的响应速度。
可以看到,Qwen2.5-Omni基本做到了“秒回”,和人的反应速度一样,延迟特别低。
接着,是视频通话测试。最近我新买了一个旋转书架,第二层全部放的是科幻书籍,其中插入了一本《智能体设计指南》。
我问:最近想学习AI,在我书架上,你推荐哪本书?
可以看到,虽然书架转得很快,她还是一下子就从画面中找到了《智能体设计指南》这本书,并推荐给我。
Qwen2.5-Omni也能够看电影,分析画面内容和人物情绪。
还能帮我分析多肉的生长情况。
过程中,我丢了一盆死掉的多肉给她,说“有点难过”。她则安慰我“你要是觉得心里过意不去,也可以找个地方把它放起来,就当做回忆吧。不管怎样,希望你能慢慢走出这个失落的情绪。”
从测的Case来看,Qwen都答得不错,几乎做到了实时交互,延迟特别低。
过去,AI语音通话和视频通话,我也测过不少。他们大多是单链路模型,所以延迟特别高。
比如语音通话,一般是先将人类语音转为文本,然后由LLM大语言模型进行处理,最后再通过TTS技术合成语音,回复给人类。这一套链路下来,必然会有延迟,以及信息丢失。
据了解,Qwen2.5-Omni模型完全创新了技术,支持原生多模态的输入和输出。
比如,在他们这个官方case中,Qwen能够记住并识别路边的各种广告牌和在视频里的对应位置。
也可以在下厨时,向Qwen咨询食材建议和调料使用。
画了一张草图,也可以让Qwen帮忙出出主意。
也能够电脑屏幕共享,读论文、做题那可太擅长了。
Qwen2.5-Omini还能听懂音乐,识别歌曲的曲风、音调,以及对歌曲提出自己的创作建议。
特别是,它还能理解音乐、音频中的情绪(包括无歌词的轻音乐),这让我有点意外。
为什么这么说?我们拿多模态鼻祖GPT-4o来举例,它只能识别语音中的文字信息。而Qwen2.5-Omni还能识别语音、视频中的情绪。
这,才是真正的多模态。

怎么做到的?
Qwen团队的技术,一直就不用质疑。
关于这个模型,他们做了很多自研创新:
1)首创双核架构Thinker-Talker。
怎么理解这个架构呢?你可以把Thinker比作我们人类的大脑,负责文本、图像、音频、视频等多模态信息的输入处理;而Talker模块则类似于我们的嘴巴或手,将Thinker大脑实时传输的语义文本,流式输出语音或文字。
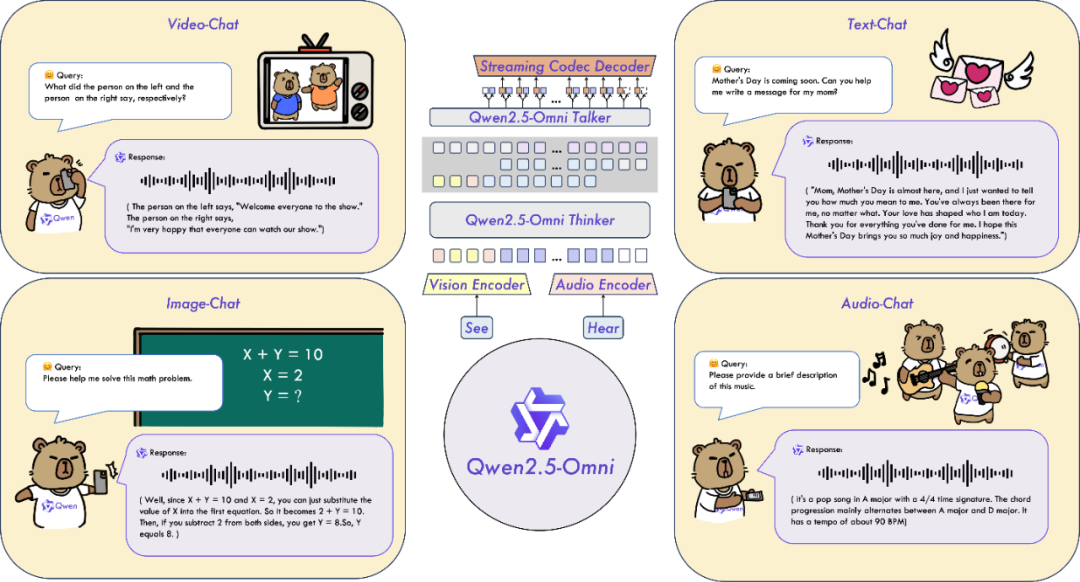
通过Thinker-Talker架构,可以实现实时语音与视频交互,让模型端到端工作。
2)首创Position Embedding融合音视频技术,将音频和视频帧融合在一个结构中。
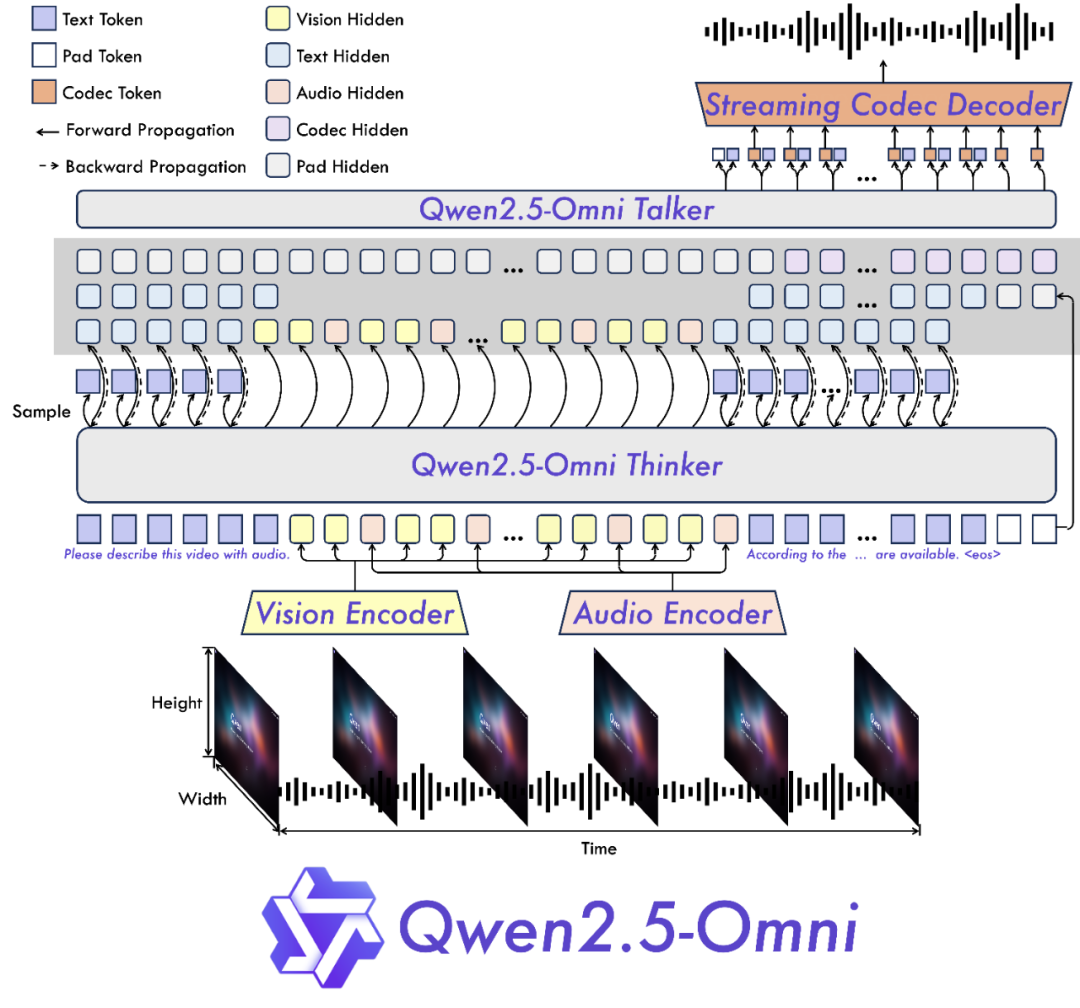
3)创新位置编码算法TMRoPE(Time-aligned Multimodal RoPE),通过显式引入时序信息,实现音视频精准同步。
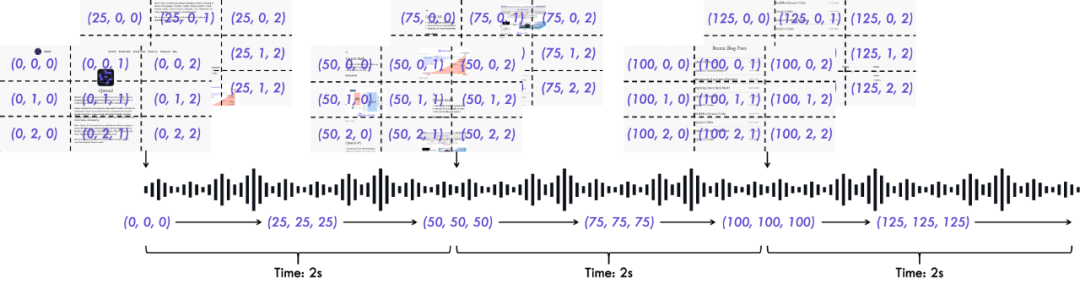
由此,带来了全新的体验:
1)实时语音与视频交互。
Qwen2.5-Omni可以同时感知所有模态输入,可以实时流式生成文本与语音,对话延迟低。
2)音频+视觉的情绪感知。
Qwen2.5-Omni不仅能通过视觉和文字,还能通过音频来识别情绪,让模型有了多模态融合的能力。比如理解音色、歌曲、情绪等。
3)指令理解大幅提升。
Qwen2.5-Omni的语音指令理解能力显著提升,达到了与纯文本输入一致的水平。
所以,Qwen2.5-Omni能够在OmniBench、seed-tts-eval等基准上刷新记录,也就不足为奇了。
更让我觉得NB的是,来自MOS测评结果,Qwen2.5-Omni的语音合成能力已经达到了人类水平。这个……就有点可怕了。

写在最后
什么是人工智能?
通常认为,人工智能就是模仿、延伸和拓展人的智能。
但你发现没有,其实现在很多AI连模仿人这一步都没有做到。你整天A来A去,最后还得靠人。以至于,有人调侃“所谓人工智就是,有多少人工,就有多少智能”。
那现在,我觉得这句调侃可以放一边了。因为,Qwen2.5-Omni全模态模型来了。

它区别于传统的单模态模型或拼接式多模态模型,实现了All-in-one的跨模态融合。
说人话就是,Qwen2.5-Omni具备了接近人类的多感官协同能力,能够「立体」式感知我们的世界并我们进行实时交互。
可以说,这一步让我们离AGI又近了。
更关键的是,它只有7B,完全开源。所有国家和地区不分政治立场,所有公司无论规模大小,所有AI爱好者不惧显卡门槛,大家都能够用得上、也用得起这款模型。
还能说什么?
阿里NB,QwenNB。
(文:沃垠AI)
感觉大模型陷入瓶劲了,不是技术,是场景