

微软、清华的研究人员联合发布了SECOM,一种专用于个性对话Agent的记忆构建和检索的创新方法。
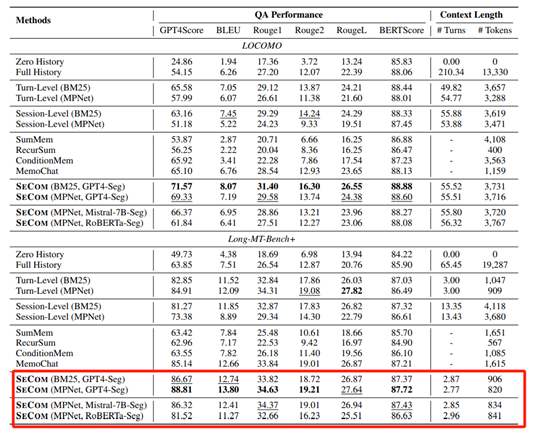
研究人员在LOCOMO和Long-MT-Bench+两个超复杂数据集上进行了综合评估。LOCOMO数据集的对话平均长度超过300轮,包含约9000个标记的对话片段,是目前最长的对话数据集之一。Long-MT-Bench+则通过合并多个会话构建更长的对话,平均包含约65轮对话。
结果显示,LOCOMO数据集上,SECOM的GPT4-Score达到71.57,比全历史方法高出17.42分,比轮次级记忆方法高出6.02分,比会话级记忆方法高出8.41分。
在Long-MT-Bench+数据集上,SECOM的GPT4-Score达到88.81,比全历史方法高出24.96分,比轮次级记忆方法高出3.90分,比会话级记忆方法高出15.43分。

随着大模型的飞速发展,已经被广泛应用在Agent中。与传统RPA、按键精灵不同的是,基于大模型的对话Agent能够进行更长时间的交互和主题。但这种长期、开放的对话也面临巨大挑战,因为它需要能够记住过去的事件和用户偏好,以便生成连贯个人化回答或执行超长自动化任务。
目前,大多数方法通过从对话历史中构建记忆库,并在响应生成时进行检索增强来实现这一目标,不过这些方法在记忆检索准确性和检索内容的语义质量方面都存在局限性。
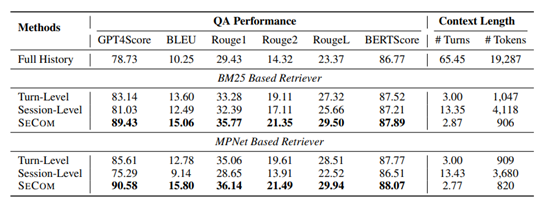
研究人员发现,记忆单元的粒度对检索增强响应生成至关重要。传统的轮次级、会话级以及基于总结的方法都存在不足。轮次级记忆过于细粒度,导致上下文片段化且不完整;
会话级记忆则过于粗粒度,包含大量无关信息;基于总结的方法在总结过程中会丢失关键细节。所以,发布了SECOM来解决这些难题。
零样本分割方法
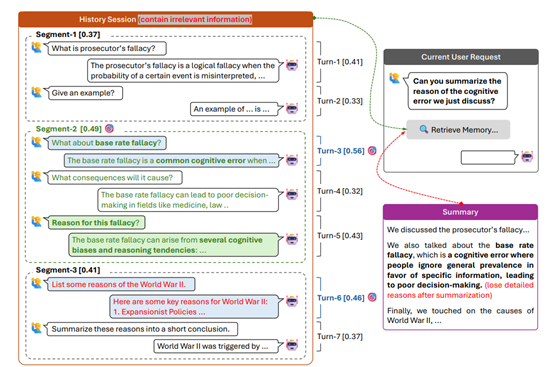
在SECOM 框架中,对话分割模型是其核心组件之一,主要负责将长期对话分解为语义连贯段落。这一过程并非简单的文本切分,而是基于对对话内容的深度语义理解,识别出对话中话题的转换点,从而将对话自然地划分为多个主题相关的单元。
能够有效避免传统轮次级或会话级记忆构建方法中存在的问题,例如,轮次级记忆的碎片化和会话级记忆的冗余信息过多。
SECOM使用了GPT-4 作为其对话分割的骨干模型。可在零样本学习的情况下对对话内容进行分析,并输出分割后的段落。

这种分割方法有两个巨大技术优势:首先,避免了传统有监督学习方法中需要大量标注数据的限制。在对话分割任务中,获取大量高质量的标注数据是非常困难的,因为话题转换点的识别本身就具有一定的主观性,即使是人类标注者也难以达成完全一致。
而零样本分割方法则无需依赖标注数据,直接利用模型的预训练知识进行分割,大大降低了数据准备的成本和难度。

此外,零样本分割能够更好地适应开放域的对话场景。由于没有受到特定领域或特定数据集的限制,GPT-4 能够凭借其广泛的知识和语言理解能力,对各种类型的对话进行有效的分割。无论是日常闲聊、学术讨论还是专业咨询,GPT-4 都能够识别出对话中的语义边界,将对话分割成连贯的段落。
使得 SECOM 的对话分割模型能够广泛应用于各种不同的对话场景,而无需针对每个场景单独训练模型。
自反思机制
为了进一步提升分割的准确性和一致性,SECOM引入了另外一个重要模块——自反思机制。
SECOM会首先以零样本的方式对一批对话数据进行分割,然后根据标注数据中的真实分割结果,识别出分割错误的部分。然后会分析这些错误,反思其原因,并据此调整分割策略。
这一过程有点类似于人类在学习过程中的自我反思和改进。通过不断地分析错误、总结经验并调整方法,模型能够逐步提高其分割的准确性。这种自反思机制不仅能够提升分割的准确性,还能够使模型的分割结果更符合人类标注者的偏好。换句话说,能使模型的分割行为更贴近人类对对话结构的理解和划分方式。
同时自反思机制的引入还带来了一个额外的好处,模型能够在少量标注数据的情况下快速适应新的领域或任务。
即使只有少量的标注样本,模型也能够通过自我反思和调整,快速学习到该领域或任务中的对话结构特点,从而提高分割性能。使得SECOM在实际应用中具有更强的适应性和可扩展性。
(文:AIGC开放社区)