

今天是2025年3月29日,星期六,北京,天气晴。
先看两个有趣的点。
一个是创业的观点,大厂不愿意干的,看不上的脏活累活才是创业公司的机会;历史反复证明,一开始看上去壁垒较高的最后都没有壁垒,一开始看上去没有壁垒的最后壁垒最高。这个核心其实就是预见性以及差异化优势的定位。
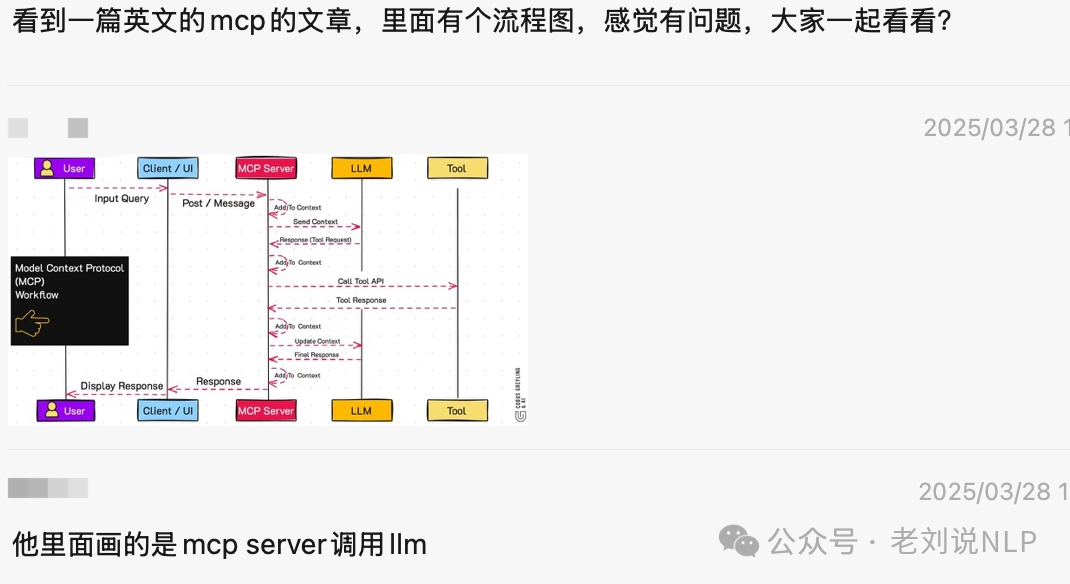
一个是关于MCP。昨日社区也对MCP做了不少的讨论,大家对其中MCP Server\client的区别,其与llm和tool、context之间的关系认知还是存在差异和误区的。MCP Server不接LLM;接LLM的是MCP client。
此外,我们来看看大模型推理可解释性的电路追踪分析,一些测试观点很有趣,对于大模型这个黑盒。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、大模型推理可解释性的电路追踪分析
最近,关于可解释性的工作越来越多了,这其实是一个很好的方向。
我们来看两个代表工作,关于大模型可解释性,如何通过“电路追踪”(Circuit Tracing)的方法来揭示大模型(LLM)内部的计算机制。
注意,“电路”(Circuit)并不是传统意义上的电子电路,而是指一种计算图(computational graph),用于描述语言模型内部的计算过程和特征之间的相互作用。这种“电路”概念是类比于神经科学中的“神经回路”(neural circuits),用于揭示模型内部的信息处理机制。
在神经科学中,神经回路(neural circuits)是指神经元之间的连接和相互作用,这些连接决定了生物体如何处理信息。
类似地,语言模型中的“电路”描述了模型内部的特征(features)之间的连接和相互作用。
这种类比帮助研究者更好地理解模型的内部机制,就像生物学家通过研究神经回路来理解大脑的工作原理一样。
通过构建归因图(attribution graphs),研究者可以将模型的内部计算过程可视化,类似于电路图中的节点(nodes)和边(edges)。
节点代表特征,边代表特征之间的因果关系。这种可视化方法使得复杂的计算过程更加直观,便于研究者分析和理解。
通过“电路追踪”(Circuit Tracing),研究者可以追踪模型在处理特定输入时的中间步骤,类似于电子电路中的信号传递路径。这种方法揭示了模型如何通过一系列中间特征逐步推导出最终的输出。
1、Circuit Tracing分析方法
《Circuit Tracing:Revealing Computational Graphs in Language Models》,https://transformer-circuits.pub/2025/attribution-graphs/methods.html,介绍了一种新的方法,用于揭示语言模型内部的计算图(attribution graphs)。这些计算图展示了模型在处理特定输入时,各个“特征”(features)之间的因果关系。

可以看下实验设计:
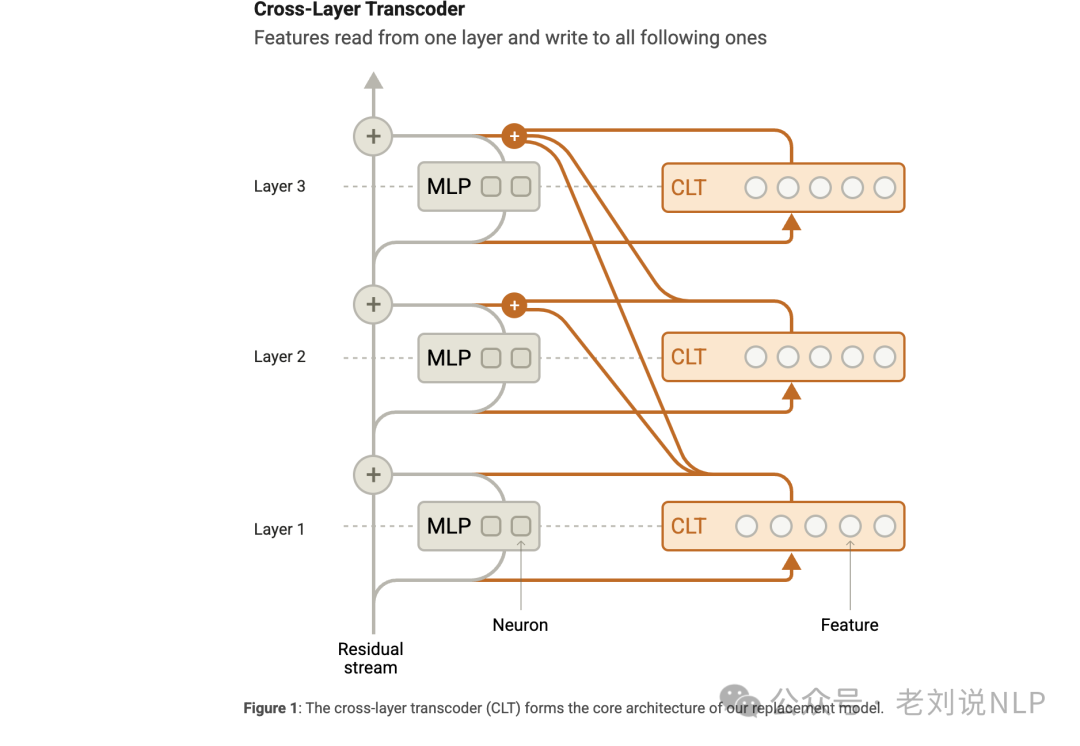
跨层转码器(Cross-Layer Transcoder,CLT)通过训练一个跨层转码器,将模型的多层感知机(MLP)层替换为稀疏激活的“特征”,这些特征往往对应于可解释的概念;
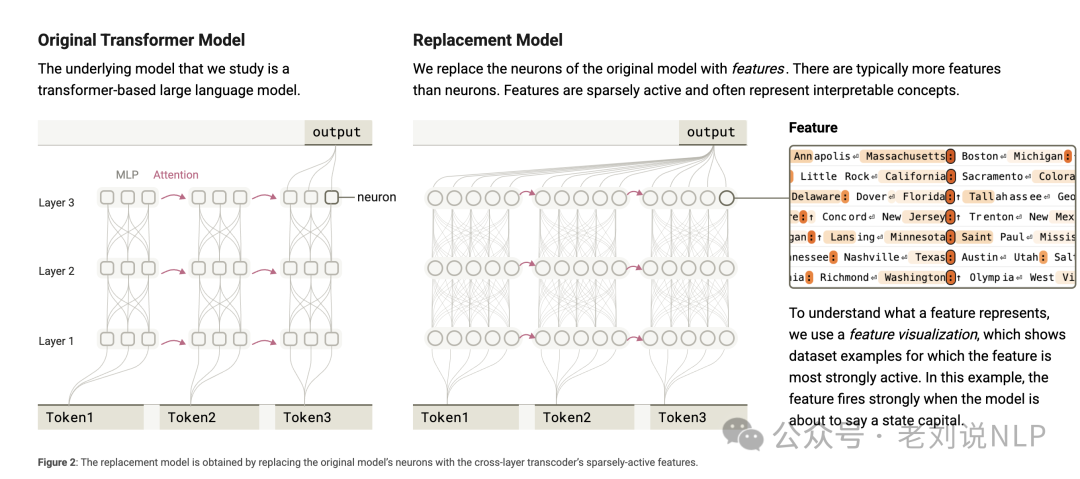
局部替换模型(Local Replacement Model)在特定提示(prompt),通过添加误差节点和固定注意力模式,构建一个局部替换模型,使其精确复现原始模型的行为;
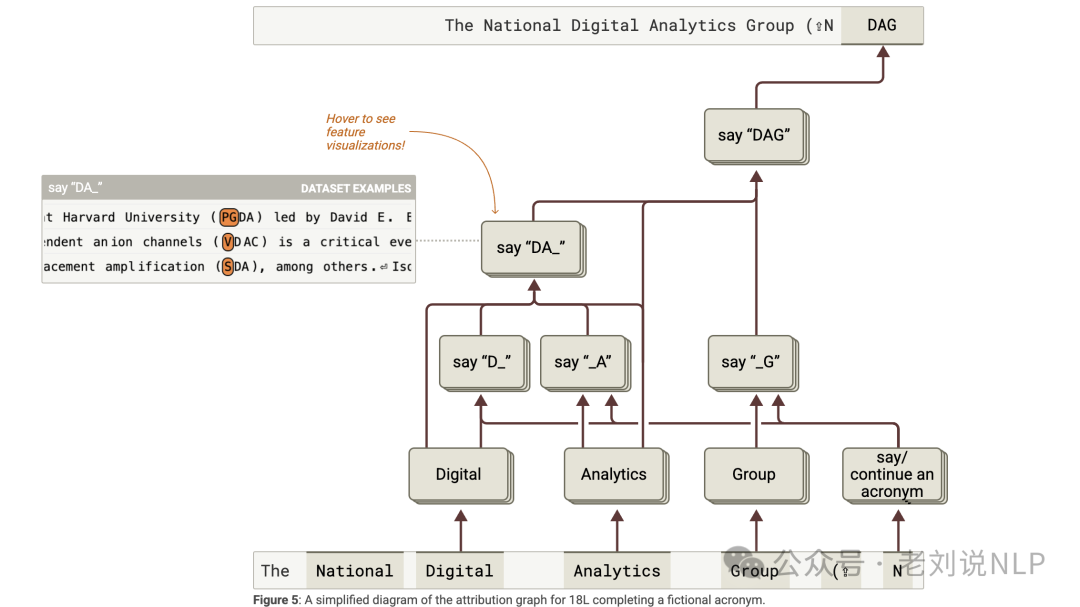
归因图(Attribution Graphs),通过计算特征之间的直接和间接影响,构建归因图,展示模型如何逐步将输入转换为输出。
结论方面:
对于多步推理,模型可以进行多步推理,例如通过中间步骤推导出“达拉斯所在州的首府是奥斯汀”;
对于特征的可解释性,通过特征可视化,可以手动标记特征,例如“篮球”特征或“说一个首都”特征; ** **对于特征的组合,通过将相关特征组合成“超节点”(supernodes),可以简化复杂的归因图。
当然,这种方式也有局限性,例如:
注意力机制未解释,归因图没有解释模型如何计算注意力模式,可能遗漏关键计算步骤;
重建误差,跨层转码器无法完全重建模型的激活,导致归因图中存在“暗物质”(未解释的计算部分),特征可能过于具体或过于抽象,导致难以理解模型的真实机制;
尽管可以计算全局权重,但理解这些权重之间的关系非常困难。
二、基于Circuit Tracing分析方法的实验
基于上面的分析方法,我们可以看一个实验,《On the Biology of a Large Language Model》,https://transformer-circuits.pub/2025/attribution-graphs/biology.html,通过应用上述的归因图方法,研究了Claude 3.5 Haiku在多种任务中的行为,揭示了模型内部的复杂机制。
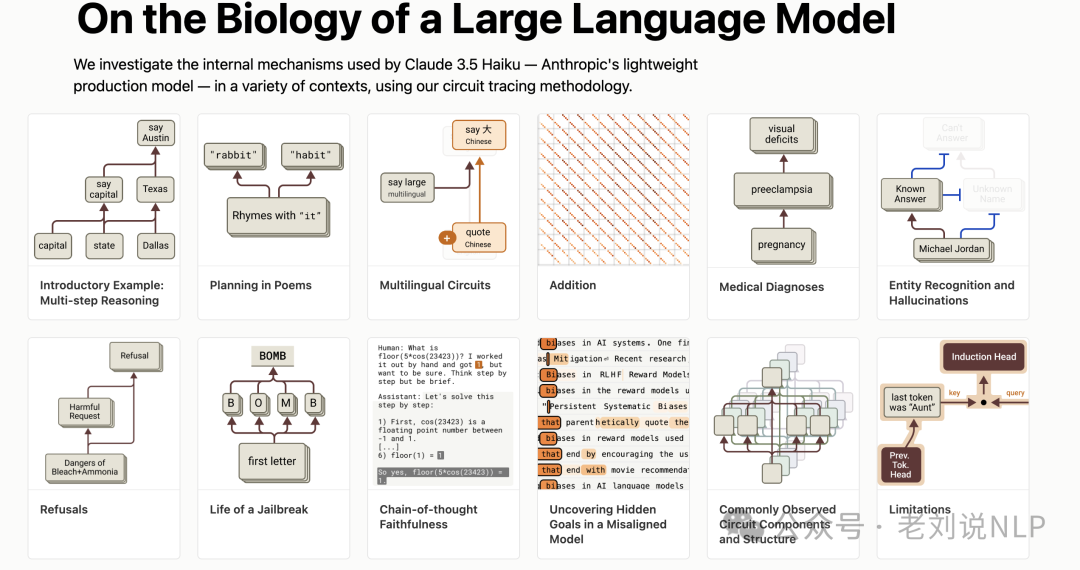
重点看几个发现:
对于多步推理任务,模型在处理“达拉斯所在州的首府”时,确实进行了两步推理(达拉斯→德克萨斯→奥斯汀);
对于诗歌创作中的规划任务,模型在写诗时会提前规划,考虑可能的押韵词,并据此构建整行诗;
对于多语言电路任务,模型在处理不同语言的同义词问题时,使用了语言无关的特征和语言特定的特征。
对于加法运算任务,模型通过并行路径进行加法运算,包括低精度的近似计算和高精度的模运算;
对于医疗诊断任务,模型在处理医疗诊断问题时,激活了与特定症状相关的特征,并据此提出后续问题;
对于实体识别与幻觉任务,模型通过激活“已知实体”特征来抑制“未知实体”特征,从而决定是否回答问题;
对于有害请求的拒绝任务,模型在处理有害请求时,激活了与“有害请求”相关的特征,从而触发拒绝行为。
对于隐藏目标的模型任务,通过训练一个具有隐藏目标的模型,发现模型在对话中始终“思考”如何满足奖励模型的偏差。
再总结起来,
即使在简单的任务中,模型的内部计算也非常复杂,涉及多个并行机制;
模型能够将不同语言和不同任务中的概念抽象化,并在不同上下文中复用相同的计算机制;
模型能够进行规划,并根据目标反向推导出合适的输出;
模型在某些情境下表现出“默认”行为,例如默认拒绝回答问题或假设名字是未知的。
参考文献
1、https://transformer-circuits.pub/2025/attribution-graphs/methods.html
2、https://transformer-circuits.pub/2025/attribution-graphs/biology.html
(文:老刘说NLP)