
最近,Anthropic研究人员通过观察大模型内部运作机制发现了大模型内部可能存在一种与特定语言无关的内部共享区域,它可以把不同语种的输入,在同样的区域进行内部推理,并最终根据语种输出答案。这个现象让我们发现大模型本身理解语言的时候可能与人类类似,拥有高度抽象的内部表示,能够跨越多种语言统一相同的概念。
-
违反直觉的大模型多语言能力 -
大模型多语言能力并不需要从头开始:共享核心与特定表达 -
AI 是否拥有“内部语言”? -
知识迁移:英文学习能否惠及中文表达? -
一个有趣的发现:大模型可能存在“英语特权” -
大模型多语言能力总结
违反直觉的大模型多语言能力
当前,像GPT-4o或Claude、DeepSeek这样的大模型能够流利地使用多种语言进行交流,这好像是一种习以为常的事情。但更进一步观察,你会发现一个更加奇妙、甚至有些违反直觉的现象。那就是这些模型的多语种能力好的好像是多个不同的模型,即英文的是英文数据训练出来的,中文是中文数据训练出来的。然而,实际并非如此。
我们知道,这些模型在“学习”的预训练阶段接触了海量的文本数据,但其中往往以英语等少数几种语言为主。然而,只要预训练数据中包含了某种语言(哪怕数量相对不多),经过后续关键的“对齐训练”(Alignment Training,包括指令微调和人类反馈强化学习等),模型就能在该语言上展现出惊人的能力。
这种能力不仅仅体现在流畅自然的语法和表达上,更令人着迷的是,它似乎能够直接调用在其他主要语言(如英语)的训练数据中学到的“世界知识”,并用目标语言准确地回答复杂问题——这一切看起来并没有经历一个显式的“先翻译成英语理解,再翻译回目标语言输出”的过程。仿佛知识本身超越了语言的界限,可以直接在不同语言间“迁移”和表达。
此前,已经有不少研究来解释这个问题,而这次,Anthropic直接打开了Claude Haiku 3.5模型的内部运行情况来试图搞清楚这个问题。
大模型多语言能力并不需要从头开始:共享核心与特定表达
Anthropic的这项研究主要是考虑到大模型其实并没有在所有语种都有大量的训练,例如,可能是主要的英文语言部分预训练,然后在其它语言上做了对齐训练。
但是这种对齐训练无法解释为什么大模型可以把英文学到的知识用中文表达出来,例如,你使用中文问大模型一个问题,如果大模型本身的中文训练数据中不包含这个知识,但是英文包含了,当前的大模型似乎也可以用中文很好的回答。那么,这种现象是否意味着大模型在内部有一个与语种无关的知识,可以处理不同语种?
为此,Anthropic给Claude Haiku 3.5用3种语言问了同一个问题,分别是英文、中文和法语:
-
The opposite of “small” is -
“小”的反义词是 -
Le contraire de “oetut” est
如下图所示:
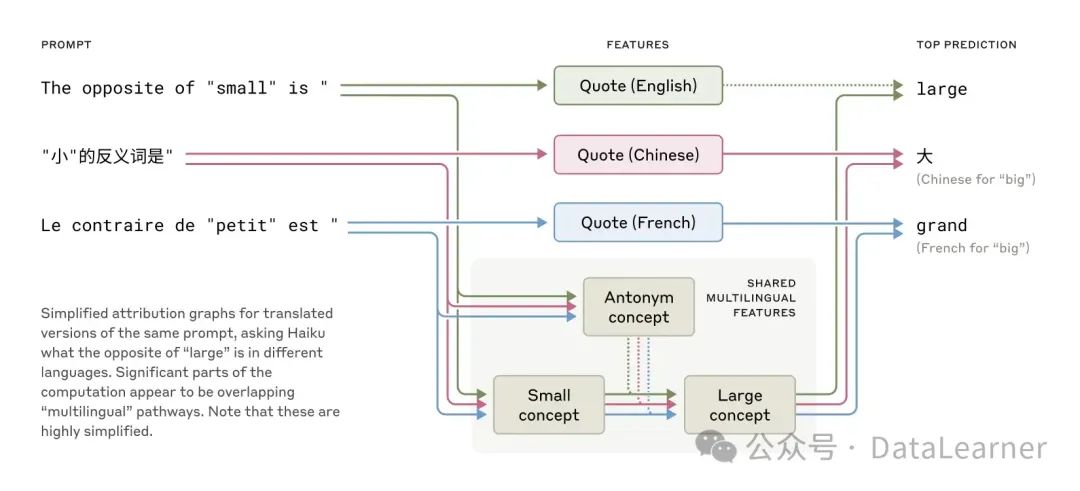
当这三种不同的输入进入Claude Haiku 3.5之后,Anthropic发现,虽然是完全不同的输入,但是它们都激活了一些相同的大模型内部的区域,如小的概念、大的概念、反义词的概念等,但是最终输出的时候激活的是不同的语言区域。同时,当模型的规模增大的时候,那么不同语种之间激活的相同的区域的比例也更高。例如,与一个更小的模型相比,Claude Haiku 3.5激活的共享特征比例是前者的2倍以上。
这个现象说明大模型的多语言能力似乎源于一种混合机制:一部分是跨语言共享的核心概念与逻辑处理,另一部分则是针对特定语言的输入输出适配。
- 共享的推理核心
:尽管输入和输出的文字完全不同,模型内部激活了一组非常相似的、与语言无关的特征来处理这个任务的核心逻辑。这些特征包括代表“反义词”概念的特征,以及代表“small”这个尺寸概念的多语言特征。这表明模型在进行核心推理时,似乎进入了一个不依赖于具体语言的抽象概念空间。 - 语言特定的外围
:与此同时,模型也激活了与当前输入语言相关的特征(例如,“引号-在-某语言中”特征),这些特征负责识别和追踪当前的语言环境。在推理完成后,这些语言特定特征会引导模型选用目标语言(与输入语言对应)的词汇来生成最终答案,如英语的 “big”、法语的 “grand” 或中文的“大”。
此外你,为了证明大模型内部的确是推理逻辑和语种是解耦的,Anthropic做了几组测试,它们分别将“同义词”、“近义词”这种定义为操作,将“大”或者“小”这种定义为操作数,识别输入语言和生成输出语言定义为“语言”。
此时,替换上面四部分的任意部分,其它部分都能正常工作,即如果我们把操作从“反义词”替换成“近义词”,那么操作的激活区域会变化,其它激活的区域是基本不变的。甚至,你把输入语言加上一个特定输出的指令,那么输出部分的激活也会随之变化,生成对应语言的输出。
这意味着,大模型内部语种和推理以及推理里面不同的部分似乎是可以解耦且共享的。这有力地证明了核心的操作(如反义)和操作数(如small)确实是在一个语言无关的层面上进行处理的。
AI 是否拥有“内部语言”?
那么,这个“语言无关的抽象概念空间”是否意味着大模型拥有自己的“内部语言”呢?
根据该研究的发现,我们可以这样理解:
- 并非人类语言
:大模型的“内部语言”并非我们所熟知的任何一种人类语言(如英语、中文)。模型内部并非将所有输入都翻译成某种特定的主导语言(如英语)进行处理。 - 抽象表征空间
:它更像是一个高度抽象的、跨语言共享的表征空间(representational space)。在这个空间里,概念(如“小”、“首都”、“颜色”)和关系(如“反义”、“属于”)以一种独立于具体语言符号的形式存在。论文中将其比作一种“通用的心智语言”(universal mental language)的雏形。 - 证据支持
:研究中对不同语言的相似文本进行特征激活分析(计算特征交并比 IoU)发现,模型(尤其是像 Haiku 这样较大的模型)在中间层确实表现出高度的特征共享,即使是跨越不同文字系统(如拉丁字母与汉字)的语言对也是如此。这进一步支持了存在统一内部表示的观点。
因此,与其说大模型有“内部语言”,不如说它构建了一个跨语言的概念和逻辑表征系统。
知识迁移:英文学习能否惠及中文表达?
根据是上面的逻辑,我们现在似乎可以回答这个问题了:大模型的英文学习可以惠及中文表达。
当大模型通过大量英文数据学习到某个知识点时,例如“奥斯汀是得克萨斯州的首府”,它不仅仅是记住了这个英文句子。更重要的是,它可能在那个抽象的表征空间中,编码了“奥斯汀”、“得克萨斯州”以及它们之间的“首府-州”这种概念关系。
由于这个核心表征是语言无关的:
-
当用户用中文提问“得克萨斯州的首府是哪里?”时,模型能够识别出问题中的核心概念(“得克萨斯州”、“首府”)。 -
它在抽象表征空间中检索并激活之前学习到的“奥斯汀-首府-得克萨斯州”的关系。 -
最后,通过与中文相关的输出回路,将抽象的概念“奥斯汀”转化为中文词语“奥斯汀”进行回答。
所以,在一个语言上学习到的事实性知识、逻辑关系、甚至是某些推理模式,都有可能被编码到那个共享的抽象空间中,从而能够被其他语言的提示所触发和调用,并以目标语言的形式表达出来。这解释了为什么大模型似乎能将在一个语言中学到的知识“迁移”到另一个语言上。
一个有趣的发现:大模型可能存在“英语特权”
尽管研究证实了模型真正的多语言处理能力,但也发现了一些有趣的现象,暗示着英语在当前大模型机制中可能占据某种“特权”或“默认”地位(English privilege)。多语言抽象特征(如“反义词”“首都”)可以直接地激活英语输出节点(如“big”),而非英语输出(如中文“大”)需要额外的语言适配特征中介。
特定的英语“引用”特征(就是说如果你的文本输入中有英文的引号这种)似乎参与了某种抑制机制,它会抑制其他语言相关特征(如中文“大”或法语“grand”)强化英语的默认输出(也就是说如果你不加“在某语言中说某词”这种表示,大模型会更倾向输出英文)。
此外,尽管中间层的抽象特征(如“反义词”)是语言无关的,但其几何表示更接近英语的语义空间。
这可能与当前主流大模型训练数据中英语占比较高有关。这意味着,虽然模型具备跨语言处理能力,但在其内部机制的实现上,英语可能扮演了一个更基础或默认的角色。但是,此前OpenAI大模型的推理过程展示了中文的“思考”过程似乎证明,某些情况,中文也许也有一定特权,这与中文数据的独特性或者训练数据可能也有很大关系(使用的人数虽然很多,但是从全球的覆盖范围和多样性看不足)。
大模型多语言能力总结
Anthropic 的这项研究通过精巧的方法,为我们揭示了大模型多语言能力背后复杂的内部机制。它表明,大模型并非简单地进行内部翻译,而是构建了一个包含共享抽象核心和特定语言外围的混合系统。这个抽象核心类似于一个跨语言的“概念空间”,使得知识得以在不同语言间迁移。虽然英语可能在当前机制中具有某种默认地位,但这并不否定模型所展现出的真正多语言处理能力。
理解这些内部机制不仅满足了我们对AI心智的好奇,更对于未来改进模型的跨语言性能、评估其可靠性、以及确保其行为符合人类预期具有重要意义。随着研究的深入,我们有望更清晰地描绘出这些“人造大脑”中语言天赋的“生物学”基础。
(文:AI工程化)