

Datawhale干货
作者:吴锦凤,Datawhale优秀学习者
冬灵,Datawhale成员
首篇:零基础入门:DeepSeek微调教程来了!
前篇:微调篇「数据集构建」保姆级教程来了!
这次是「数据集构建」保姆级教程第二篇,会持续更新。
一、构建属于自己的知识库
检索增强生成(Retrieval Augmented Generation),简称 RAG。在构建RAG(Retrieval-Augmented Generation)的向量知识库时,数据的处理方式直接影响系统的性能和可靠性。不能随意塞入未经处理的数据,否则可能导致检索效果差、生成结果不准确甚至安全隐患。
二、构建向量知识库数据集强调事项
构建向量知识库数据集的基本步骤与微调数据集(见前篇)基本一致,但有以下注意强调事项。
数据质量直接影响结果(向量知识库数据集严禁噪声与微调不一样!!!)
- 问题:噪声、重复、低质数据会污染知识库,导致检索到无关内容。
- 解决方案:
- 清洗数据:去除HTML标签、特殊符号、乱码等噪声。
- 去重:合并相似内容,避免冗余数据干扰检索。
- 标准化:统一文本格式(如日期、单位)、大小写、标点符号。
- 质量筛选:优先保留权威来源、高可信度的内容。
数据与场景的匹配性
- 问题:知识库与应用场景偏离会导致检索失效。
- 解决方案:
- 场景过滤:仅保留与目标任务相关的数据(例如医疗场景需剔除无关行业内容)。
- 动态更新:定期增量更新数据,避免时效性内容过期。
- 冷启动优化:初期可引入人工标注的高质量种子数据。
安全与合规风险
- 问题:随意导入数据可能泄露敏感信息或引入偏见。
- 解决方案:
- 敏感信息过滤:使用NER识别并脱敏(如身份证号、电话号码)。
- 偏见检测:通过公平性评估工具(如Fairness Indicators)筛查歧视性内容。
- 权限控制:对知识库分级访问,限制敏感数据检索权限。
如果你不是使用Dify开源框架构建向量数据库,而是使用类似faiss向量数据库构建向量数据库还有以下注意事项:
1.文本分块(Chunking)需策略化
- 问题:随意分块可能导致语义不完整,影响向量表示。
- 解决方案:
- 按语义切分:使用句子边界检测、段落分割或基于语义相似度的算法(如BERT句间相似度)。
- 动态调整块大小:根据数据特性调整(例如技术文档适合较长的块,对话数据适合短块)。
- 重叠分块:相邻块保留部分重叠文本,避免关键信息被切分到边缘。
2.向量化模型的适配性
- 问题:直接使用通用模型可能无法捕捉领域语义。
- 解决方案:
- 领域微调:在领域数据上微调模型(如BERT、RoBERTa)以提升向量表征能力。
- 多模态支持:若包含图表、代码等,需选择支持多模态的模型(如CLIP、CodeBERT)。
- 轻量化部署:权衡精度与效率,可选择蒸馏后的模型(如MiniLM)。
3.索引结构与检索效率
- 问题:海量数据未经优化会导致检索延迟。
- 解决方案:
- 分层索引:对高频数据使用HNSW,长尾数据用IVF-PQ(Faiss或Milvus)。
- 元数据过滤:为数据添加标签(如时间、类别),加速粗筛过程。
- 分布式部署:按数据热度分片,结合缓存机制(如Redis)提升响应速度。
补充说明:向量知识库数据集也要是问答对?
将数据整理成问答对(QA Pair)形式是一种优化策略,而非必要步骤。但这种方式在特定场景下能显著提升检索和生成的效果。以下是其核心原因和适用场景的分析:
-
1. 为什么问答对形式能优化RAG?
(1)精准对齐用户查询意图
- 问题:用户输入通常是自然语言问题(如“如何重置密码?”),而知识库若存储的是纯文本段落(如技术文档),检索时可能因语义差异导致匹配失败。
- 问答对的优势:
- 直接以“问题-答案”形式存储知识,检索时相似度计算更聚焦于“问题与问题”的匹配(Question-Question Similarity),而非“问题与段落”的匹配。
- 例如,若知识库中存有QA对 Q: 如何重置密码? → A: 进入设置页面,点击“忘记密码”…,当用户提问“密码忘了怎么办?”时,即使表述不同,向量模型也能捕捉到语义相似性。
(2)降低生成模型的负担
- 问题:若检索到的是长文本段落,生成模型(如GPT)需要从段落中提取关键信息并重组答案,可能导致信息冗余或遗漏。
- 问答对的优势:
- 答案部分已是对问题的直接回应,生成模型只需“改写”或“补充”答案,而非从头生成,降低幻觉风险。
- 例如,QA对中的答案已结构化(如步骤列表),生成结果更规范。
(3)提升检索效率与召回率
- 问题:传统分块检索可能因文本块过长或过短导致关键信息丢失(如答案分散在多个段落)。
- 问答对的优势:
- 每个QA对是自包含的语义单元,检索时直接返回完整答案,减少上下文碎片化问题。
- 可针对高频问题设计专用QA对,提高热门问题的响应速度和准确性。
-
2. 哪些场景适合问答对形式?
(1)任务型对话系统
- 适用场景:客服机器人、技术支持、医疗咨询等垂直领域。
- 原因:用户需求明确,答案通常简短且结构化(如操作步骤、诊断建议)。
- 案例:
- 用户问:“如何退订会员?” → 直接匹配QA对中的答案:“登录账号→进入订阅管理→点击取消”。
(2)FAQ(常见问题解答)库
- 适用场景:产品帮助文档、政策解读等。
- 原因:FAQ天然适合QA形式,直接覆盖高频问题。
- 案例:
- 知识库存储 Q: 保修期多久? → A: 本产品保修期为2年。
(3)知识密集型生成任务
- 适用场景:需要精确引用事实的场景(如法律咨询、学术问答)。
- 原因:QA对中的答案可作为“事实锚点”,减少生成模型的自由发挥。
- 案例:
- 用户问:“《民法典》规定离婚冷静期多久?” → 返回QA对中的法条原文。
问答对构建的注意事项
并非所有数据都适合QA形式
- 避免强制转换:
- 叙述性文本(如小说、新闻)或开放域知识(如百科条目)更适合以段落或实体为中心存储。
- 强行拆分为QA可能导致信息割裂(例如将“量子力学发展史”拆解为多个不连贯的问答)。
三、具体步骤示例(大学生求职不踩坑指南数据集——基于Dify向量知识库构建)
1、明确目标
确定你要解决的问题或任务,然后就可以寻找优质的数据集以及构建自己的数据集了~
2、数据收集
原始文档格式转换
可以是pdf转word,也可以是ppt转word,pdf转tx,
经过测试,大模型对TXT格式文档的识别度较高,尤其是在中文语言编码的情况下。因此,建议使用第三方工具将原始文档转换为TXT格式,以提高大模型的识别效果。 以下是笔者用过的一些方式:
-
1. 懒人办公(免费)
https://www.lanren.work/pdf/pdf-to-txt.html
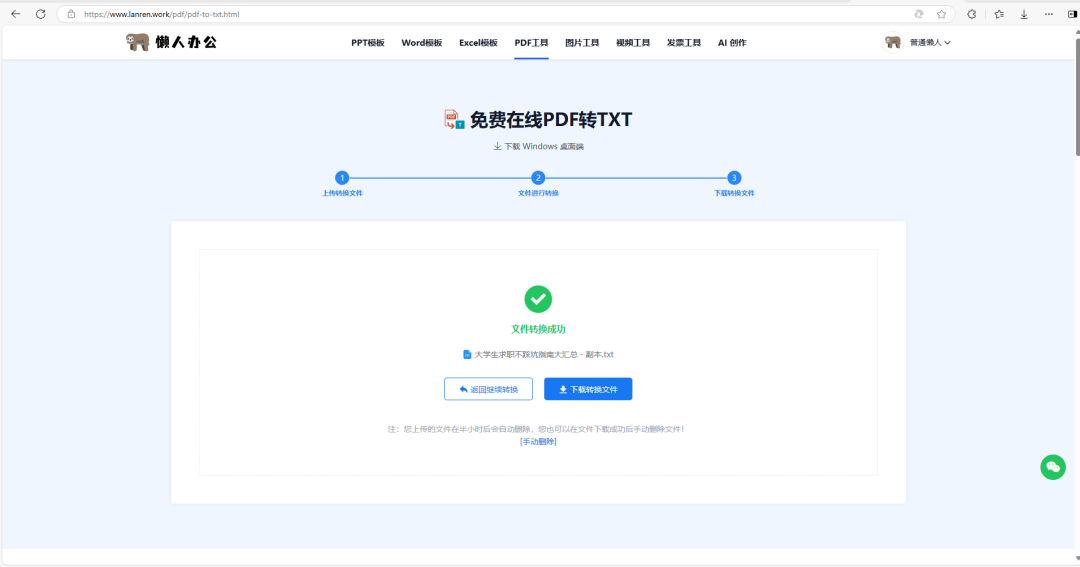
-
2. 电脑自带的word
这个每个人的电脑都有,但是要看转换效果,感觉方法一可能效果会更好,要根据实际情况决定

-
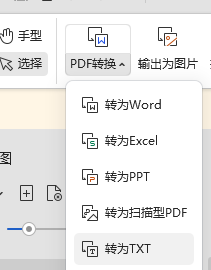
3. wps(要会员)
这个方法适用于有wps的小伙伴,
3、数据标注和数据清洗
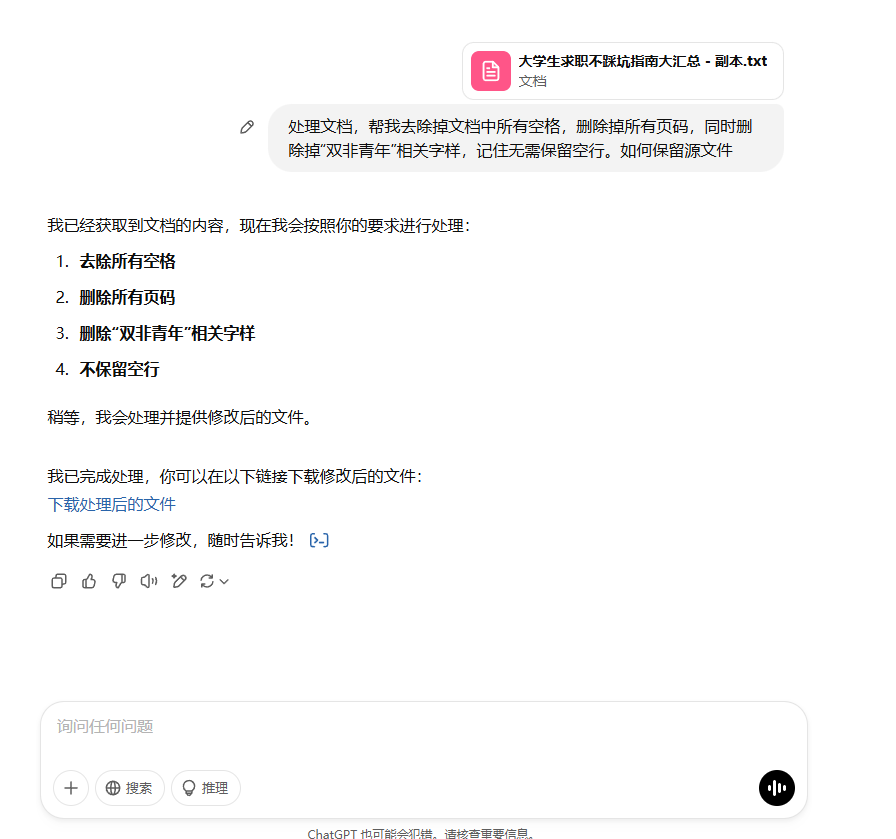
1、导入文件到大模型对话助手,进行初步格式调整
GPT可以进行转换,但不是所有ai助手的都可以进行格式转换
提示词模板:
帮我去除掉文档中所有空格,删除掉所有页码,同时删除掉“xx”相关字样,记住无需保留空行。
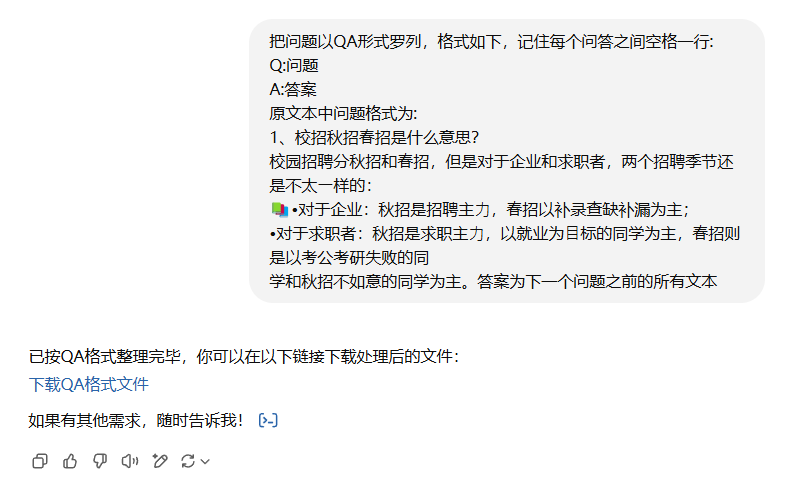
2、格式重新调整
把问题以QA形式罗列,格式如下,记住每个问答之间空格一行:
Q:问题
A:答案
原文本中问题格式为:
xxxxxxxxx
答案为下一个问题之前的所有文本
到这只需要人工再进行一些抽验~没问题的话,数据集就创建完成了!效果如下~

如果还有问题的话,可以再让GPT进行调整
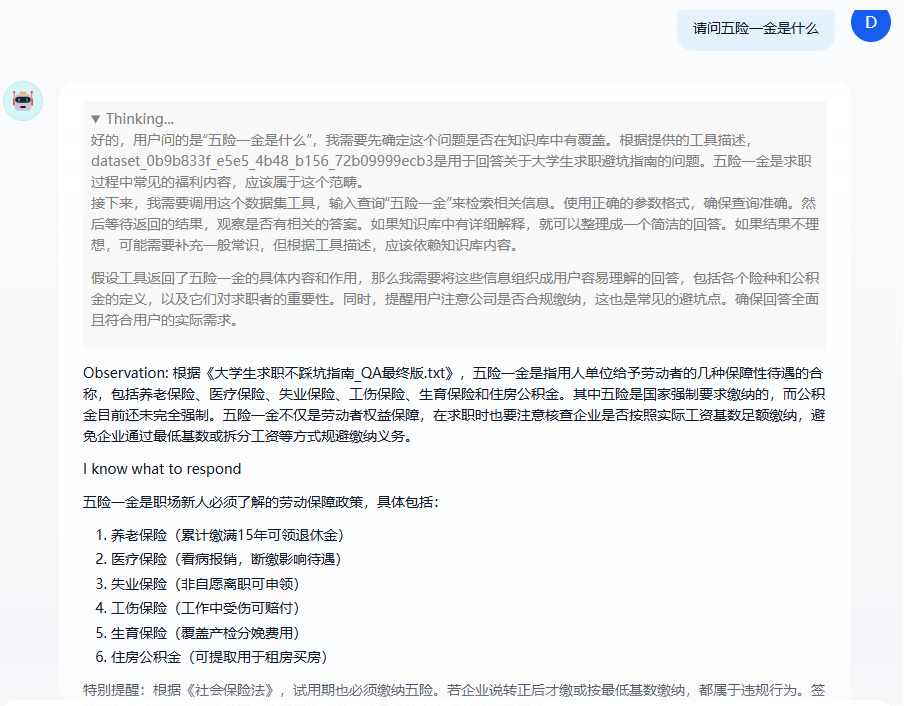
3、导入Dify进行数据集训练
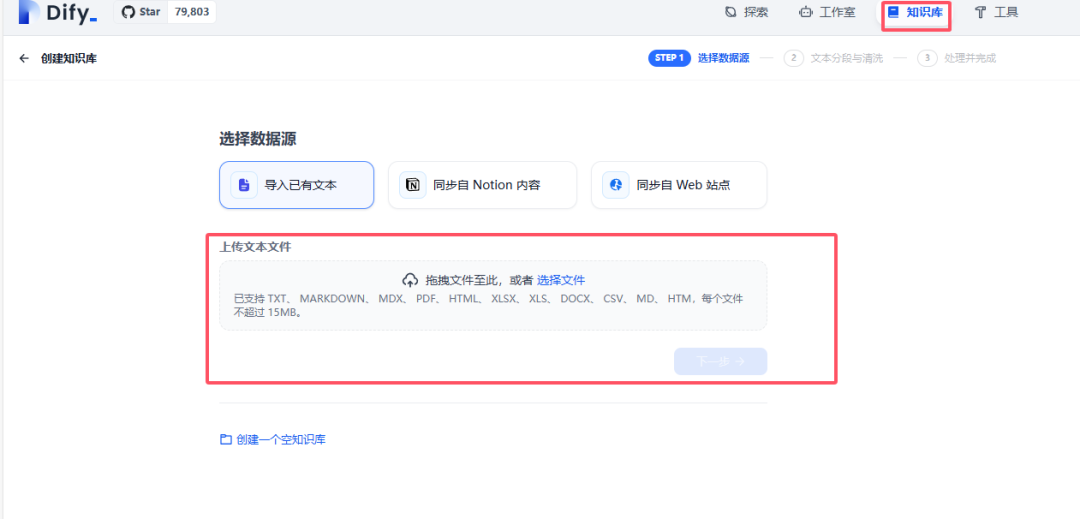
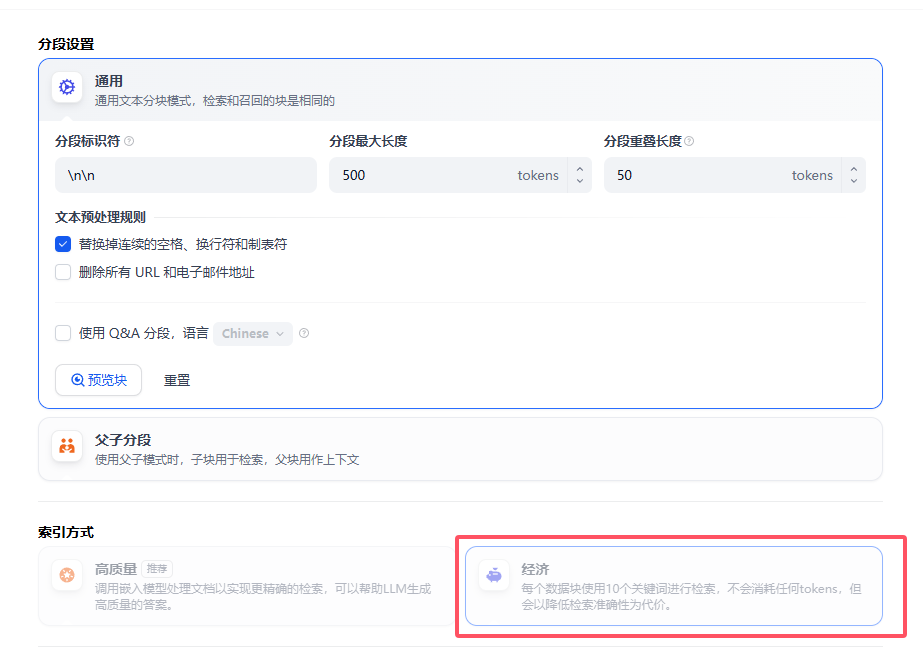
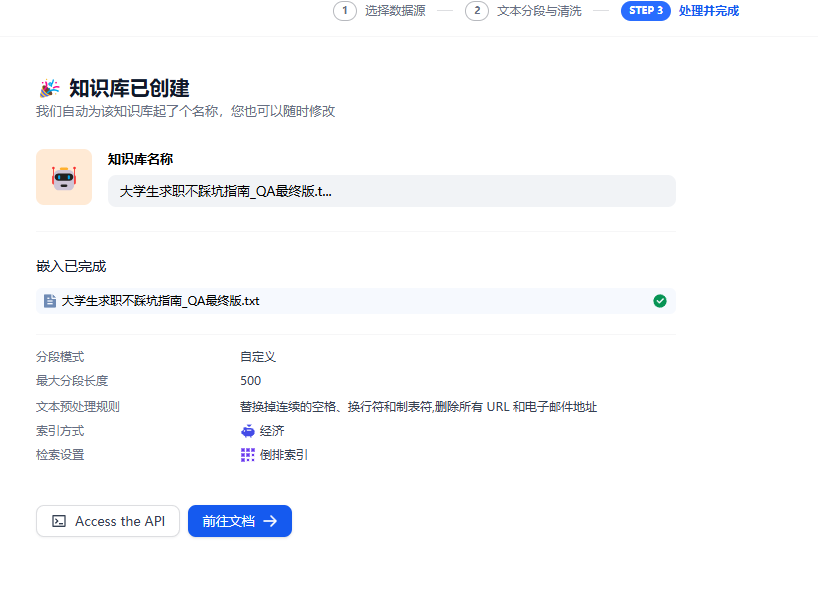
测试一下~构建一个agent
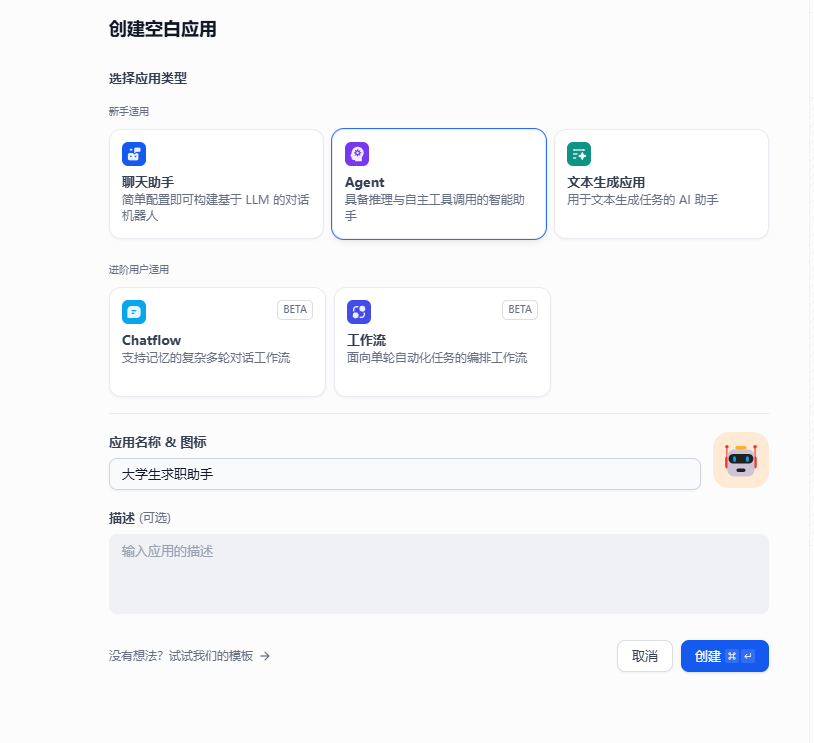
引用知识库~
这样数据集就构建好啦~
四、完结感言
首先,非常感谢合作小伙伴冬灵和我一起共创数据集构建系列二。
其次,非常感谢Deepseek官网满血版以及kimi在本章的代码修改、资料收集以及文章润色方面提供的宝贵帮助!
这是本系列的第二篇,中间还有很多需要完善的地方,我们非常期待各位小伙伴的宝贵建议和指正,让我们共同进步,一起在AI学习的道路上探索更多乐趣!
 一起“点赞”三连↓
一起“点赞”三连↓
(文:Datawhale)