


相信大家最近已经体验到了再一次火爆全网的 DeepSeek V3-0324 最新版,我第一时间也写了文章介绍,虽然是一次小更新,但超出想象,实测就前端能力来说超过R1,与Claude 3.7相比也毫不逊色!
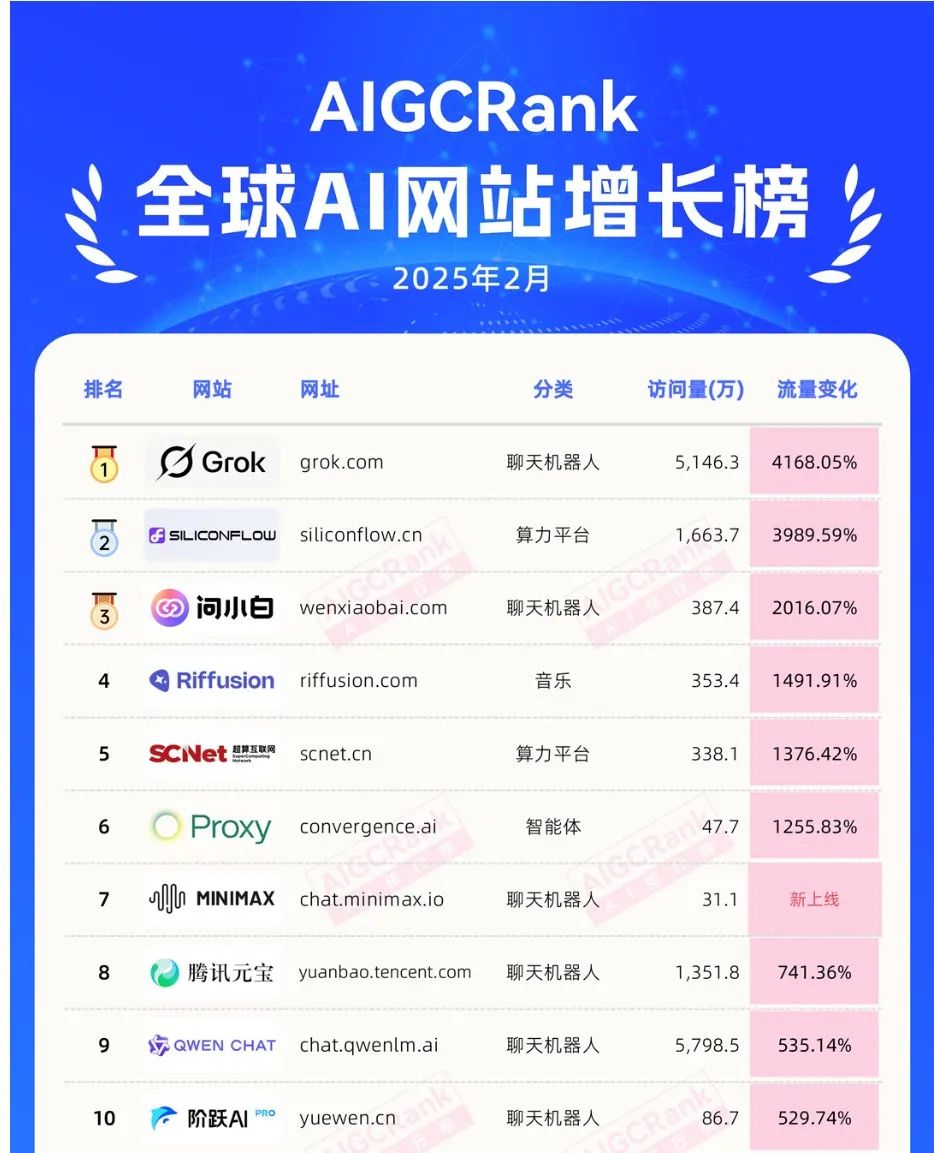
一个月之前,我给大家介绍过免费的AI“问小白”,当时由于DeepSeek R1的火爆,官方体验不佳,“问小白”第一时间接入满血版R1,免费无广告,流畅的R1体验给大家留下深刻印象,这两天“问小白”又第一时间上线了 DeepSeek V3-0324,这可能是你最早能够体验到 V3最佳效果的地方了,顺便给大家放张图,金杯银杯不如用户的口碑,它在AIGCRank发布的2025年2月全球AI网站增长榜上,位居全球增速第三
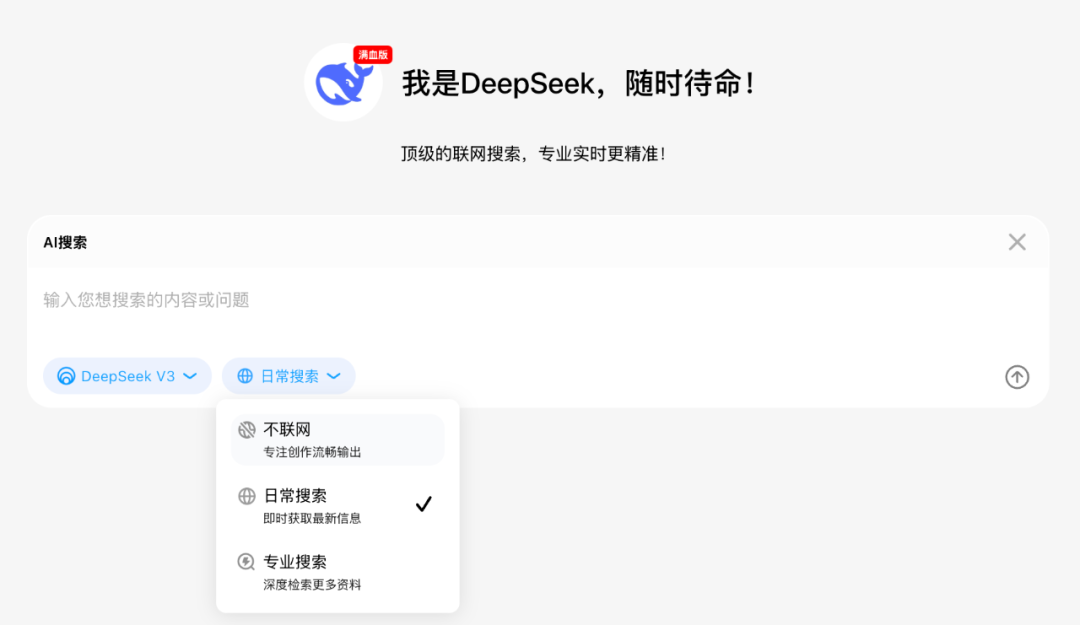
问小白自研的元石大模型,结合DeepSeek R1/V3,双模驱动基础上,加上业内领先的 RAG 增强技术,能让大模型与网页信息进行有效的交叉验证。问小白推出了两种搜索模式:日常搜索和专业搜索,搜索更准,幻觉更低。使用 V3 速度更快,答案直出更敏捷;用 R1,深度思考,推理更聪明,问小白把AI搜索推向了全新的高度
废话不多说,直接实测一下
直接上手实测
打开问小白的网页
https://www.wenxiaobai.com/(我比较习惯网页端实测体验,大家可以自行选择。手机 app 端关闭 R1 即是V3,PC端或者mac端直接选择 V3 即可)
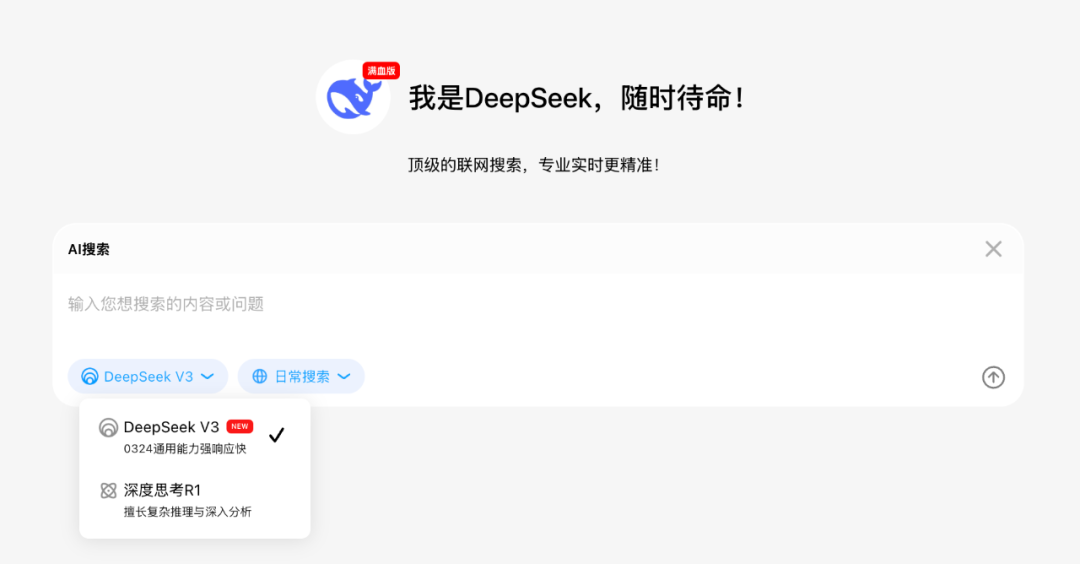
我尝试用问小白解决几个典型场景的问题(记得要在设置里选择V3新版,搜索可以选取日常搜索)
场景一:快速获取并总结最新行业动态(新版V3+日常搜索)
我问:“总结一下过去 24 小时内,关于人工智能最新进展和主要突破,并列出信息来源。”
问小白的 V3 模式响应极快,几乎是“秒回”,迅速整合了50篇最新的新闻、研究摘要,并清晰地列出了来源链接。答案不仅时效性强,而且逻辑清晰,重点突出,分门别类。这要是靠传统搜索引擎,我得自己点开多少个网页、过滤多少广告才能拼凑出来?

作为每天时刻关注AI前沿的我来说,看到问小白V3 对过去24小时AI的最新进展总结,有些答案我可以一眼验证,比如模型与技术突破里面三条我很确定,但是就全面度而言我还是没能及时注意到2到4涉及AI商业,行业,研究前沿的权威最新信息,而且可以直接点击信息来源,不得不说这对常年关注AI 的我非常有用,对普通用户来说我相信这是一个非常满意的搜索结果
我的评价: 对于需要快速把握行业脉搏、获取即时信息的需求,问小白的 AI 日常搜索结合 V3 的速度优势,体验非常好。信息准确,来源可靠,节省了大量筛选时间,不想拉踩同行,但真的比某度强太多了
场景二:快速专业搜索,挑战复杂问题(新版V3+ 专业搜索)
继续上一个问题 ,根据问小白给出的结果,我问了一个比较有深度的问题:“深度整合所有关于这个争议的信息:OpenAI图像生成引发版权争议 GPT-4o的吉卜力风格图像生成功能引发设计圈震动,结合AI发展,法律,版权,模型训练数据来源等问题来研究
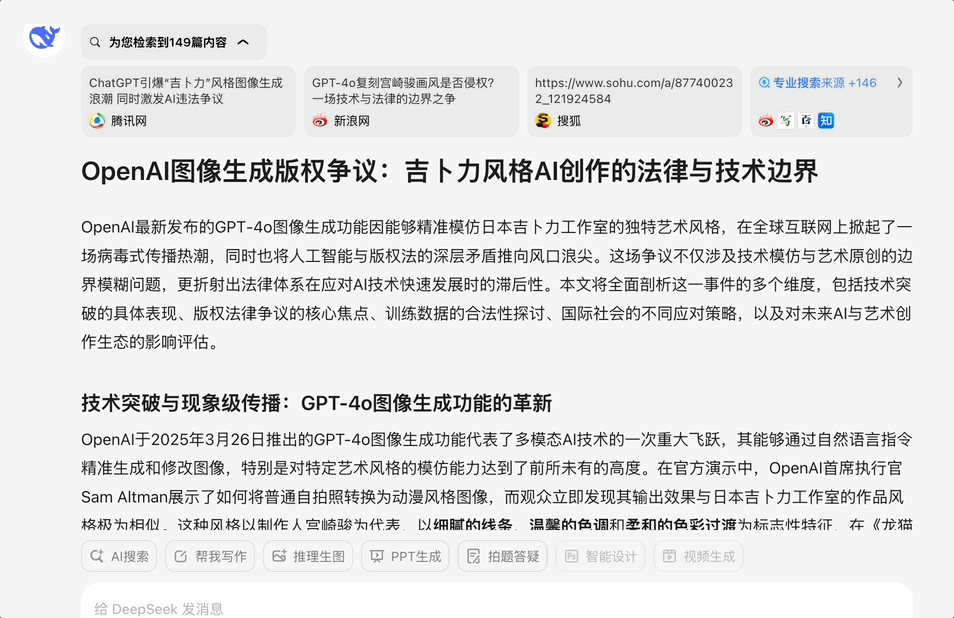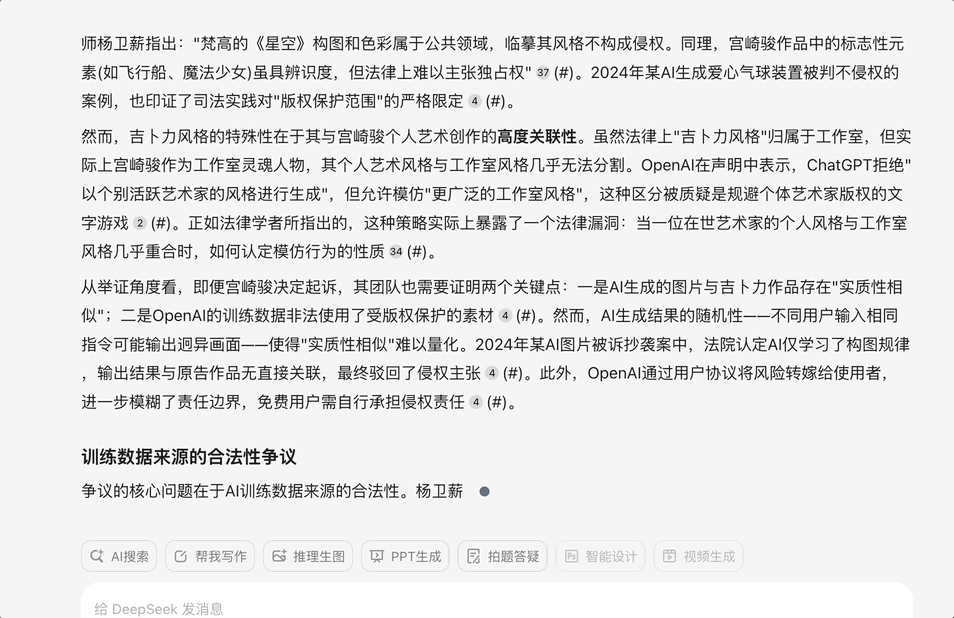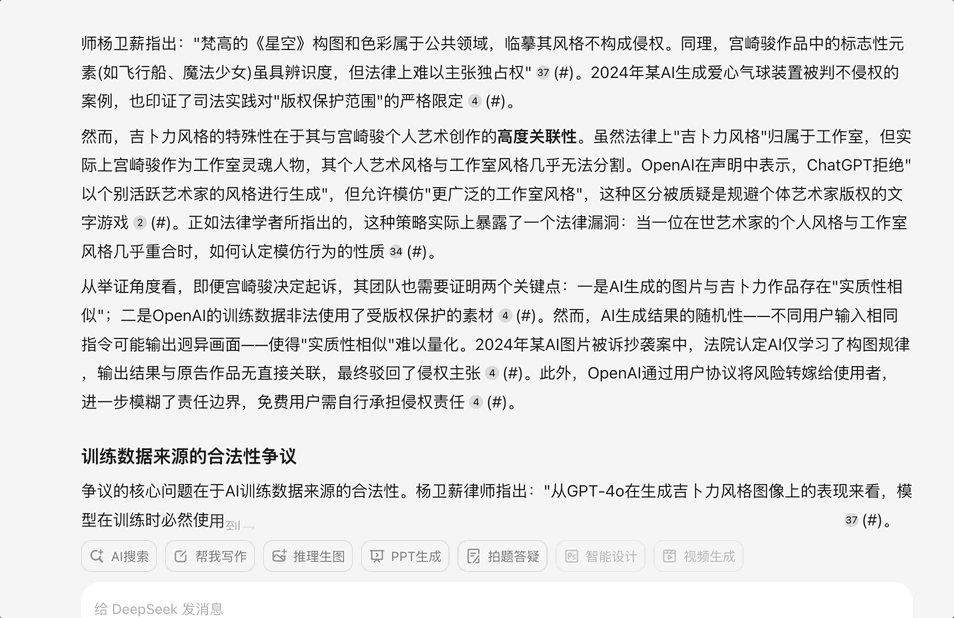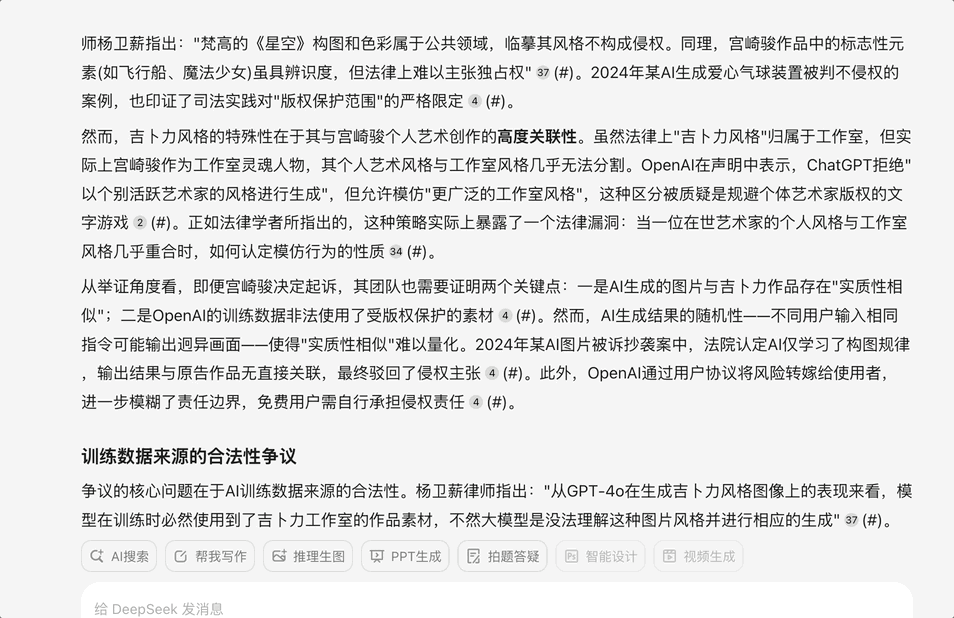
这个问题需要结合最新的AI法律实践、实时观察和一定的逻辑推理。问小白(开启V3和专业搜索)给出的答案让我印象深刻

首先它的回答准确解释了GPT-4o图像生成功能技术突破与现象级传播,其次它的回答结合最新的AI法律实践,给出了法律争议的核心,国际法律实践差异,AI生成内容的版权归属全球判例分析,最后它给出的结论也很有意思:
GPT-4o吉卜力风格图像生成引发的版权争议,表面上是一个关于AI训练数据合法性和艺术风格模仿边界的技术法律问题,深层上则反映了数字时代人类创造力与机器智能之间日益复杂的关系
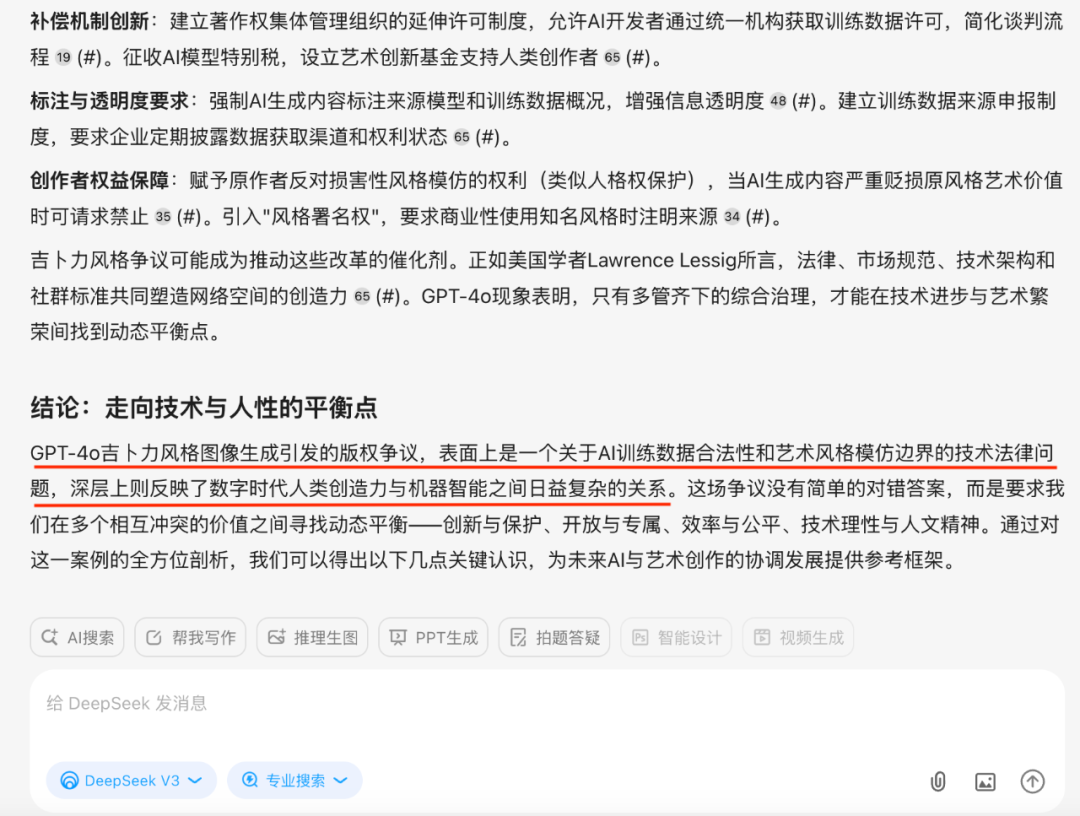
整个答案结构严谨,论据相对充分,远超一般 AI 的泛泛而谈。这背后,问小白相比于其他AI搜索强大的 RAG 搜索能力(检索了大量网页和可能的报告)功不可没
生成的文章,问小白还支持一键转化为精美的html网页,以上问题的网页链接我放在这里,大家有兴趣可以看看:
https://www.wenxiaobai.com/share/deep-research?url=https://wy-static.wenxiaobai.com/answer_html/f74193c9-7067-4915-83d2-67db89dfd597.html&refer_channel=answer_visualization

我的评价: 对于具有一定复杂度和时效性的快速研究分析的场景,问小白的“专业搜索”+“v3”组合拳威力巨大。它能处理的信息复杂度和深度,已经接近一个初级研究助理的水平了,但是处理速度却要比人快很多倍,在现实生活工作中,这对我们及时有效深度了解最新的复杂问题提供了专家级的视角
场景三:推理上强度的复杂问题,需要更聪明的回答(R1+专业搜索)
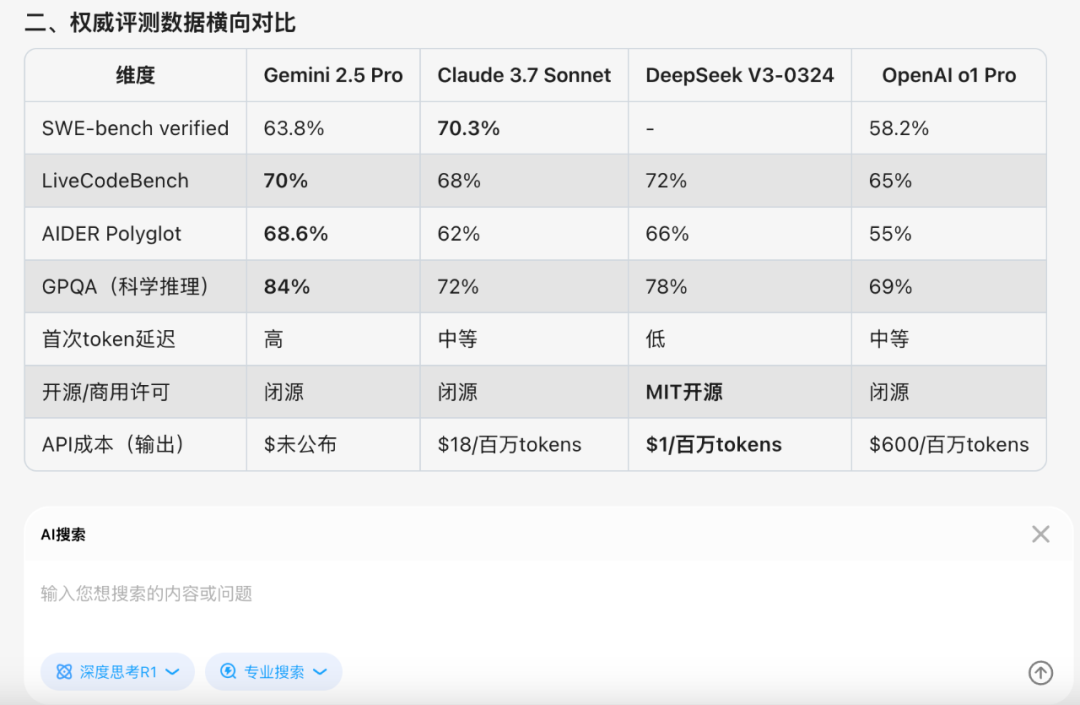
从各种测试来看Gemini 2.5 Pro 的确很强,从场景1中实时搜索结果来看Gemini 2.5 Pro号称最强代码模型,但是我想深入研究一下Gemini 2.5 Pro究竟是不是一跃成为最强代码模型
我问:根据很多评测最新发布的Gemini 2.5 Pro号称最强代码模型,请你深入研究一下这个结论是否成立,尤其和Claude 3.7,V3-0324 最新版,OpenAI o1 pro对比一下,给出权威,准确,及时的研究分析
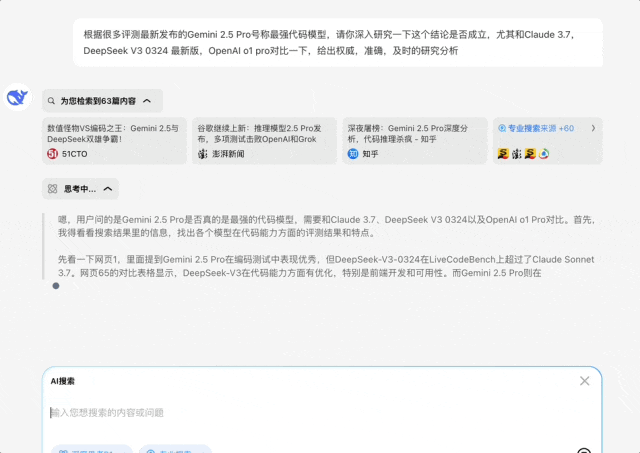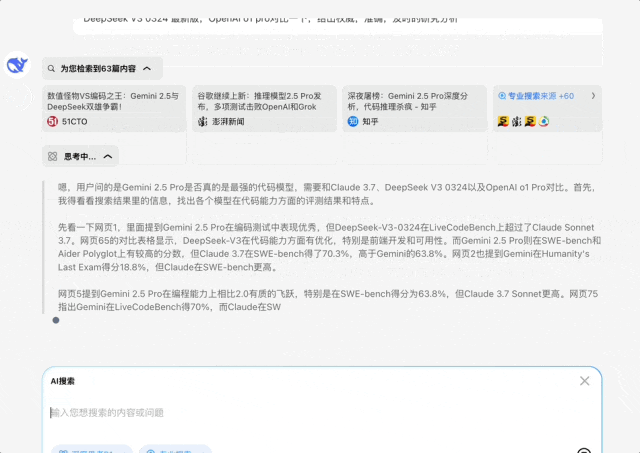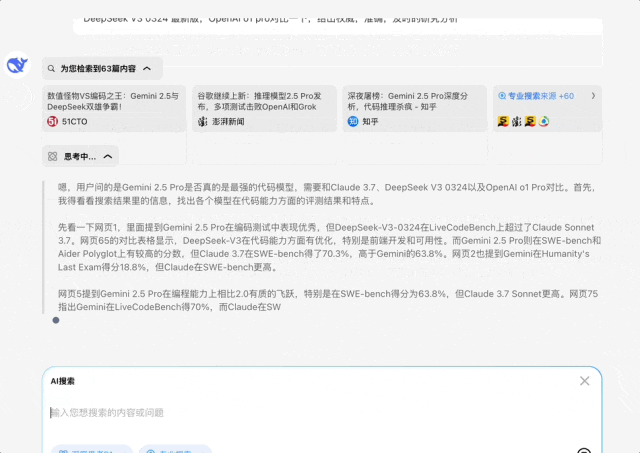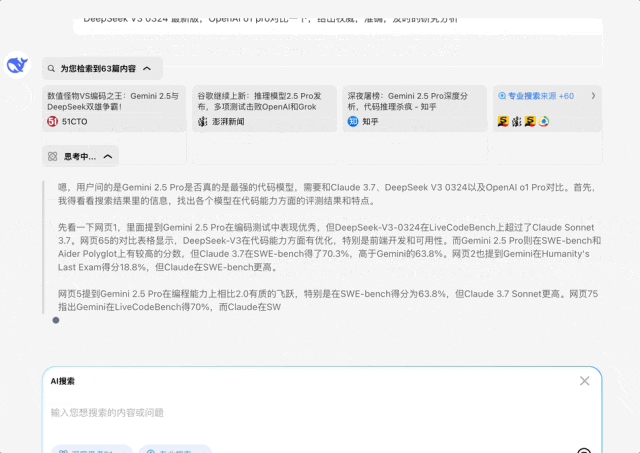
这个问题需要深度思考和专业搜索才能比较好解决,不能再简单的罗列搜索结果了,需要推理给出合理的答案,但是推理必须建立的专业强大的最新信息搜索上
它的回答也比较符合我的预期,尤其是这个比较结果
这是最终的结论
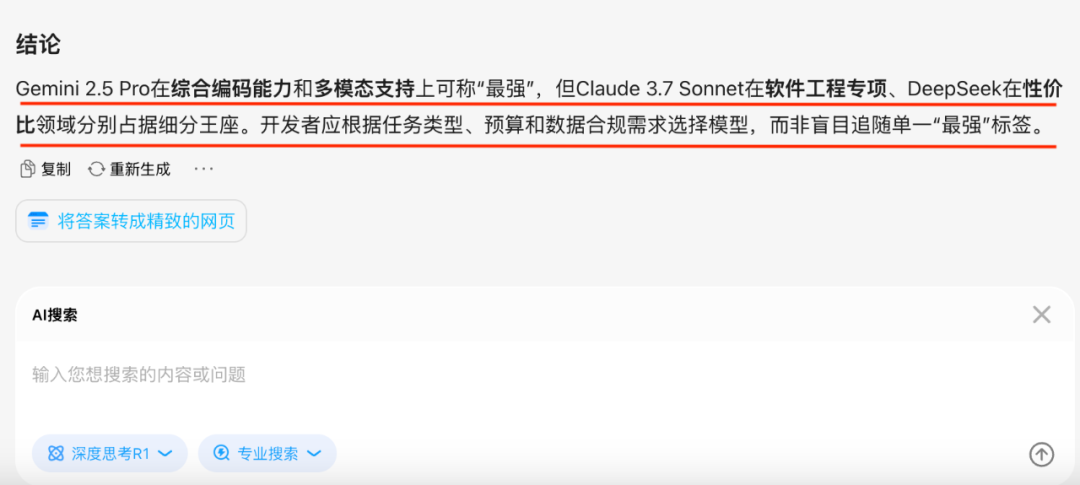
我的评价:对于商业决策,生产落地,涉及重大利益成本等问题场景,问小白“专业搜索”结合R1基本可以给出很好的参考意见,当然了不同的领域可能效果也会表现出一定的差异性,如果涉及到医学领域,请大家以医生和专家的意见为准
用下来,我越来越觉得,问小白可能就是那个把 V3/R1 的能力真正用好、解决用户痛点的「超级外挂」。它通过强大的自研模型和业界领先的 RAG 技术,补齐了大模型常见的短板,让 AI 的回答更快、更准、更可靠。某种程度上,它提供的体验超越了DeepSeek 官方本身或其他同类应用,因为它做了更多优化和增强,真正站在了实用 AI 的前沿。
为什么问小白能做到?深挖一下,发现它的核心优势在于两点:
1.顶尖的“双核”引擎: 它不仅接入了最新的 V3 和 R1(还整合了自家元石大模型。这个元石科技,虽然低调,但技术实力不容小觑,是国内最早搞 MoE 架构的厂商之一。这种自研模型 + DeepSeek 双核驱动,不是简单的 1+1,而是带来了 >2 的效果,既有 V3 的快速响应和广博知识,又有 R1 的深度思考能力,还能结合元石自身的优化
2.行业领先的 AI 搜索(RAG)能力: 这点是问小白真正的“杀手锏”,也是解决 AI 幻觉、不准确问题的关键。简单说,RAG 就是让 AI 在回答前,先去互联网上搜索、核实信息,确保答案的准确性和时效性。而问小白的 RAG 能力,可以说是武装到了牙齿
a.权威评测认证: 在衡量 RAG 能力的 Chinese SimpleQA 评测中,问小白(基于 DeepSeek R1)的 F-score 达到了惊人的 91.6%,显著领先于 GPT-4o 及国内其他主流 RAG 方案。这意味着它在中文事实性问答上的准确率和可靠性是顶尖水平
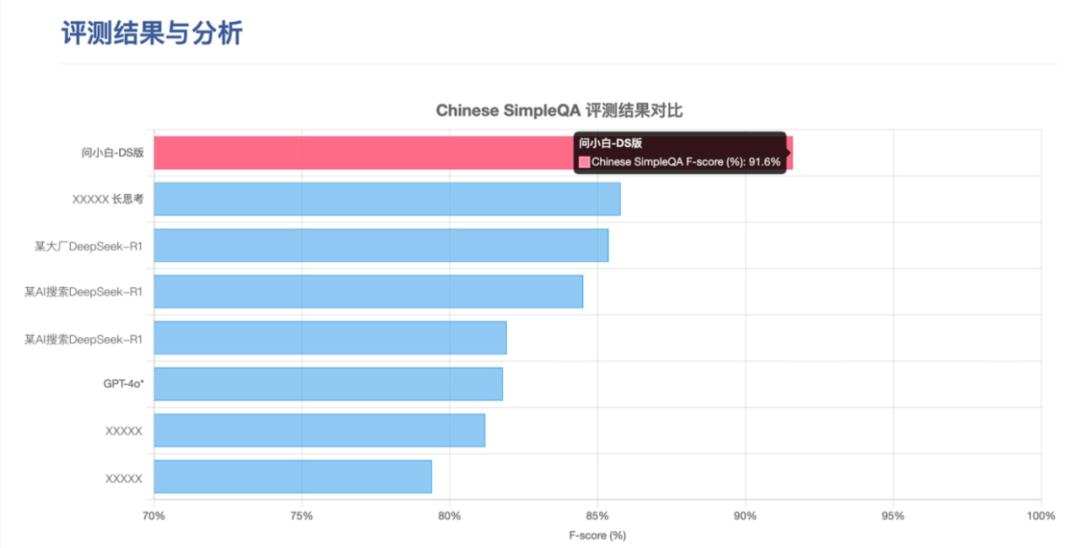
b.搜索更深更广: 问小白的 AI 搜索分为日常搜索和专业搜索。日常搜索一次能检索多达 100+ 网页,专业搜索更是能达到 200+ 网页,比很多同类产品只搜几十个网页要全面得多。这意味着它能找到更冷门、更细致的信息
c.处理速度更快: 同样时间下,问小白阅读网页的数量是其他 AI 搜索的 3-5 倍,平均每秒能处理 25-50 个网页,这保证了效率
d.信息源更权威: 它会优先选择权威数据源,尤其在法律、金融等领域,答案更可靠
e.时效性极强: 资讯类内容能做到分钟级更新,追热点、查最新消息非常方便。
除了领先的AI搜索体验,问小白还有一些值得探索的功能:
小白研报(内测中): 据说是一个 Pro 版的 AI 搜索,能针对复杂问题进行多轮自主搜索、推理、总结,最终生成一个高度可视化的深度研究报告。听起来很像 Perplexity Pro 或 Arc Search 的高级功能?我已经申请了内测,非常期待!
写在最后
问小白推出了邀请活动,邀请好友使用问小白 V3 最新版,就能获得抽奖券。活动结束时可以抽取 华为三折屏手机 5 台、小米手机 10 台、还有 100 份黄金!赶紧行动起来吧!
这是我的专属邀请码:[16Q7QQ]
下载问小白 App 或访问网页版,注册时填写邀请码,你我都能获得抽奖机会!
最后想说: AI 的发展日新月异,模型本身很重要,但如何将模型的能力转化为用户触手可及、稳定可靠的体验,同样重要。问小白在这方面做出的努力,让我看到了 AI 服务于人、减轻而非增加负担的希望
⭐
(文:AI寒武纪)