
随着模型能力的不断提升,Agent应用大量增多,如何更高效进行大模型工具调用成了关注重点。
当前,基于 JSON 或特定文本格式的 API 调用,虽然实现了 Agent 与外部环境的基础交互,但随着任务复杂度的提升,其固有的局限性日益成为瓶颈:
-
表达能力的限制: 预定义的工具集难以优雅地处理需要复杂控制流(如循环、条件分支)或数据流(变量传递与复用)的任务。这迫使 Agent 进行多次低效的 LLM 交互,或依赖外部编排逻辑。 -
工具组合的笨拙: 在不同工具间传递输出、构建动态工具链,往往需要开发者编写大量“胶水代码”,增加了开发和维护的复杂度。 -
交互效率的瓶颈: 对于需要迭代或批量处理数据的场景,重复的 API 调用显著增加了延迟和成本,限制了 Agent 的响应速度和应用范围。 -
工具管理的复杂性: 为覆盖多样化需求而不断扩展的工具集,容易导致接口泛滥,增加了认知负担和维护成本。
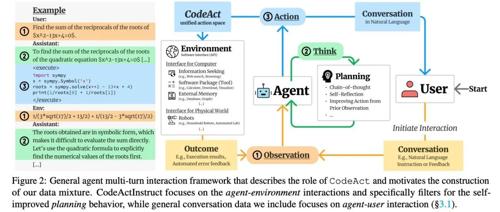
这些普遍存在的痛点,促使业界寻求一种更强大、更灵活的 Agent 行动范式。最近,爆火网络的manus团队发表论文《Executable Code Actions Elicit Better LLM Agents[1]》揭秘了他们在这方面的探索。其核心理念颇具创造性:不再让LLM选择工具,而是让它直接生成可执行的Python代码来完成任务。

CodeAct 核心理念:赋予 Agent 编写代码的能力
CodeAct 的根本出发点是,与其让 LLM 在有限的工具列表中选择,不如直接利用其强大的代码生成能力,让它产出 Python 代码来完成任务。在这里,Agent 的“动作”不再是一个原子化的 API 调用,而是一段能够被 Python 解释器执行的代码块。
这种范式的转变意味着:
-
传统模式: LLM 推理 -> 生成结构化调用指令 (JSON/Text) -> 外部解析与执行 -> 工具返回结果 -> LLM 再推理… (多轮交互) -
CodeAct 模式: LLM 推理 -> 生成 Python 代码 -> Python 解释器执行 -> 返回执行输出/错误 -> LLM 再推理… (单次交互可能包含复杂逻辑)
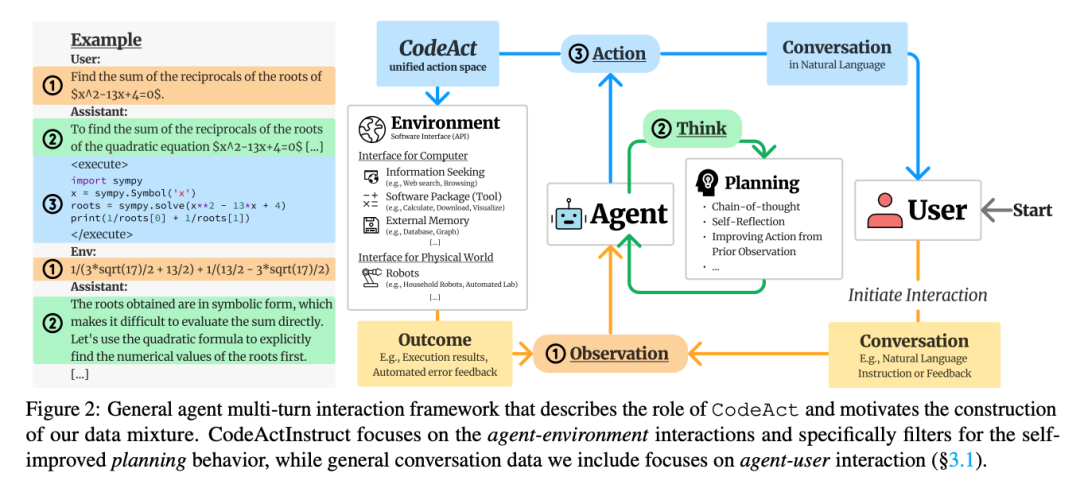
CodeAct 的关键优势:释放 Agent 的深层潜力

CodeAct 的设计并非空中楼阁,它旨在解决现实问题并发挥 LLM 的内在优势。 CodeAct 的核心优势表现在:
-
卓越的灵活性与表达力: Python 代码原生支持复杂的控制流( if/else,for/while)和数据流(变量)。这使得 Agent 能够用单一代码动作封装多步骤逻辑、工具组合和动态决策,极大地提升了处理复杂任务的能力,摆脱了固定工具集的束缚。 -
显著的效率提升: 通过在一次交互中执行更丰富的操作,CodeAct 有效减少了完成复杂任务所需的 LLM 交互轮次。CodeAct 论文在 M3ToolEval 基准上的实验数据(成功率提升达 20%,交互轮次减少高达 30%)明确佐证了这一点,这意味着更快的响应速度和更低的运行成本。 -
无缝的生态整合: CodeAct 使 Agent 能够直接利用 Python 海量的现有库(PyPI)。无论是数据处理(Pandas)、网络请求(Requests)还是机器学习(Scikit-learn,见论文图 3 示例),Agent 都可以通过简单的 import来调用成熟的功能,极大扩展了能力边界,并减少了重复封装工具的工程量。 -
内建的自省与调试机制: Python 解释器的错误反馈(Traceback)为 Agent 提供了宝贵的调试信息。CodeAct 架构支持 Agent 接收并理解这些错误,进行自主的代码修正(Self-Debugging),从而在交互中不断改进,提高了任务的鲁棒性和最终成功率。 -
与 LLM 能力的天然契合: 现代 LLM 在预训练阶段接触了大量代码数据,本身就具备较强的代码理解和生成能力。CodeAct 利用了模型的这一核心优势,让 Agent 以一种更自然、更擅长的方式进行表达和行动,而不是强制适应可能并非最优的 JSON 或文本格式。
为了方便开发者应用 CodeAct 思想,LangChain 推出了 langgraph-codeact[2] 库。该库基于强大的 LangGraph 框架(专为构建有状态、可循环的复杂 Agent 设计),提供了一套将 CodeAct 集成到 Agent 构建流程中的工具和接口。这降低了开发者尝试和部署 CodeAct Agent 的门槛。

CodeAct 的挑战与潜在风险
CodeAct 带来的强大能力是一把双刃剑,其潜在的风险不容忽视。社区的讨论(如 jc_stack 对安全性的担忧,Prometheus 对代码可靠性的质疑)也提醒我们需要保持审慎:
-
安全风险:核心关切点。 允许 LLM 生成并执行任意 Python 代码,是 CodeAct 模式最显著的风险来源。缺乏严格控制可能导致严重的安全漏洞,例如非授权的文件访问、网络攻击或系统破坏。正如 jc_stack 所强调的,健壮且精细权限控制的沙箱环境(Sandbox)是在生产环境中部署 CodeAct 的绝对前提。如何设计和实施有效的安全防护机制,将是 CodeAct 能否广泛应用的关键。 -
可靠性挑战:代码质量的保证。 尽管 LLM 的代码生成能力日益增强,但它们能否持续生成逻辑正确、没有潜在 bug 的代码,尤其是在缺乏人类监督的自主运行场景下,仍然是一个悬而未决的问题(Prometheus 的观点)。运行错误的代码可能比直接报错导致更隐蔽、更严重的问题。提升 LLM 代码生成的准确性、可靠性,以及发展有效的代码验证和修正机制,至关重要。
尽管面临挑战,CodeAct 所展现的前景依然广阔,有望在多个领域催生新的应用范式:
-
复杂工作流自动化: 在金融科技(DeFi)、商业智能、自动化报告等领域,CodeAct 能将数据查询、处理、计算、可视化等步骤有效串联,实现更高级别的端到端自动化。 -
交互式数据科学: Agent 可直接操作 Pandas、NumPy、Matplotlib 等库,辅助数据科学家进行探索性分析、建模和结果呈现。 -
动态环境适应: 在需要根据实时反馈调整策略的任务中(如网页自动化、软件测试),CodeAct 的灵活性将使其表现出色。 -
科学计算与研究: Agent 有潜力调用专业计算库,参与模拟、数据分析甚至实验流程的设计。
相较于其他 Agent 框架(如TaskWeaver),CodeAct 的核心差异化在于其对原生 Python 代码执行的侧重、对多轮交互中错误反馈自调试机制的深度集成,以及对庞大 Python 生态的直接利用。
小结
在当前MCP爆火的时间点,CodeAct是进一步深度的探索,能够更加充分发挥模型的能力,并降低工具调用的繁琐性。AI生产工具再使用工具的模式,相较于人类来讲有得天独厚的优势。 Agent 从被动的“工具执行者”,向能够理解复杂指令、自主规划并用代码创造性解决问题的“智能协作者”演进。从这个角度讲,按此方式迭代,也能够摆脱应用和模型的边界冲突,模型越强应用越强,摆脱被模型吞噬的魔咒。
参考资料
Executable Code Actions Elicit Better LLM Agents: https://arxiv.org/pdf/2402.01030
[2]langgraph-codeact: https://github.com/langchain-ai/langgraph-codeact
(文:AI工程化)