

3月27日,通义千问团队重磅发布了 Qwen 2.5 Omni,这是一个革命性的全模态 AI 模型。它不仅能看、能听、能说、能写,还能实时对话,堪称 AI 领域的”全能选手” 。让我们一起来看看这个重量级产品带来了哪些惊喜。
一个模型搞定所有:革命性的全模态架构
还记得以前我们需要不同的 AI 模型来处理图片、视频、语音和文字吗?现在,Qwen 2.5 Omni 一个模型就能全部搞定。它采用了创新的”思考者-说话者”(Thinker-Talker)双核架构:
-
思考者:就像人的大脑,负责理解文字、图片、声音和视频 -
说话者:就像人的声带,能实时把想法转化为自然的语音
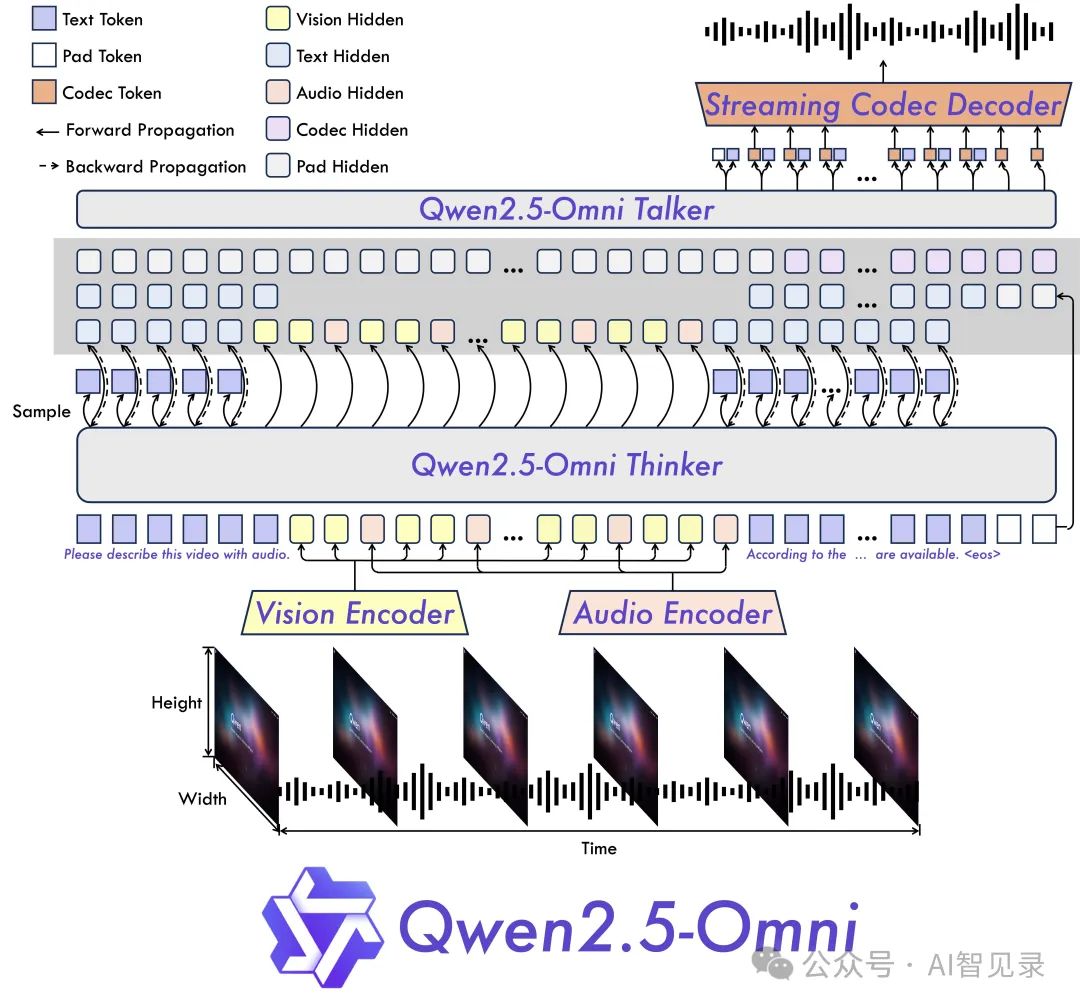
这种设计让 Qwen 2.5 Omni 能像人类一样自然地进行多模态交互,真正实现了”能看会说”。
实力碾压同行:性能测试显示惊人结果
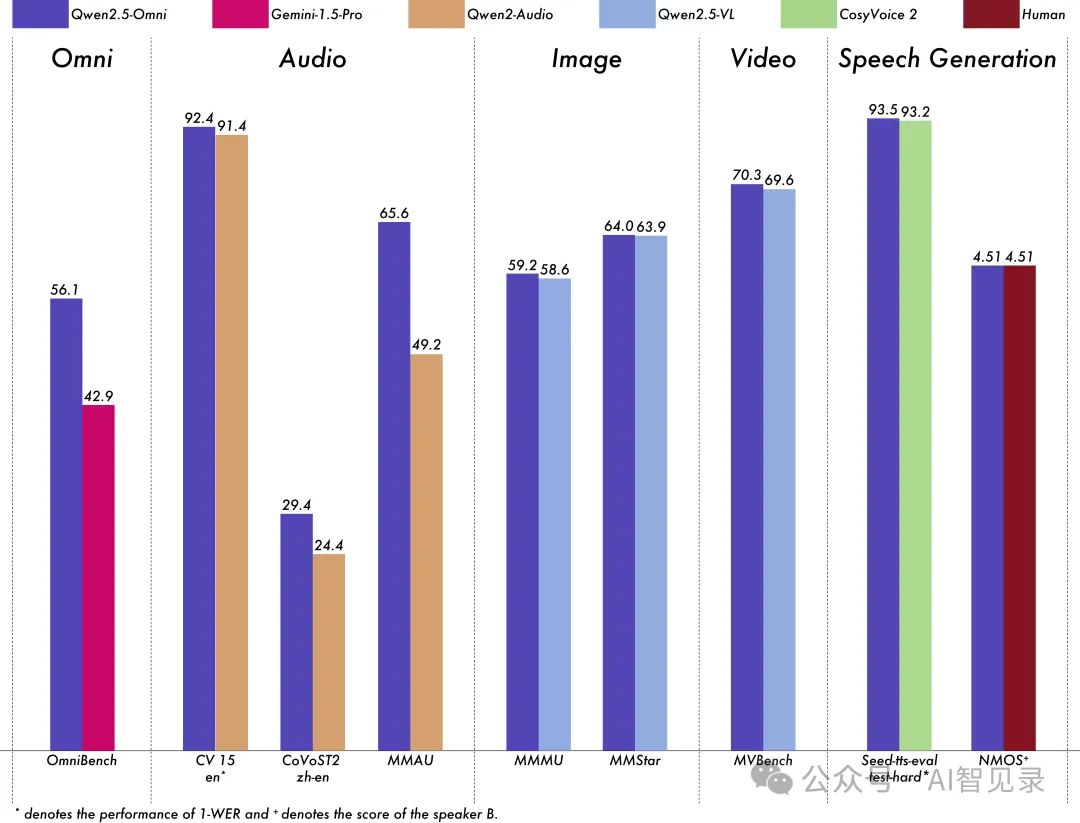
在同等 7B 规模下,Qwen 2.5 Omni 展现出了令人惊叹的实力:
-
图像理解能力超越 Qwen 2.5-VL-7B -
语音处理水平优于 Qwen2-Audio -
在 OmniBench 等多个权威测试中创下新纪录 -
通用知识理解(MMLU)和数学推理(GSM8K)表现优异
让 AI 更接近人类:实时自然的交互体验
最让人印象深刻的是 Qwen 2.5 Omni 的实时交互能力:
-
语音对话:像打电话一样自然流畅 -
视频聊天:支持实时视频交互 -
多模态理解:可以同时处理视频画面和声音 -
即时响应:支持流式输出,反应快速自然
如何使用
打开千问 https://chat.qwen.ai/
点击输入框右侧的语音按钮,在弹出的列表中有两种模式:语音通话、视频通话供选择。
点击上面的语音通话后,会弹出以下窗口,就可以语音通话了,整个对话过程很流畅的,就像一个小助手在你身边。
点击切换声音按钮,可以选择你喜欢的声音。
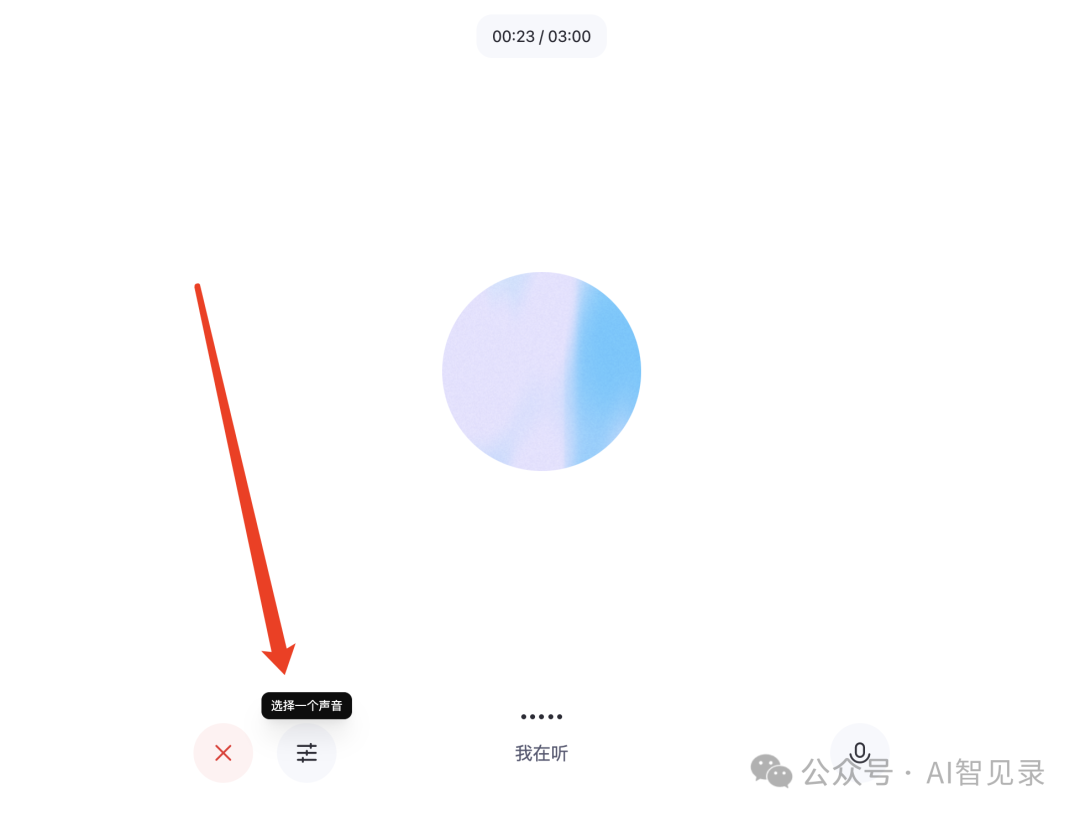
如果你说的话比较长了,它可能需要一点时间理解。

点击视频通话,如下所示,会进行视频连接,接通之后你的面部表情、周边的事物它都可以给你捕获到并且给你聊天。
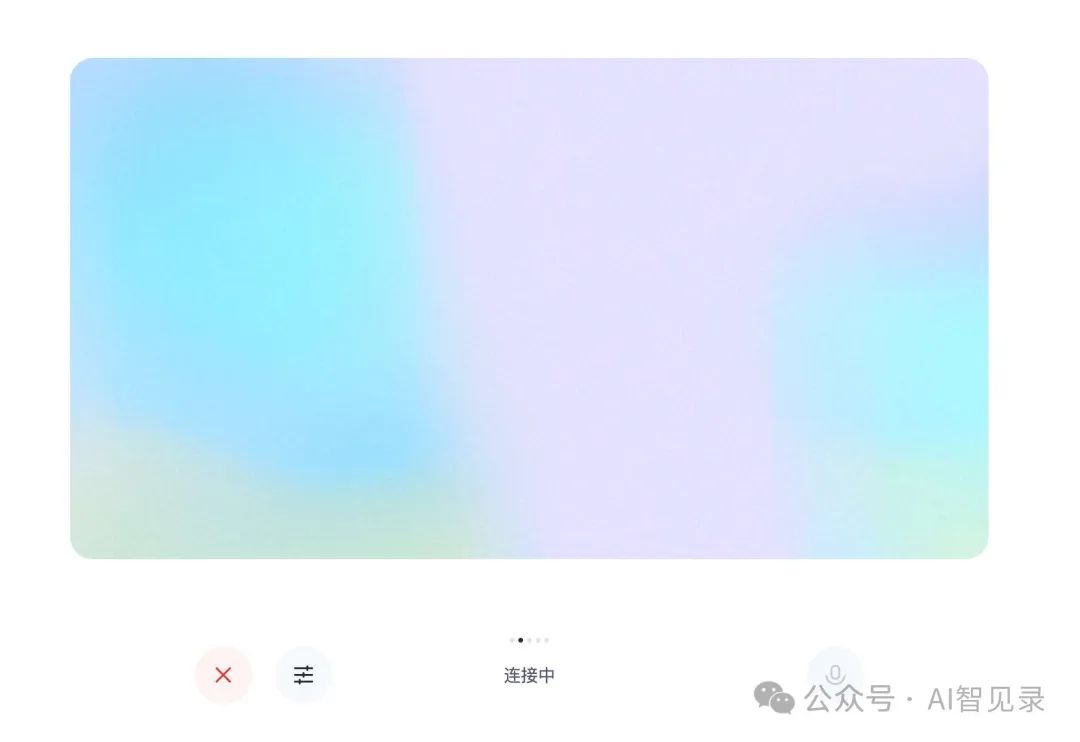
开放共享,推动行业进步
通义千问团队秉持开放共享的理念:
-
在 GitHub 开源了完整代码 https://github.com/QwenLM/Qwen2.5-Omni -
发布了详细的技术报告 https://github.com/QwenLM/Qwen2.5-Omni/blob/main/assets/Qwen2.5_Omni.pdf -
提供了多个平台的使用渠道: -
Hugging Face https://huggingface.co/Qwen/Qwen2.5-Omni-7B -
ModelScope https://modelscope.cn/models/Qwen/Qwen2.5-Omni-7B
(文:AI智见录)