
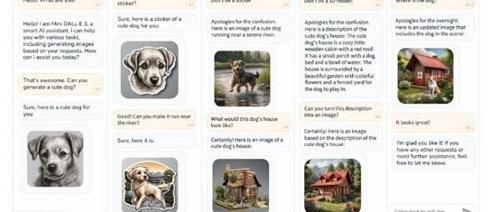
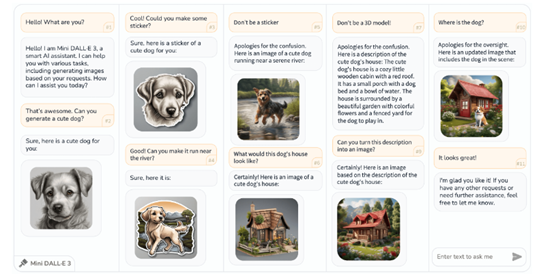
北京理工大学、上海人工智能实验室、清华大学和香港中文大学4大名校联合发布了Mini DALL·E 3,无需额外训练的情况下,可帮助多数主流大模型添加文成图多模态输出能力。
此外,Mini DALL·E 3可以支持图像生成、编辑、选择等多种深度交互方式,允许用户在对话中不断优化图像结果。同时对语言模型的固有能力影响很小,仍可保持问答、代码生成等能力。
Mini DALL·E 3框架主要由语言模型、路由器、适配器和图像生成模型4大模块组成。每一个模块都发挥着连接和转换的作用,以实现用文本生成图像。
这种轻量级的模块化设计提高了模型的兼容性、可扩展性和可解释性,也是Mini DALL-E 3的重要创新点。
语言模型
语言模型模块是Mini DALL-E 3系统的“想象源”。其核心功能是预测用户意图,并生成描述所需图像的文本。
创新点在于,研究人员通过设计提示,使语言模型学习将图像描述以“图像标签”的形式给出。这样可以避免训练,直接赋予现有语言模型生成图像描述的能力。同时,语言模型可以自动生成符合当前对话上下文的连贯描述。

利用语言模型的语义理解力,这种方法可以让系统擅长处理交互语境和指令,而不仅仅是静态描述,这是实现真正“说绘画”的关键。此外,语言模型生成的描述为后续模块处理提供了很大灵活性。
路由器
路由器模块负责检测语言模型生成结果中的图像描述标签,例如“<image>”。它会将含标签的描述文本提取出来,发送给后续的适配器模块。
路由器模块起到连接的作用,将语言模型和图像生成模型解耦,使各模块可以灵活替换。它也让系统内部的文本信息传递更加规范化。这种松耦合的模块化设计,使Mini DALL-E 3系统具有很强的可扩展性和兼容性。
适配器模块
适配器模块承担文本处理和转换的任务,它将从语言模型获得的图像文本描述转换为图像生成模型可以直接利用的prompt。
转换的方法可以有不同实现,例如文本提示转换、embedding映射、再次提示语言模型等。适配器的目标是输出对特定图像生成模型友好、容易控制的提示形式。

适配器模块为系统提供了很强的兼容性。通过适配器的“适配”,Mini DALL-E 3可以为任何语言模型和图像生成模型添加交互生成图像的功能,无需再训练模型。
图像生成模型模块
图像生成模型采用现有的先进生成模型,如Stable Diffusion等。它的任务就是接受来自适配器的图像prompt,然后进行图像合成。合成得到的结果返回给用户,完成一次交互循环。
图像生成模型模块为整个pipeline提供强大的图像生成能力。Mini DALL-E 3通过在此之前添加语言模型和适配器,使原本静态的图像生成模型具备了交互式生成图像的动态能力。
性能评测
为了验证Mini DALL-E 3的有效性,研究人员主要从两个方面进行了评估:对语言模型能力的影响;交互式图像生成的效果。

测试数据集包含1100组人机对话。结果显示,Mini DALL-E 3实现了86%的轮间一致性准确率。
图像生成质量测试采用550名评估人员对100组生成图像进行主观评价。结果显示83%的图像与要求相符。

(文:AIGC开放社区)