


DeepSeek-R1 模型以其卓越的性能在自然语言处理领域引起了广泛关注,其基于 R1 蒸馏数据进行 SFT(Supervised Fine-Tuning)的小模型也展现出了强大的效果。前段时间,大佬“刘聪NLP”开源了中文 DeepSeek-R1(满血)蒸馏数据集,包括 SFT 版本和普通版本。这一数据集的发布,迅速吸引了众多研究者和开发者的目光,并成功登上了 HuggingFace Trending 榜。基于这份数据集,我们有机会复现 R1 蒸馏模型的效果,进而训练出属于自己的中文版推理模型,为中文自然语言处理领域的发展贡献一份力量。
一、数据集
作者开源这个数据集的初衷,主要是为了弥补DeepSeek-R1蒸馏中文数据集匮乏,同时也是为了帮助大家更好地复现R1蒸馏模型的效果,特此开源中文数据集。
中文基于满血 DeepSeek-R1 蒸馏数据集– 110k-SFT 版本地址如下:
https://modelscope.cn/datasets/liucong/Chinese-DeepSeek-R1-Distill-data-110k-SFT
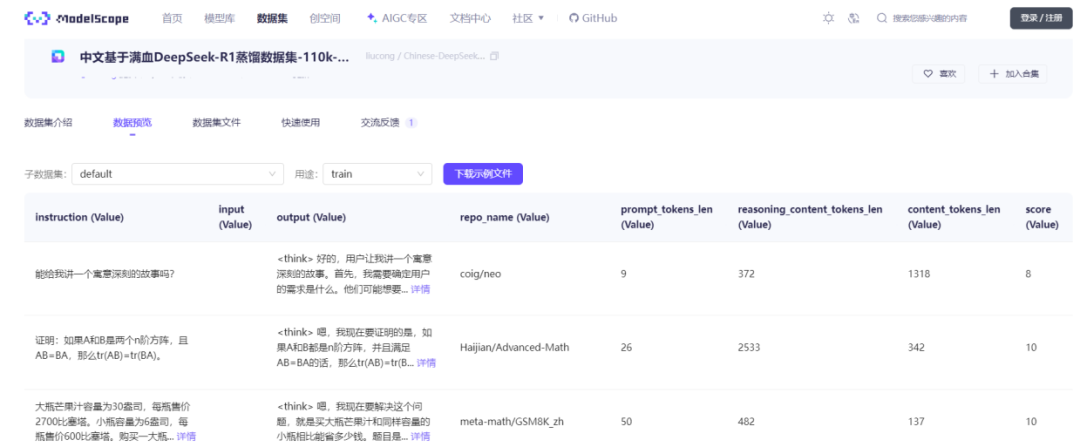
本数据集为中文开源蒸馏满血R1的数据集,数据集中不仅包含math数据,还包括大量的通用类型数据,总数量为110K。
该中文数据集中的数据分布如下:
-
Math:共计36568个样本,
-
Exam:共计2432个样本,
-
STEM:共计12648个样本,
-
General:共计58352,包含弱智吧、逻辑推理、小红书、知乎、Chat等。
二、环境准备
(一)安装 ms-swift
我们选择基于 ms-swift 来进行模型的微调训练。ms-swift 是一个功能强大的开源工具,它支持使用 PEFT(Parameter-efficient Fine-Tuning)或全参数微调的方式,对 450 多种大型语言模型(如 Qwen2.5、InternLM3、GLM4、Llama3.3、Mistral、Yi1.5、Baichuan2、DeepSeek-R1 等)以及 150 多种多模态语言模型(如 Qwen2.5-VL、Qwen2-Audio、Llama3.2-Vision、Llava、InternVL2.5、MiniCPM-V-2.6、GLM4v、Xcomposer2.5、Yi-VL、DeepSeek-VL2、Phi3.5-Vision、GOT-OCR2 等)进行微调,极大地拓展了模型的应用范围和适应性。
安装 ms-swift 的具体操作如下:
# 克隆 ms-swift 仓库git clone https://github.com/modelscope/ms-swift.gitcd ms-swift# 安装 ms-swiftpip install -e .
安装完成如下:
(二)安装 vllm
在模型推理阶段,为了提升推理效率,我们采用 vllm 框架进行推理加速。vllm 是一款专为大语言模型推理设计的高性能、灵活且易于部署的框架。它通过优化的内存管理和高效的调度算法,能够显著提高模型的推理速度,使模型的响应更加迅速,尤其适用于需要高效处理大模型的场景。
安装 vllm 的命令如下:
pip install vllm安装完成如下:
(三)安装deepspeed
DeepSpeed 是一个用于大规模深度学习训练的高效优化库,通过并行化、内存优化和混合精度等技术,显著提升训练效率、降低硬件需求并优化资源利用率。
安装 deepspeed的命令如下:
pip install deepspeed安装完成如下:
三、模型推理(微调前)
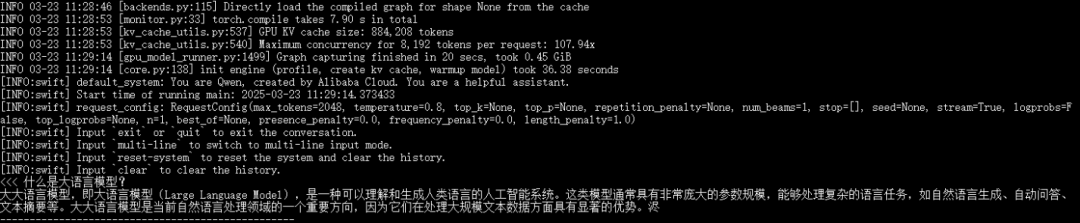
现在微调训练前,进行推理测试一下,方便后面对比微调后的效果
CUDA_VISIBLE_DEVICES=0 \swift infer \--model /root/autodl-tmp/Qwen/Qwen2.5-1.5B \--stream true \--infer_backend vllm \--max_model_len 8192 \--max_new_tokens 2048 \--temperature 0.8
推理效果如下:
四、模型准备
为了进行微调,我们需要准备一个预训练模型作为微调的对象。在这里,我们选择使用 modelscope 中的 snapshot_download 函数来下载所需的预训练模型。在开始之前,请确保已经提前安装了 modelscope,安装命令为:’pip install modelscope’;接下来,在 `/root/autodl-tmp` 路径下新建一个名为 `download.ipynb` 的文件,并在其中输入以下代码:
# 模型下载from modelscope import snapshot_downloadmodel_dir = snapshot_download('Qwen/Qwen2.5-1.5B', cache_dir='/root/autodl-tmp', revision='master')
下载完成如下:
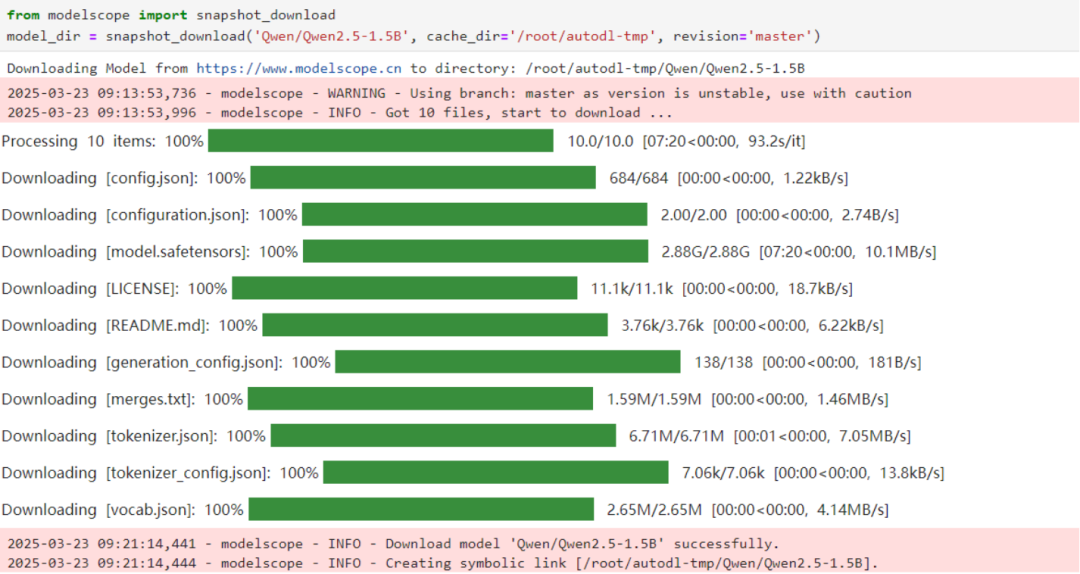
运行上述代码后,模型将被下载到指定的路径。下载成功后,`model_dir` 中会存放模型的本地路径,方便后续的微调操作。
五、模型微调
以下是微调脚本的示例代码:
nproc_per_node=2CUDA_VISIBLE_DEVICES=0,1 \NPROC_PER_NODE=$nproc_per_node \swift sft \--model /root/autodl-tmp/Qwen/Qwen2.5-1.5B \--train_type full \--dataset 'liucong/Chinese-DeepSeek-R1-Distill-data-110k-SFT#500' \--torch_dtype bfloat16 \--num_train_epochs 1 \--per_device_train_batch_size 1 \--per_device_eval_batch_size 1 \--learning_rate 1e-5 \--gradient_accumulation_steps $(expr 16 / $nproc_per_node) \--eval_steps 50 \--save_steps 50 \--save_total_limit 5 \--logging_steps 5 \--max_length 8192 \--output_dir output \--warmup_ratio 0.05 \--dataloader_num_workers 4 \--deepspeed zero2
在上述脚本中,我们设置了一些关键的参数,以确保微调过程的顺利进行:
`–model` 参数指定了预训练模型的名称;
`–train_type`指定训练类型,full 表示进行全量训练;
`–dataset` 参数指定了用于微调的数据集;
`–torch_dtype` 参数设置了模型的精度类型为 bfloat16,以在保证性能的同时降低计算资源的消耗;
`–num_train_epochs` 参数定义了训练的总轮数;
`–per_device_train_batch_size` 和 `–per_device_eval_batch_size` 参数分别设置了每个设备在训练和评估阶段的批量大小;
`–learning_rate` 参数设置了学习率;
`–gradient_accumulation_steps` 参数用于梯度累积,以在有限的硬件资源下实现更大的有效批量大小;
`–output_dir` 参数指定了微调模型的输出路径;
`–deepspeed zero2` 参数启用了 DeepSpeed 的 ZeRO-2 级优化,以进一步提高训练效率和内存利用率。
注意:很多参数设置的比较小,是为了减少GPU和训练时间实;际训练中需要加大`–dataset`、`–num_train_epochs`、per_device_train_batch_size` 和 `–per_device_eval_batch_size`等参数 。
训练完成截图如下:
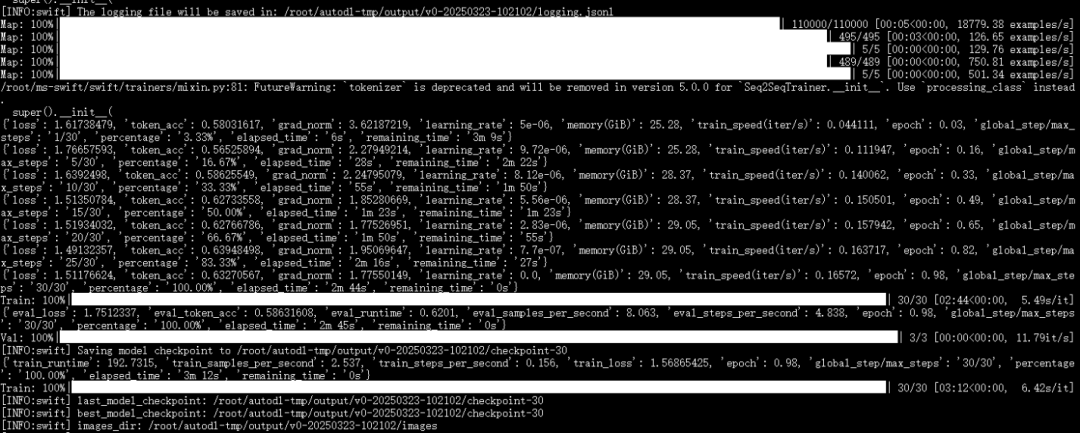
六、模型推理(微调后)
完成模型微调后,我们将基于微调产生的权重文件进行推理测试。以下是推理命令的示例:
CUDA_VISIBLE_DEVICES=0 \swift infer \--model /root/autodl-tmp/output/v0-20250323-102102/checkpoint-30 \--stream true \--infer_backend vllm \--max_model_len 8192 \--max_new_tokens 2048 \--temperature 0.8
在推理命令中:`–model` 参数指定了微调后的模型路径;`–stream` 参数设置为 true,表示启用流式推理,以实时输出推理结果;`–infer_backend` 参数指定了推理后端为 vllm;`–max_model_len` 参数设置了模型的最大输入长度;`–max_new_tokens` 参数定义了生成的新 token 的最大数量;`–temperature` 参数用于控制生成结果的随机性,数值越低,生成结果的确定性越高。
推理效果:
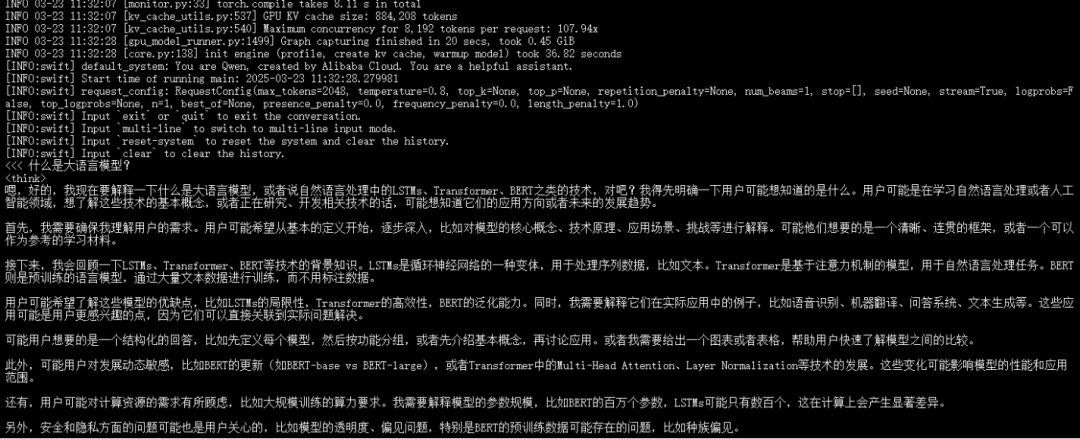
注意:如上图推理链路虽然出来了,太整体效果还是不太行;实际应用中我们再微调时需要指定更多的训练数据集,需要更大训练轮次。
总结
通过上述步骤,我们成功地利用开源的中文 DeepSeek-R1 蒸馏数据集,复现了 R1 蒸馏模型的效果,并训练出了自己的中文版推理模型。这一过程不仅展示了开源数据集和开源工具的强大潜力,也为中文自然语言处理领域的研究和开发提供了一个实用的参考案例。未来,我们可以进一步探索如何优化模型的微调策略和推理性能,以更好地满足实际应用中的需求,推动中文自然语言处理技术的不断发展和创新。
(文:小兵的AI视界)