
Llama 4 发布了。
https://huggingface.co/meta-llama

但这次,它没有高调宣称参数量“遥遥领先“,而是通过三款模型来重新布局:
-
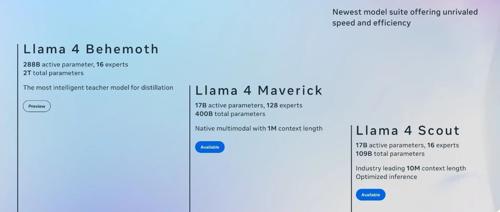
• Scout:109B 参数,17B 激活,16 专家 MoE,可部署在单张 H100 上,10M token 长上下文,适用于文档分析、多轮对话、代码等任务 -
• Maverick:400B 参数,17B 激活,128 专家 MoE,1M token 长上下文:400B 参数,128 专家,推理仅激活两个。对标 GPT-4o,性能不逊色,推理成本仅为其十分之一 -
• Behemoth:2T 参数,288B激活,16 专家 MoE,不部署、不开放,仅用于训练阶段,为 Scout 和 Maverick 生成训练数据
一个用、一主力、一教学,不卷彼此,也不试图通吃所有任务。
讲道理,看这个发布的时候,我总隐隐有当时读 DeepSeek V3 技术报告的感觉:拥抱 MoE,拥抱合成数据
架构转向:MoE 登上主舞台
Lllma 3 是 Dense,哪怕 400B 的模型都是 Dense;而 Llama 4 是 MoE 架构。
(关于架构的问题,推荐阅读:「大,就聪明吗?」)
过去,MoE 更多还是“实验室选项”,自 DeepSeek 大火后,很多厂商开始尝试将其用于主力模型,比如这次的 Meta。在 Llama 4 中,模型 Scout 配置 16 专家,而 Maverick 则是 128 专家,推理时都只激活两个,17B的量。
回顾一下,DeepSeek 在 R1 和 V3 中也是类似:671B 总参数,37B 激活,用更可控的计算开销,换来模型能力密度的提升。
当然,得说一下,MoE 并不适合所有任务场景,也存在调度复杂、专家平衡等训练难题。但它至少打开了一个现实维度:参数使用方式,和参数数量本身一样值得被设计。
多模态:从外挂走向原生
Llama 3 时代,图像输入依赖外挂 encoder,与语言模型拼接;Llama 4 时代,图像直接作为 token 输入,参与语言上下文建模。
这意味着:图文不是模型之后拼出来的,而是在训练中就一体建模的语境单位。
这种结构带来的提升,在任务表现中非常直接:
-
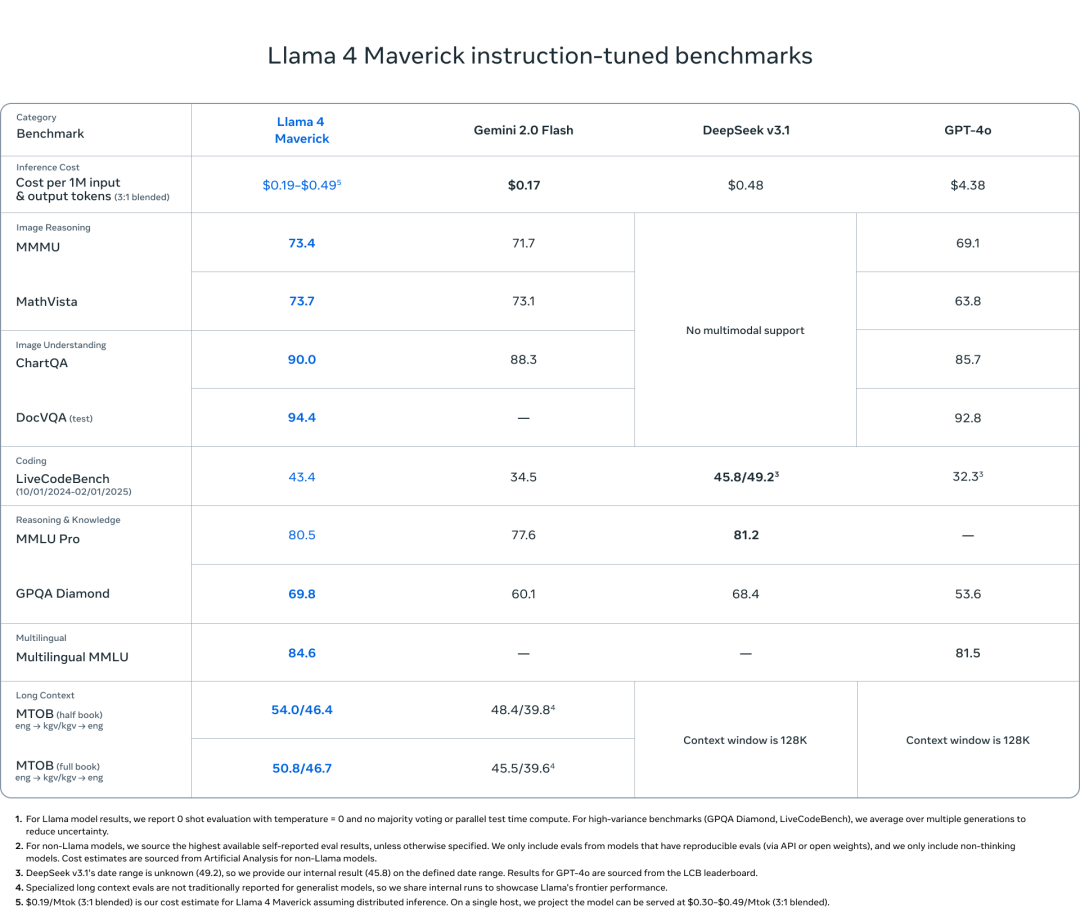
• Maverick 在 DocVQA 拿下 94.4,超过 GPT-4o(92.8) -
• ChartQA 达到 90.0,MathVista 73.7,均高于 GPT-4o -
• 推理成本却仅为 GPT-4o 的十分之一
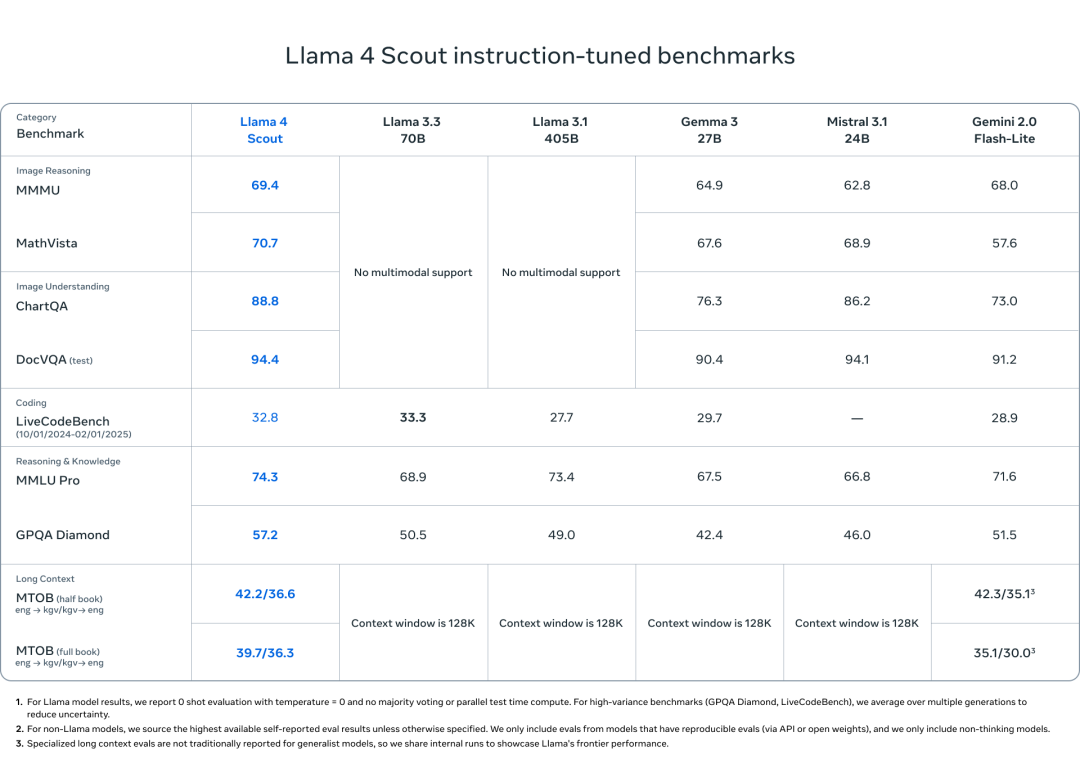
而原生多模态架构也体现在 Scout 身上——虽然是轻量模型,但在 DocVQA、ChartQA 上,Scout 依然打出了高于同尺寸模型(甚至部分大模型)的稳定表现。
此处说一下, DeepSeek 的 V3/R1 仍未引入图像 token
训练转向:大模型是过程
Behemoth 最大号的 Llama4,很强,但它不对外。
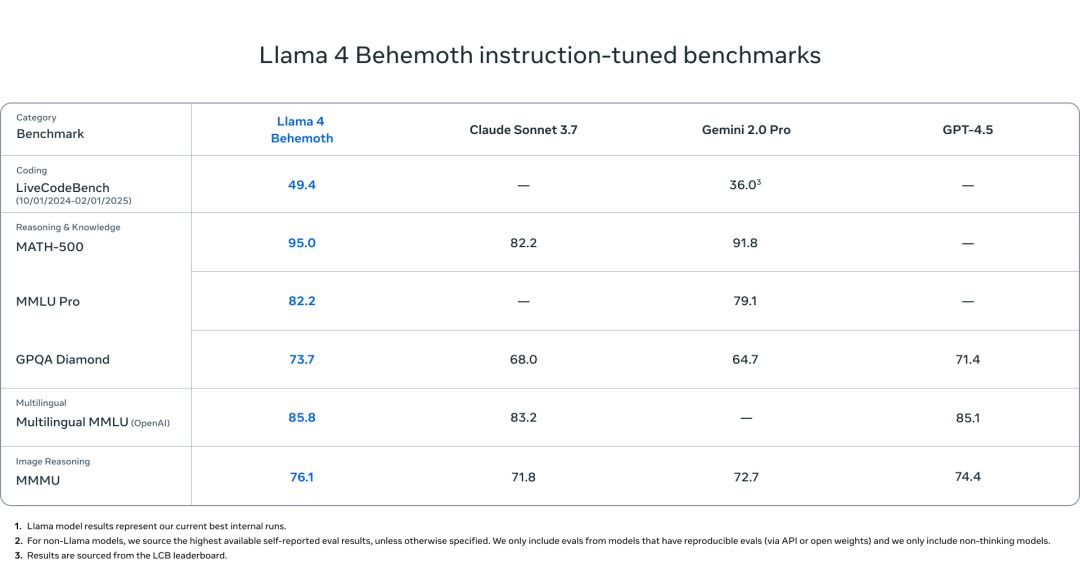
Behemoth的全部作用,是生成训练数据,为 Scout 和 Maverick 提供能力示范,并通过轻量 DPO 和 RLHF 进一步优化行为。换句话说,Meta 并不再执着于“最强模型”上线,而是选择把最大资源投入到训练系统本身。
这个事儿,有点像:
-
• OpenAI 开发了「草莓」,来训练新的 GPT -
• DeppSeek 开发了 DeepSeek-R1-Light 来训练 DeepSeek V3

不是封神,而是转向
在我看来,Llama 4 并没有带来参数最大、能力最强的单点突破。但它用一个更完整、更分工明确的体系,回应了模型设计正在发生的变化:
Scout 是部署,Maverick 是交付,Behemoth 是理解力的源头
与其说是一次产品发布,更像是宣告一次路线调整。
(文:赛博禅心)