

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
根据AI发展科研机构Epoch AI公布的关于大模型消耗训练数据的研究报告显示,人类公开的高质量文本训练数据集大约有300万亿tokens。
但随着ChatGPT等模大型的参数、功能越来越强以及过度疯狂训练,对训练数据的需求呈指数级增长,预计最快将在2026年消耗完这些数据,而合成数据成为最有效的替代方案。
卡内基梅隆大学、谷歌DeepMind和MultiOn的研究人员联合发布了一篇论文,来研究合成数据对训练大模型的价值。

为了发现合成数据的不同能力,研究人员提出了正面和负面两种数据类型。正面数据,即正确的问题解决方案,通常是GPT-4、Gemini 1.5 Pro等高性能大模型生成的数据,为大模型提供了正确的示例,以便学习如何解决类似的数学等问题。
仅仅依赖正面数据进行训练,虽然能够提供适度的性能提升,但这种方法存在两大局限性:1)可能无法充分揭示问题解决过程中的内在逻辑,因为模型可能仅仅通过模式匹配而非真正理解来学习解决问题。
2)随着训练数据量的增加,模型可能学会依赖一些偶然出现的错误关联或非本质特征,这导致了模型泛化能力的降低,尤其是在处理新颖问题时这一情况就越发明显。
所以,又提出了负面数据类型,这是一种被最终答案验证器判定为错误的数据,为模型提供了学习避免错误的机会。错误的解题步骤能揭示模型在推理过程中的缺陷,促使模型学习如何避免这些错误,进而增强其逻辑推理能力。前段时间国内非常火爆的“弱智吧”数据就是属于这一类型。
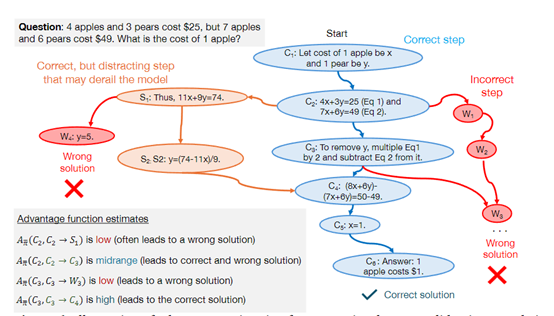
但是想有效利用负面数据也并不容易,因为错误的步骤可能包含误导性的信息,如果未经恰当处理,反而可能加剧模型的错误学习。
研究人员则使用了DPO(直接偏好优化)方法进行了优化,帮助模型从错误中学习,同时强调每个解题步骤的重要性。

通过对比正面和负面数据,DPO能够为每个解题步骤分配一个优势值,这个值反映了该步骤相对于理想解法的相对价值。
高优势值意味着该步骤在正确解题路径中是关键的,而低优势值则可能指向了模型推理过程中的问题所在。利用这些优势值,模型可以通过强化学习的方式动态调整其策略,以更高效地学习和改进合成数据。
为了测试正面和负面合成数据的性能,研究人员用DeepSeek-Math-7B、LLama2-7B等模型,在GSM8K、 MATH数据集上进行了综合测试。
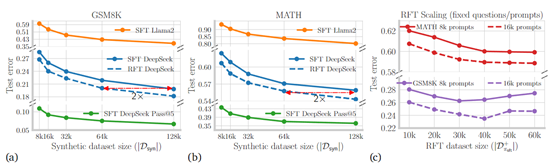
结果显示,经过正面和负面合成数据预训练的大模型,在数学推理任务上的性能与仅使用正面数据相比,性能提升了8倍。这表明在强化学习框架下,大模型通过纠正错误并从中学习,能够更加有效地掌握数学逻辑和问题解决技巧。
(文:AIGC开放社区)