
一开始听到“知识图谱(Knowledge Graph)”这个词,确实有点让人望而生畏——不是概念本身,而是构建它的过程。
我之前尝试过做一个知识图谱,但失败了。
图这种数据结构,确实是表达复杂关系最好的方式之一,广泛应用于推荐系统、欺诈检测等等。但最吸引我兴趣的,其实是信息检索。
于是我开始探索,如何利用知识图谱来构建更强大的RAG系统。
当然,RAG并不一定非得依赖知识图谱,它甚至都不需要数据库。只要你能从海量信息中提取出相关内容,并传递给大语言模型(LLM)的上下文,RAG就可以正常工作。
比如你可以用网页搜索作为RAG的检索手段,也可以用向量数据库来进行语义搜索。
如果你选择用图数据库来检索上下文信息,那我们通常会称之为“GraphRAG”。
不过本文并不是要讲GraphRAG(也许将来会专门写一篇),而是聚焦在:如何利用LLM来构建知识图谱。当然,在这之前我们还是得提一下,为什么知识图谱能让RAG更强大。
为什么RAG要用知识图谱?
知识图谱在检索更相关信息方面,确实有它的独门技巧。虽然向量数据库在多数情况下已经够用了,但它也不是万能的。
向量数据库的核心检索方式,是基于文本的“语义相似度”。它大致的流程是这样的:
我们用一个向量嵌入模型(比如 OpenAI 的 text-embedding-3)把文本转成向量。比如“Apple”和“Appam”(一种印度食物)虽然字母有重叠,但它们转成向量后,在语义空间中的距离就很远了。然后这些向量会被存进一个像Chroma这样的向量数据库。
到了检索阶段,我们再用同一个嵌入模型把用户的查询转成向量,然后用余弦相似度之类的方式计算距离,找出最相似的内容返回。
这就是目前我们用向量数据库检索信息的唯一方式。你可能已经意识到,模型选得好不好直接影响检索的质量。而数据库本身反而不是主要问题(当然,并发、速度这些是另说)。
来看一个例子:
假设你有一个超大的文档,介绍了很多公司的高管团队。
对于“John Doe 先生是哪个公司CEO?”这种简单问题,向量搜索能给出很准确的答案,因为答案往往就包含在被嵌入的某个文本块中。
但如果你问的是,“有哪些人和 John Doe 一起担任多个董事会成员?”这种问题,就超出了普通向量搜索的能力范围了。
原因在于,向量检索只能处理明确提到的信息,而无法进行跨多个信息源的综合推理。而知识图谱就不同了,它可以在全局数据层面进行结构化的推理。
比如它可以把国家节点、战略节点聚合在一起,让你可以用一个简单的查询语句,立刻找出需要的信息。
理解了知识图谱的优势后,我们来看看它最大的挑战——构建。
构建知识图谱,曾经太难
几年前,一个同事跟我介绍了知识图谱。他的想法是:为我们所有的项目建立一个统一、可检索的图谱。
我花了个周末学习 Neo4j,觉得这个想法还挺靠谱的。
问题是:我们手头有一堆PDF、PPT和Word文档,怎么把其中的实体(节点)和关系(边)提取出来?
当时没找到太好的办法,只能靠手动整理这些非结构化的内容,然后转成图数据模型。
虽然可以用 PyPDF2 读取PDF,再用关键字搜索找出节点和边,但效果很差,效率也极低。最后只能放弃这个方案,打上“不值得投入”的标签。
但现在,LLM 已经成为我们日常工具的一部分,情况完全不同了。
用 LLM 几分钟构建一个知识图谱
如今,从文本甚至图像中提取信息已经不再是难事。
虽然处理非结构化数据还是有提升空间,但过去几年中 LLM 的发展,确实打开了新的可能性。
这一节我们将动手尝试:用 LLM 来构建一个简单(可能是最简单)的知识图谱,并探讨如何逐步优化,走向企业级应用。
这次我们用到 Langchain 的一个实验性功能:LLMGraphTransformer,并选择 Neo4J Auro(一个云托管的图数据库)来存储图数据。
如果你用的是 LlamaIndex,可以看看它提供的 KnowledgeGraphIndex 接口,功能也类似。当然,Neo4j 也不是唯一选择,其他图数据库也可以胜任。
我们先从安装必要的依赖包开始……
pip install neo4j langchain-openai langchain-community langchain-experimental在这个例子中,我们会将一组商业领袖及其所属组织等信息映射到图数据库中。如果你想跟着一起操作,可以查看我使用的示例数据——这是一个我用AI生成的虚拟数据集。
下面是一个从非结构化文档中生成知识图谱的代码示例,简单得出乎意料:

上面的代码非常直观明了。
其中最关键的部分是构建图数据库的过程。我已经特别标出了这一段。LLMGraphTransformer 类会使用我们传入的 LLM,从文档中抽取出图结构信息。
你现在可以将任何 Langchain 的 Document 类型传递给 convert_to_graph_documents 方法,用来提取知识图谱。这个源文件可以是纯文本、Markdown 文件、网页内容,甚至是另一个数据库查询的返回结果。
如果这项工作靠人工来完成,可能得花上几个月的时间——而几年前我们确实是这么做的。
你可以登录 Aura 的图数据库控制台来可视化这个图谱,呈现效果可能会像下面这样:
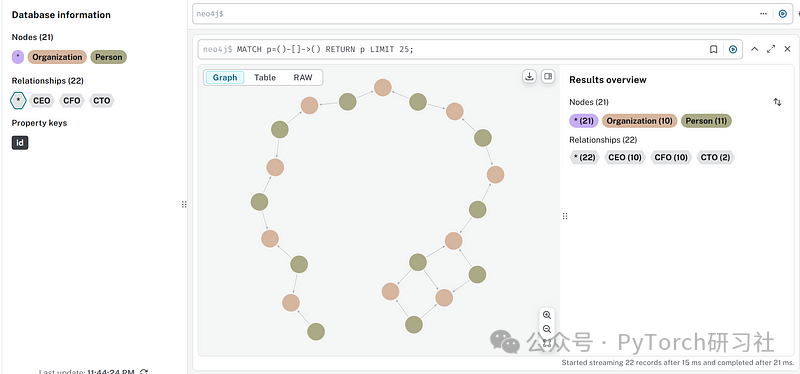
在这个过程中,底层的 API 实际上是调用了一个 LLM,自动从文本中提取出相关信息,并构建了 Neo4J 所需的 Python 对象(用于表示节点和边)。
现在我们已经知道使用 extractor API 构建知识图谱是件轻松的事,接下来就该讨论,如何让知识图谱真正达到企业级应用的标准。
如何让知识图谱达到企业可用的标准?
曾经,我们放弃构建知识图谱,是因为这件事太复杂了。如今,构建过程的确简单了不少,但我们刚刚生成的这个图谱,离“可用于可靠业务”的程度还有距离。
我发现了几个明显的缺陷,并对其中两个做了改进,这里值得重点讲讲:
1. 提高对图谱提取过程的控制力
如果你跟着例子实际跑了一遍,可能会注意到,自动生成的图谱中,只有 Person 和 Organization 两类节点。本质上,这个提取过程仅识别了人物及其所在的公司。
注意:用 LLM 来提取图谱本质上是一个“概率性”的过程。你的结果未必和我一样。
但实际上,我们是可以从文本中提取出更多信息的。比如某个高管毕业于哪所大学,或者他们过去的工作经历等。
那能不能提前告诉系统我们要提取哪些实体类型和关系呢?幸运的是,LLMGraphTransformer 类是支持这项功能的。
你可以通过如下方式初始化:

在这个版本中,我们明确告诉 transformer 去识别三类实体:人物、公司、大学;并指定它们之间可能存在的关系。这个信息对 LLM 提取实体关系是非常关键的。
此外,node_properties=True 这一参数,会让系统尽可能提取节点的各种属性(即使它们没有明确的关联关系)。
通过明确设定实体类型和关系,构建出来的知识图谱通常更完整、更精准。但如果我们希望尽可能“确保”所有重要信息都能被提取出来,还可以配合下面这个方法:
2. 图谱转换前进行“命题化”处理(Propositioning)
文本是一种“有点混乱”的数据形式,而人类写出来的文本往往更混乱。
我们不会总是把所有信息集中说出来,哪怕是在正式的技术文档里,也常常是前后分散表达。比如在这篇文章中,我用过 “Knowledge Graph” 和 “KG” 两种表达方式。
这种“信息散落在多个位置”的现象,会让 LLM 难以正确理解上下文。
而 LLMGraphTransformer 在内部会先对文本进行分块(chunk),然后每个 chunk 独立处理。这样一来,不同 chunk 之间的信息联系就会被打断。
举个例子,假设文章开头提到某人是“CIO”(首席信息官),但这个解释只出现在文本的前一部分。那么在分块之后,后面的 chunk 再次提到“CIO”时,LLM 就可能不清楚这个缩写指的是“信息”还是“投资”或别的含义。
为了解决这个问题,我们可以先进行“命题化”处理(propositioning),让每个 chunk 自包含必要的上下文信息。
具体做法如下:

这个代码用的是 Langchain 的 Prompt Hub 里的一个提示词。从结果可以看出,每一个句子都是独立完整、易于理解的,不再依赖其他上下文信息。
在构建知识图谱前做这样的处理,可以极大降低节点或关系遗漏的风险。
最后的思考
我曾经尝试构建知识图谱,但失败了。那时候构建图谱的投入远远大于它带来的价值。但这还都是在 LLM 出现之前。
直到我发现 LLM 可以从纯文本中提取出图谱结构,并存入 Neo4J 这样的数据库时,我非常震撼。当然,这项技术目前还不够成熟。
我不认为这些功能已经准备好用于生产环境——除非你愿意加点“修补”。
本文提到的两个方法,是我在实际操作中用来提升知识图谱质量的有效手段。希望它们对你也有帮助。
👀 如果你曾因复杂度而放弃构建知识图谱,是时候重新出发了!
https://medium.com/data-science/enterprise-ready-knowledge-graphs-96028d863e8c
https://raw.githubusercontent.com/thuwarakeshm/knowledge-graph-example/refs/heads/main/sample.txt
(文:PyTorch研习社)