

新智元报道
新智元报道
【新智元导读】来自UIUC等大学的华人团队,从LLM的基础机制出发,揭示、预测并减少幻觉!通过实验,研究人员揭示了LLM的知识如何相互影响,总结了幻觉的对数线性定律。更可预测、更可控的语言模型正在成为现实。
LLM会一本正经、义正辞严的捏造事实,「脸不红,心不跳」地说谎。
「幻觉」被普遍认为与训练数据相关。
但在掌握真实训练数据的情况下,为什么LLM还会幻觉?能否提前预测LLM幻觉的发生?
来自美国伊利诺伊大学香槟分校UIUC、哥伦比亚大学、西北大学、斯坦福大学等机构的研究团队,在Arxiv上发布预印本,提出了知识遮蔽定律(The Law of Knowledge Overshadowing):揭示、预测并减少LLM幻觉!
一作张雨季宣布新发现,介绍了LLM幻觉的对数线性定律(Log-Linear Law),分享了最新研究成果:

论文链接:https://arxiv.org/abs/2502.16143
LLM存在一种根本矛盾:
即使使用高质量的训练数据,「幻觉」依旧存在。
要解决这一矛盾,需要对LLL的根本机制有更深入的理解。
为此,本次研究团队提出了新概念:「知识遮蔽」,即模型中的主导知识可以在文本生成过程中,掩盖那些不太突出的知识,从而导致模型编造不准确的细节。
基于这一概念,研究者引入了新的框架来量化事实性幻觉,通过模拟知识遮蔽效应实现。
事实性幻觉的发生率会随着以下3个因素的对数尺度线性增加:(1)知识普及度,(2)知识长度,以及(3)模型大小。
基于这一规律,可以预先量化幻觉现象,甚至在模型训练或推理之前,就能预见幻觉出现。
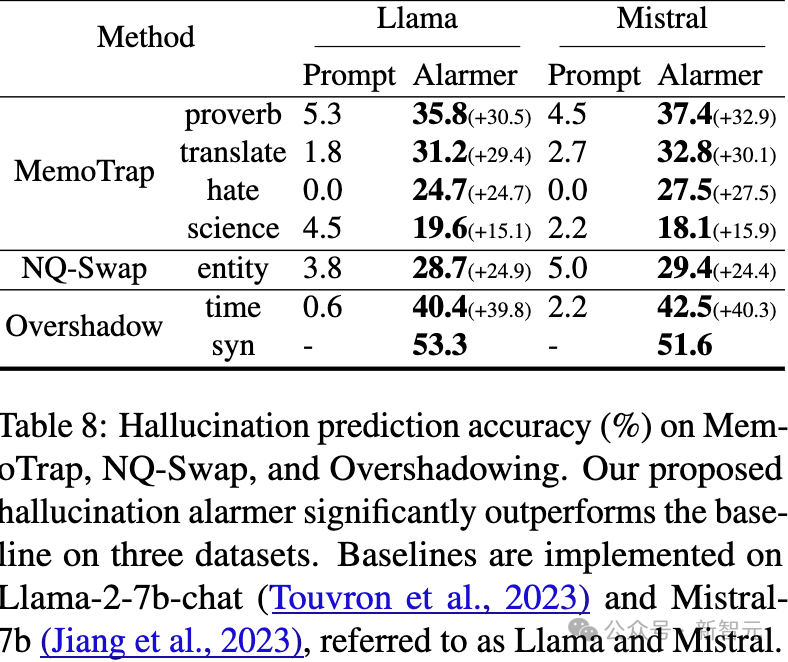
在遮蔽效应基础之上,研究人员还提出了一种新的解码策略CoDa,以减少幻觉现象,这显著提高了模型在Overshadow(27.9%)、MemoTrap(13.1%)和NQ-Swap(18.3%)测试中的事实准确性。
新研究不仅加深了对幻觉背后基础机制的理解,也为开发更加可预测和可控的语言模型提供了可行的见解。

什么是「LLM幻觉」

排名第一的原因就是训练数据问题。
然而,发现即使在严格控制预训练语料库仅包含事实陈述的情况下,这一问题仍然存在。
具体来说,在使用查询提取知识时,观察到某些知识倾向于掩盖其他相关信息。
这导致模型在推理过程中未能充分考虑被掩盖的知识,从而产生幻觉。
知识遮蔽导致幻觉
为了系统地描述知识遮蔽现象,在训练语料库中,研究人员定义了知识对(knowledge pairs)。
具体来说,设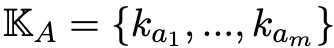 和
和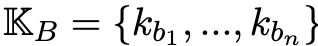 代表一对知识集合。
代表一对知识集合。
其中,K_A包含m个知识陈述样本ka_i,而K_B包含n个知识陈述样本kb_j。
在K_A和K_B中的每个陈述都通过一个共享的词元集合X_{share}相关联。
在知识集K_A中,每个声明ka_i由一个共享的token序列Xshare、一个唯一的token序列xai和输出Ya组成。
每个声明kai表示为:
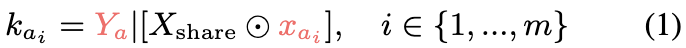
其中⊙表示将独特的序列xai插入Xshare中(整合位置可以变化)。
同样,对于不太受欢迎的知识集K_B,用xbj表示独特的token序列,每个声明kbj表述为:
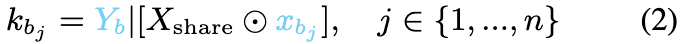
当在推理过程中抑制独特的token序列xbj或xai时,会发生知识遮蔽。
以xbj被遮蔽为例,当提示Xshare⊙xbj时,模型输出Ya,形成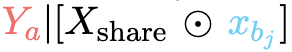 ,错误地将事实声明kai和kbj合并成事实幻觉,违背了地面真相
,错误地将事实声明kai和kbj合并成事实幻觉,违背了地面真相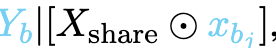 ,如图1所示。
,如图1所示。
事实幻觉的度量为了测量由知识遮蔽引起的事实幻觉,引入了相对幻觉率R。
当KA是更受欢迎的知识集时,首先量化模型正确记忆来自KA的样本的召回率,记为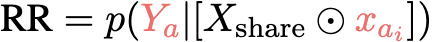 。
。
然后,量化模型在xbj被遮蔽时产生输出的幻觉率HR,记为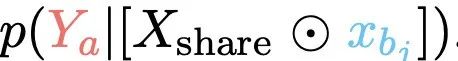 。
。
相对幻觉率R=HR/RR表示不那么受欢迎的知识集由xbj编码的知识被更受欢迎的知识集由xai编码的知识抑制的程度。这个比率表示较不流行的知识(xbj)在多大程度上被较流行的知识(xai)所抑制。
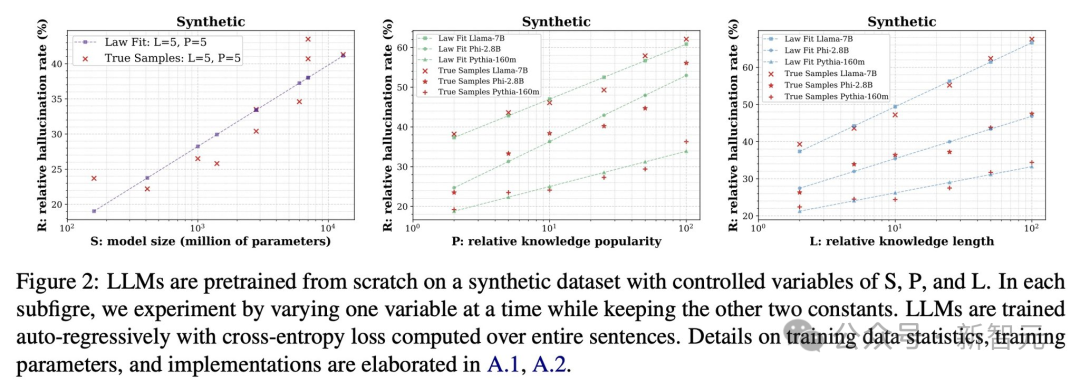
图2:大语言模型(LLMs)在一个具有可控变量S、P和L的合成数据集上从零开始预训练。
在每个子图中,通过改变其中一个变量进行实验,同时保持另外两个变量不变。
LLMs采用自回归(auto-regressive)方式进行训练,并基于整句话计算交叉熵损失(cross-entropyloss)。
关于训练数据的统计信息、训练参数及具体实现细节,请参考原文附录A.1和A.2。
影响变量的公式化由于影响事实幻觉的潜在因素尚未被深入研究,从全局和局部两个角度分析这些变量,重点关注导致「知识遮蔽」(overshadowing)效应的知识占比。
当K_A比K_B更流行时,样本数量满足m>n。
全局视角下,定义相对知识流行度(relative knowledge popularity)为P=m/n,该值表示在整个训练语料库中,某一知识的相对占比。
局部视角下,量化单个句子中知识的权重,定义相对知识长度(relativeknowledgelength)为: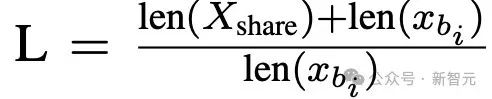 其中,长度(length)是指token的数量。
其中,长度(length)是指token的数量。
此外,先前研究表明,扩大模型规模可以提升模型性能。因此,研究增加模型规模(S)是否能缓解事实幻觉现象。
何时会出现事实幻觉?
1、未经过额外训练的开源预训练LLM,
2、从零开始训练一个新的LLM,
3、以及对预训练LLM进行下游任务的微调。
开源LLM中的幻觉
结果表明,频率更高的知识倾向于掩盖频率较低的知识。
这一发现与「高频知识掩盖低频知识」的现象相一致,说明数据中出现频率高的内容容易主导模型的输出,从而导致幻觉。
 幻觉的对数线性规律
幻觉的对数线性规律实验设置:为了准确量化幻觉与其影响因素之间的关系,在具有受控变量设置的合成数据集上,研究人员从头开始预训练语言模型。
之所以这样做,是因为现实世界训练数据中,自然语言天生就有变异性和不精确性,无法以完全准确地枚举所有流行/不流行知识的表达形式。
对于每个受控变量实验,从分词器词汇表中,采样词元来构建每个数据集,如表1所示。

研究人员从零开始预训练每个LLM,使用表1中的数据集,共包含19.6亿tokens,并在自回归(auto-regressive)方式下进行训练。
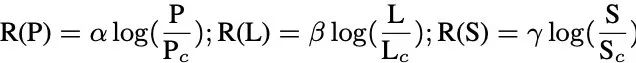
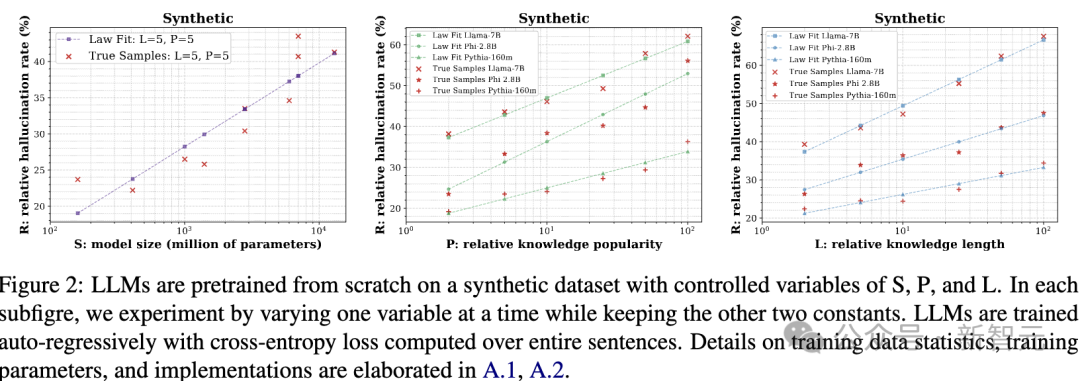
更高的流行度会导致信息被掩盖:高频知识会主导模型的学习,而低频知识则更容易被忽略或错误替代。
更长的文本会导致信息被掩盖:在句子内部,如果x_{bj}的token长度短于X_share,它的语义边界会变得不清晰,导致信息被掩盖。
更大模型导致信息被掩盖:在保持低频知识的清晰语义区分方面,更大的模型的能力有所下降。最终可能导致低频知识在生成过程中被忽略或误用,从而增加幻觉(hallucination)发生的概率。
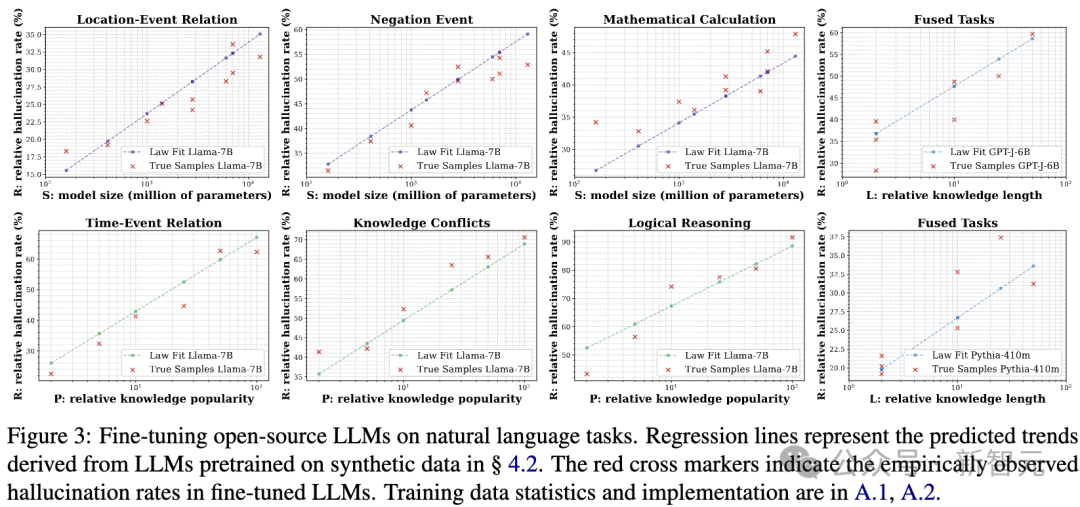
在微调LLM中验证对数线性规律时间、地点、性别、否定查询(negation queries)、数学和逻辑推理与知识冲突解析(knowledge conflict resolution)。
对于每个任务,研究人员生成:
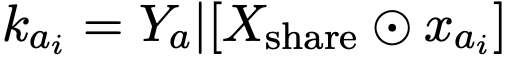 ;
;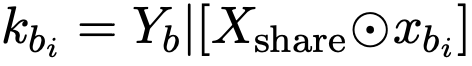 。
。 利用对数线性规律主动量化幻觉
利用对数线性规律主动量化幻觉研究人员利用训练LLM在受控的合成数据集上拟合出的对数线性规律(log-linear law),来预测经过微调后的LLM在不同下游任务中的幻觉率。
具体来说,研究人员使用该规律预测幻觉率R,并分析它如何随以下变量变化(见图3):模型规模S、相对知识流行度P、相对知识长度L。
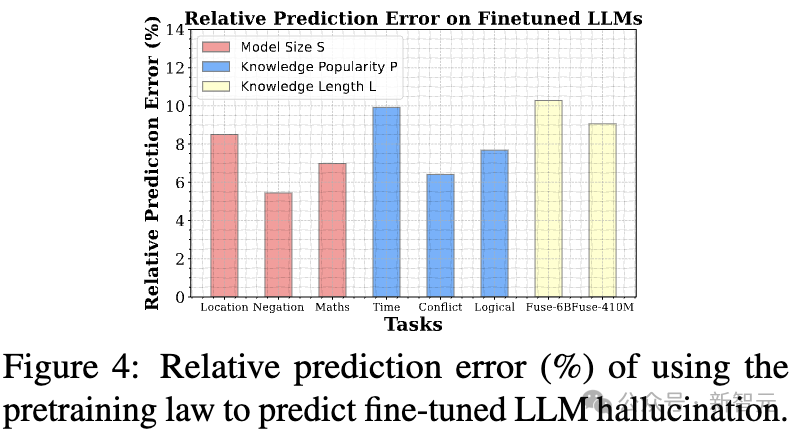
随后,研究人员比较预测的幻觉率与微调实验中实际观测到的幻觉率之间的差异。
研究人员使用相对预测误差来评估对数线性规律的预测能力,其计算公式如下:
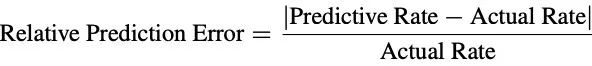
 当前最佳LLM中的事实幻觉
当前最佳LLM中的事实幻觉
为什么知识会被掩盖?
在实验中观察到的知识掩盖的扩展效应(scaling effects of knowledge overshadowing)现象。
记忆—泛化—幻觉幻觉是否可以被理解为记忆阶段之后——即泛化(generalization)阶段的必然副产物?
随着模型记忆大量信息并捕捉关联关系,它们会在泛化过程中适应新的分布。
然而,在这一过程中,不占主导地位的知识可能会因过度平滑(smoothing)或信息压缩(compression)而被更常见的模式所掩盖。
泛化误差界解释幻觉
在受控实验设置下,可以将除了L和m之外的变量视为常数。
在这里,h(L)表示一个与L正相关的函数值,μ反映了输入变化的敏感度,即相对知识长度L对泛化能力的影响。此外m代表K_A的样本数量。
理论上,更低的误差下界意味着更强的泛化能力。
当L增加(即知识的相对长度增长)或m增加(即知识的相对流行度提高)时,二者都会降低泛化误差界,也就是说说,提高泛化能力。
但与此同时,这也与幻觉率的上升趋势一致,即泛化能力增强的同时,模型更容易产生事实幻觉(hallucination)。
更多详细的理论推导可在原文附录A.5中查看。
如何消除幻觉?
识别被掩盖的知识在语言模型(LLM)中,给定输入token序列X,模型会生成续写token序列Y,其中X和Y都由词汇表V中的token组成。
如果X中的某些token x_b被掩盖(overshadowed),模型可能会生成幻觉输出(hallucinated output)。
比如说,输入X是下列内容:
「Who is a famous African researcher in machine learning area?」
Y=「Yoshua Bengio」
解决方案:研究人员提出CoDA(对比解码),用于放大被掩盖的知识,从而减少幻觉现象的发生。
检测被掩盖的Token为了识别被掩盖的token x_b,研究人员采用逐步屏蔽(masking)的方法,即依次屏蔽X中的x_b,形成X’,直到找到被掩盖的token(具体的x_b选择方法见原文附录A.4)。
如果x_b被掩盖,则模型的条件概率会发生退化:
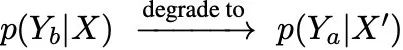
换句话说,模型的输出会从Y_b偏向Y_a,导致信息丢失或幻觉。
为了确保研究人员能够量化输出候选yi∈P(Y|X)和P(Y|X′)的足够语义,采用自适应合理性约束,保留满足以下条件的token:
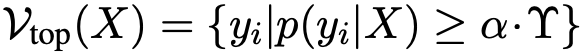
,其中α=0.01是一个超参数,Υ是一个全局变量,表示所有yi候选中的最大概率。
然后,R-PMI在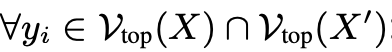 上进行量化:
上进行量化:
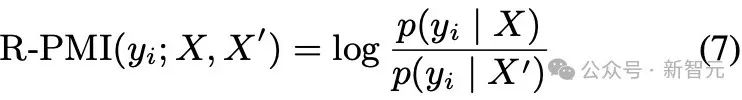
本质上,负的R-PMI值表示token yi更倾向于与X′相关联,且没有受到遮蔽信息的影响。
因此,为了量化P(Y|X)在多大程度上推广到P(Y|X),需要找到下列最小值:
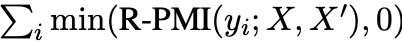
此外,值得注意的是,尽管某些token被X′遮蔽,但仍有一些token逃脱了这种遮蔽效应,定义为Vesc:
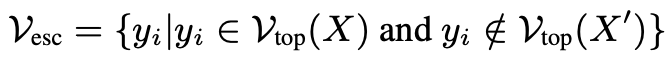
这些逃脱的token展示了消除幻觉的潜力。
研究人员提出了一个逃避奖励机制(ERM),该机制通过向负R-PMI的总和添加正奖励来评估逃避效应是否超过了遮蔽效应。
将所有具有负R-PMI的yi表示为yi∈S,ERM的计算方式如下:
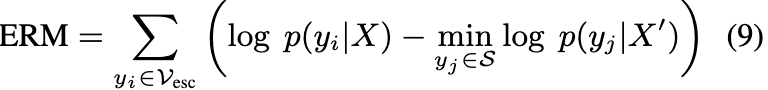
这里的计算是为了使ERM与RPMI保持平衡,两者具有相似的分母p(yj|X′),在方程7中表示来自X′的最小偏差。
然后,研究人员可以通过以下公式计算遮蔽知识指标:Indicator=R-PMI总和+ERM。
指标值为负表示进行了适当的泛化而没有遮蔽其他知识,而正值则表示过度泛化并遮蔽了token xb。
接着,研究人员可以在定位被遮蔽的token后,预测潜在的幻觉,表8显示了准确率。
 提升被遮掩的知识
提升被遮掩的知识研究人员提出了一种方法,用于提升被遮掩的知识。
一旦识别出编码被遮掩知识的token xb,研究人员就会对这些token采用对比解编码,以减少X′的影响并突出X的重要性。
具体来说,为了降低X′的偏差,研究人员对每个yi∈Vtop(X)∩Vtop(X′)减去X′的先验偏差P(yi|X′),计算方式如下:
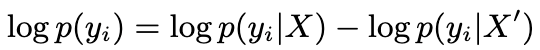
同样,对于每个yi∈Vesc,研究人员进行以下操作:
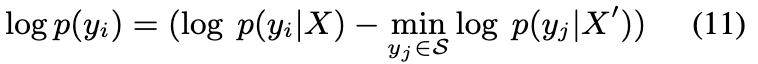
在这里,右式后一项表示来自普遍知识的最小先验偏差。
这种减法旨在平衡yi∈Vesc和yi/∈Vesc之间的偏差调整,确保对两者进行成比例的调整。
然后研究人员通过以下方式预测最优输出y^{∗}_{i}
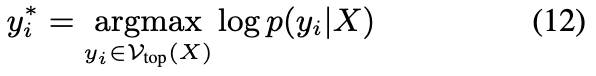
到目前为止,研究人员已经减少了由X′编码的普遍知识带来的遮掩效应,然后放大了编码有意义被遮掩知识的逃避token,以减少幻觉。
实验结果在Overshadow、MemoTrap和NQ-Swap任务上,CoDA分别将贪心解码的性能提升了27.9%、13.1%和18.3%。
增强推理能力的基线方法在处理因知识遮蔽(knowledge overshadowing)导致的幻觉现象时表现不佳。
而基于自一致性(self-consistency)的方法则表现出不稳定性,甚至可能出现性能下降,这可能是由于强化了来自流行知识的偏差。
图5展示了对CoDA受两个因素P和L影响的定量分析。
随着知识的过度泛化,提取有价值信息变得越来越困难,因为有用的知识表示受到了抑制。
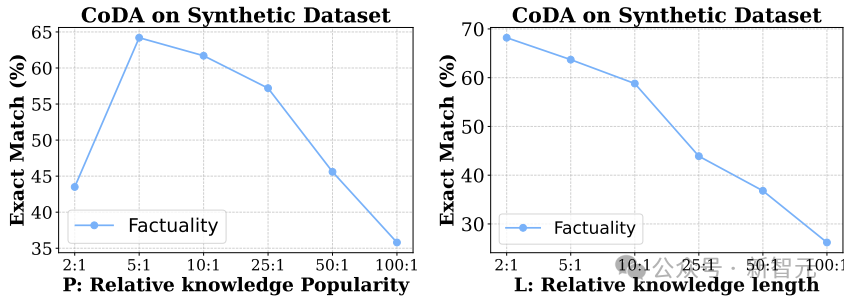
图5:关于流行度P和长度L对CoDA在消除知识遮蔽方面表现的定量分析。
一作简介

(文:新智元)