

Meta 新发布的 LLaMa 4 大模型,疑似在训练过程中「暗中作弊」!

Hyperbolic Labs 联合创始人兼首席技术官 Yuchen Jin 在社交媒体上爆出猛料称:
有 Meta 内部人士在 Reddit 上披露,为了提高 LLaMa 4 在各种基准测试上的分数,Meta 团队竟直接将测试数据集「悄咪咪」塞进了训练数据!
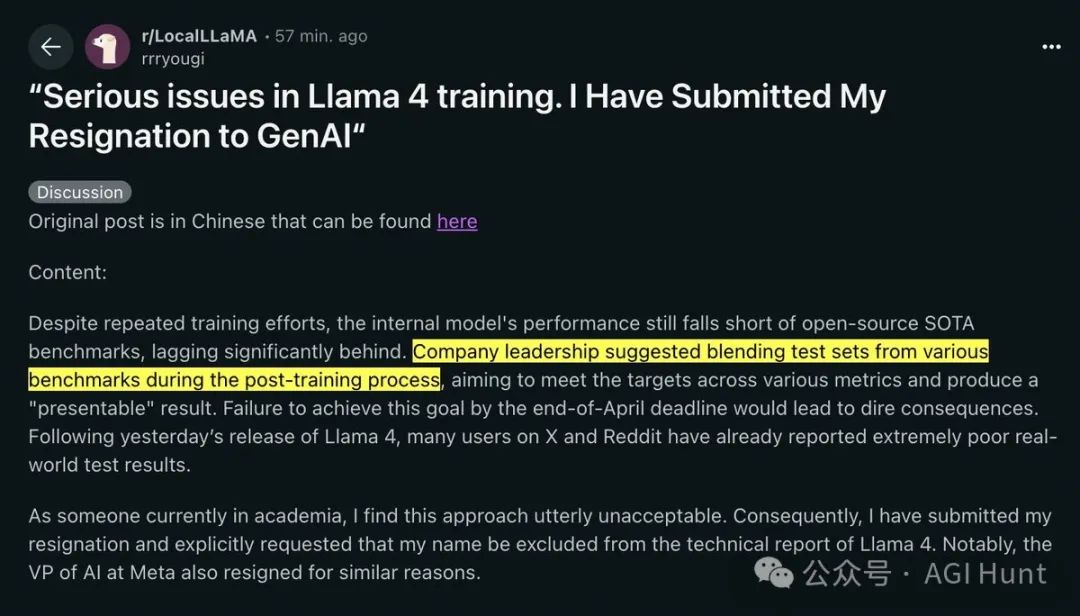
这事儿放哪都算是重量级丑闻!
要知道,AI 模型这么搞等于直接考前偷看答案卷,还能叫公平竞争吗?
这就跟高考前老师「不小心」把试卷发你手里,转头你就考了满分,然后还振振有词说自己厉害——你咋不上天呢?!
这消息一出,AI 圈直接炸锅了!
有人直言「完全不令人印象深刻」

还有人直接爆粗口:「WTF」

甚至有人把锅甩给 Meta 的 AI 掌门人 Yann LeCun:「Meta AI 的负责人要么忙着怼 Elon(马斯克),要么在贬低 LLMs,还能指望什么?」

(这位兄弟,你是也买TSLA 了吧……
有人甚至宣称:「Zuck 需要开除 Le Cun,我打赌他在模型训练过程中偷偷 SSH 进入集群修改权重,就为了能继续做这种事」
还有人表示:「😮 🤯 简直难以置信」
有意思的是,就在这消息闹得沸沸扬扬的当口,Meta AI 研究副总裁 Joelle Pineau 突然宣布离职。

这时间点,也是有点妙啊!
有人担忧 Joelle Pineau 离职的时机「正好在 Llama 4 训练争议之后,这太疯狂了。不知道这是否预示着 Meta AI 更大的震荡。你觉得这对 FAIR 的未来意味着什么?」
不过也有人出来「灭火」。
有自称参与 LLaMa 4 训练数据混合工作的人员明确表示:「我不知道有这种情况发生」。

眼看风波越闹越大,一位网友建议「让子弹飞一会儿」,别急着下结论。
有不少业内人士表示怀疑,The Tiny Corp 团队直言:
「不可能是真的,没有大实验室会这么蠢。我认为 Llama 4 的表现问题主要来自破碎的实现或者糟糕的量化,MoE 架构很难搞对。我猜几周内问题会被修复,到时它的表现会与那些基准测试成绩相当」。
另有评论指出,这很可能是「因为符合某种叙事,所以大家过度关注 Reddit 上一条帖子而已,让我们给研究团队一点信任」。
不少网友直接表示要转向其他开源模型,「看来我们得坚持用 DeepSeek 了」,还有人点名 Gemma 和 Qwen 作为更好的开源选择。
甚至有人直言不讳:「这很 Facebook 风格」,「我认为他们都在玩弄基准测试」,「哥们,这次 Llama 真的搞砸了」。
同时也有人给出了解决之道:独立测试!
数据科学家 Lech Mazur 表示,他正在用自己独立开发的测试集来评估 LLaMa 4,不管 Meta 做了什么,真相终将大白。

SSindia 网友分享了自己的亲身体验:「我有几个脚本问题,LlaMa 4 无法一次性解决。这些是中等复杂度的 Python 脚本任务,而 Gemini 2.5 Pro 和 Claude 3.7 都能一次完成」。

还有人提出有趣的观点:「相当肯定每家都在某种程度上最大化基准测试成绩。但当你比较 Llama 的实际表现和基准测试成绩时,差距太明显了」。

也有看得更开的:「这些事很常见,很多 AI 实验室都这么做,可能是有意的,也可能是他们倒入的数据恰好包含了公开基准测试集。所以不能只怪一家。这就是为什么公开基准测试不是检验模型表现的解决方案。至少在我们获得 AGI 前,应该有一种更有效或手动的方法来验证这些东西」。

还有人调侃「得开始学中文了」,还有人嘲讽「AI 开发团队造假数据,这太难以置信了」。

有人注意到这不是第一次:「这是不是第一次知名模型遭遇此类指控?」
面对这场风波,Yuchen Jin 也给出了自己的建议:
任何公开的基准测试数据集,迟早会泄露到模型训练集中。
所以:
1. 不要盲目相信任何基准测试分数;
2. 自己尝试模型,看它在你具体应用场景下的表现,这才是真正重要的。
Erika S 表示赞同:
「完全同意。基准测试只是起点——始终用你自己的数据进行验证」。
关于 Meta 内部情况,有人补充:「Yann 不负责 Llama 项目」
而网友 Noah Vandal 也分析称「我打赌他们更专注于 JEPA 风格模型而非 LLM」。

从技术角度看,Qubitum 指出:「transformers 库对 llama4 有多个 bug,vllm 和 sglang 不确定。给他们几天时间先稳定推理」。
Chris Bora 调侃道 Yann LeCun「忙着玩 Threads 呢」,而 zomgthisisawesomelol 则评论:「Yann 是 AI 领导层中最悲观的,想象一下为这样的人工作」。
有人提出不同看法:「当 Yann 试图告诉你 LLMs 本身有局限性时,你宁愿说’不,他在破坏’,而不是承认他的观点有道理,这有点奇怪」。
这也再次提醒我们:在 AI 领域,外表光鲜的数据可能暗藏玄机。
在热火朝天的 AI 竞赛中,各家都想出奇招提升分数,但如果真像爆料所说那样「开小灶」,可就真有点不地道了。
至于 Meta 此事是真是假,目前尚无定论。
Meta,是否真的已经落后了呢?
你怎么看?
reddit 链接:
https://www.reddit.com/r/LocalLLaMA/comments/1jt8yug/serious_issues_in_llama_4_training_i_have/
(文:AGI Hunt)
meta也被卷得够呛