
🍹 Insight Daily 🪺
Aitrainee | 公众号:AI进修生
Hi,这里是Aitrainee,欢迎阅读本期新文章。
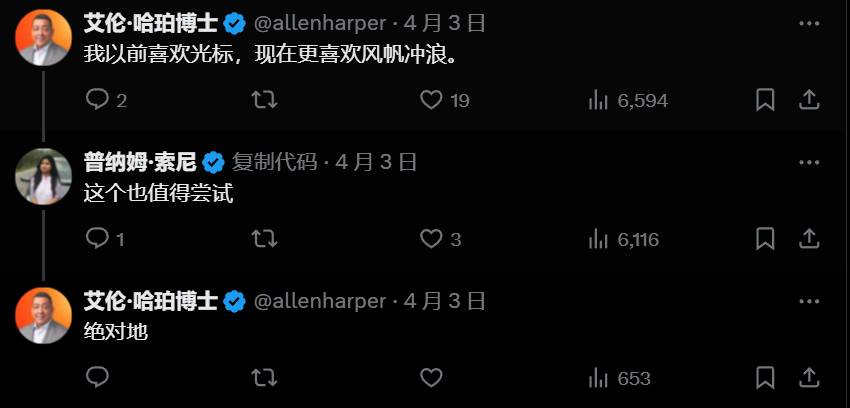
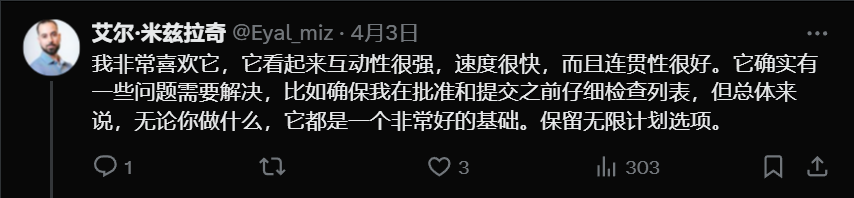
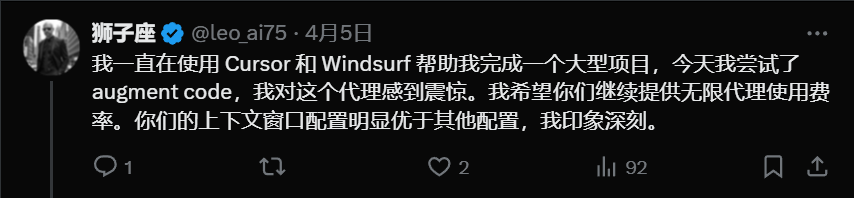
官方喊话了:“ 免费来试试,把你最大最复杂的代码库丢过来,看我们搞不搞得定。(augmentcode.com)。”
创始人 Scott Dietzen 表示,Webflow、Kong、Pigment 这些公司已经在用了。
这 Agent 要干啥?不只是写代码,而是帮你搞定整个开发流程。
专为在实际系统中工作的工程师打造: – 多文件编辑 – 完整 PR 创建 – 终端命令和代码执行 – 上下文感知文档和测试代理不只是建议代码。它编写码、运行代码并记录每一步。
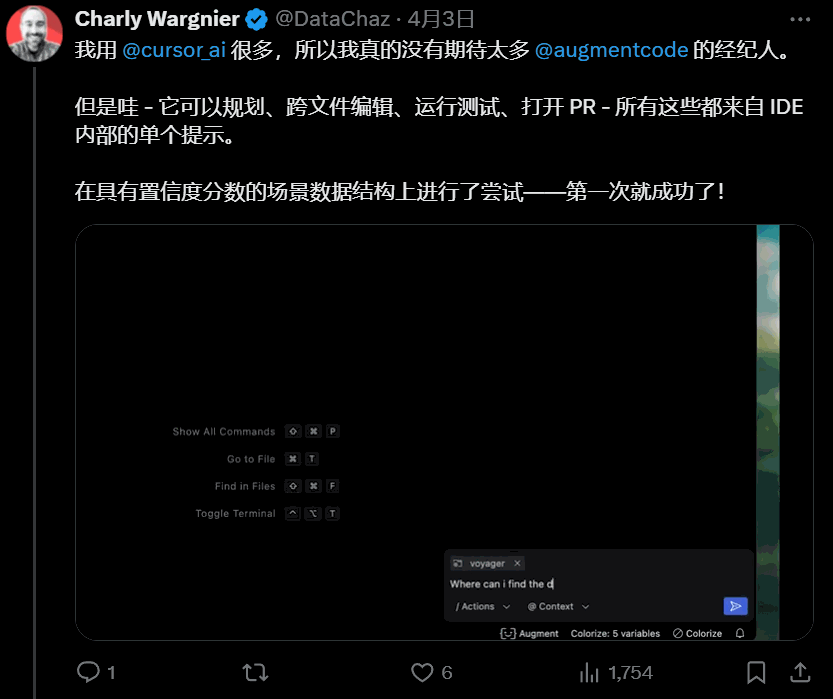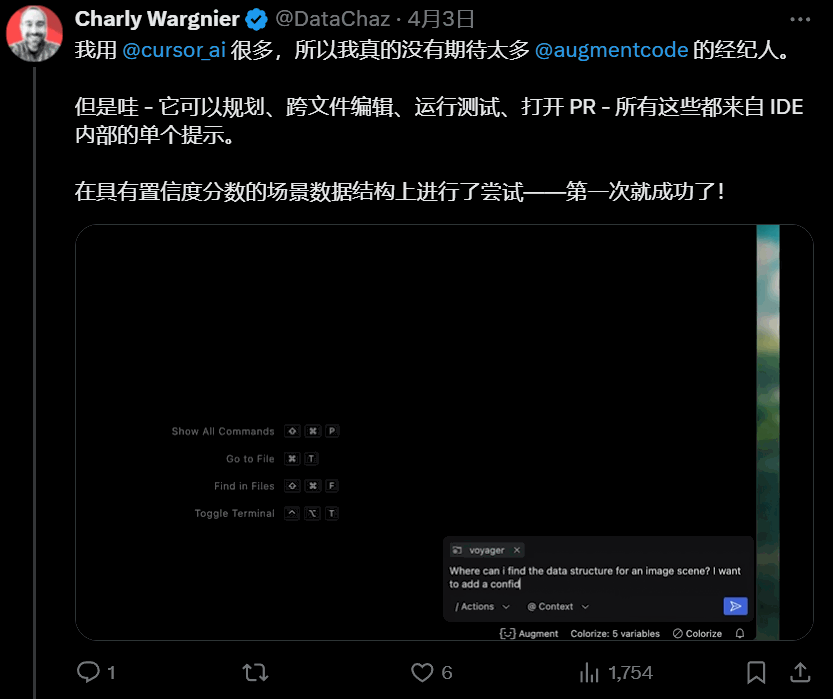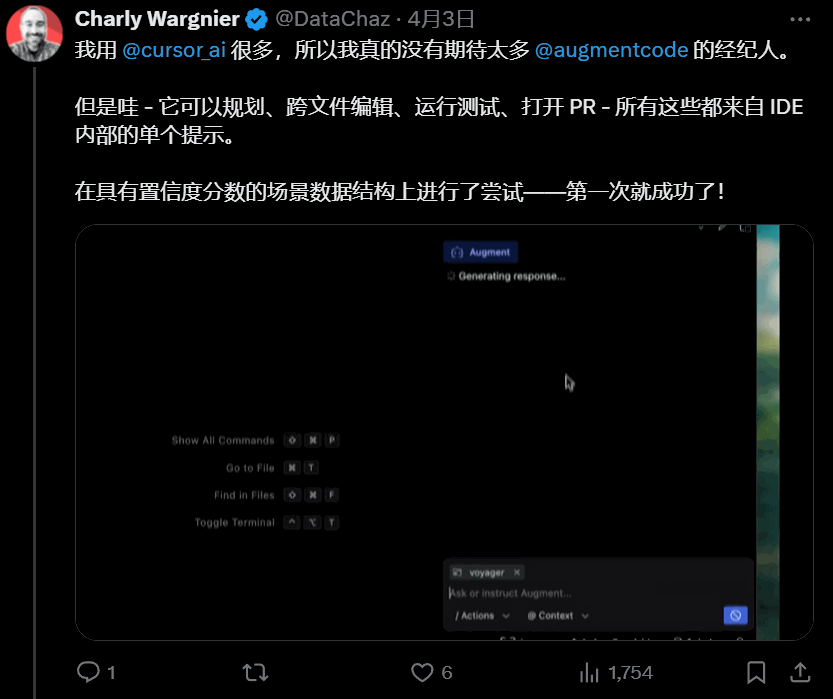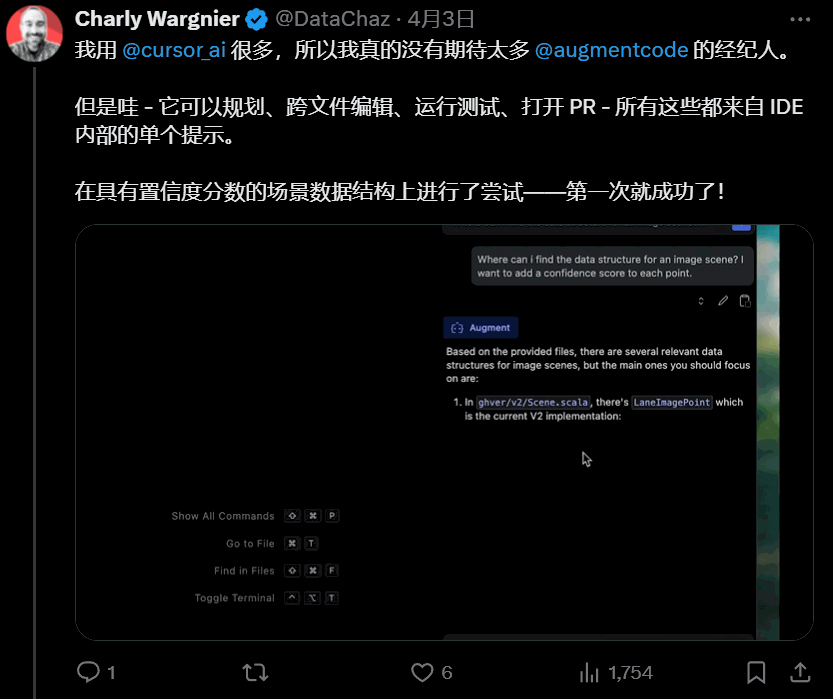
终端/执行权限 get:直接指挥终端、运行代码,能力边界大扩展。
智能文档/测试:结合项目背景,生成靠谱的文档和测试用例。
全程 Live Show:写、跑、记,每一步操作都透明可见。
集成开发工作流 (Integrated Dev Workflows)从接活 (ticket) 到交差 (PR),一条龙服务,不用换工具:
-
连 GitHub 做分支、提交、发 PR。 -
连 Linear 发现和解决 issue。 -
连 Notion、JIRA、Confluence 把文档需求变成代码。AI 真正融入了你的日常工作流。
Agent 的几大亮点:
持久记忆 (Persistent Memory) 这 Agent 越用越懂你:
-
它会学你的代码风格。 -
你上次怎么重构的,它记得。 -
你公司的基建和规范,它能适应。关键是记忆能累积,不用每次开工都像教新人一样重新说一遍。
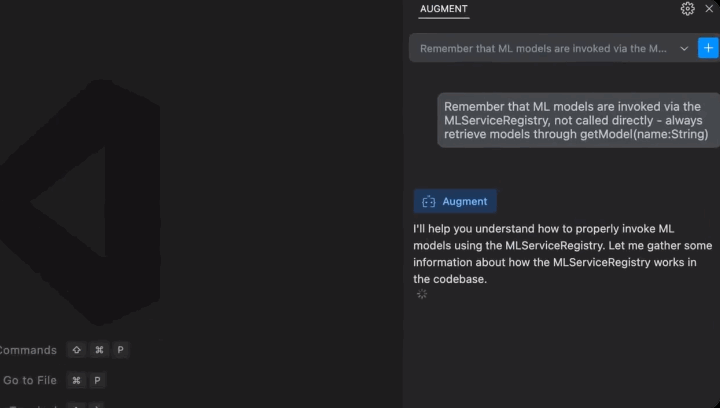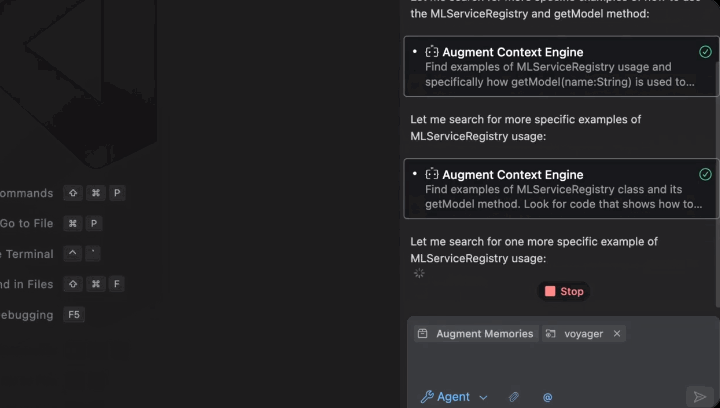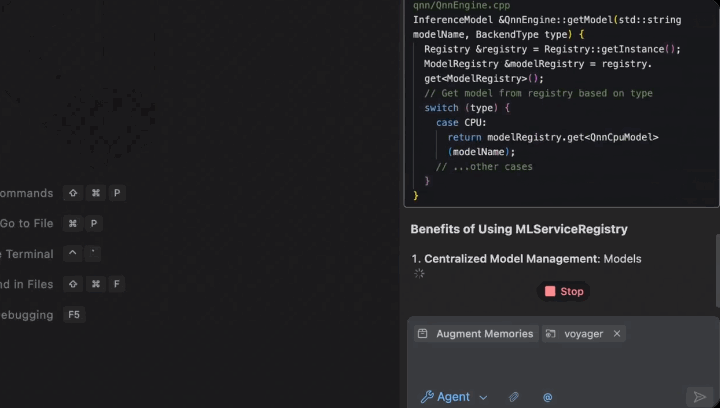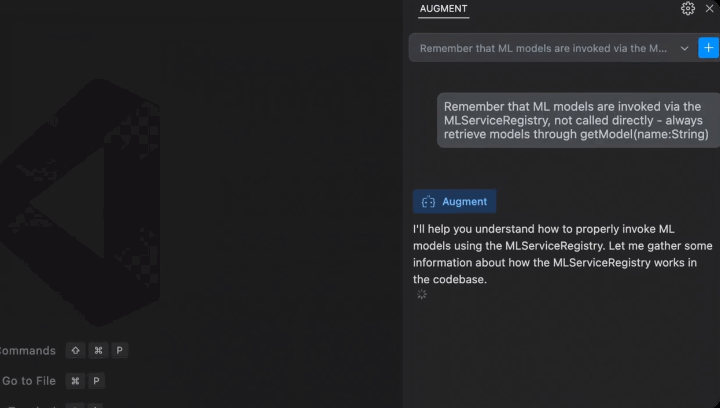
关于持久记忆你可以看对话框这个位置。
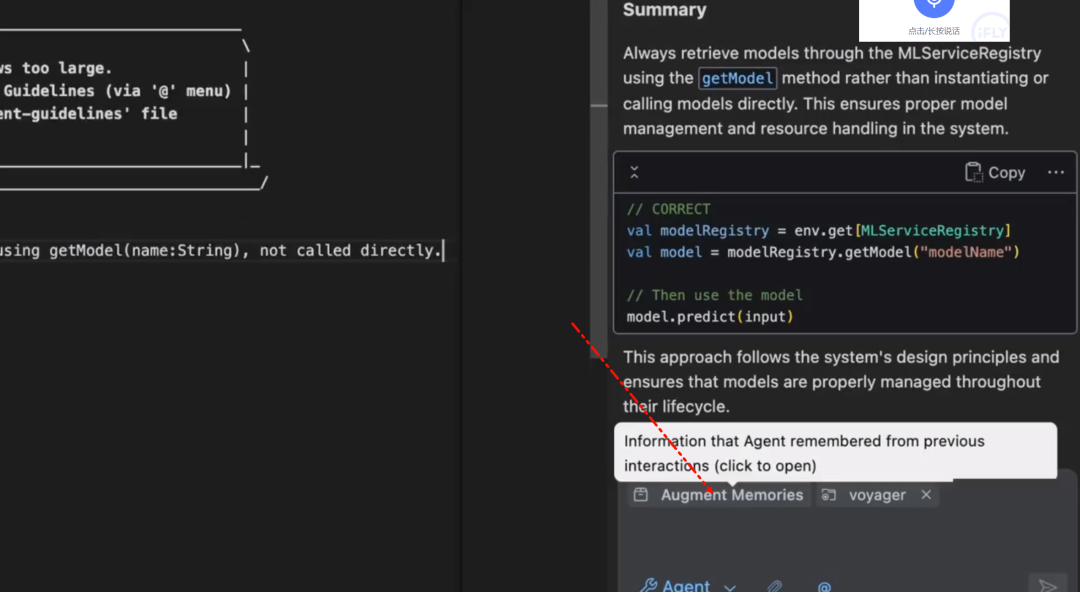
无需查看指南、询问同事或提交帮助请求即可快速获得答案。聊天可以帮助你快速前进。
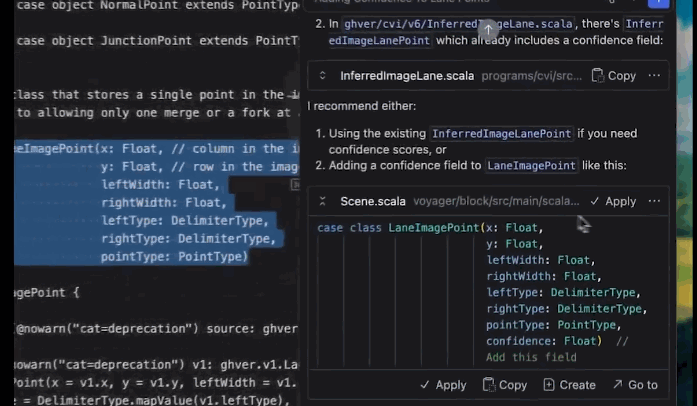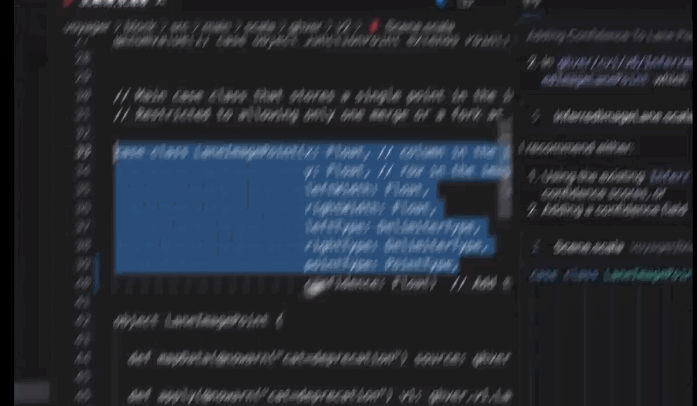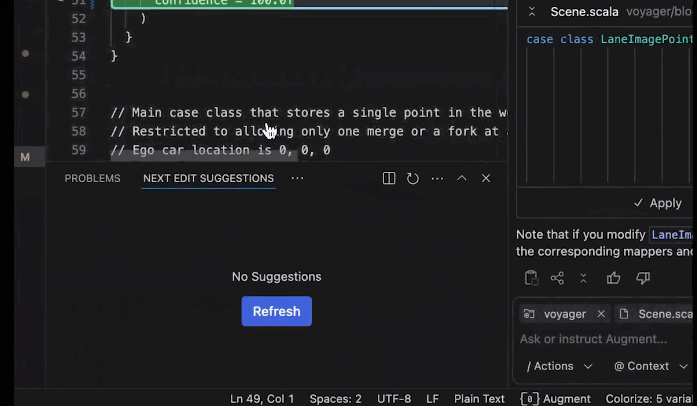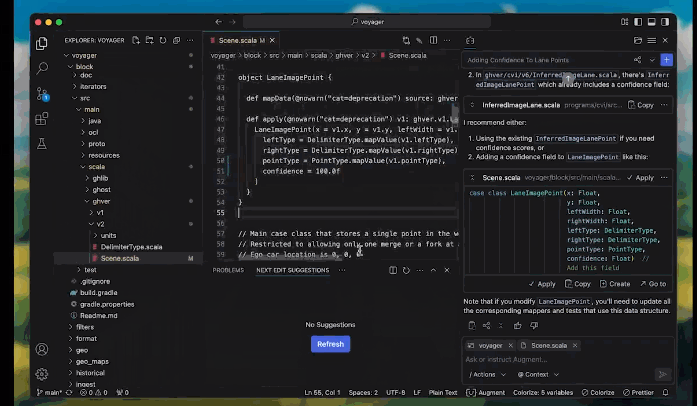
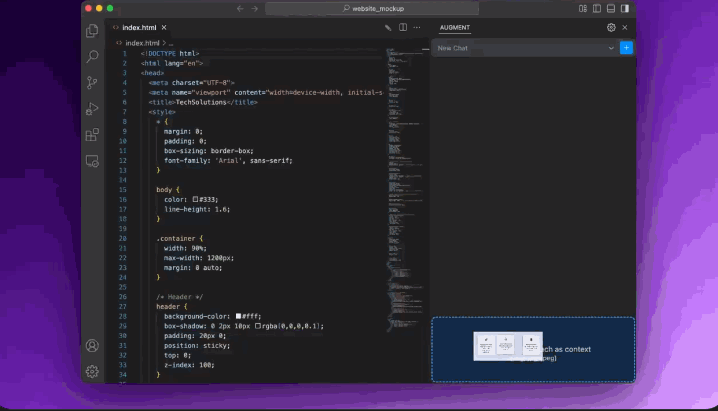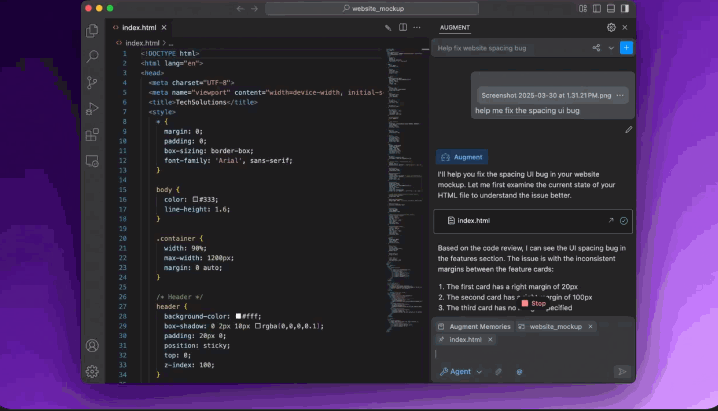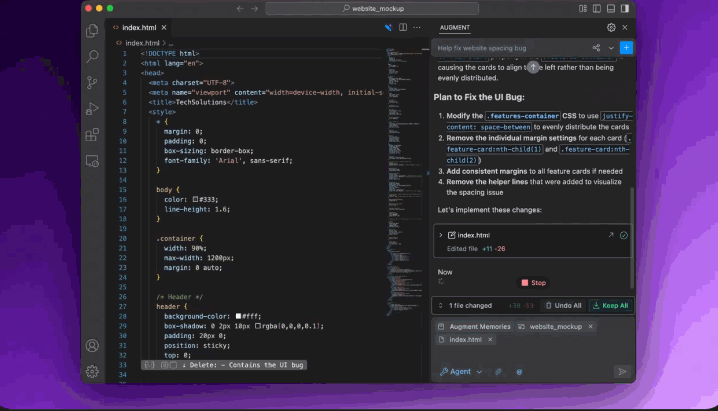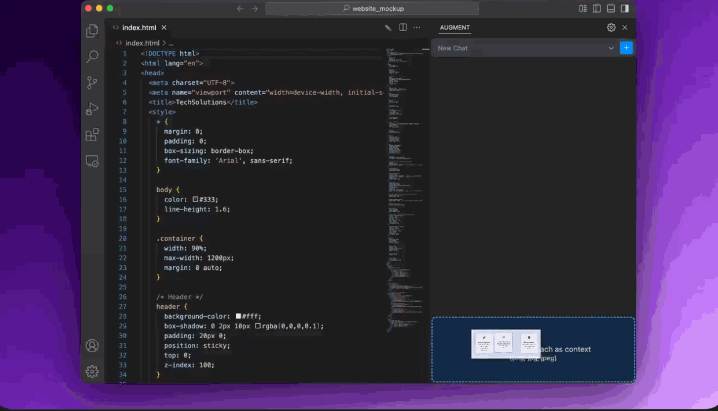
-
截图拖进去,Agent 自动诊断 (CSS/布局/逻辑)。 -
精准修复 + 只跑相关测试 = 效率起飞! -
调试变简单:拖拽、修复、确认,三步搞定。
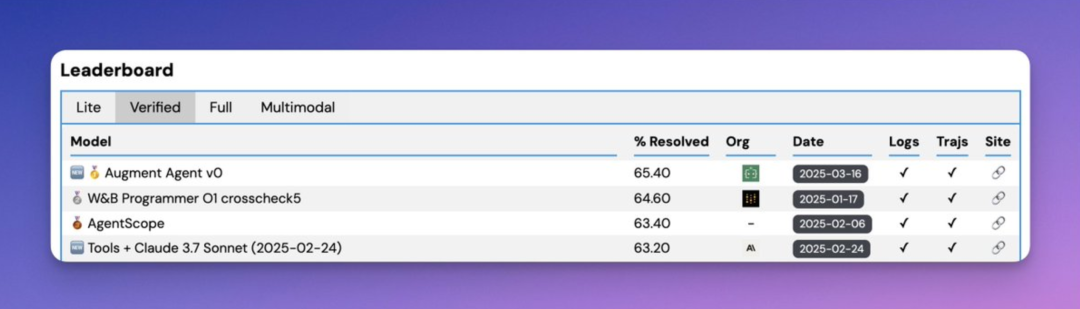
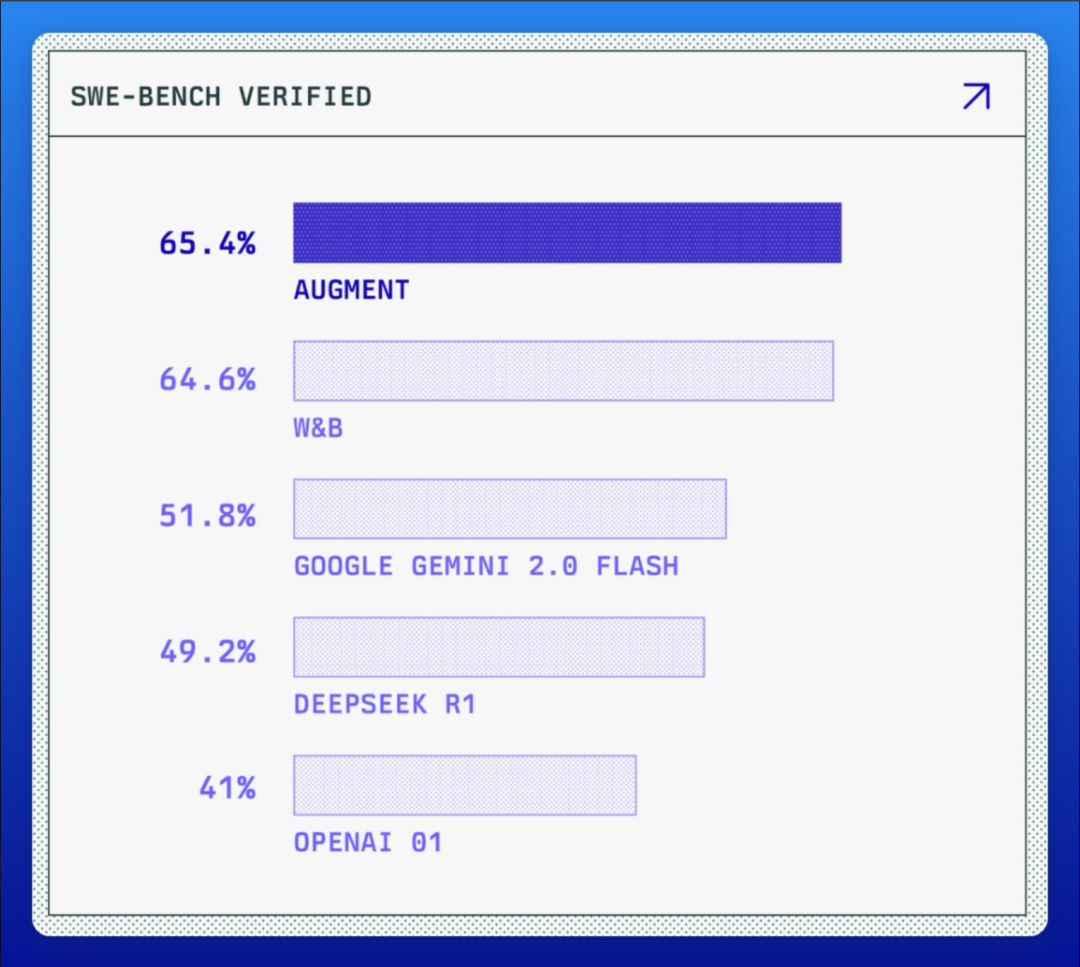
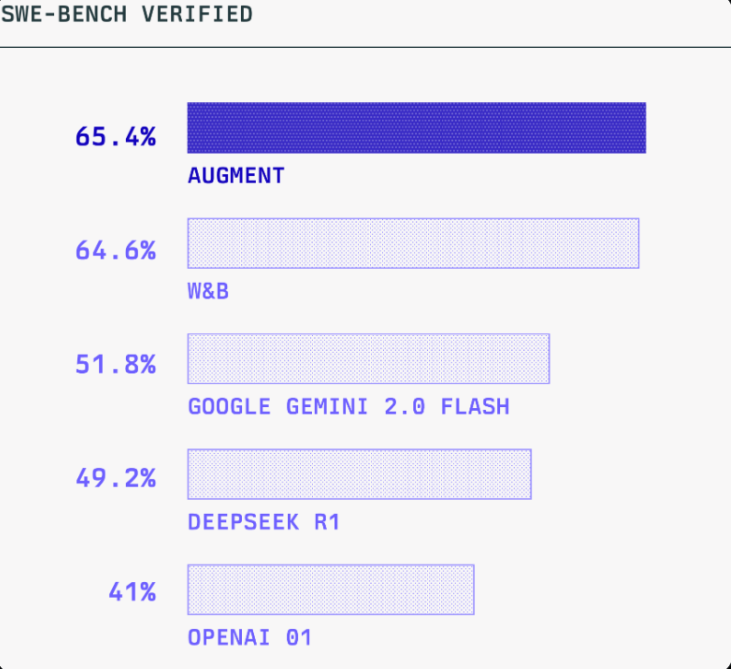
先科普下:SWE-bench 这玩意儿到底测啥?
跟 LeetCode 刷题不一样,它模拟的是真实世界的软件工程:从 GitHub issues 里找真实 bug,扔给你一个代码库(依赖都装好了),让你自己搞定。
你得自己找测试用例,自己写脚本复现问题,自己定位、修改代码,还得保证不破坏原有功能。这比单纯写算法要复杂得多,更考验 Agent 的综合能力。
以前的文章也有聊过:
当然,没哪个基准是完美的,SWE-bench 也有它的局限:
- 偏科严重:
更侧重修小 bug,而不是搞新功能。 - 提示词太“友好”:
任务描述比开发者实际提问清晰多了。 - Python 独大:
忽略了 Java、C++ 等其他语言的复杂性(比如 Python 的报错信息通常更友好)。 - “小打小闹”:
代码库规模比生产环境小几个数量级。 - 不够“硬核”:
大部分问题有经验的人类工程师一小时内就能解决。
更重要的是,真实软件工程里的协作、迭代、各种第三方工具集成 (Linear, Jira, Notion, Slack 等)、卡壳时问开发者、根据反馈自我学习… 这些 Augment 产品里下了功夫的地方,SWE-bench (目前) 都测不到。 (比如 Augment 最近还搞了个 AugmentQA benchmark,专门测代码库感知的检索能力)。
Augment 从这次“屠榜”悟到了啥?
- 基础模型是爹:
模型本身的能力决定了上限。 - 调 Prompt 有用,但很快到顶。
- 集成 (Ensembling) 能提分 (3-8%),但不稳定且太烧钱,
实际产品里玩不起。 - Benchmark ≠ 产品体验:
grep/find 在 SWE-bench 里导航够用,但真实复杂代码库和模糊需求下就吃力。很多能提升用户体验的改进,在 SWE-bench 上根本体现不出来。
所以,Augment 的结论很明确:作为应用层 AI 编程公司,死磕 Benchmark 不如死磕产品体验。正道是利用微调开源模型和强化学习,把 Agent 搞得又快又便宜。只有这样才能真正解锁新的 AI 编程范式,而不是在 Benchmark 上自嗨。 未来他们会在这方面有更多动作。
技术细节控看这里 (Deep Dive 摘要):
-
最终方案是 Claude Sonnet 3.7 + o1 的组合拳。 -
借鉴了 Anthropic 的架构,但自己搞定了他们没公开的“规划”工具 (用的是 sequential_thinking tool)。 -
试了各种花活:智能粘贴、改进 bash 工具、加 embedding 检索… 发现对 SWE-bench 分数提升有限 (但强调 embedding 对实际产品体验至关重要)。 -
把任务拆分成多个 Agent (比如先定位测试,再专门修复回归 bug) 的尝试,效果不佳,甚至会引入新 bug。 -
集成 (Ensembling) 就用了简单的 O1 投票选最优解,复杂的不搞,因为太贵。 -
(他们还贴了具体的启动 Prompt 指令,感兴趣可以去原文看。) -
https://www.augmentcode.com/blog/1-open-source-agent-on-swe-bench-verified-by-combining-claude-3-7-and-o1
使用Augment氛围搭建Docusaurus文档网站
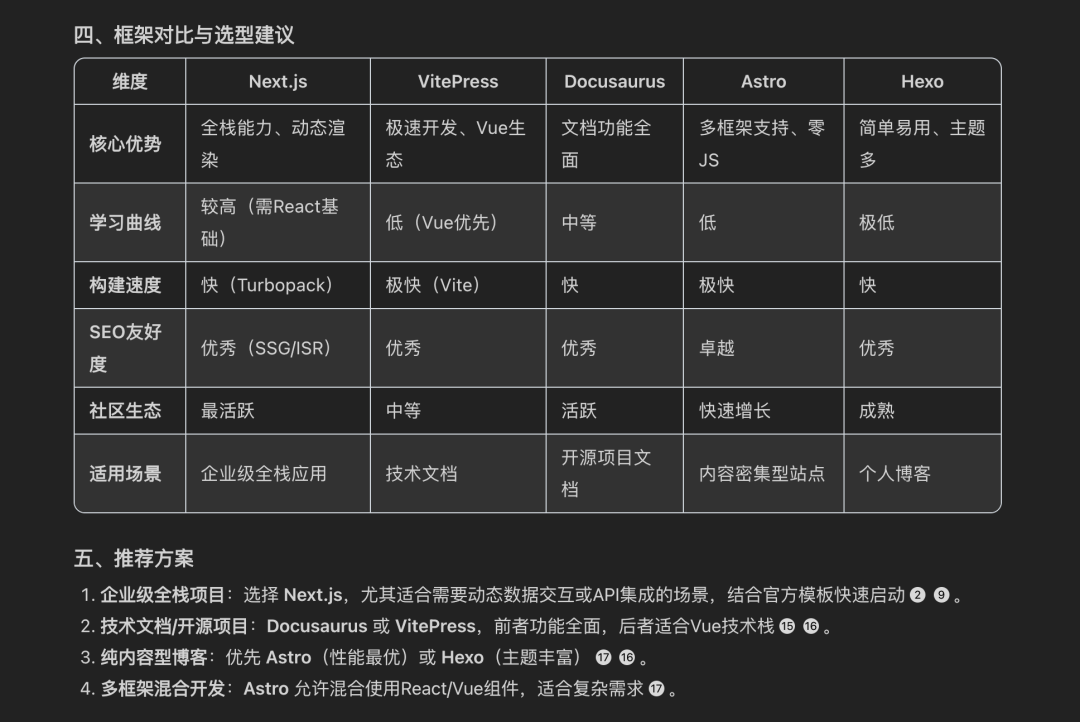
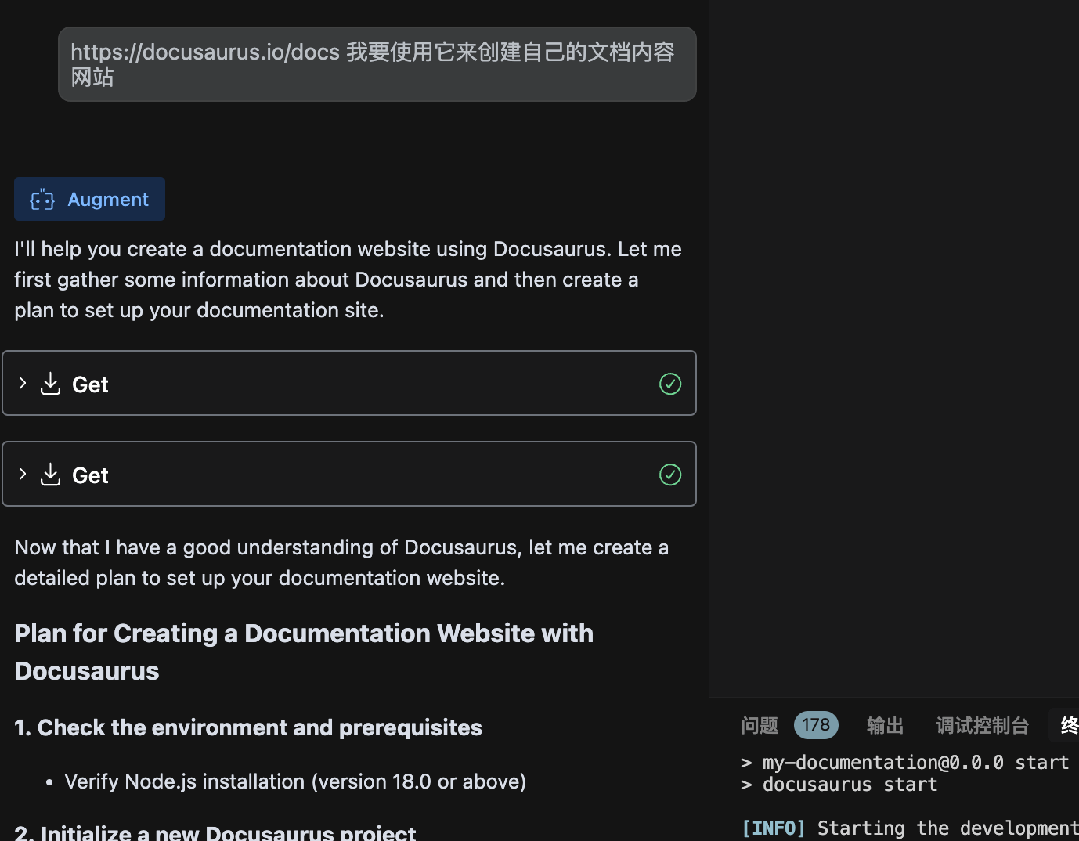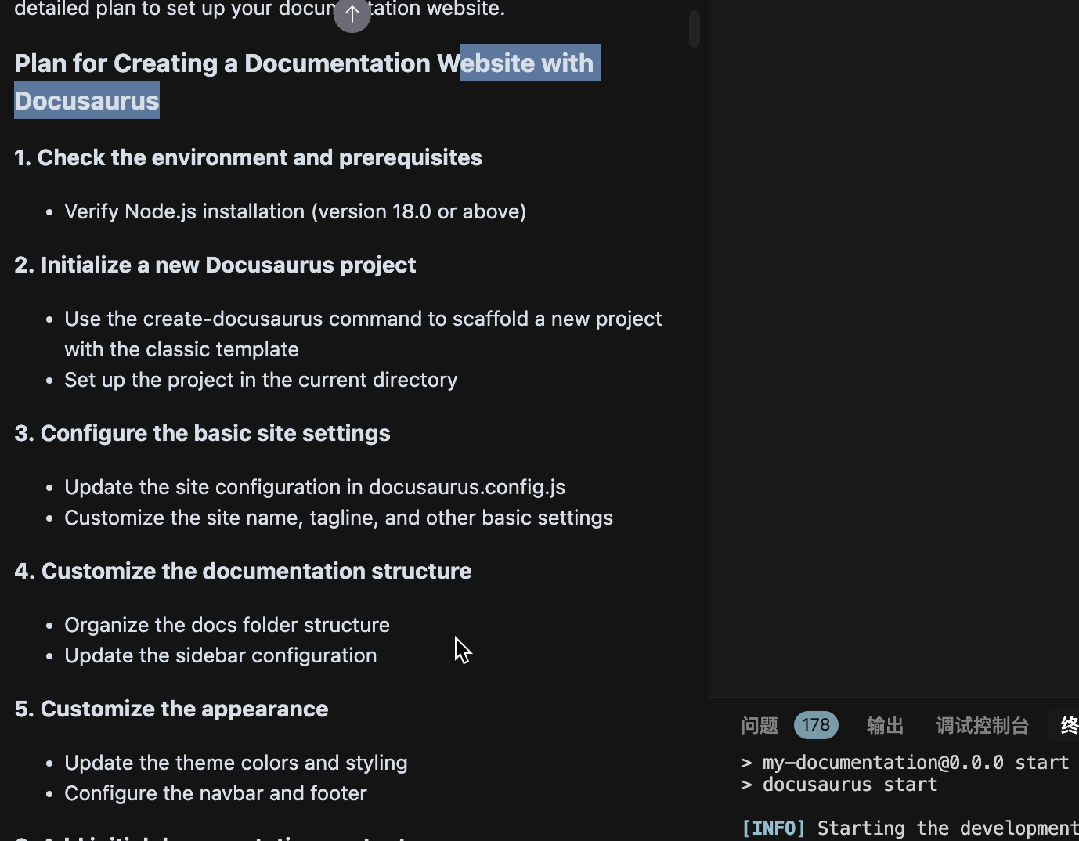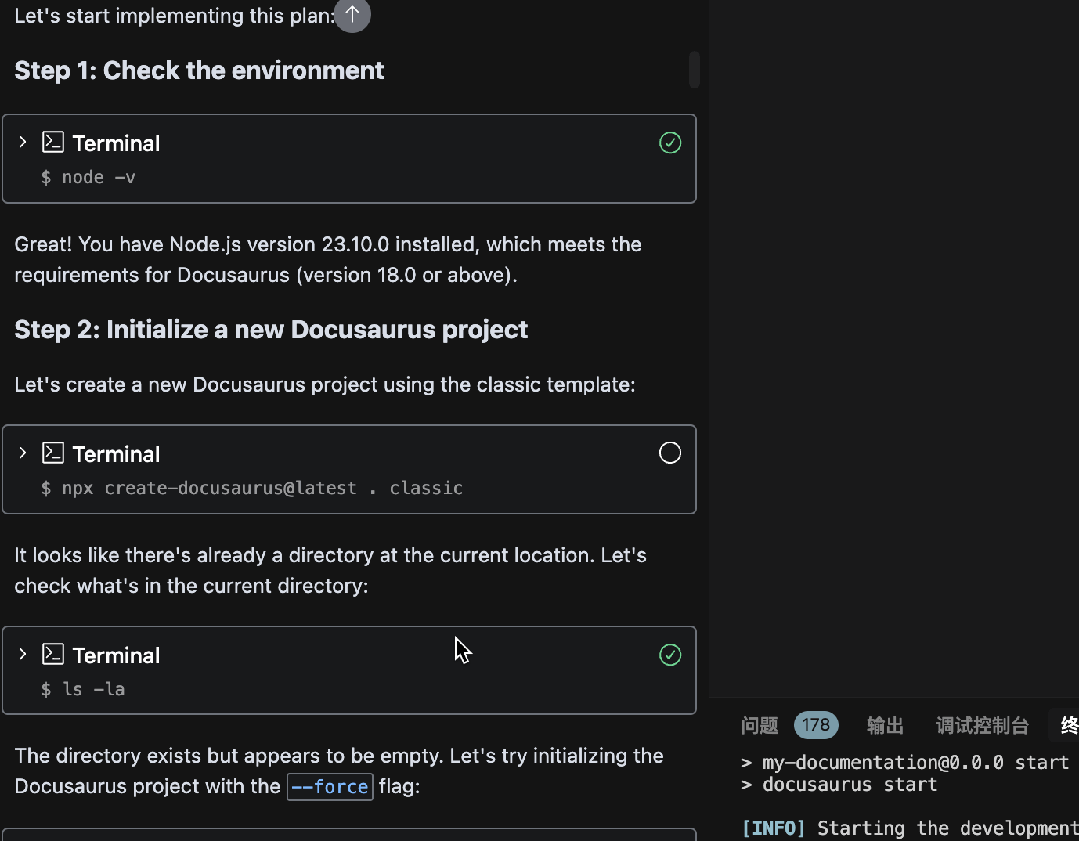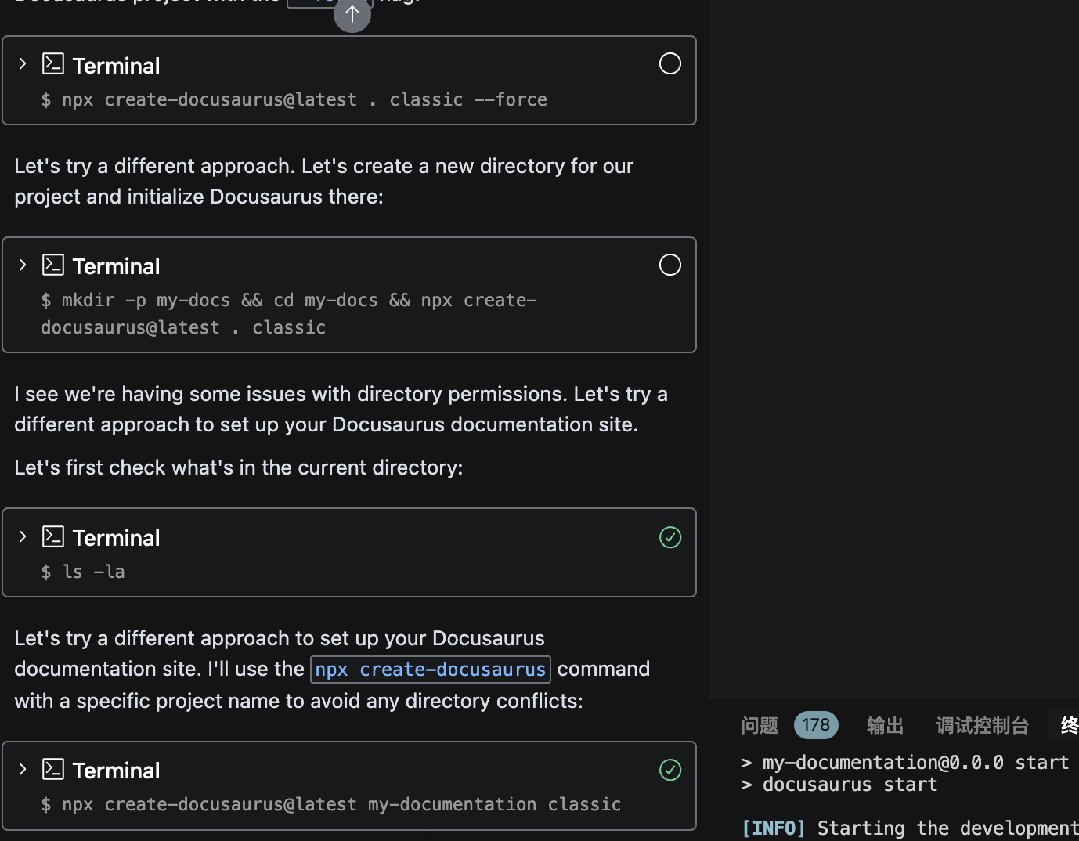
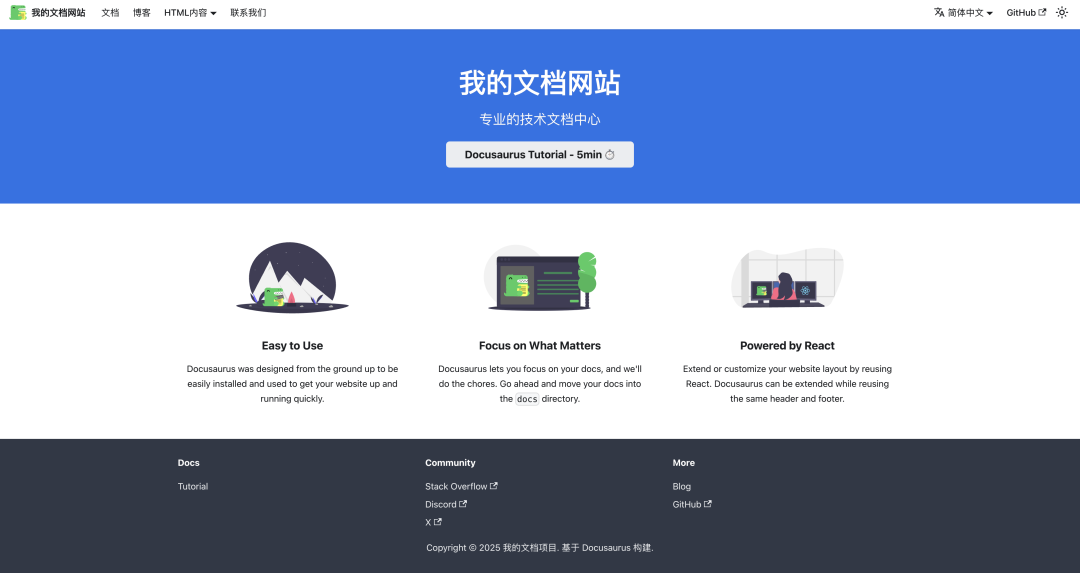

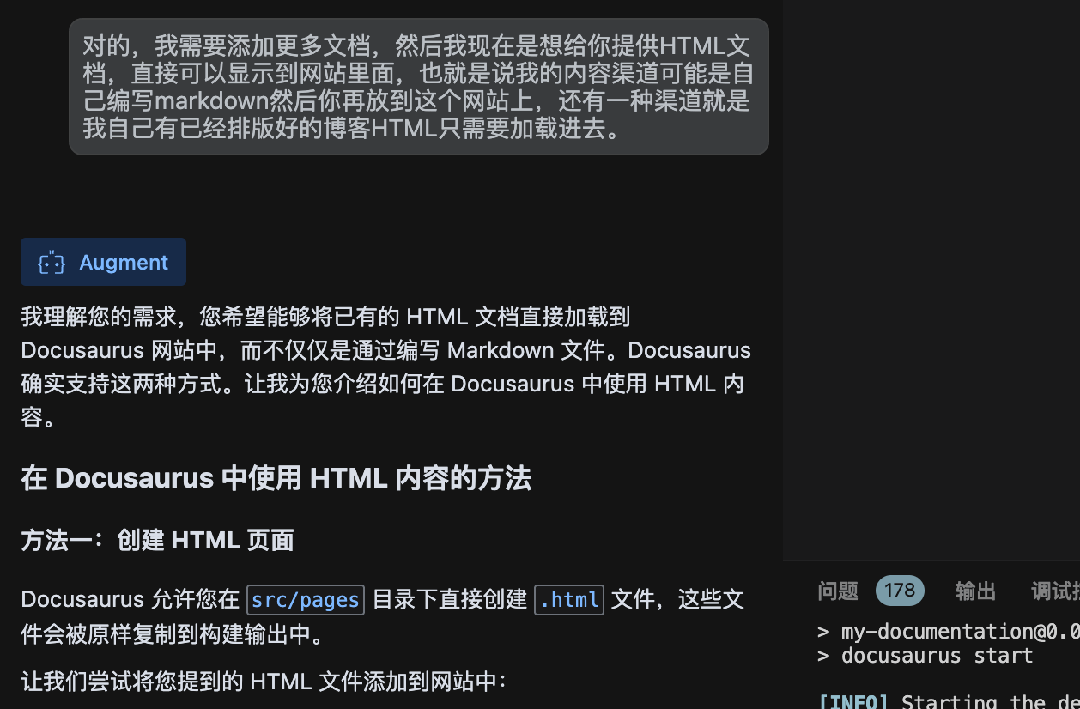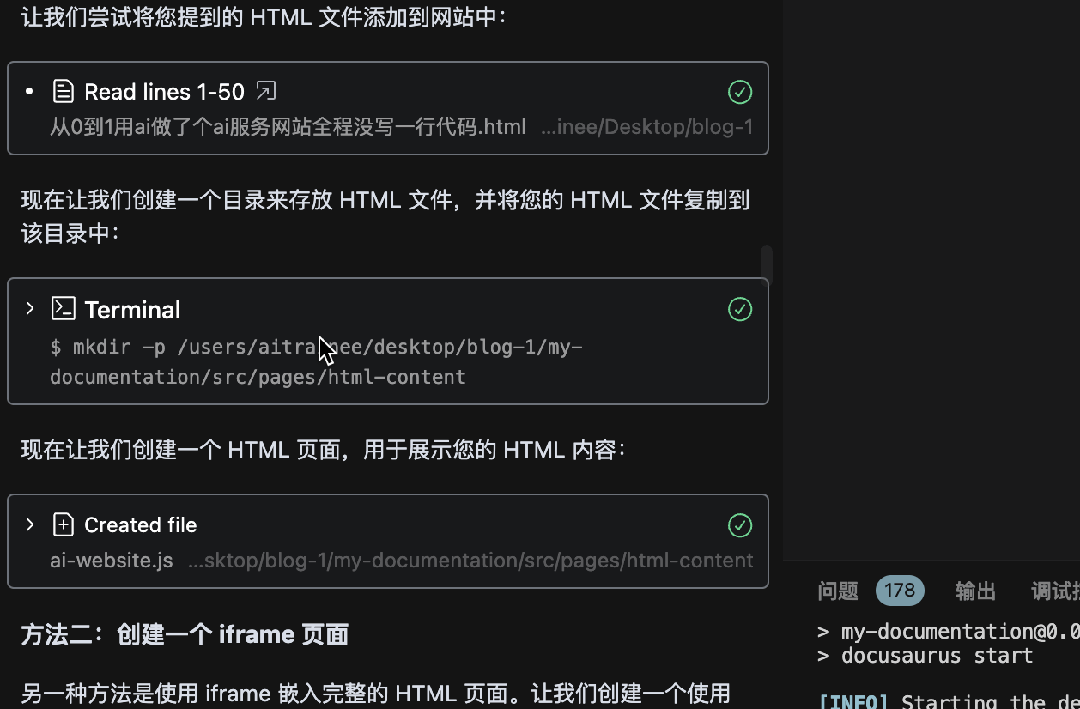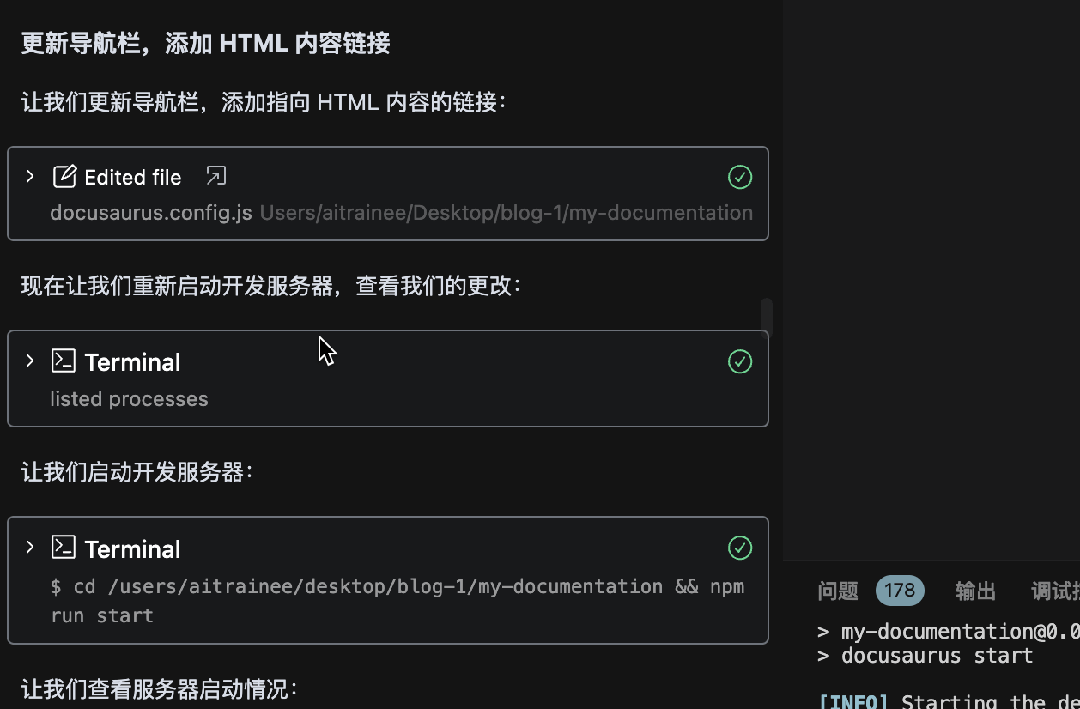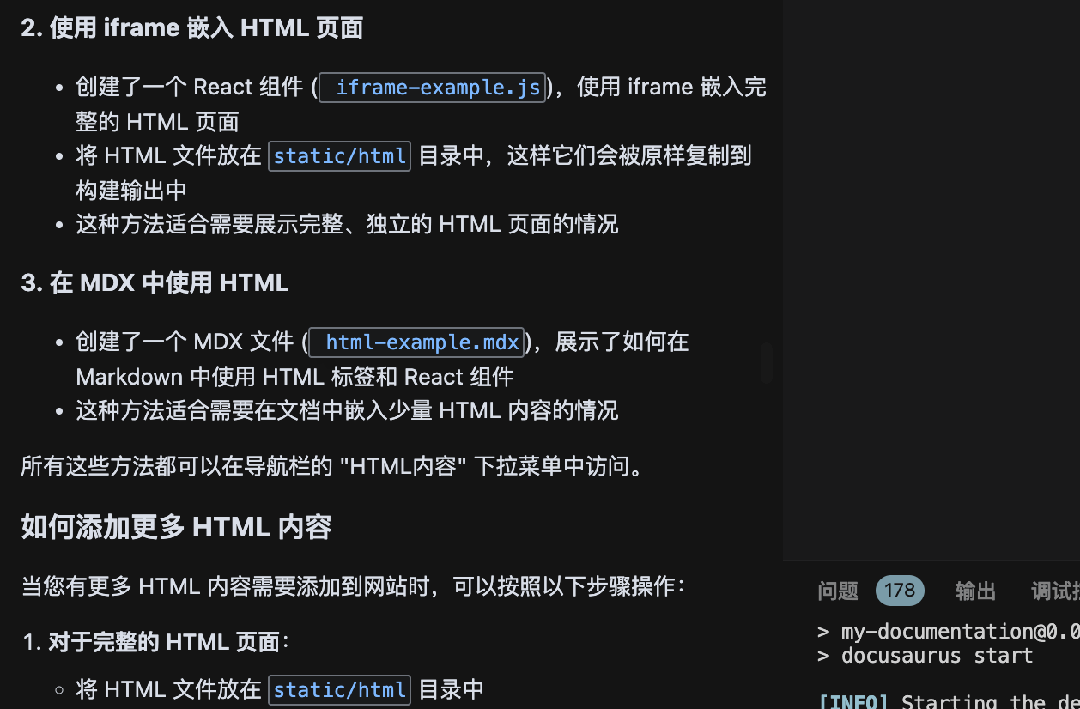

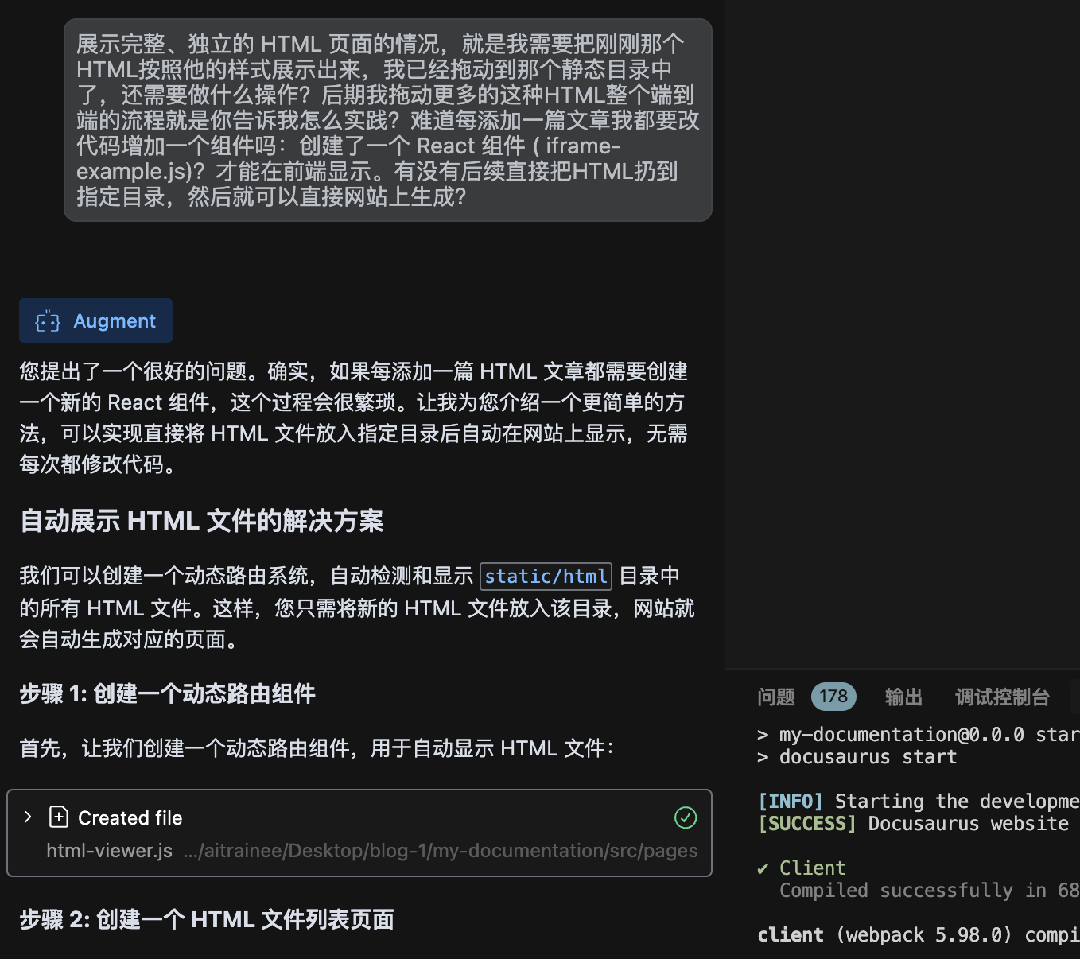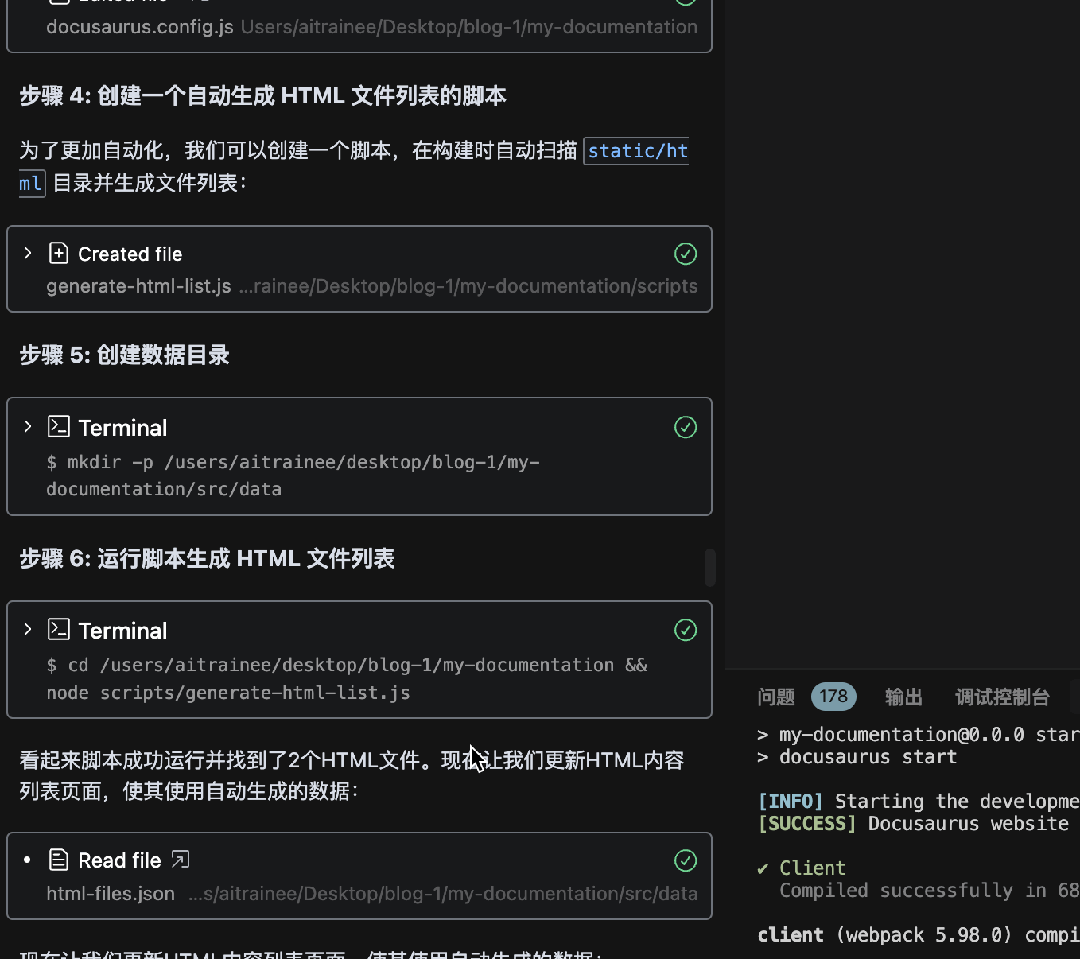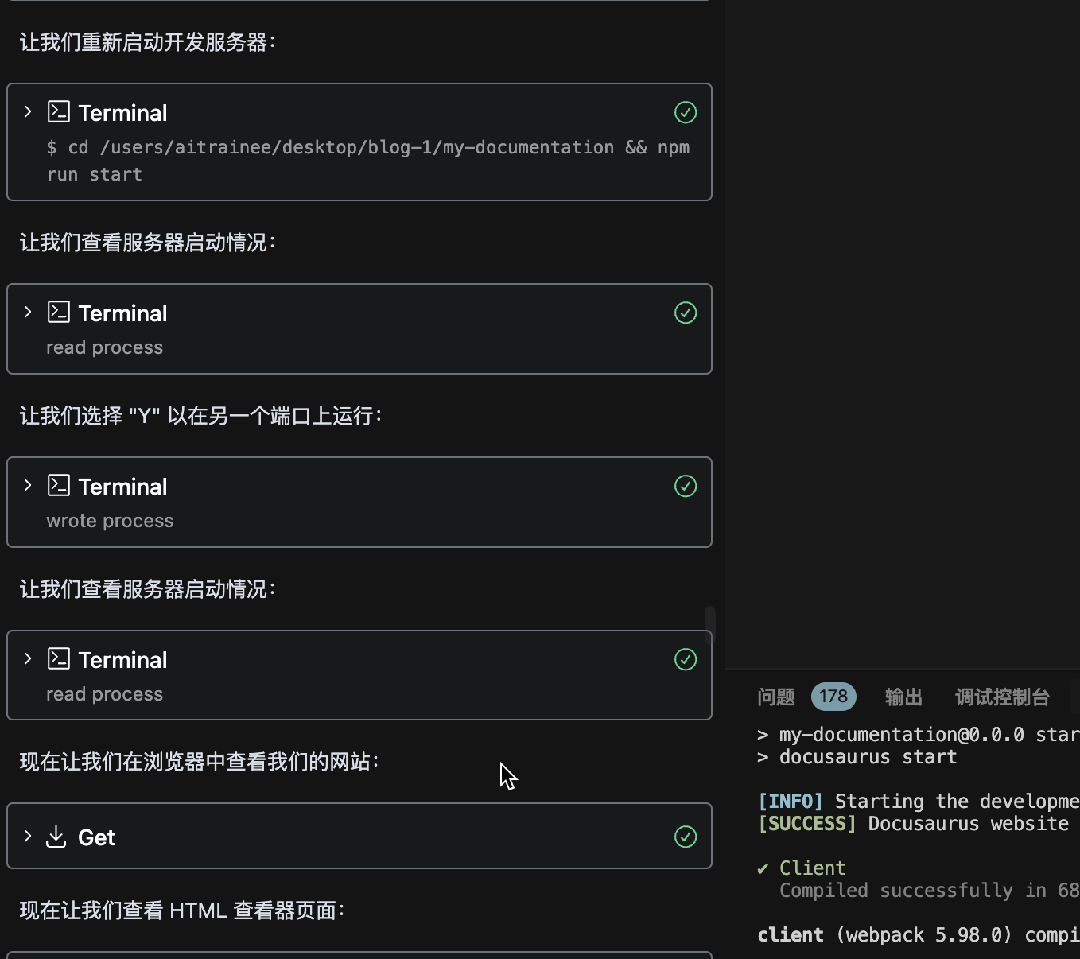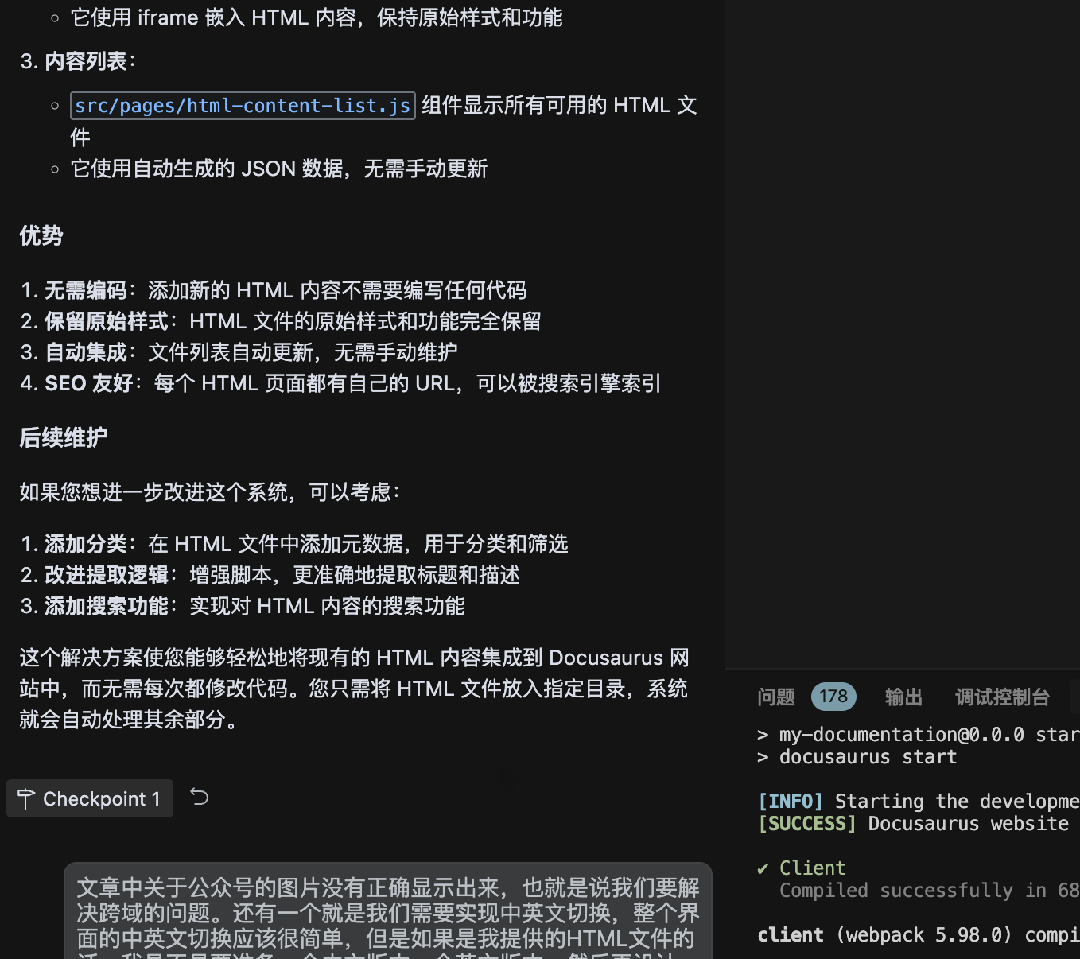

怎么玩转 Augment?
就是个 IDE 插件,支持 VS Code 和 JetBrains 全家桶 (IntelliJ, WebStorm, PyCharm 等)。一般用自动Agent模式,还有几点:
- 聊天 (Chat):
对着代码库提问,让它帮忙找 Bug,或者一起构思新功能。 我发现他这个模式下也支持mcp的调用。 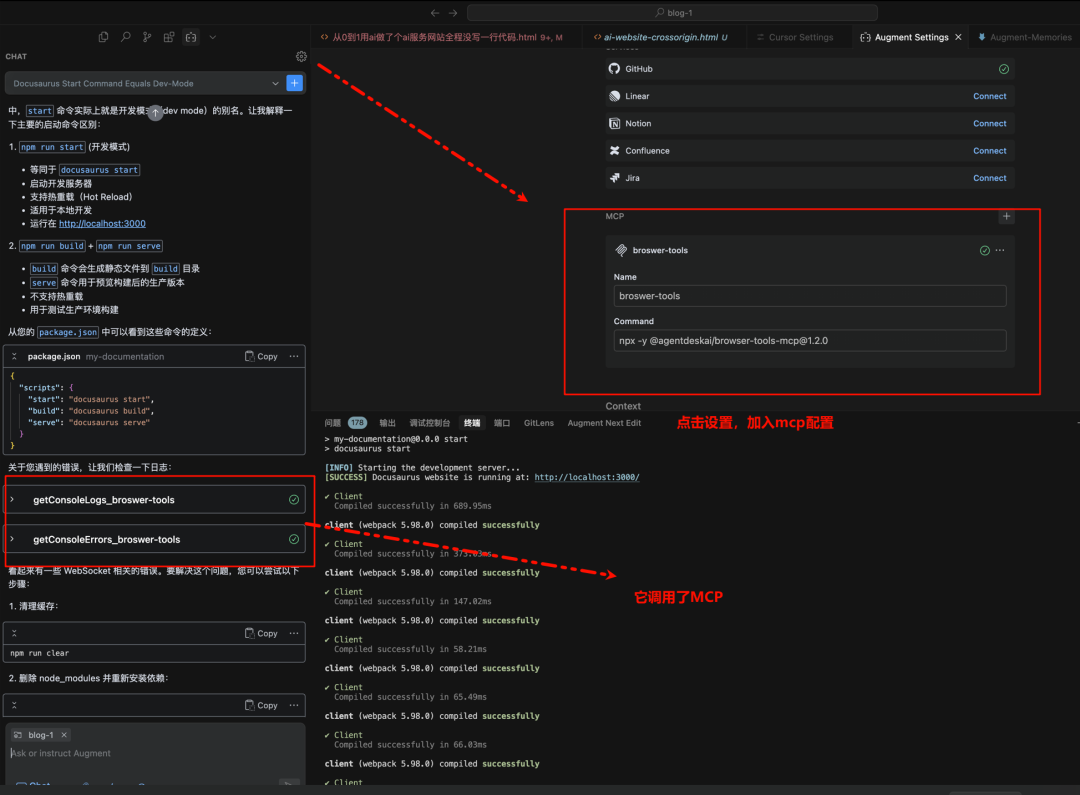
这里尝试的mcp是这个。 比Playwright更高效!BrowserTools MCP 让Cursor直接控制当前浏览器,AI调试+SEO审计效率狂飙! - 代码补全 (Code Completions):
快得飞起。写内部 API、写测试、用第三方 SDK,Tab 键一路按到底就行。 - 编辑建议 (Suggested Edits):
你改了一个地方,它能自动找出整个代码库里其他需要跟着改的地方,并给出建议。有人说靠这个功能,写 PR 几乎就是一路点点点。当然,这个功能cursor和windsurf也有。 - Slack 机器人:
永远在线的 Slack 机器人回答问题,哪怕队友都下线了。遇到问题 @ 它一下,别浪费开发时间干等。
Augment 是第一个专为 团队 设计的 AI 编程平台。
AI编码最佳实践
Augment Agent 使用经验指南:
Agent 这玩意儿贼强,但也还嫩着呢。想让它乖乖听话、高效干活,得掌握点门道:
Prompt 怎么写?
别偷懒,信息给足!说得越细,它干得越好。
Agent 跑偏了咋办?
-
错得离谱:删档重来,开个新会话。 -
小错不断:耐心点,提示它往回纠正。 -
终极大招:用检查点功能,一键回到解放前。
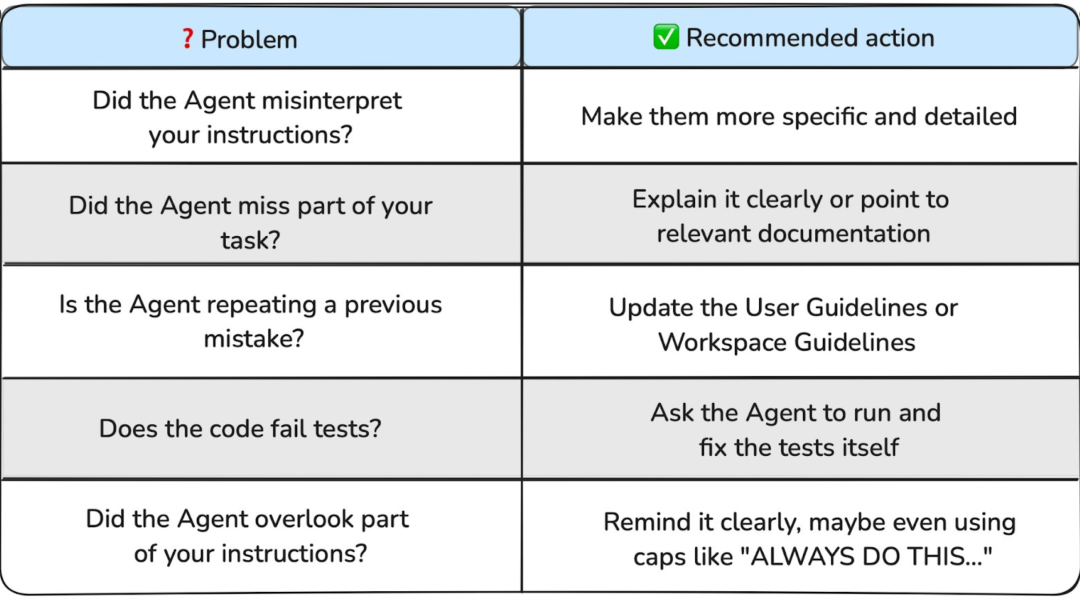
啥时候能信它?慢慢来,别急。
Agent 干活时,你能干啥?
-
新手:老实看着,点点头批准。 -
中级:可以摸鱼干点别的。 -
大神:跟它并肩作战,实时指挥、纠偏。

附AI编码最佳实践文档:https://www.augmentcode.com/blog/best-practices-for-using-ai-coding-agents
Augment开炮:AI 模型选择器是失败的设计。
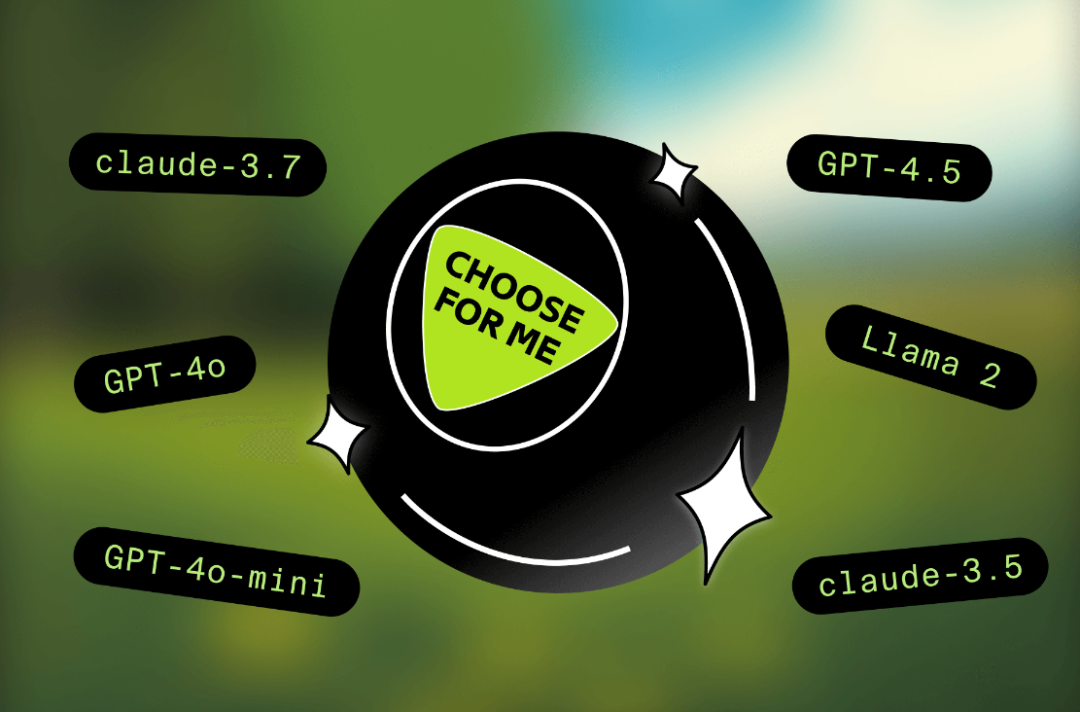
又列举Sam Altman :模型选择器,用户体验就是不行。

关于他说到的这一点,其实现在的Cursor既提供模型选择选项又提供自动模型选择选项,甚至提供自定义agent模式。灵活度方面很高。
最新的模型,不一定就是最好的
很容易觉得,用上最新、最强的模型,效果肯定更好——但现实中 LLM 不是这么玩的。
-
比如 Sonnet 3.7,挺强,但得仔细调教,不然话太多。 -
GPT-4.5 发布时没啥水花,因为在实际任务里,大家没觉得有啥提升。
根本问题是:LLM 的质量取决于输入质量。 没有正确的上下文,再牛的模型也白搭。
官方表示:” 这就是为啥 Augment 要死磕一个能搞定企业级代码库的 实时上下文引擎 (Context Engine)。它能确保 LLM 在正确的时间拿到正确的上下文,让响应更准、更相关、更有用。
当别人都在卷 UX、列一堆模型让你选的时候,我们的赌注是上下文,不是下拉框。 我们不是搞个简单的本地索引加基础搜索,指望它撞大运找到对的上下文。我们是实打实地构建了一个真正的上下文引擎,它深度理解企业级代码库,动态检索最相关的信息,喂给 LLM 最需要的东西,从而给出高质量、高相关的建议。“
模型选择?交给Augment就行了
Augment 不给你模型选择器,因为 Augment 替你搞定了复杂性。它会根据以下因素动态选择最佳模型:
✅ 任务类型 (代码补全、聊天、行内建议)
✅ 真实世界编码任务的性能基准
✅ 成本 vs. 延迟的权衡
✅ AI 模型的最新进展
官方表示:” 选哪个 AI 模型,是我们的问题,不是用户的问题。 我们非常严肃地对待这个责任,我们世界级的 AI 研究团队建立了一套广泛的测试和评估标准,确保最佳结果。
每个考虑用于 Augment Code 产品的模型,都要经过严格的“试镜”。这包括外部基准测试 (如 swebench-verified)、广泛的内部试用、与 20 多个全职测试人员进行的 A/B 测试,以及内部基准评估。
模型选择器浪费开发者时间(和钱)
选择的幻觉可能感觉很爽,但实际上增加了摩擦。想象一下,每次 Google 搜索都要先选个搜索算法?或者跑代码前先在 10 个编译器里挑一个?
更坑的是,模型选择器可能带来意外成本。在提供模型选择器的工具里,有些模型用一次就比别的贵很多。这对采用这些工具的组织来说,成本完全不可预测。当最新的模型出来时,你可能面临天价账单,却没有任何保证工程师能从中获益。
用 Augment,你不用担心使用限制或意外费用。不管我们后台给你用了哪个模型,都是无限次使用。 不用切换设置,不用反复猜测,没有隐藏费用——只有最适合当前任务的 AI。
如果你的 AI 编程助手还需要你选模型,那它就没干好自己的活。“
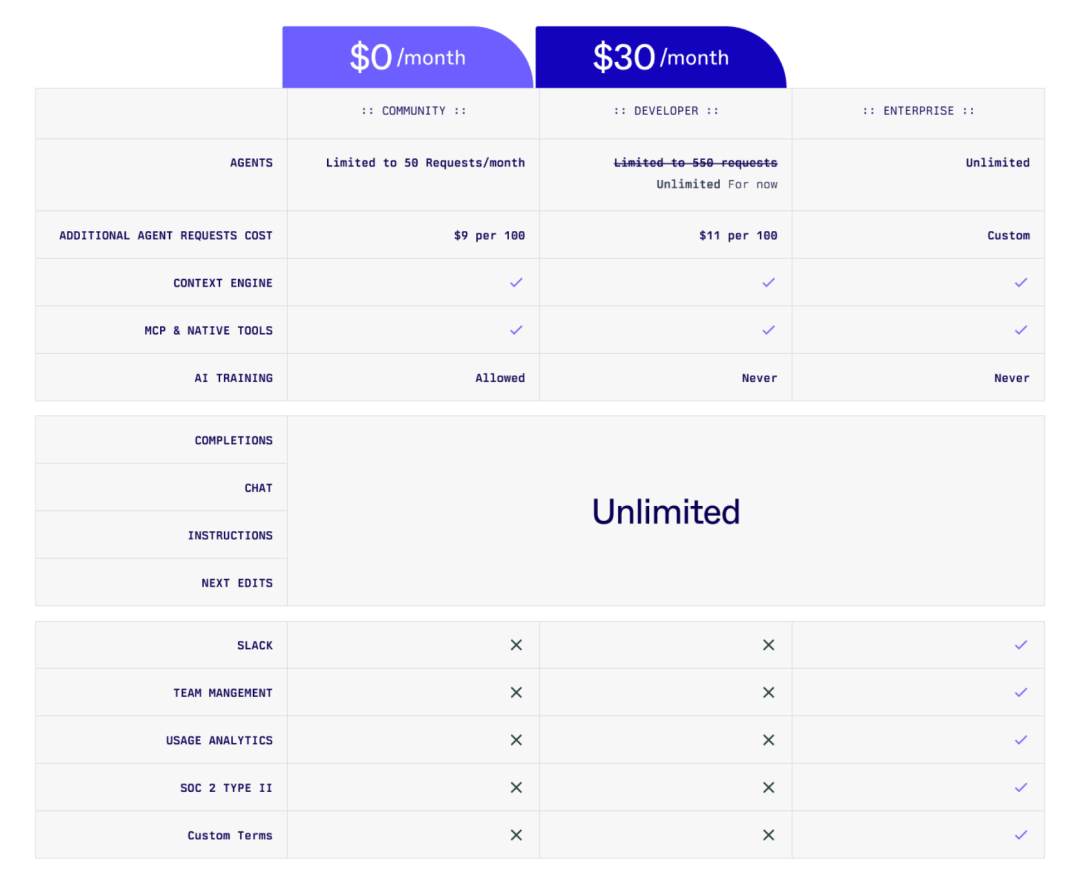
Augment:定价层
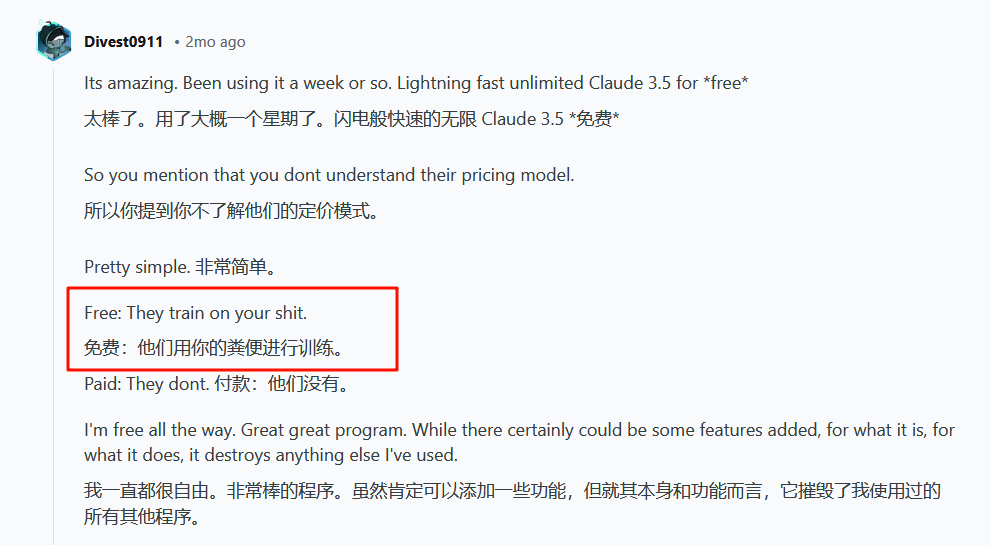
 进行训练,难绷。
进行训练,难绷。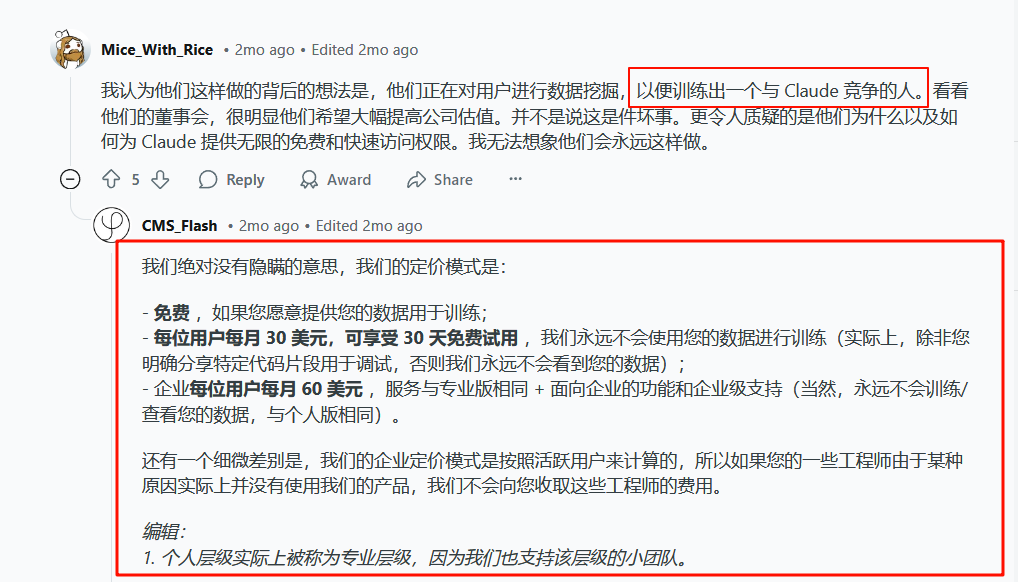
本号知识星球(汇集ALL订阅频道合集和其他):

星球里可获取更多AI绘画实践以及其他AI实践:
本号连载过许多MCP的文章,从概念到实践再到自己构建:
MCP实践:Cursor + MCP:效率狂飙!一键克隆网站、自动调试错误,社区:每个人都在谈论MCP!
最新MCP托管平台:让Cursor秒变数据库专家,一键对接Github,开发效率暴增!
Blender + MCP 从入门到实践:安装、配置、插件、渲染与快捷键一文搞定!
比Playwright更高效!BrowserTools MCP 让Cursor直接控制当前浏览器,AI调试+SEO审计效率狂飙!
手把手教你配置BrowserTools MCP,Windows 和 Mac全流程,关键命令别忽略。
2分钟构建自己的MCP服务器,从算数到 Firecrawl MCP(手动挡 + AI档)
太简单了!Cline官方定义MCP开发流程,聊天式开发,让MCP搭建不再复杂。
[1] https://docs.augmentcode.com/
点这里👇关注我,记得标星哦~
(文:AI进修生)