
开发一个可用的RAG系统需要整合至少5个过程:数据存储→向量数据库→嵌入模型→LLM→定制逻辑。更可怕的是,随着数据变化,开发者需要手动重新索引和生成嵌入向量,才能保持系统相关性和性能。本该简单的”提问-智能回答”体验,变成了脆弱的胶水代码、脆弱的集成和持续的维护工作。
Cloudflare近日宣布推出的AutoRAG服务可能要改变了这一局面。AutoRAG 的核心亮点包括:
-
全托管端到端管道:自动化处理从数据摄取、分块、嵌入到向量存储(使用 Cloudflare Vectorize)、语义检索和响应生成(使用 Workers AI)的完整流程。 -
自动化索引与更新:持续监控数据源并在后台自动重新索引,无需手动干预即可保持 AI 知识库的实时性。 -
简化开发体验:将复杂的 RAG 组件(数据存储、向量数据库、嵌入模型、LLM、自定义逻辑)抽象化,使开发者能专注于应用构建而非底层管道维护。 -
基于 Cloudflare 生态构建:利用 Cloudflare 的 R2、Vectorize、Workers AI 和 AI Gateway 等成熟组件,提供透明的性能、成本和行为可见性。
从技术角度分析,AutoRAG 的工作流程主要分为 索引(Indexing) 和 查询(Querying) 两个核心过程。
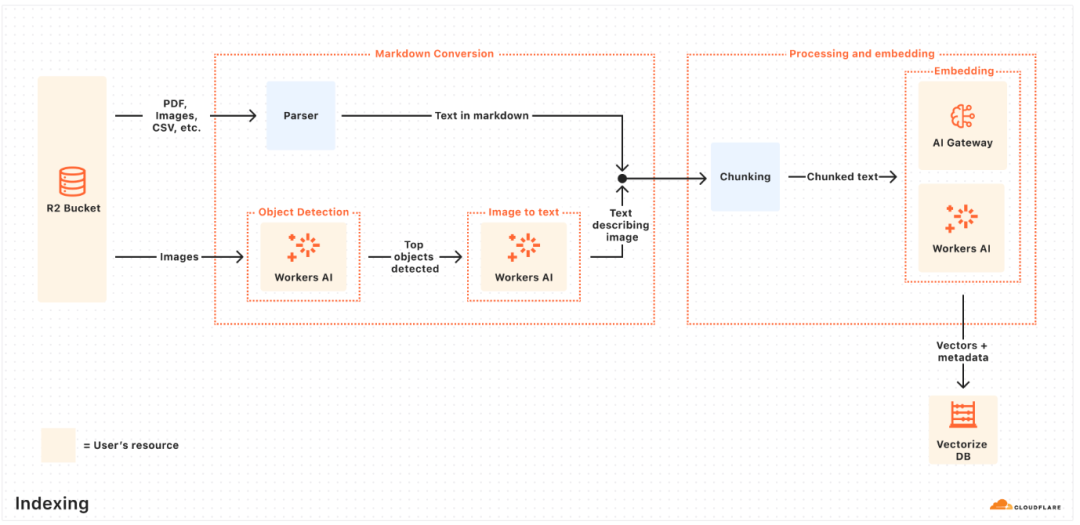
索引过程是异步的后台任务,它自动从指定数据源(目前支持 Cloudflare R2)读取文件(PDF、图像、文本、HTML、CSV 等),使用 Workers AI 将内容统一转换为 Markdown 格式(包括利用对象检测和视觉到语言转换处理图像),接着进行文本分块和嵌入向量化处理,最终将向量及元数据存储在账户下的 Vectorize 数据库中。该过程会周期性自动运行,处理新增或更新的文件。

查询过程则是同步触发的,当接收到用户请求后,AutoRAG 可选地使用 LLM 重写查询以优化检索效果,然后将查询向量化,在 Vectorize 数据库中执行向量搜索,检索最相关的文本块及其原始内容,最后结合原始查询,利用 Workers AI 的文本生成模型生成基于检索上下文的回应。
在开放测试期间,启用 AutoRAG 是免费的,索引、检索和增强等计算操作不产生额外费用。每个账户限制创建 10 个 AutoRAG 实例,每个实例最多支持 100,000 个文件。Cloudflare 计划在 2025 年继续扩展 AutoRAG 的功能,包括支持更多数据源(如直接网站 URL 解析、Cloudflare D1 结构化数据)以及引入更智能的响应生成技术(如内置重排、递归分块)以提升结果质量。
5分钟快速上手教程
步骤1:创建Worker抓取网页内容
import puppeteer from"@cloudflare/puppeteer";
interface Env {
MY_BROWSER: any;
HTML_BUCKET: R2Bucket;
}
exportdefault {
async fetch(request: Request, env: Env) {
const browser = await puppeteer.launch(env.MY_BROWSER);
const page = await browser.newPage();
await page.goto(targetUrl);
const htmlPage = await page.content();
await env.HTML_BUCKET.put(key, htmlPage);
await browser.close();
returnnew Response('Success');
}
}
步骤2:创建AutoRAG实例
-
在Cloudflare仪表板选择AI > AutoRAG -
关联R2存储桶(如html-bucket) -
选择默认嵌入模型和LLM -
配置AI Gateway监控 -
命名实例并创建
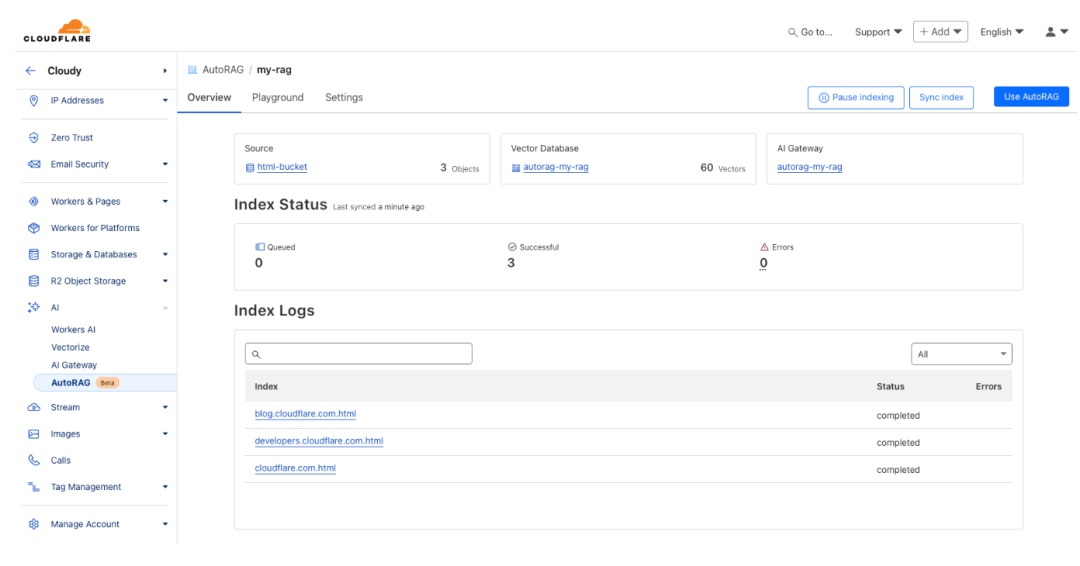
步骤3:集成到应用
const answer = await env.AI.autorag('my-rag').aiSearch({
query: '什么是AutoRAG?'
});
小结:
就如Cloudflare CTO所讲,”这是我们在AI基础设施民主化道路上的重要一步,让每个开发者都能轻松构建上下文感知的AI应用,而不必担心底层复杂性。”这将进一步降低了构建和维护 RAG 系统的复杂性和成本,这将使得RAG技术将更加普及化和易于集成。
官方文档:https://developers.cloudflare.com/autorag
公众号回复“进群”入群讨论。
(文:AI工程化)