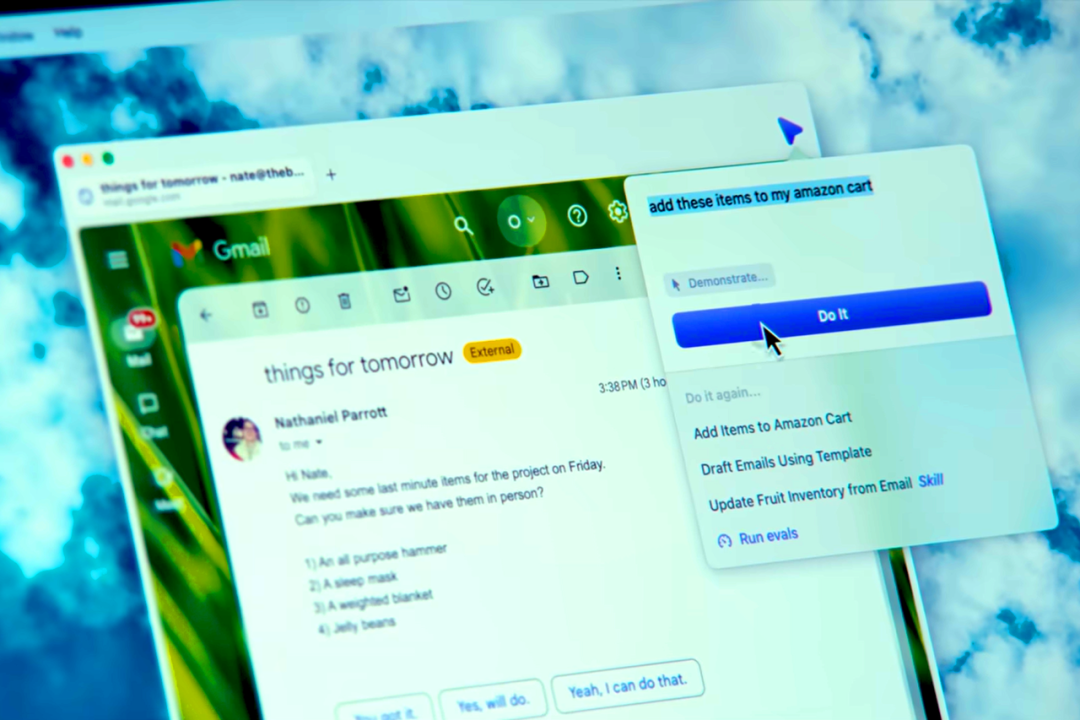
在早期演示中,Dia 就展示了浏览器如何代表人类执行任务。
例如,Dia 通过自己浏览亚马逊,找到这些物品并将它们添加到购物车中。这正是浏览器能做到的事——利用它对你所有 Web 应用和浏览数据的访问权限,替你完成任务。
尽管,如今的 Dia 距离这一目标尚有差距,但这种从被动响应到执行理念的转变,却与当下大火的 Agent 不谋而合。
在 OpenAI 推出的 Operator,以及智谱最新发布的「沉思」Agent 中,我们也看到浏览器开始代替用户采取行动,比如预订机票、比较产品价格、填写表单,甚至完成在线购物。
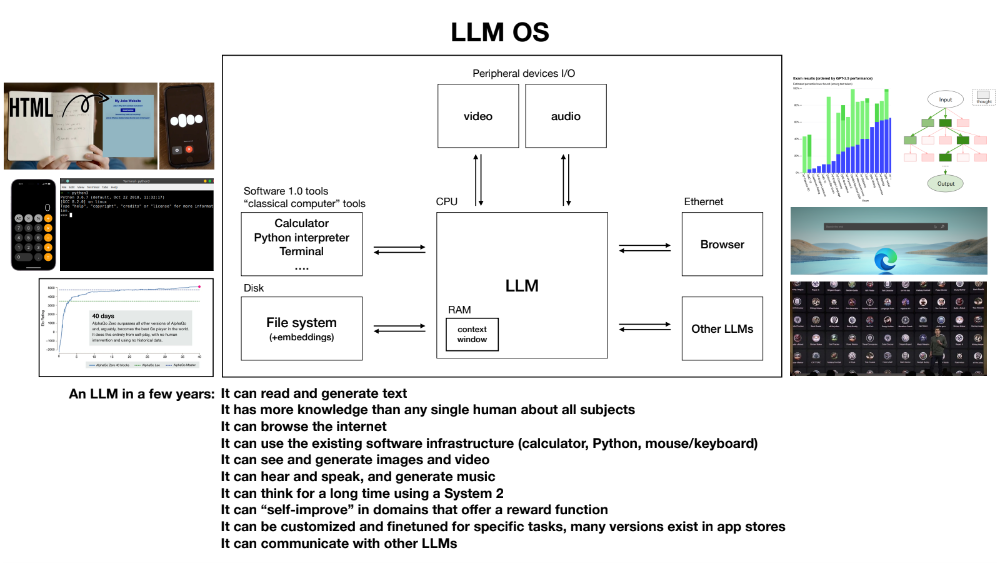
为了更好地了解这一趋势,不妨再来看看 OpenAI 前 AI 大神 Andrej Karpathy 提出的「LLM 操作系统」设想:
LLM 作为内核:LLM 是整个系统的中心,类似于传统操作系统中的 CPU,负责处理核心任务和协调其他组件。
存储体系:包括上下文窗口(类似 RAM),用于存储当前正在处理的信息。
文件系统:用于长期存储数据,类似于传统计算机的硬盘。
向量数据库(embeddings/vector databases):用于存储和检索嵌入向量,是 LLM 进行语义理解和检索的重要基础。
浏览器:作为 I/O 外设之一,用于访问互联网资源,获取实时信息。
多模态工具:支持处理文本、图像、音频等多种数据类型。
其他工具:如代码解释器、计算器等,用于辅助 LLM 完成复杂任务
从根源上讲,浏览器自诞生之初便紧密贴合人类需求,为人类而生的属性贯穿始终。传统浏览器依赖的 UI 自动化工具(如 Selenium)本质上是对人类操作的镜像模拟。
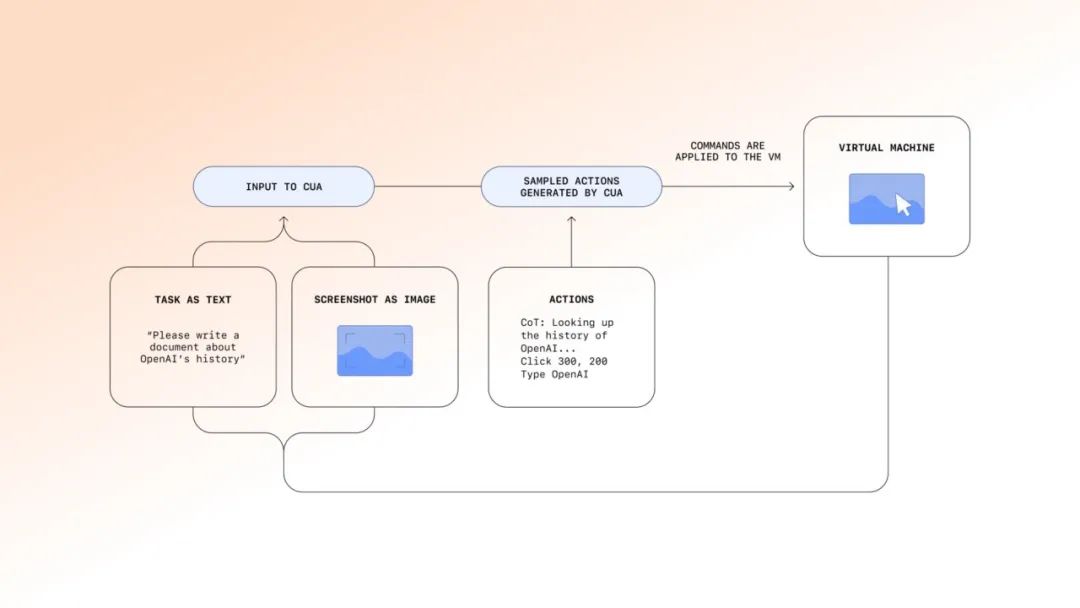
与图形化界面和手动操作有所不同,AI Agent 需要通过代码访问和解析数据与网页进行自动化交互,而动态加载的内容、复杂的页面结构,以及反爬机制(如验证码)的普遍应用,都是亟待解决的几道难关。
浏览器服务商 Browserbase 创始人 Paul Klein 也曾给出一些技术思路:
开发开源、高效的浏览器,减少浏览器启动时的等待时间和安装所需的资源量,提升运行速度和部署便利性。
利用 LLM 快速定位网页数据,VLM 基于截图识别元素,支持自然语言交互,无需复杂脚本,即使面对混淆或动态内容也能适应。
提供更可靠的 SDK 和 API 开发工具,简化开发流程,提高 AI Agent 使用体验。
更理想的状态是,AI Agent 与浏览器/网站则需要通过标准化协议直接通信,跳过视觉交互环节,基于数据接口(如 API、底层协议)实现自动化操作,完成从 「人→界面→数据」 到 「机器→协议→数据」的直连。
这段时间频繁出现在大众视野的 MCP,正是解决传统「人→界面→数据」模式瓶颈的一种方案。它通过客户端-服务器架构,将 AI Agent(主机/客户端)与外部资源(服务器)连接起来,用协议取代了界面操作。
简单来说,你可以把 MCP 想象成一个「万能接口」,就像电脑上的 USB-C 接口一样。这个接口让 AI 模型能够轻松地连接到各种外部资源,比如文件、数据库、在线服务等。
通过 MCP,AI 助手不仅能获取数据,还能直接对数据进行操作,比如读取文件内容、更新数据库记录等。
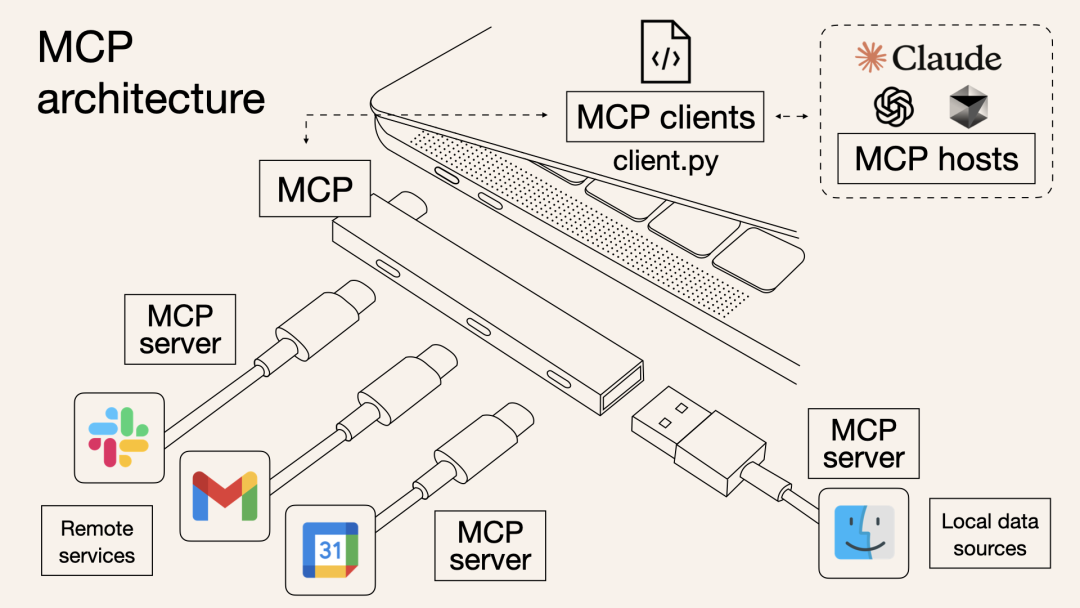
浏览器会继续服务人类,但会越来越适配 AI 的需求。人类下达命令,Agent 高效执行的协作模式将成为未来的常态。
从早期的命令行界面(CLI),到图形用户界面(GUI),再到如今迈向人机纯自然语言交互以及机器与机器的协议层交互,技术在复杂化,但交互方式却在不断简化。
现在,浏览器 2.0 时代已经开始,而 Web,远未走向死亡。
「AI 不会以应用程序的形式存在,也不会是一个按钮。我们相信它将是一个全新的环境——建立在 Web 浏览器之上,」Dia 的官网如是说。



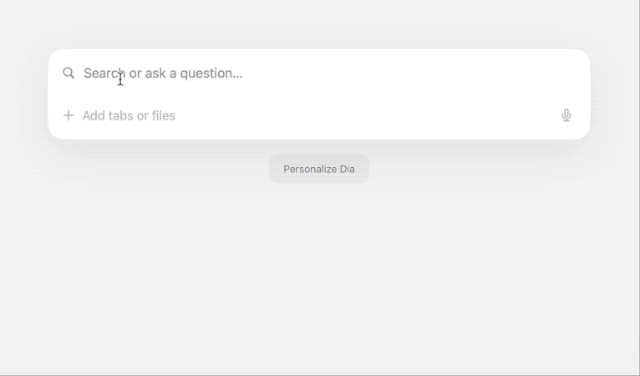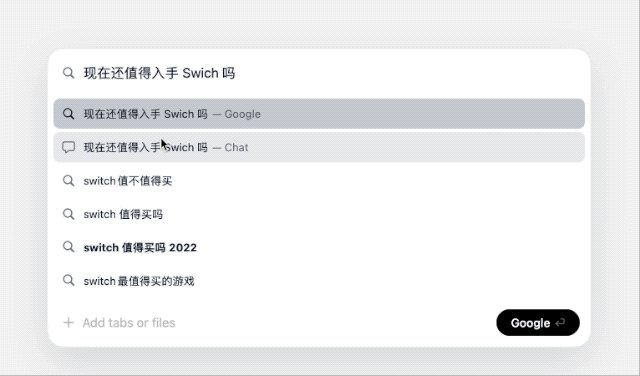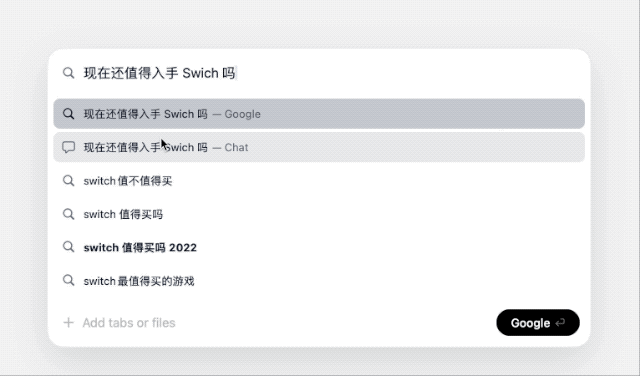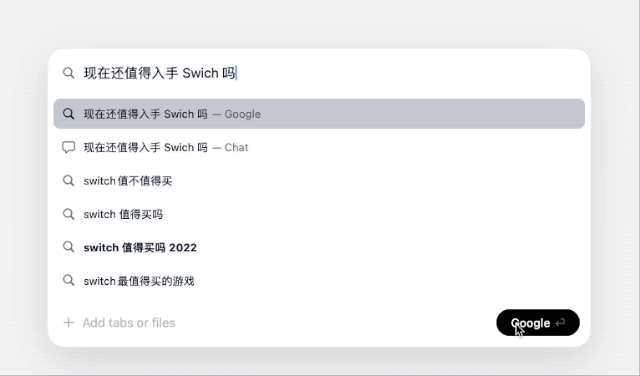
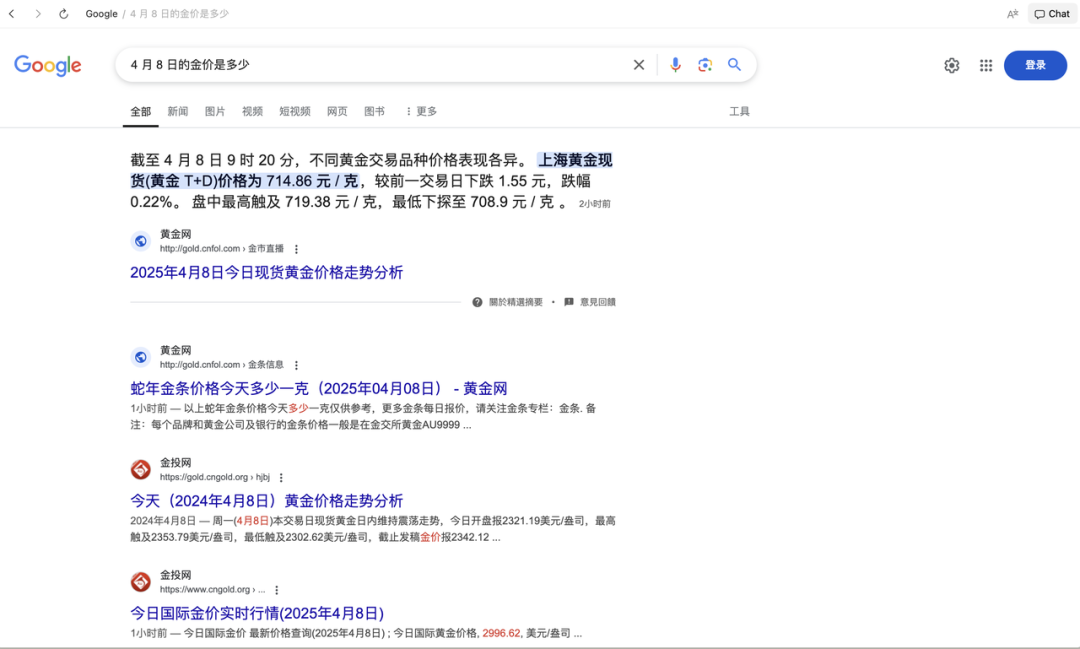


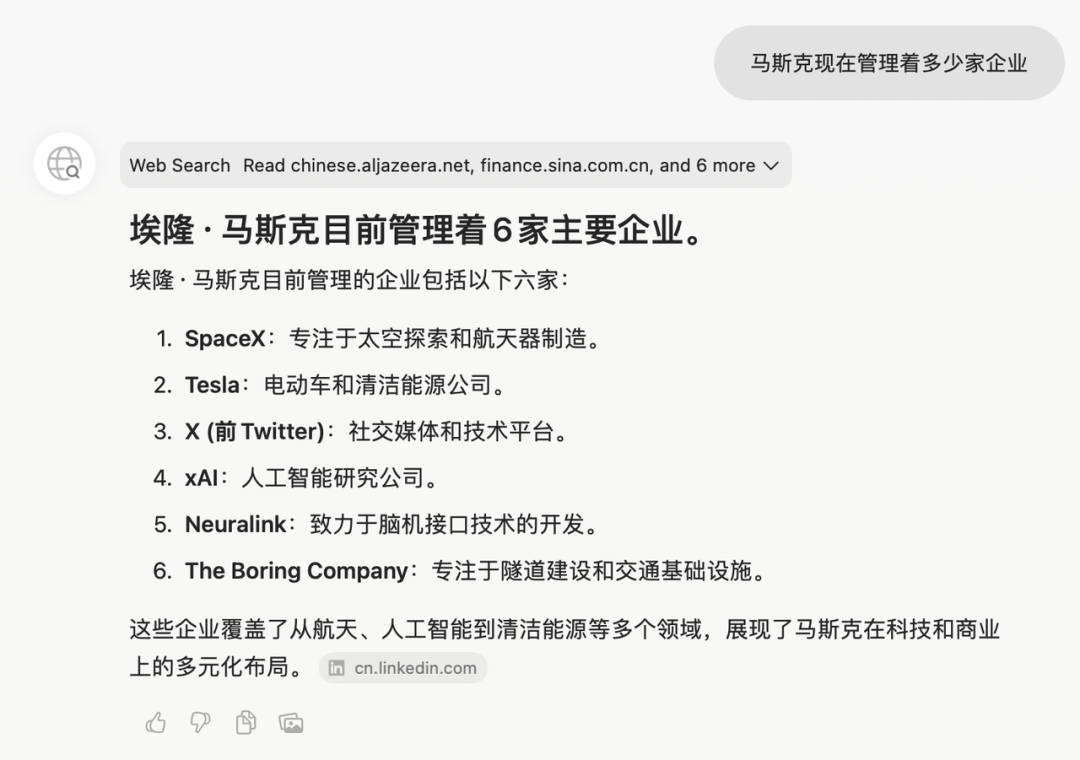
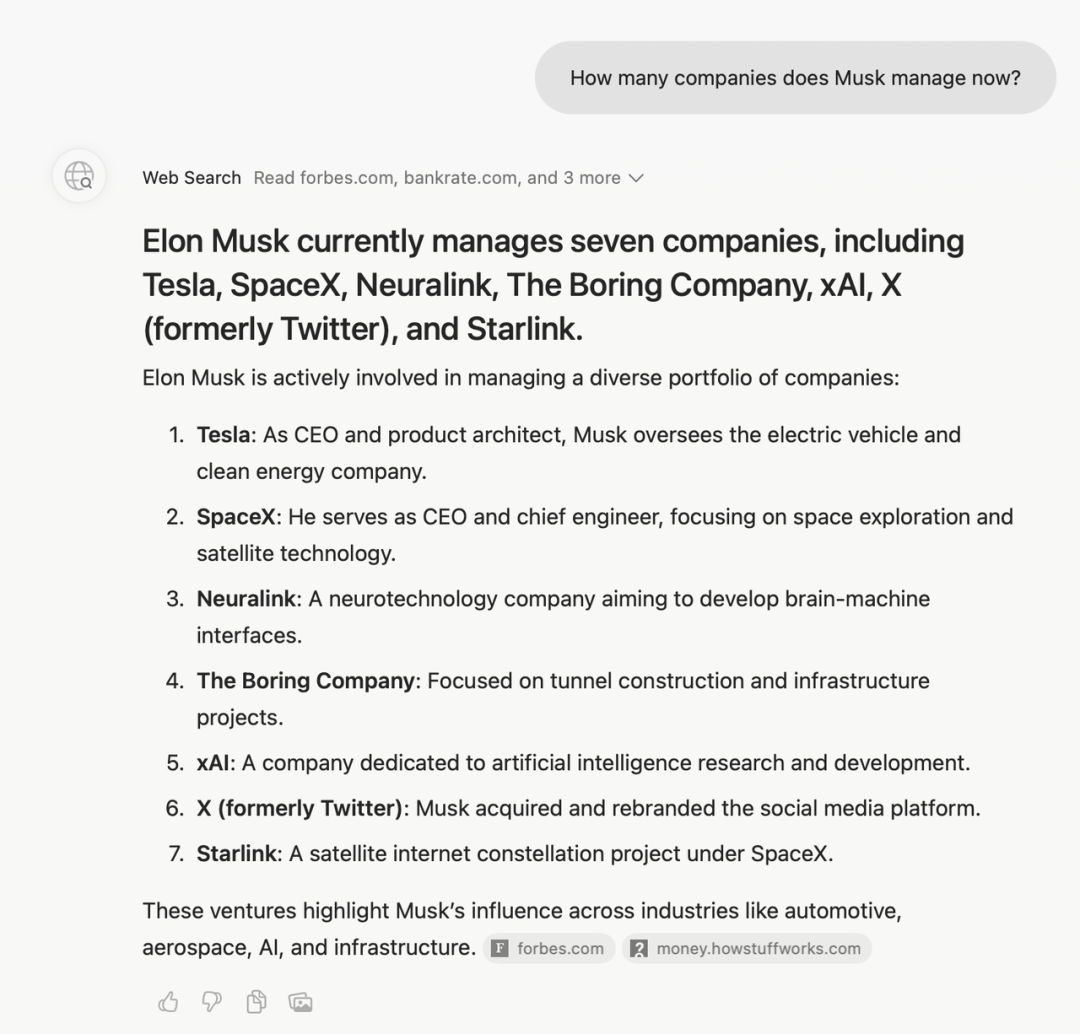
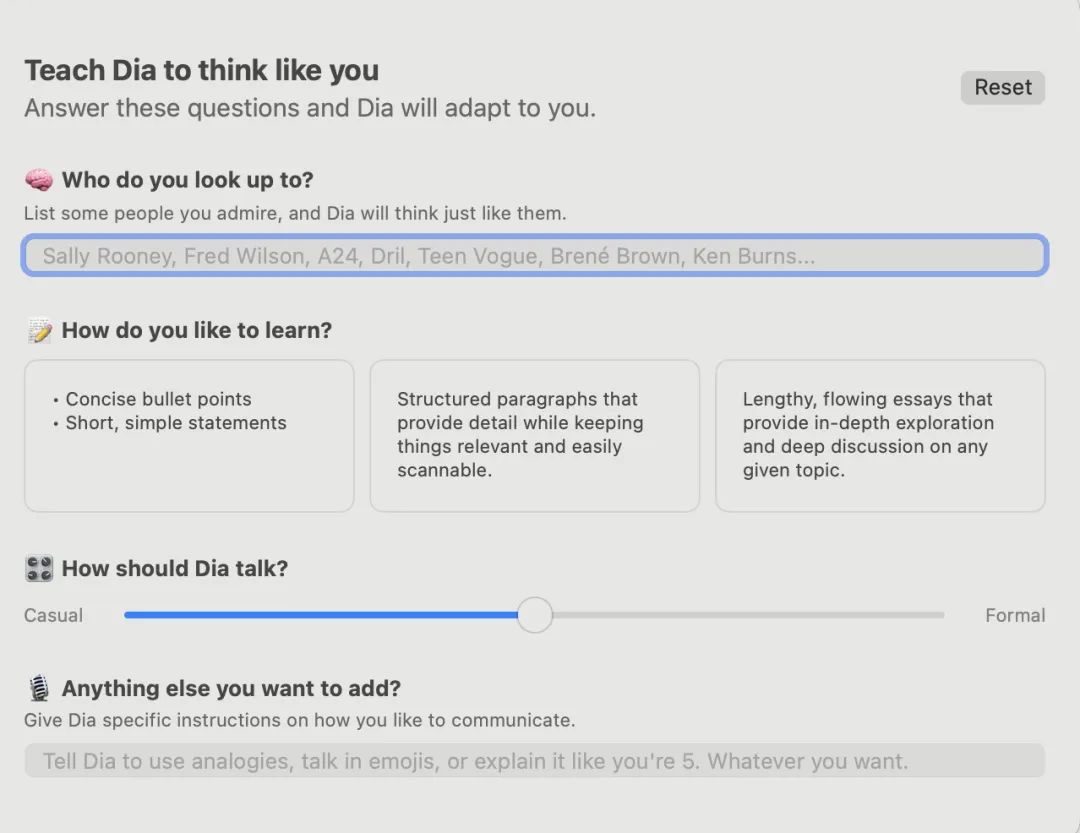



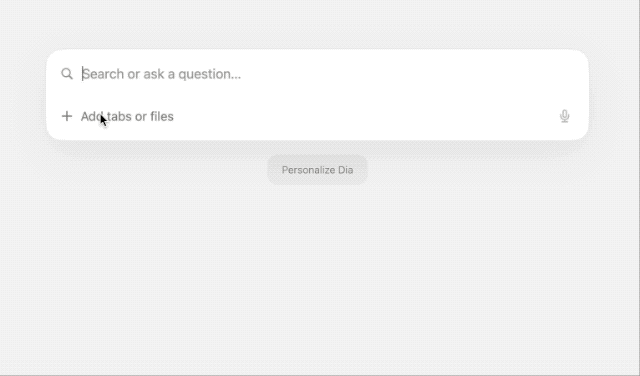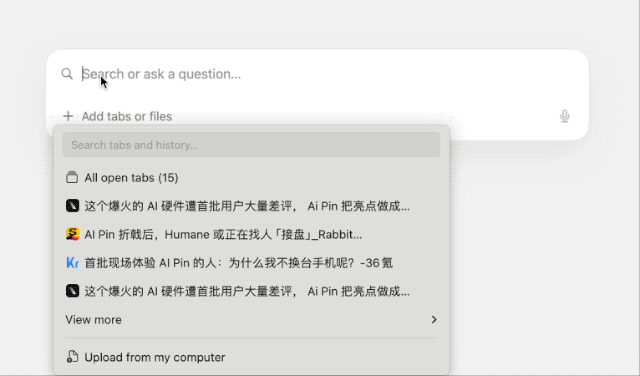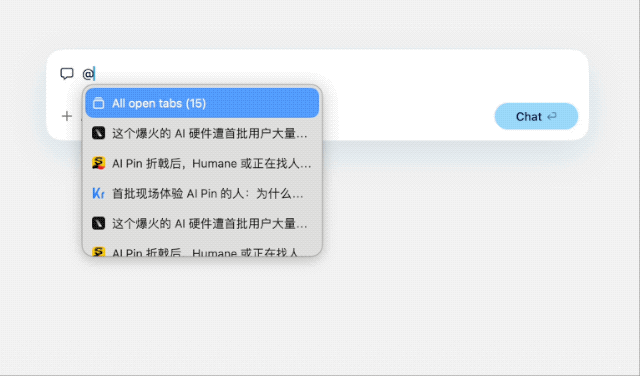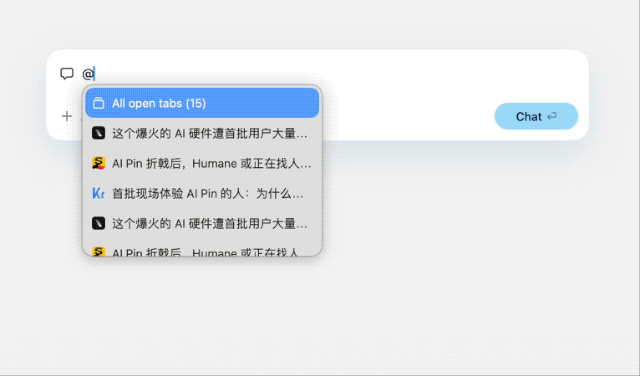



 下载地址:https://www.diabrowser.com/download
下载地址:https://www.diabrowser.com/download