

随着人工智能技术的不断发展,大语言模型(LLM)在各个领域的应用越来越广泛。然而,针对特定领域的优化仍然是一个重要的研究方向。Baichuan-M1-14B 是由百川智能开发的一款专为医疗场景优化的开源大语言模型。它不仅在通用语言任务上表现出色,还在医疗领域展现了卓越的性能。
一、模型概述
Baichuan-M1-14B 是业界首款从零开始专为医疗场景优化的开源大语言模型。它旨在解决传统通用语言模型在医疗领域应用时的不足,例如对专业术语的理解、复杂医疗推理能力以及长序列任务的处理。该模型在医疗领域的表现达到了同尺寸通用模型的 5 倍甚至更高的效果,同时在通用任务上也保持了卓越的性能。
-
大规模高质量数据训练:基于 20 万亿 token 的高质量医疗与通用数据训练。
-
细粒度医疗专业建模:针对 20+ 医疗科室进行细粒度建模。
-
创新模型结构:引入短卷积注意力机制、滑动窗口注意力机制等优化,显著提升上下文理解和长序列任务表现。
-
提供多种模型版本:包括 Base 模型和 Instruct 模型,满足不同场景需求。
二、技术架构
(一)短卷积注意力机制
传统 Transformer 模型依赖 induction heads 来捕捉序列中的重复模式和上下文依赖。Baichuan-M1-14B 引入了短卷积注意力机制,通过在计算 Key 和 Value 时引入轻量化的短卷积操作,显著降低了对 induction heads 的依赖。这种机制在语言建模任务中表现出色,尤其是在对上下文信息依赖性强的任务中。
(二)滑动窗口注意力机制
在部分层中采用滑动窗口注意力机制,减少 KV Cache 内存占用,同时在计算效率和性能之间取得平衡,特别适用于长序列任务。
(三)优化位置编码震荡
通过增大部分注意力头的维度,降低 RoPE 曲线震荡,使模型在长序列任务中表现更稳定,同时保持模型的多样化特征捕捉能力。
(四)大峰值学习率策略
采用 WSD 学习率调度策略,使用高峰值学习率促进模型泛化能力。这一策略显著提升了模型在 benchmark 上的任务表现。
(五)自适应梯度更新
引入动态梯度剪裁机制,当梯度过大时,当前机制能动态选择是否跳过更新,减少因特殊样本或陡峭损失空间导致的不稳定。
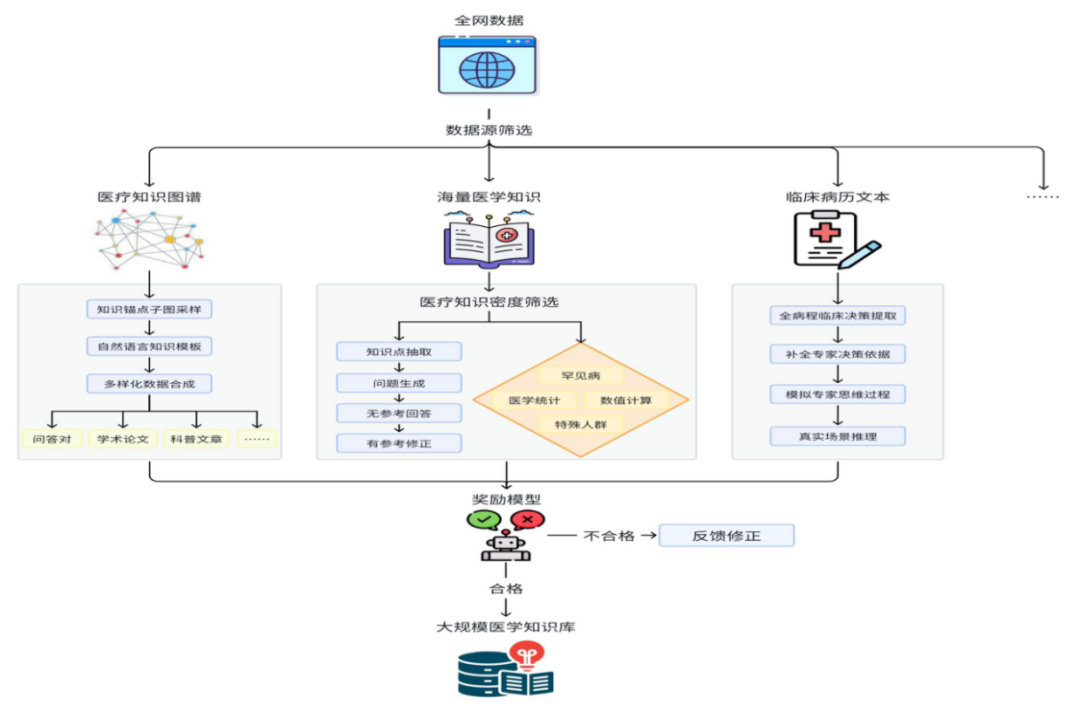
三、数据收集与处理
(一)医疗数据收集
为了确保模型在医疗领域的专业性,Baichuan-M1-14B 的数据收集工作非常细致。数据来源包括:
-
千万级专业医疗数据:中/英文专业论文、医疗病例、医疗教材、知识库等。
-
亿级医疗问答与临床数据:涵盖复杂医疗推理与实际临床案例。
-
全面的数据分类与评估:按医疗科室、内容和价值进行分类,确保数据分布均衡,筛选出真正具有医疗价值的数据。
(二)数据合成与优化
数据合成是提升模型性能的关键环节。Baichuan-M1-14B 通过以下方法优化数据:
-
合成数据设计:利用海量医学知识文本和结构化知识图谱生成高质量医疗推理数据。
-
自我反思机制与奖励模型:不断提升合成数据质量,最终生成近万亿 token 的医疗数据,覆盖长尾知识与复杂场景。
(三)通用数据收集
除了医疗数据,Baichuan-M1-14B 还结合了大规模的通用数据集:
-
20T多语言通用数据集:包括 14T 英文数据、4T 中文数据、2T 涵盖 30 种主流语言的数据。
-
去重与上采样策略:针对高质量数据进行适度上采样,显著提升模型性能。
-
27类全球知识分类:基于小模型实验优化数据配比,确保通用能力与领域能力的平衡。
四、训练方法
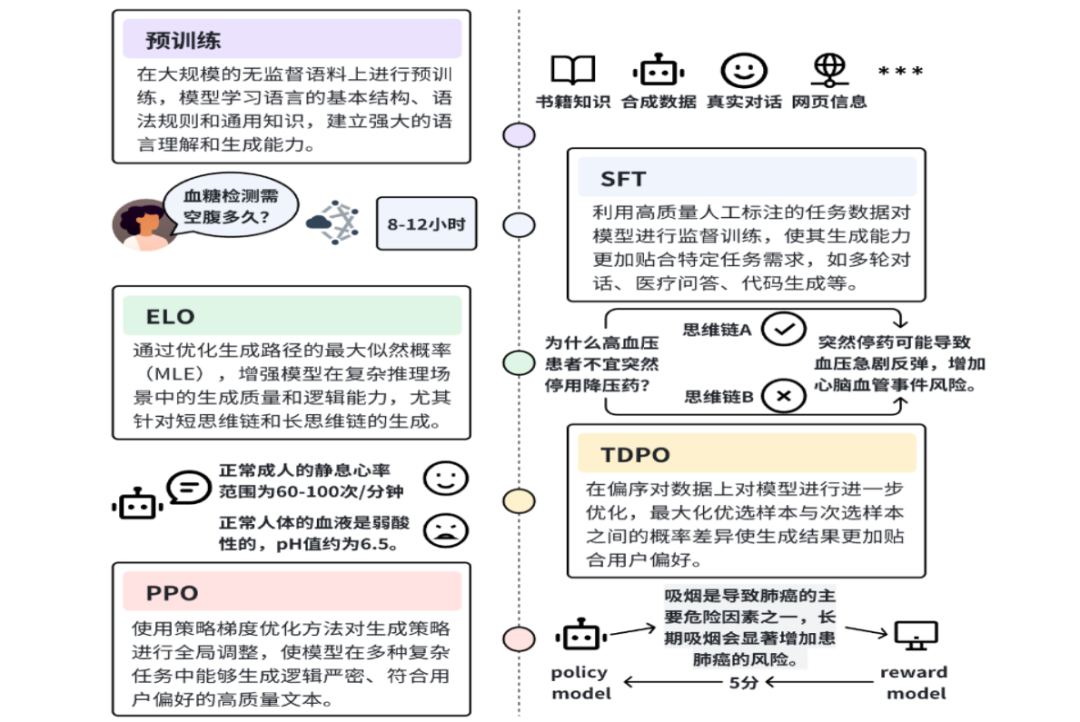
(一)多阶段课程学习
Baichuan-M1-14B 的训练分为三个阶段,逐步优化模型的通用能力与医疗领域能力:
1.通识能力提升阶段:以通用语言建模为目标,提升基础语言能力和常识。
2.医疗基础知识提升阶段:引入高质量医疗数据,重点提升推理、数学及医学知识能力。
3.医疗进阶知识提升阶段:进一步优化数据质量,聚焦复杂医疗推理、病症判断和长尾知识。
(二)对齐优化
通过强化学习和偏序对数据的优化,提升模型生成质量、逻辑推理能力和用户偏好贴合度:
-
偏序对数据:覆盖多轮对话、指令跟随、数学与代码、推理任务等场景,数据来源包括人类标注和多模型生成。
-
优化流程:
-
ELO:基于最大似然优化多样化高质量的思维链生成。
-
TDPO:使用偏序对数据优化生成模型,使其更贴合用户偏好。
-
PPO:通过策略优化进一步增强生成逻辑与任务表现。
五、性能表现
Baichuan-M1-14B 在多个主流评测集上取得了优异的指标,展现了卓越的医疗场景能力,同时具备强大的通用表现。以下是部分评测结果对比:

六、快速使用
(一)使用 Transformers推理实践
Baichuan-M1-14B 支持通过 Hugging Face Transformers 快速加载和使用。以下是使用 Baichuan-M1-14B-Instruct 模型的代码示例:
from transformers import AutoModelForCausalLM, AutoTokenizerimport torch# 1. 加载预训练模型和分词器# 指定 Baichuan-M1-14B-Instruct 模型的名称model_name = "baichuan-inc/Baichuan-M1-14B-Instruct"# 使用 Hugging Face 的 AutoTokenizer 加载模型的分词器# 参数 trust_remote_code=True 允许加载远程代码,确保模型的自定义实现能够正确加载tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)# 使用 Hugging Face 的 AutoModelForCausalLM 加载预训练模型# 参数 torch_dtype=torch.bfloat16 指定模型的权重数据类型为 bfloat16,以减少内存占用并加速推理# .cuda() 将模型移动到 GPU 上进行加速计算(如果可用)model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()# 2. 输入提示文本# 定义用户想要询问的问题prompt = "May I ask you some questions about medical knowledge?"# 3. 对输入文本进行编码# 构造对话消息,包括系统角色和用户角色的内容messages = [{"role": "system", "content": "You are a helpful assistant."}, # 系统角色的提示,定义模型的行为{"role": "user", "content": prompt} # 用户的问题]# 使用分词器的 apply_chat_template 方法将对话消息转换为模型可接受的格式# 参数 tokenize=False 表示不立即分词,而是先将对话转换为文本格式# 参数 add_generation_prompt=True 表示添加生成提示,以引导模型生成回答text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)# 使用分词器对转换后的文本进行分词和编码# 参数 return_tensors="pt" 表示返回 PyTorch 张量格式的编码结果# 将编码后的输入移动到模型所在的设备(GPU)model_inputs = tokenizer([text], return_tensors="pt").to(model.device)# 4. 生成文本# 调用模型的 generate 方法生成回答# 参数 max_new_tokens=512 表示生成的最大新 token 数量generated_ids = model.generate(**model_inputs, max_new_tokens=512)# 从生成的 token 中提取新生成的部分# 通过比较生成的 token 和输入的 token 的长度,去除输入部分,只保留生成的部分generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]# 5. 解码生成的文本# 使用分词器的 batch_decode 方法将生成的 token 解码为文本# 参数 skip_special_tokens=True 表示跳过特殊 token(如 [CLS]、[SEP] 等),只保留实际生成的文本内容response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]# 6. 输出结果# 打印生成的文本回答print("Generated text:")print(response)
(二)使用 vLLM推理实践
vLLM 是一个高性能的推理框架,支持 Baichuan-M1-14B 的推理。以下是使用 vLLM 的步骤:
1. 安装 vLLM
docker pull vllm/vllm-openai:v0.6.6.post1# docker内安装vllmgit clone https://github.com/baichuan-inc/vllm.gitcd vllmexport VLLM_PRECOMPILED_WHEEL_LOCATION=https://files.pythonhosted.org/packages/b0/14/9790c07959456a92e058867b61dc41dde27e1c51e91501b18207aef438c5/vllm-0.6.6.post1-cp38-abi3-manylinux1_x86_64.whl# 国内用户可选用以下配置# export VLLM_PRECOMPILED_WHEEL_LOCATION=https://pypi.tuna.tsinghua.edu.cn/packages/b0/14/9790c07959456a92e058867b61dc41dde27e1c51e91501b18207aef438c5/vllm-0.6.6.post1-cp38-abi3-manylinux1_x86_64.whlpip install --editable .
2. 启动服务
# bf16推理vllm serve baichuan-inc/Baichuan-M1-14B-Instruct --trust-remote-code# bitsandbytes量化推理vllm serve baichuan-inc/Baichuan-M1-14B-Instruct --trust-remote-code --load-format=bitsandbytes --quantization=bitsandbytes
3. 发送请求
from openai import OpenAIopenai_api_key = "EMPTY"openai_api_base = "http://localhost:8000/v1"client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,)prompt = "May I ask you some questions about medical knowledge?"chat_response = client.chat.completions.create(model="baichuan-inc/Baichuan-M1-14B-Instruct",messages=[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": prompt},])print("Chat response:", chat_response)
总结
Baichuan-M1-14B 是一个专为医疗场景优化的开源大语言模型,它在医疗领域展现了卓越的性能,同时在通用任务上也表现出色。通过大规模高质量数据训练、创新的模型结构优化以及多阶段课程学习和对齐优化,Baichuan-M1-14B 为医疗领域的 AI 应用提供了强大的支持。我们可以通过 Hugging Face Transformers、vLLM 等工具快速上手使用该模型,并在实际应用中发挥其强大的能力。
(文:小兵的AI视界)