
在这篇文章中,我将介绍如何使用 LangGraph、Agentic RAR、Nano-GraphRAG 以及 Claude 3.7 Sonnet 来创建一个基于智能推理(Agentic RAR)的聊天机器人,看完这篇文章之后你就学会了如何为你的业务打造一个强大的智能推理聊天机器人。
我首先向你展示一下聊天机器人的效果:“生成代码,检查以下数字是否为回文数:123、121、12321、12345、123454321。”
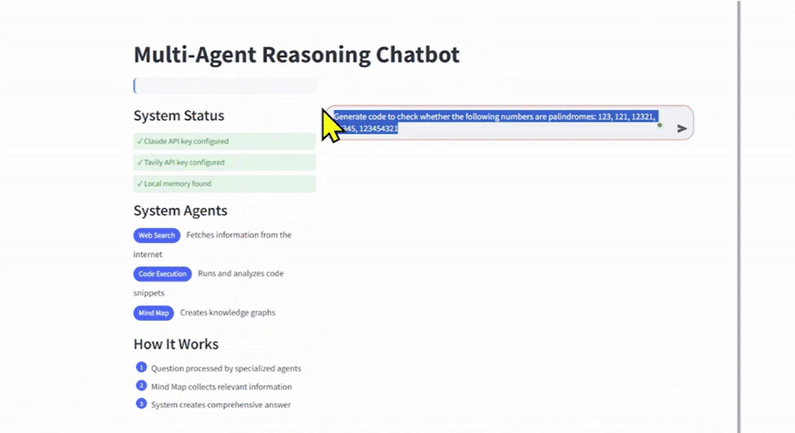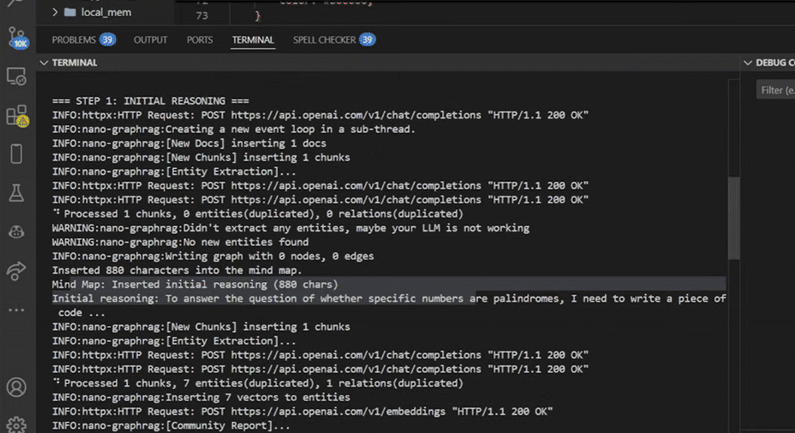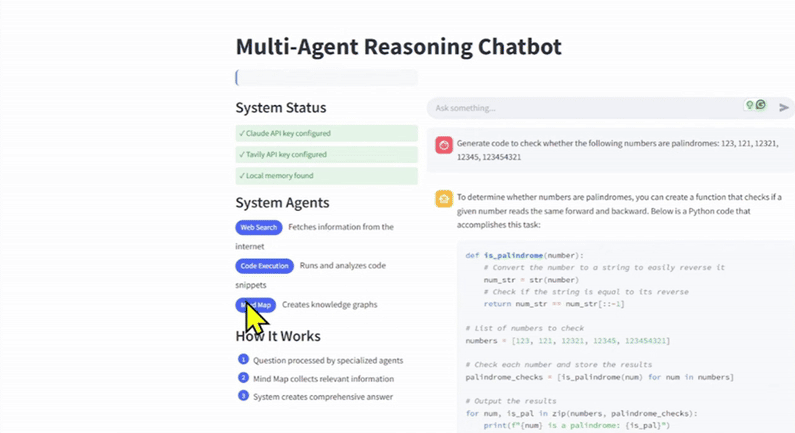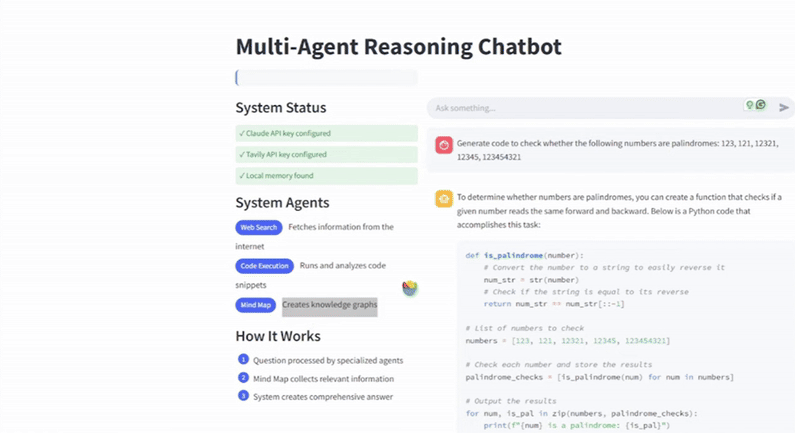
当用户提出问题时,初始推理 Agent 会对其进行分析,识别需要哪些专业 Agent,并检测特定的标签,这些标签表明 Agent 查询类型,例如网页搜索、代码执行或思维导图。
每个 Agent 都有一个负责收集数据的伙伴。例如,当代码 Agent 执行任务时,另一个 Agent 会记录过程并将其存储在一个文件中。
-
route_to_agent 通过检查状态的推理和所需 Agent 来指导工作流程,提取嵌入式查询,决定激活哪个 Agent,并存储路由决策。
-
当需要网页搜索时,web_search_agent 会查询 Tavily API,处理结果,更新推理,并在移除自身之前存储查询和结果。
-
code_execution_agent 生成并执行代码,提取带有格式化标签的输出,更新推理,存储结果,并在执行后移除自身。
-
思维导图 Agent 扮演两个角色:在整个过程中收集知识,并在查询时组织结构化信息。它汇编所有收集的信息,将其格式化为知识文档,并存储在 GraphRAG 知识图谱中,以便检索和结构化分析。
-
知识管理依赖于通过 collected_knowledge 字典进行的过程内收集和通过基于 GraphRAG 的 MindMap 类进行持久存储,它使用基于目录的存储、JSON 文本块、用于语义搜索的向量嵌入以及通过 graph_retrieval 的查询功能,从而使知识随着时间的推移而增长。
-
最后,synthesize_answer 方法整合所有收集的信息,生成全面的总结,将其存储在思维导图中,查询相关信息,并结合推理链和思维导图信息生成最终答案。
我在开发中遇到的问题
在开发聊天机器人时,我踩了一些坑。
-
一个主要问题是思维导图初始化,Agent 在没有任何数据收集之前就尝试访问数据,导致“matrix”错误。为了解决这个问题,我改变了初始化方法,在启动时仅创建基本的目录结构,并让 Agent 在存储信息之前收集真实数据。
-
另一个坑是 Agent 之间的状态管理,因为信息在转换之间会丢失。我通过添加一个持久的知识收集机制解决了这个问题,使用 collected_knowledge 字典跟踪输出,确保知识逐步积累。
-
最后,思维导图中的知识整合效果不佳,因此我修改了工作流,持续收集数据,在适当的时刻存储格式化的知识,并在合成前查询思维导图。
-
最大的突破是重新设计思维导图 Agent,使其成为一个被动的收集者,而不是一个显式调用的 Agent,从而让它在推理过程中自然构建全面的知识图谱。
通过这篇文章,你将了解 Agentic RAR 和 Nano-GraphRAG 是什么,为什么 Agentic RAR 如此独特,它是如何工作的,以及我们如何使用 Agentic RAR 创建一个强大的推理聊天机器人。
什么是 Agentic RAR?
首先,大型语言模型(LLM)中的推理能力可能还不是 AGI(通用人工智能)或 ASI(超人工智能),但它在处理数学、编码和复杂思维等任务方面已经取得了巨大的进步。
以 Claude 3.7 Sonnet 的最新版本为例,这是市场上首个混合推理模型。它可以根据需求快速响应或进行更深入的思考,用户还可以调整它的思考时间。它能够启动一种长时间思考模式,模拟人脑的思考过程。
LLM 在序列推理方面存在困难。例如,如果你要求一个 LLM 解决一个多步骤的数学问题,它可能会忘记前面的步骤,从而给出错误的答案。
如果遇到不明确的地方,它们会猜测而不是询问细节,这可能导致错误。有时,它们甚至对同一个问题给出不同的答案,这也很令人困惑,因为它们在处理专家级话题和长期对话时会遇到困难。
想象一下,你有一个非常聪明的朋友,他不仅知识渊博,还能上网搜索更多信息,编写并运行简单的程序,甚至还能画出思维导图来帮助连接各种想法。
这就是 Agentic RAR 的用武之地。它在 RAG 模式基础上,引入了一种动态的、以推理为核心的问题处理方式。
Agentic Reasoning 就像赋予 AI 模型使用额外工具的能力——就像我们使用计算器解决复杂数学问题、查字典找词义或用搜索引擎在线查找答案一样。
想象你问 AI:“中国现在的人口是多少?”它不仅依赖过去学到的知识,还能检查最新数据并给你一个准确的答案。这让 AI 变得更聪明、更有用,因为它不会只是猜测——它会通过使用正确的工具找到最佳答案,就像我们在现实生活中一样!
为什么 Agentic RAR 独特?
Agentic RAR 的独特之处在于,它通过统一的 API 标准化工具调用,使得集成新工具(比如化学方程求解器)变得轻而易举。
它还能动态分配认知负荷,通过将简单任务分配给轻量 Agent,将复杂计算交给专用代码代理,确保高效使用资源——在医学诊断测试中,响应速度提高了 40%,计算能力使用量减少了 72%。
它的多模态记忆融合使思维导图代理能够存储并链接文本、公式和图表,创建一个三维知识系统——使其能够处理复杂问题。
它是如何工作的?
Agentic Reasoning 采用一种结构化的方法,结合各种外部 Agent 来增强 LLM 的推理能力。
-
它使用网页搜索 Agent 从互联网获取实时信息,帮助补充 LLM 预训练数据集之外的知识。
-
编码 Agent 用于执行代码或完成计算任务;这个 Agent 支持定量推理并解决需要编程技能的问题。
-
思维导图 Agent 用于构建知识图谱,组织和可视化复杂的逻辑关系,帮助结构化推理过程。
-
该模型能在推理过程中识别何时需要额外信息或计算能力。它可以生成特定的查询,无缝触发外部 Agent 的使用。
在综合所有信息和结构化信息后,模型会构建一个连贯的推理链并生成最终答案。
认识 Nano-GraphRAG
GraphRAG 由微软提出,非常有效,但官方实现和使用非常复杂,难以修改和定制。
Nano-GraphRAG 是一个轻量且灵活的 GraphRAG 实现,旨在简化 GraphRAG 的使用和定制。它保留了 GraphRAG 的核心功能,同时提供更简单的代码结构、更友好的用户体验和更高的可定制性。
Nano-GraphRAG 仅有大约 1100 行代码(不包括测试和提示),设计为轻量、异步且完全类型化,非常适合希望将 GraphRAG 集成到项目中而又不增加复杂性的开发者。
在正式开始撸代码之前,我想向大家推荐一本由著名 AI 大佬:Sebastian Raschka 出版的《大模型技术30讲》,欢迎大家通过下方链接购买,支持一下小编买桶泡面加班写文章
不过也为了真诚地感谢各位铁子,从4月14号到4月16号,我将向评论区的铁子们随机赠送。铁子们!行动起来!
开始编码
我开发了 MindMap 类作为一个智能系统,用于高效存储和检索信息。在使用 __init__ 函数初始化时,我创建了一个工作目录(local_mem),并使用 GraphRAG 组织数据,立即保存任何提供的初始内容。
我使用 insert 函数添加信息并存储,确认保存了多少字符。当需要提问时,我调用 __call__ 函数,它使用 graph_retrieval 函数搜索存储的信息,在“本地”模式下查看相关数据并显示结果。
我还开发了 process_community_report 函数,从特殊的 JSON 文件中读取并合并结构化的社区报告,从而更容易同时查看所有相关信息。如果我想专门在社区报告中搜索,我使用 graph_query 函数,它根据这些报告收集并格式化我的问题,返回最相关的信息。
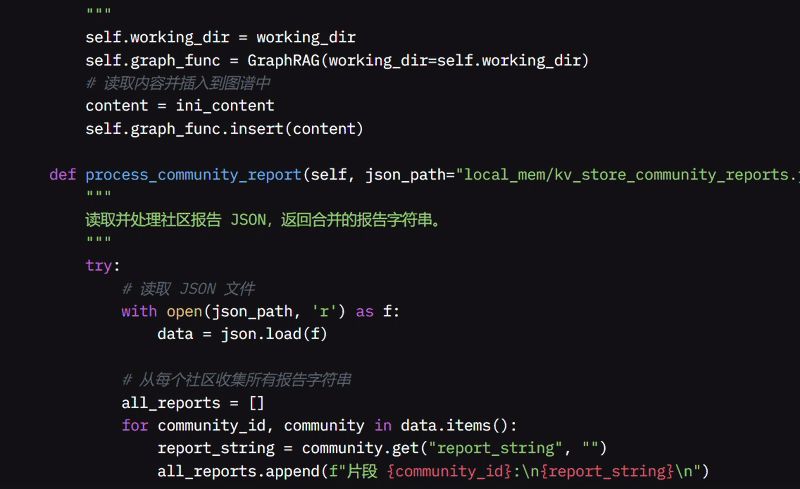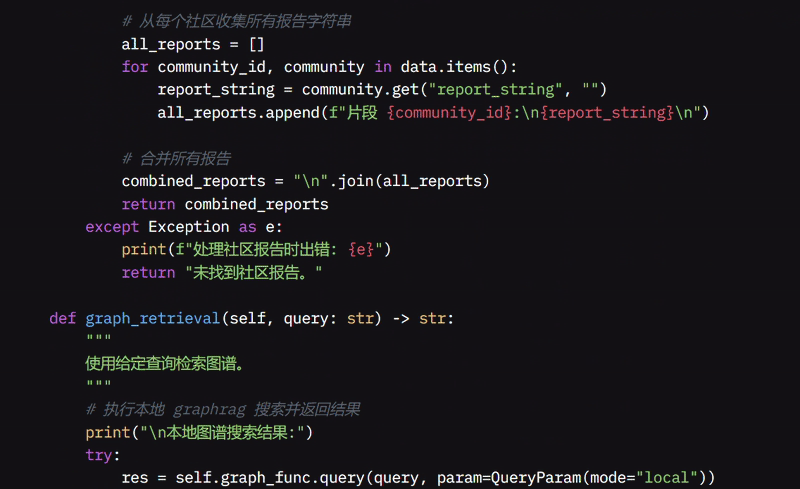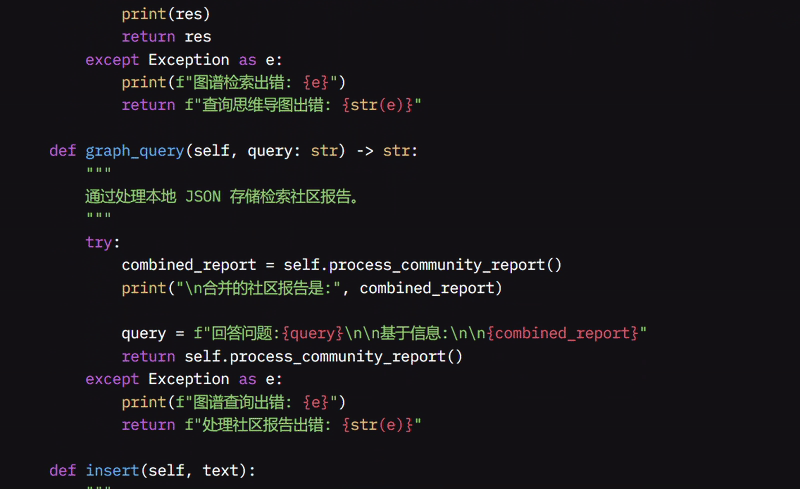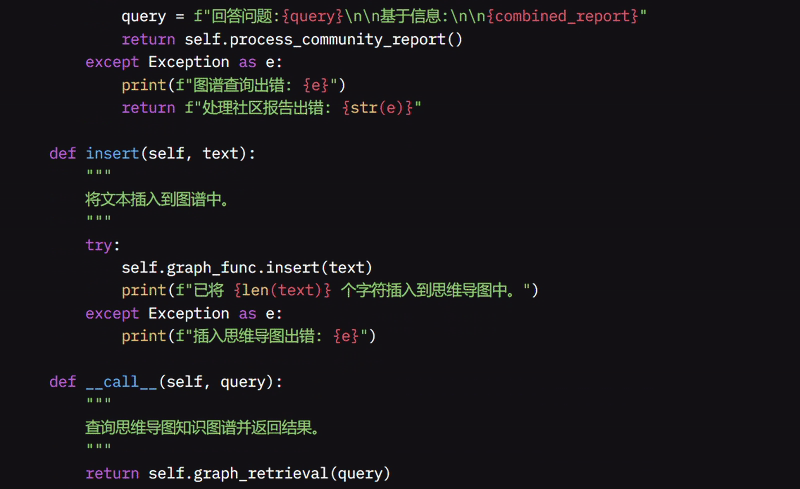
我创建了 MultiAgentReasoner 类,使其像一个智能管理者,协调多个 Agent 来帮助回答你的问题,每个 Agent 有特定的角色,例如搜索网页、编写代码或组织信息。
当我创建一个新的 MultiAgentReasoner 时,它会连接到名为 Tavily 的工具以协助搜索,创建一个 MindMap 来存储和组织信息,设置搜索次数限制(默认为 3 次),创建一个计划(称为工作流程),并准备一个存储收集知识的地方。
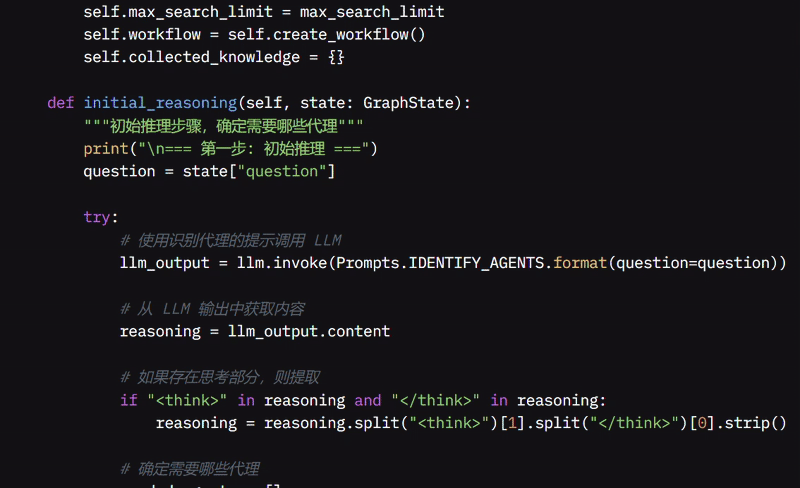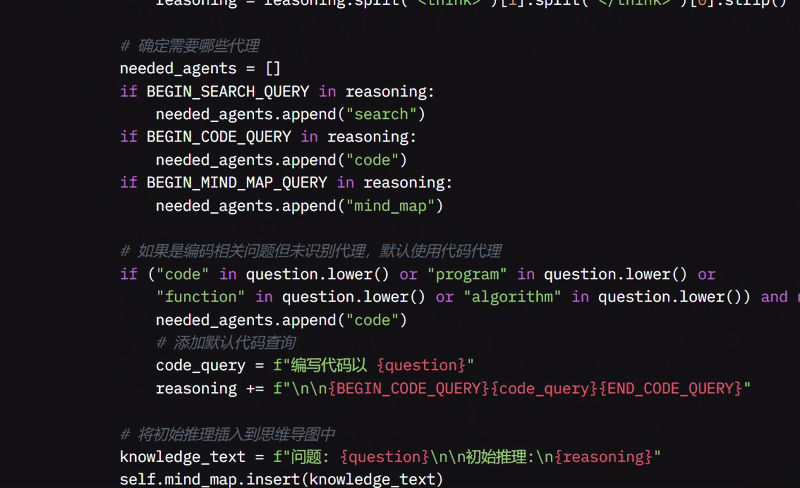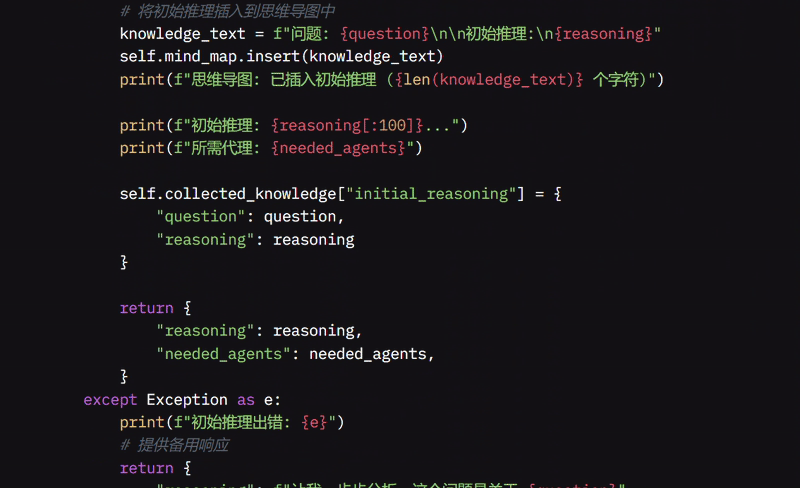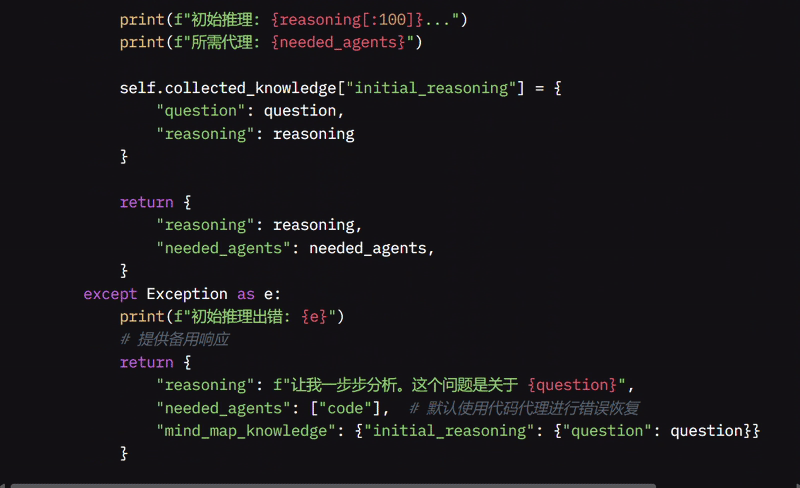
initial_reasoning 函数是系统开始分析问题的地方。它从 GraphState 中获取问题,并使用 LLM 进行分解。如果 LLM 识别出“思考”部分,它会提取该部分。然后,系统根据问题确定需要哪些辅助 Agent,如果需要搜索则添加搜索 Agent,对于编码相关问题添加代码 Agent,或者如果涉及组织则添加思维导图 Agent。
如果没有为编码相关问题添加 Agent,它会自动添加代码 Agent 并生成默认查询,例如“编写代码以 [你的问题]”。在将问题及其初始推理存储到 MindMap 中以供将来参考后,它会预览其推理和将使用的 Agent。
如果出现问题,系统会打印错误消息,提供类似“让我一步步分析”的备用响应,将代码 Agent 设置为默认辅助,并通过返回问题的基本信息继续进行。
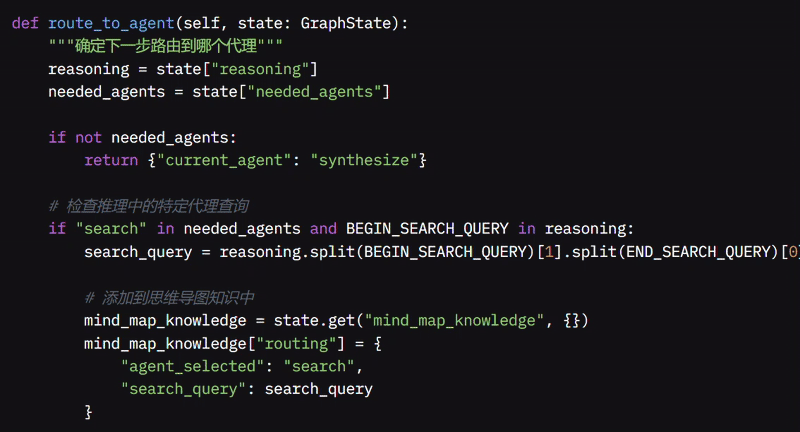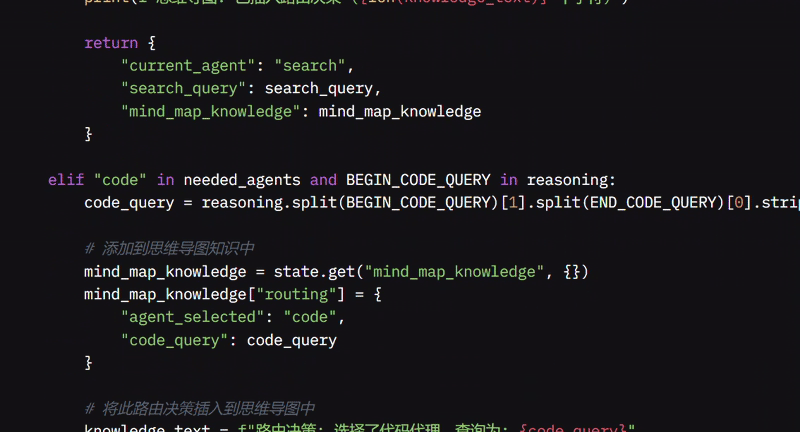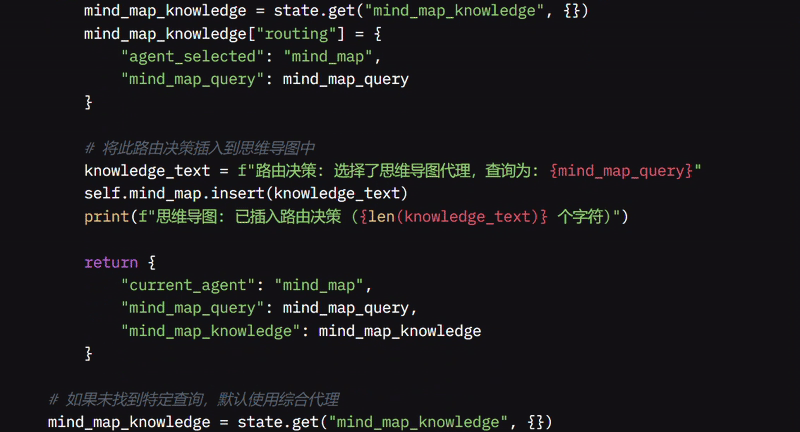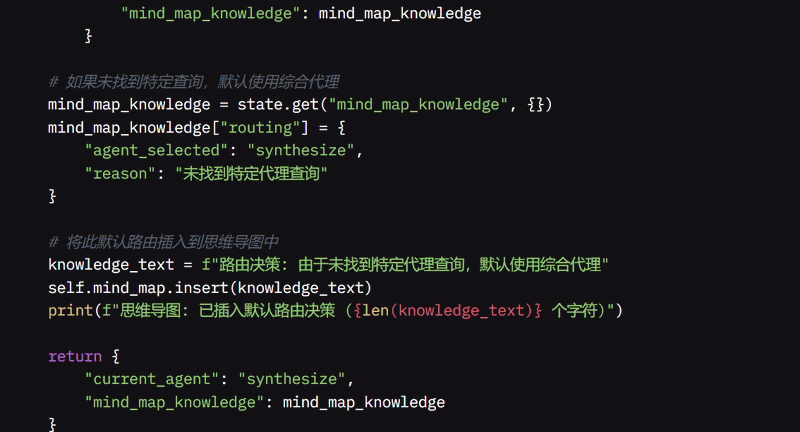
route_to_agent 函数根据推理决定哪个 Agent 应处理问题。当系统收到问题时,我检查其存储在状态中的推理,确定它是否需要搜索、编码或思维导图。
如果不需要特定 Agent,我默认使用综合 Agent。如果需要搜索 Agent,我在推理中寻找搜索查询,提取它,并将问题路由到搜索 Agent,同时将决策保存在 MindMap 中。如果需要代码 Agent,我检查与代码相关的查询,提取相关信息,并将其发送到代码代理,同样将决策保存在 MindMap 中。
如果推理涉及思维导图查询,我提取该查询并将问题路由到思维导图 Agent。如果未找到这些特定查询,我将问题路由到综合 Agent,它可以合并信息或提供简单响应。
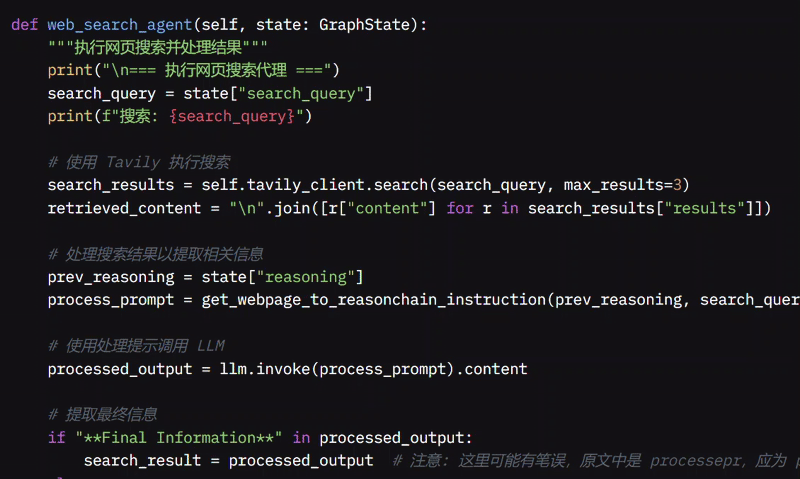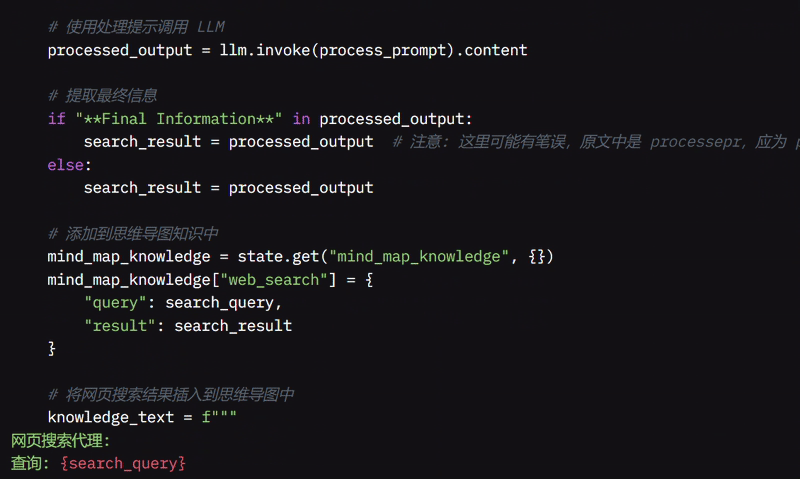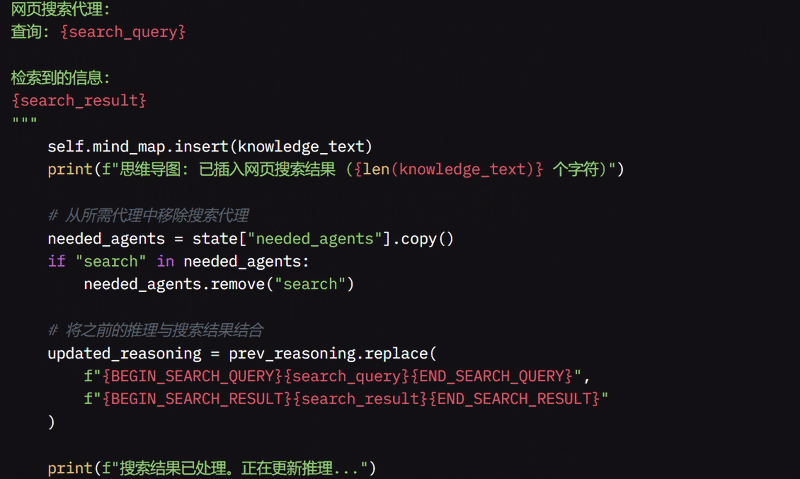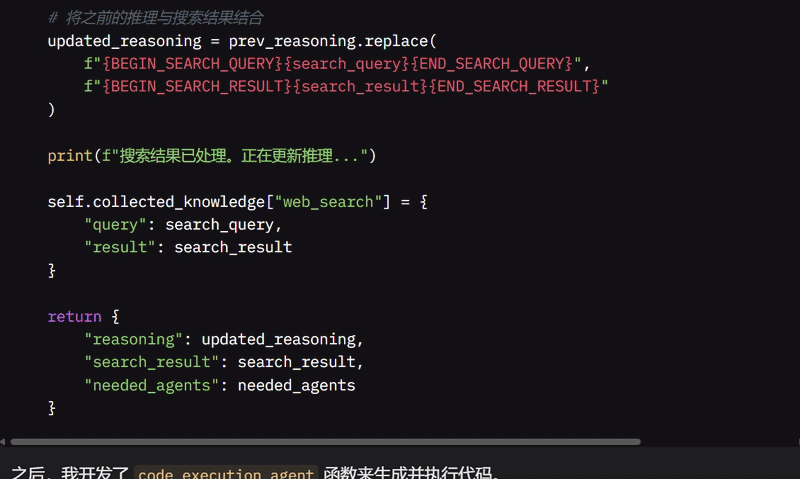
然后,我设计了 web_search_agent 函数,当问题需要时搜索并收集相关信息。我会打印一条消息并从系统状态中检索搜索查询。使用名为 Tavily 的工具,它会在网络上搜索查询,收集最多三个搜索结果,并合并内容。
系统随后为 LLM 创建指令以处理结果,帮助专注于最相关的信息。它检查是否有标有“最终信息”的部分,如果有则使用该部分,否则使用整个 LLM 输出。
查询和结果会被存储在 MindMap 中以供后续参考。它更新待办事项列表,移除“搜索”任务,并通过将查询替换为搜索结果来更新推理。
最后,该函数将搜索结果存储在收集的知识中,并返回更新的推理和结果,确保系统拥有回答问题所需的最新信息。
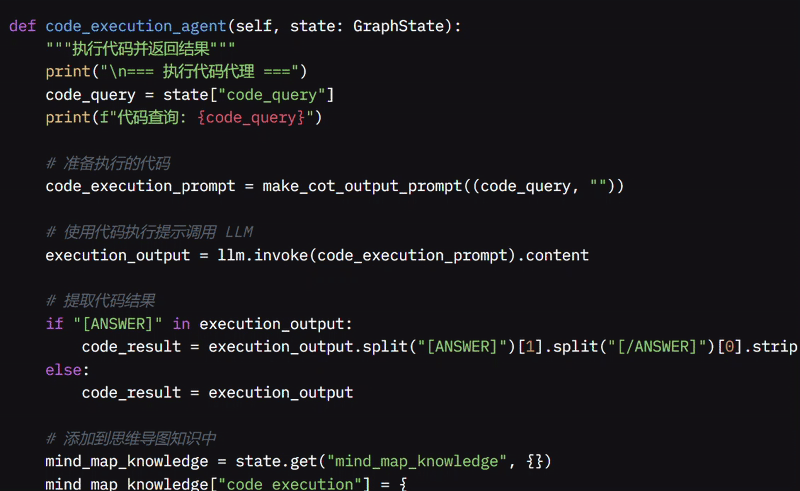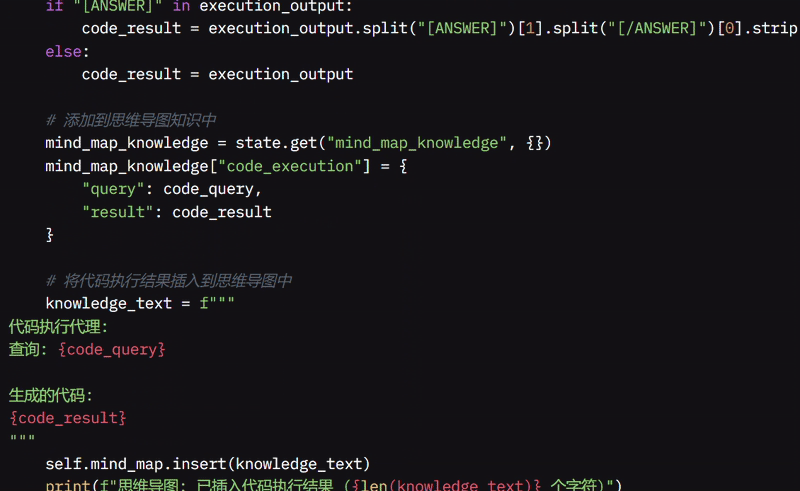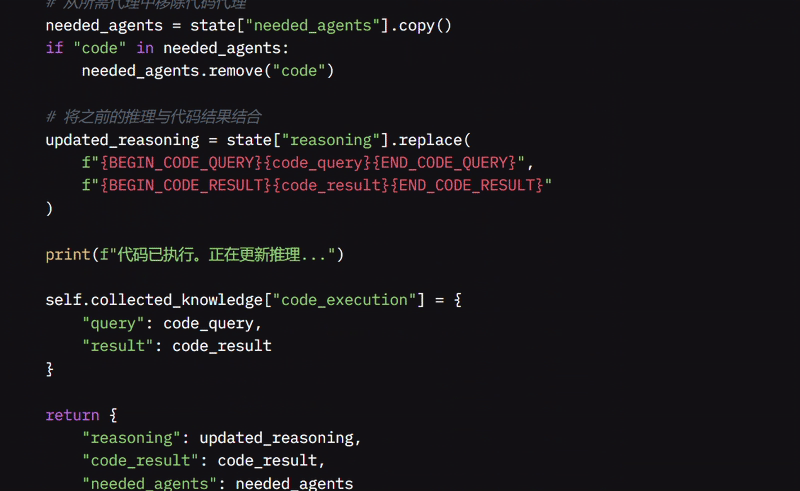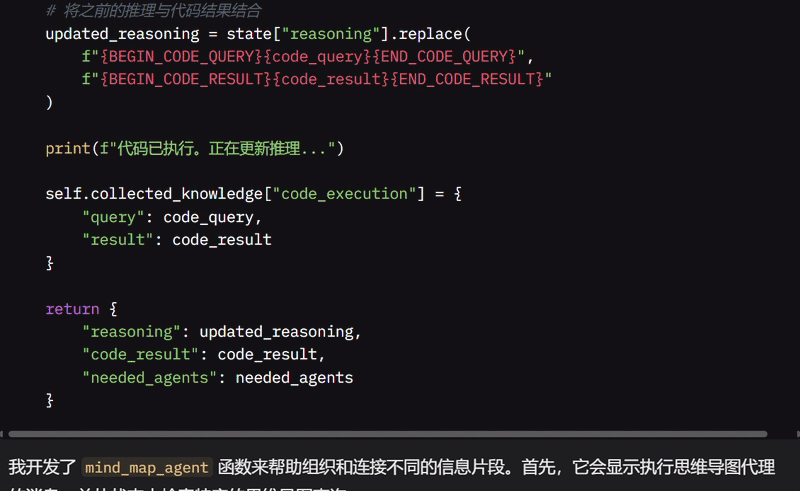
之后,我开发了 code_execution_agent 函数来生成并执行代码。
它创建一个“思维链”(chain of thought, cot)来指导 LLM 生成代码,然后将指令发送给模型。如果输出包含像 [ANSWER] 和 [/ANSWER] 这样的特殊标签,它会提取其中的代码;否则,它使用整个响应。
该函数将原始查询和生成的代码保存在 MindMap 中以供将来参考,更新待办事项列表,移除“代码”任务,并通过将代码查询替换为结果来更新整体理解。
它还将查询和结果存储在收集的知识中以便将来轻松使用,并返回更新的推理、代码结果和所需 Agent 的新列表,完成流程。
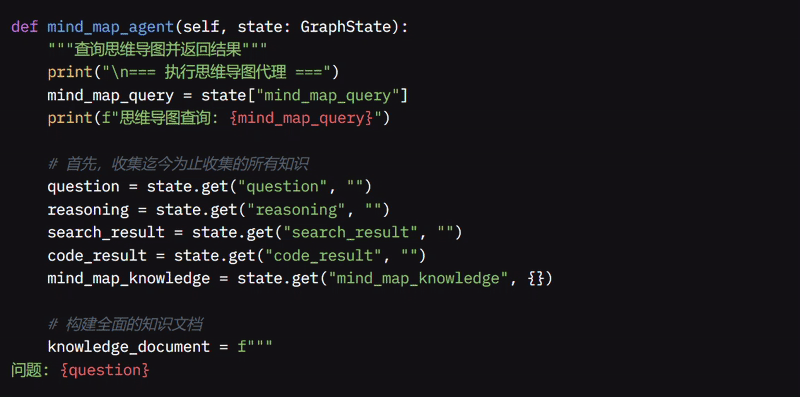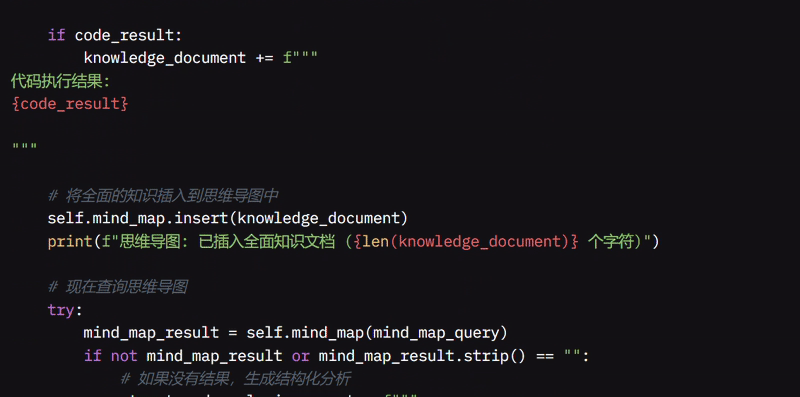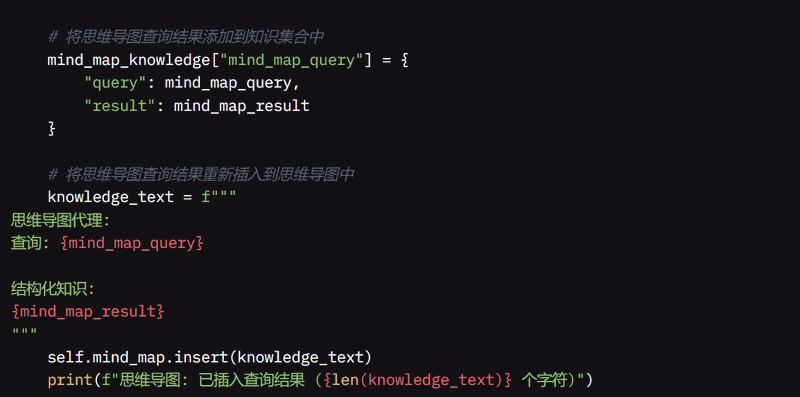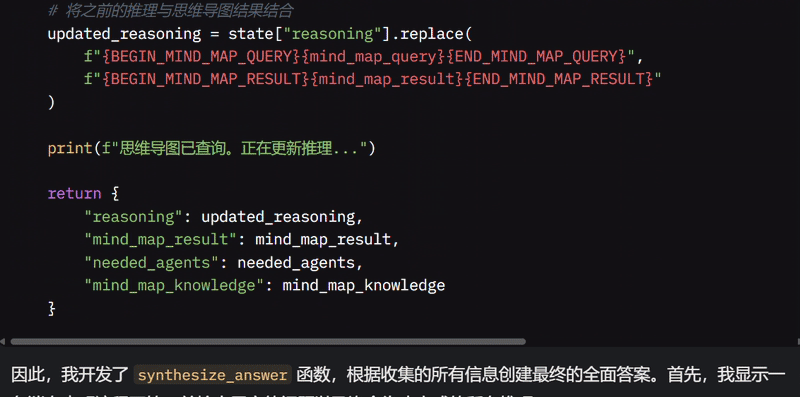
我开发了 mind_map_agent 函数来帮助组织和连接不同的信息片段。首先,它会显示执行思维导图 Agent 的消息,并从状态中检索特定的思维导图查询。
它会收集所有信息,包括原始问题、推理、搜索结果、代码执行结果以及 MindMap 中已有的任何知识。然后,它使用这些信息创建一个全面的知识文档并存储在思维导图中。
在用用户的问题查询思维导图时,它尝试找到直接答案,但如果没有结果,我使用 LLM 创建一个结构化分析,突出关键概念和信息。
如果查询思维导图时出错,我提供一条备用消息以继续流程。然后,我将思维导图查询及其结果保存在思维导图中以供将来使用,并通过标记思维导图任务完成来更新待办事项列表。
最后,我通过合并思维导图结果更新整体推理,并返回更新的推理、思维导图结果和知识。
因此,我开发了 synthesize_answer 函数,根据收集的所有信息创建最终的全面答案。首先,我显示一条消息表明流程开始,并检索用户的问题以及迄今为止完成的所有推理。
然后,我将所有这些信息合并成一个文档,包括原始问题和推理链。如果有任何搜索结果或代码执行结果,我会将其添加到文档中,以提供收集知识的完整视图。
一旦知识收集完成,我将其存储在思维导图中以供将来使用,并查询与问题相关的任何信息。然后,我生成一个综合提示,包括所有收集的知识(包括思维导图的信息),并将其传递给 LLM 以创建清晰完整的答案。
生成最终答案后,我将其存储在思维导图中,并打印一条消息表明答案已准备好。最后,我返回最终答案以显示给用户。

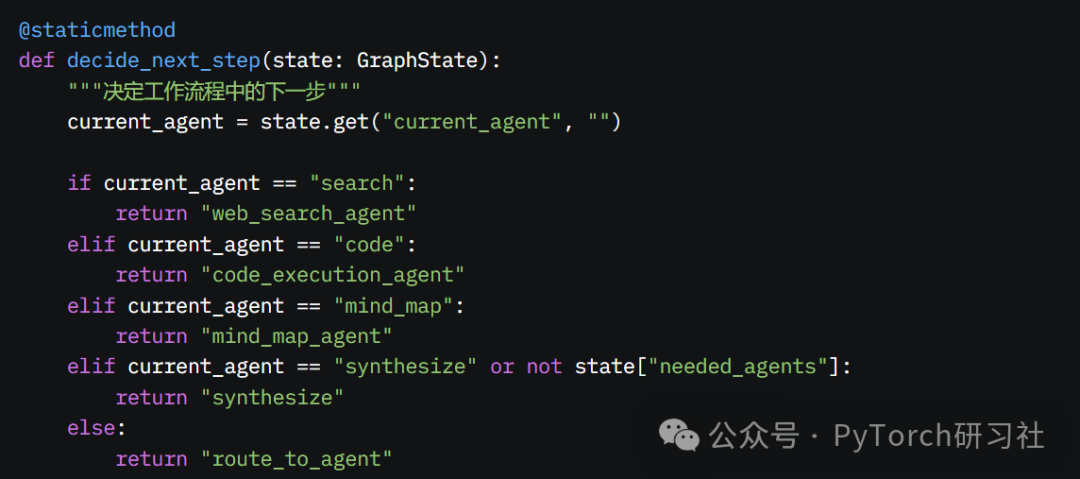
我创建了 decide_next_step 函数作为交通指挥,根据当前 Agent 决定工作流程中的下一步。它检查当前活跃的 Agent,并根据活跃 Agent 将流程引导到适当的下一步。如果没有 Agent 活跃,它返回一个空字符串。
我还开发了 create_workflow 函数来设计整个工作流程图。我添加了表示不同功能的所有关键节点,例如推理、网页搜索、代码执行、思维导图和综合。我将起点设置为“initial_reasoning”,并定义了连接这些节点的路径(边)。
我创建了依赖于 decide_next_step 函数的条件边,该函数根据问题的具体需求决定下一个节点。最后,我标记流程的结束,编译图谱,并返回完成的工作流程。

结论
Agentic Reasoning 和 Nano-GraphRAG 不仅仅是工具框架,它们代表了 AI 系统的演变——从单一模型到智能代理生态系统,从静态知识到动态认知——标志着推理革命的开始。Nano-GraphRAG 对于对 GraphRAG 感兴趣的人来说是理想选择,它提供了简单性、易用性和可定制性,使其成为开发者的强大替代方案。
(文:PyTorch研习社)