统一多模态模型的目标是整合深度理解(通常产生文本输出)和丰富的生成(产生像素输出),将这两种不同的模态在单一架构中对齐面临着巨大挑战,如何有效地将自回归 MLLMs 的潜在世界知识转移到图像生成器中?
以往的统一模型旨在训练一个单一的自回归 transformer 骨干网络,以联合建模 p(文本,像素)。
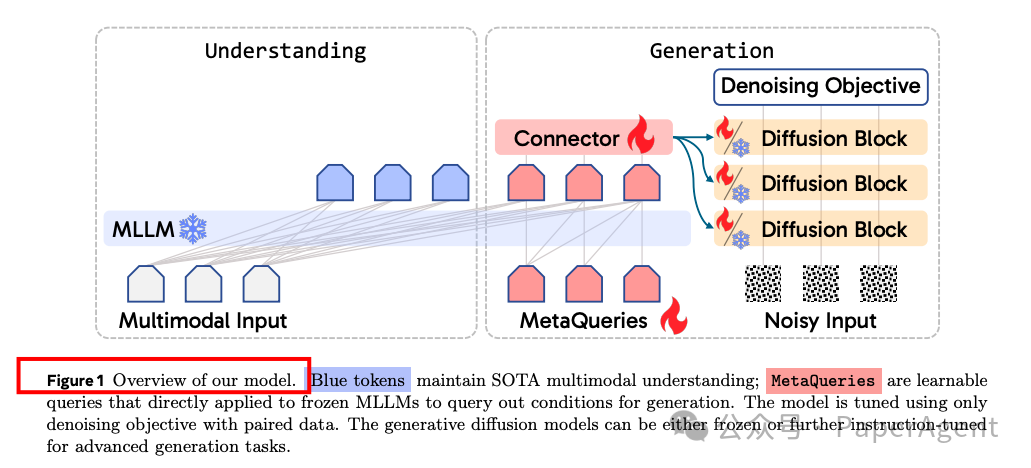
可能与 OpenAI 暗示的同期GPT-4o图像生成系统在高层次理念上有相似之处,Meta&NYU(谢赛宁大佬)选择采用一种“token → [transformer] → [diffusion] → pixels”的范式,MetaQueries的核心是“Render unto diffusion what is generative, and unto LLMs what is understanding”的理念,即专注于在预训练的、针对不同输出模态的专业模型之间有效转移能力。
具体来说,MetaQueries使用一组随机初始化的可学习查询(Q),直接输入到冻结的MLLM中,以提取用于多模态生成的条件(C)。这些条件通过一个可训练的连接器对齐到文本到图像扩散模型的输入空间。整个模型使用原始的生成目标在成对数据上进行训练。
探讨了两种设计选择——使用可学习查询和保持MLLM骨干冻结。实验结果表明:
-
可学习查询在图像生成质量上与使用MLLM的最后一层嵌入相当,甚至在使用更多tokens时可以超越它。
-
冻结MLLM可以在保持SOTA多模态理解性能的同时,实现与完全微调MLLM相当的图像生成性能。
图像重建结果,对比GPT-4o以及 SEED、Emu 和 Emu2 (后面三个结果来自论文)
图像编辑结果,这种能力可以通过轻量级微调从图像重建中轻松转移
指令调整的定性结果。 经过指令调整的 MetaQuery 实现了强大的主体驱动能力(第一行),甚至可以通过多模态输入进行推理以生成图像(第二行)。
MetaQuery 利用冻结的 MLLM 进行推理和知识增强的生成,克服了基础 Sana 模型中遇到的失败案例。
更多信息:《动手设计AI Agents:CrewAI版》、《高级RAG之36技》、新技术实战:中文Lazy-GraphRAG/Manus+MCP/GRPO+Agent、大模型日报/月报、最新技术热点追踪解读(GPT4-o/数字人/MCP/Gemini 2.5 Pro)
https:Transfer between Modalities with MetaQueriesProject Page: https:
(文:PaperAgent)