

如果你有关注AGI 相关的BenchMark
应该会经常看到这两个神秘基准测试的名字
ARC-AGI和GAIA
一个号称能隔离泛化能力,
测试AI的真正问题解决能力
不让AI靠预设知识蒙混过关

另一个则直击现实世界痛点
号称如果有AI能解决它,
就意味着AI研究的里程碑!
而两个BenchMark 究竟谁更强呢?
先说ARC-AGI——AI智商检测器!
自2019年就开始测量AI进步的ARC-AGI
是唯一能精准指出AI何时超越纯记忆的基准!
这玩意表面看像是个简单的小测验

摆着一堆不同颜色的方块,
要AI从中识别视觉模式,
然后生成正确的”答案”网格
听起来很简单?
那咱看看各家模型都什么表现:
GPT-4o才考了5%的分!
一众AI模型们全傻眼了~
这与测试模式识别或暴力计算的基准不同,
ARC-AGI挑战的是概念推理能力,
这可是人类智能的传统领地啊!
可就是这么个变态测试
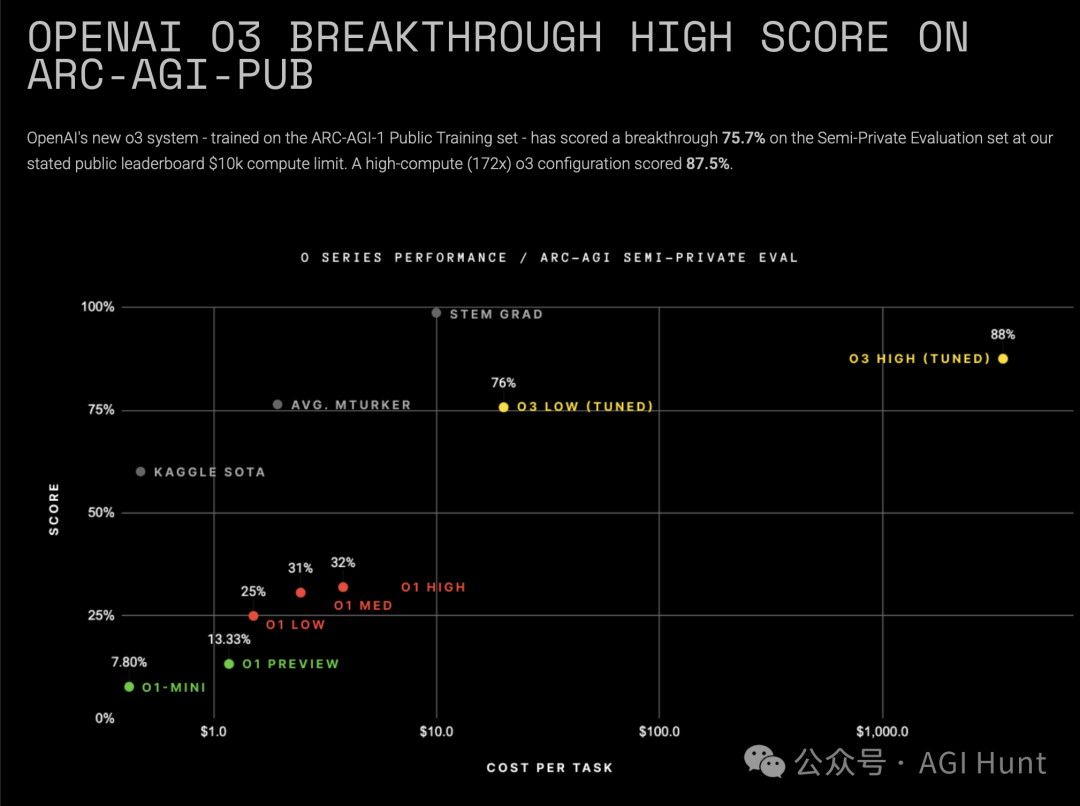
OpenAI的o3模型竟然在公共排行榜上拿了75.7%,
高计算模式下甚至打到了87.5%
嘿,这AI翅膀真硬了啊?!

不过就在上个月(2025年3月)
ARC Prize基金会又整出个ARC-AGI-2
这新版本对AI难度更高

(但对咱人类还是一样简单)
这不是存心为难AI吗?!
再说GAIA——AI搬砖小能手!
这个GAIA 也不简单,
它提出的问题对人类来说概念上简单,
但对大多数先进AI来说却是噩梦!
人类受访者能拿下92%,
而带插件的GPT-4才可怜巴巴地拿了15%
怎么又是拿人类智商欺负AI?!
不过与ARC-AGI 不同的是
GAIA考的是AI的现实世界能力:
推理、多模态处理、网络浏览,
总之就是各种工具使用能力
正经人谁还记ARC-AGI 这样的八股文啊?
整得跟考公务员似的
实际中还是能上手干活才是真本事!

而且这GAIA还分三个级别,难度拉满:
由450多个非平凡问题组成,
每个都需要不同级别的工具和自主性才能解决,
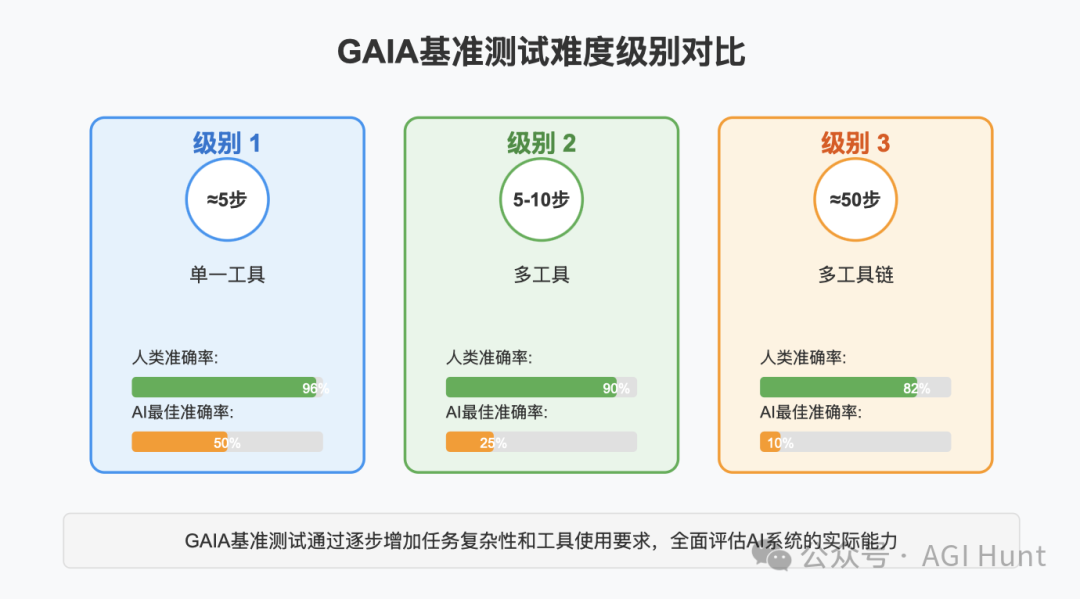
一级难度就够顶级LLM 喝一壶,
三级难度简直是模型能力的飞跃
第1级问题需要约5个步骤和一个工具,
第2级需要5到10个步骤和多个工具,
第3级可能需要多达50个离散步骤和任意数量工具
什么叫真实世界的复杂性?
这就是!
为避免LLM评估常见陷阱,
GAIA出的都是有挑战性的多步骤问题,
不可操纵且不易暴力破解
模型大挑战
来看ARC-AGI-2的战场:
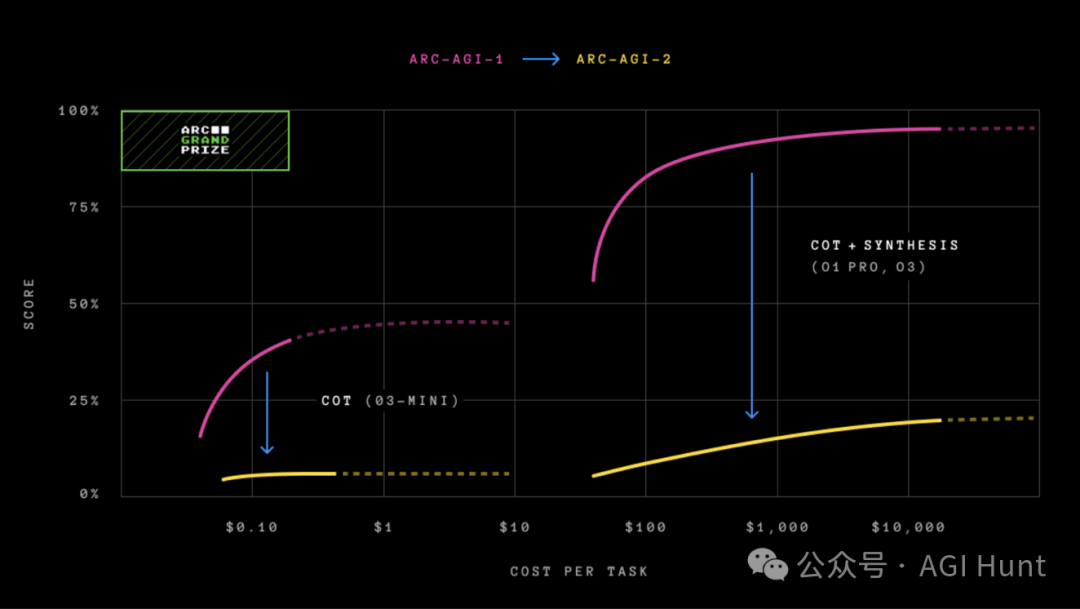
连OpenAI的o1-pro和DeepSeek的R1
这些“推理型”AI都只能拿1%-1.3%的成绩,
强大的非推理模型如GPT-4.5、Claude 3.7 Sonnet
和Gemini 2.0 Flash也就1%左右
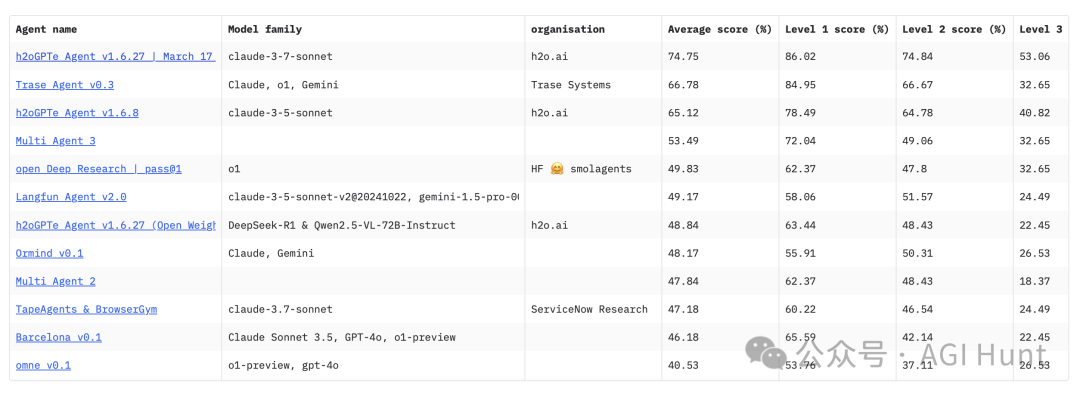
GAIA这边竞争更激烈:
h2oGPTe Agent这个猛人
以65%的显著分数位居榜首,
大幅超过了其他主要玩家
不过就这成绩,跟人类的92%比,还有不小差距啊!
双测试基准
这俩测试都精准打中了AI模型的七寸!
GAIA在AI社区备受尊敬,
因为它测的是AI现实世界实用性,
不是纯理论知识
ARC-AGI也是一针见血:
它隔离了泛化能力——
把有限信息应用到新的、未见过情况的能力,
让AI必须展示真正的问题解决能力
这俩基准测试其实是互相补充的角色:
ARC-AGI:考验AI的抽象推理和通用思维
GAIA:测试AI的工具使用和实际操作
这是给AI上的一堂全面素质课啊!
谁才是AGI 的超级照妖镜?
GAIA与其他测试不同,
它专注于需要综合能力的现实任务:
推理+多模态处理+工具使用
而ARC-AGI关注泛化能力——
在有限样例下找规律并应用到新问题
谁更厉害呢?
我的答案是:它们并非对手,而是搭档!
这就像你考驾照:
理论考试(ARC-AGI):测你懂不懂规则
路考(GAIA):看你会不会实际开车
只有两样都过关的AI,才能真正上路!
GAIA的思路打破了当前AI基准测试潮流,
不是追求对人类越来越难的任务,
而是认为AGI的到来,
取决于系统能否像普通人一样解决简单问题
AI能摆脱照妖镜魔咒吗?
随着模型不断进化,这些基准测试也在升级:
ARC-AGI-1被o3模型攻破后,
ARC-AGI-2马上就来接盘,
继续作为AI研究的指南针
而GAIA那边,成功率达到90%
被认为是多代理系统可以替代人类的门槛,
这是多代理系统的一种”图灵测试”

可AI发展的终极目标是什么呢?
把GAIA的问题解决了,
真的会是AI研究的里程碑
那时,AI就不只是聊天机器人了,
而是能像人类一样处理复杂现实问题的助手!
虽然这其实很危险
但不正是人们想要的结果吗?
而AI评估的未来
将不会只在孤立的知识测试,
而在于对问题解决能力的全面评估。
像ARC-AGI和GAIA这样的基准测试,
正在架着通往真正AGI的桥梁!
你更看好哪个?
是偏重脑力操作的ARC-AGI?
还是强调实际动手能力的GAIA?
欢迎在评论区说说你的看法!
(文:AGI Hunt)