


在药物研发领域,高成本和高风险一直是困扰科学家们的难题。传统的药物研发过程繁琐且耗时,常常需要数年时间才能取得突破性进展。为了加速这一进程,谷歌推出了TxGemma,这是一款基于Gemma 2的高效、通用型大型语言模型(LLM),专门用于药物研发。TxGemma不仅能够进行药物特性预测,还具备对话能力和推理能力,为科学家们提供了一个强大的工具,帮助他们更高效地进行药物研发。
一、项目概述
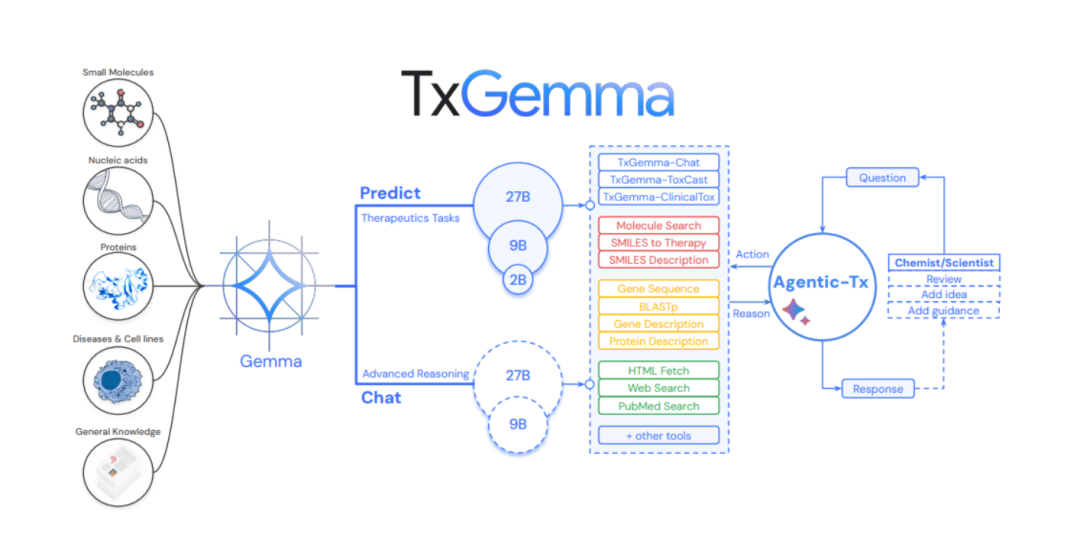
TxGemma是谷歌推出的一款高效、通用的药物研发大模型,基于Gemma 2架构微调,融合了700万治疗实体数据进行多任务学习。它能够理解和预测整个药物发现过程中治疗实体的属性,包括小分子、蛋白质、核酸、细胞系和疾病等,从确定有希望的目标到帮助预测临床试验结果。
TxGemma具备多任务处理能力、高效的预测能力、对话式交互以及微调能力,能够处理与自由文本交织的各种化学或生物实体信息,适用于广泛的治疗开发任务。它可以帮助研究人员预测潜在新疗法的重要特性,如安全性或有效性,从而缩短新药研发周期。
此外,TxGemma还具备对话模型,允许科学家和医学工作者以自然语言进行交互,为基于分子结构的预测提供机械推理,并参与科学讨论。
二、技术原理
(一)基于Gemma 2的微调
TxGemma是基于Google DeepMind的Gemma 2模型家族开发的,使用了700万训练样本进行微调,这些样本来自Therapeutics Data Commons(TDC),涵盖了小分子、蛋白质、核酸、疾病和细胞系等多种治疗相关数据。这种微调使得TxGemma能够更好地理解和预测治疗实体的属性,在药物发现和治疗开发的各个阶段发挥作用。
(二)多任务学习
TxGemma模型经过训练,能够处理多种类型的治疗开发任务,包括分类、回归和生成任务。多任务学习能力使模型能够综合考虑不同类型的治疗相关数据和问题,在多种场景下提供有效的预测和分析。
(三)对话能力的实现
为了实现对话能力,TxGemma的“聊天”版本在训练过程中加入了通用指令调整数据。这使得模型不仅能够进行预测,还能够以自然语言的形式解释其预测的依据,回答复杂问题,并参与多轮讨论。
三、功能特点
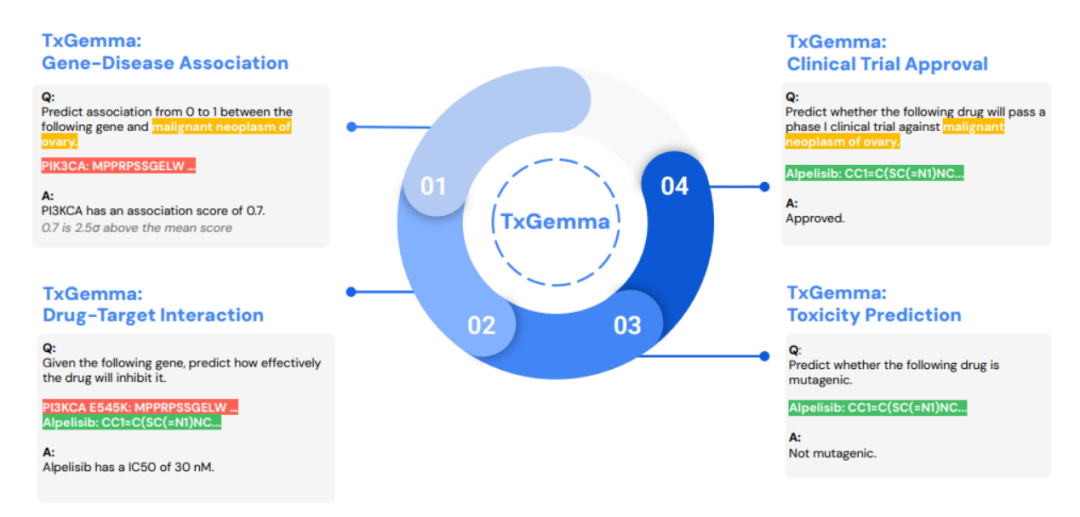
1.药物特性预测:TxGemma能够理解和解析化学结构、分子组成以及蛋白质相互作用,帮助研究人员预测药物的关键特性,如安全性、有效性和生物利用度。
2.生物医学文献筛选:TxGemma可以筛选生物医学文献、化学数据和试验结果,协助研发决策。
3.多步推理与复杂任务处理:基于Gemini 2.0 Pro的核心语言建模和推理技术,TxGemma能够处理复杂的多步推理任务,例如结合搜索工具和分子、基因、蛋白质工具来回答复杂的生物学和化学问题。
4.对话能力:TxGemma的“聊天”版本具备对话能力,能够解释其预测的依据,回答复杂问题,并进行多轮讨论。
5.微调能力:开发人员和医学研究者可以根据自己的治疗数据和任务对TxGemma进行适配调整。
四、应用场景
1.靶点识别与验证:在药物发现的早期阶段,TxGemma可以帮助研究人员识别潜在的药物靶点。
2.药物合成与设计:在药物合成过程中,TxGemma可以根据反应产物预测反应物集,为研究人员提供合成路径的建议,加速药物合成的进程。
3.治疗方案优化:在治疗方案的选择和优化方面,TxGemma可以根据患者的疾病特征、药物特性等因素,提供个性化的治疗建议。
4.科学文献解读与知识发现:研究人员可以利用TxGemma的对话能力,快速获取和理解大量的科学文献中的关键信息。
5.医学教育:在医学教育领域,TxGemma可以作为教学工具,帮助学生和医学专业人员更好地理解药物开发的复杂过程。
五、性能表现
(一)预测性能
TxGemma-27B-Predict在66个治疗开发任务中,有64个任务的性能优于或接近最先进的通用模型,在45个任务上表现更好。在与专用模型的比较中,TxGemma在50个任务上优于或媲美专用模型,在26个任务上表现更优。
(二)对话能力
TxGemma-Chat在MMLU基准测试中的准确率为73.87%,略低于Gemma-2-27B的75.38%,但在医学遗传学、高中统计学和大学化学等领域表现出轻微改进。与TxGemma-27B-Predict相比,TxGemma-27B-Chat在所有治疗任务上的相对性能提高了30%。
(三)代理系统性能
Agentic-Tx在ChemBench、GPQA和HLE基准测试中表现出色,分别在ChemBench偏好任务和HLE化学与生物学任务上实现了9.8%和14.5%的相对改进。
(四)数据效率
在TrialBench的严重不良事件预测数据上进行微调时,TxGemma-27B-Predict在不到10%的重新训练数据下达到了与基线Gemma-2-27B相当的性能。
六、快速使用
(一)环境准备
1. 安装必要的Python包:确保已安装`transformers`和`accelerate`库。如果尚未安装,可以通过以下命令安装:
pip install accelerate transformers2. 准备GPU环境:确保你的系统配置了GPU,并且已安装合适的CUDA版本。TxGemma模型较大,运行时需要较大的显存,推荐使用至少16GB显存的GPU。
(二)加载模型和Tokenizer
1. 加载模型和Tokenizer:从Hugging Face Hub加载TxGemma模型和对应的Tokenizer。
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("google/txgemma-9b-chat")model = AutoModelForCausalLM.from_pretrained("google/txgemma-9b-chat", device_map="auto")
(三)格式化提示(Prompts)
1. 加载TDC提示模板:从Hugging Face Hub加载Therapeutics Data Commons(TDC)的任务提示模板。
import jsonfrom huggingface_hub import hf_hub_downloadtdc_prompts_filepath = hf_hub_download(repo_id="google/txgemma-9b-chat",filename="tdc_prompts.json",)with open(tdc_prompts_filepath, "r") as f:tdc_prompts_json = json.load(f)
2. 构造任务提示:选择一个TDC任务,并根据模板构造提示。例如,预测药物是否能穿过血脑屏障(BBB)的任务:
task_name = "BBB_Martins"input_type = "{Drug SMILES}"drug_smiles = "CN1C(=O)CN=C(C2=CCCCC2)c2cc(Cl)ccc21"TDC_PROMPT = tdc_prompts_json[task_name].replace(input_type, drug_smiles)print(TDC_PROMPT)
(四)运行模型进行预测
1. 使用模型生成响应:将格式化好的提示输入模型,生成响应。
input_ids = tokenizer(TDC_PROMPT, return_tensors="pt").input_ids.to("cuda")outputs = model.generate(input_ids, max_new_tokens=8)response = tokenizer.decode(outputs[0], skip_special_tokens=True)print(response)
2. 使用Pipeline简化操作:也可以使用`pipeline` API,它会自动处理模型和Tokenizer的加载,简化代码:
from transformers import pipelinepipe = pipeline("text-generation",model="google/txgemma-9b-chat",device="cuda",)outputs = pipe(TDC_PROMPT, max_new_tokens=8)response = outputs[0]["generated_text"]print(response)
(五)对话式交互
1. 构造对话格式的提示:对于对话式交互,需要按照特定的格式构造提示,包括用户和模型的角色标记。
messages = [{"role": "user", "content": TDC_PROMPT}]chat_prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True
2. 生成对话响应:使用模型生成对话响应,并继续交互:
inputs = tokenizer(chat_prompt, return_tensors="pt").to("cuda")outputs = model.generate(inputs, max_new_tokens=8)response = tokenizer.decode(outputs[0], skip_special_tokens=True)print(response)# 继续对话messages.append({"role": "assistant", "content": response})messages.append({"role": "user", "content": "Explain your reasoning based on the molecule structure."})chat_prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)inputs = tokenizer(chat_prompt, return_tensors="pt").to("cuda")outputs = model.generate(inputs, max_new_tokens=512)response = tokenizer.decode(outputs[0], skip_special_tokens=True)print(response)
七、结语
TxGemma作为谷歌推出的高效药物研发大模型,通过其强大的预测能力、对话能力和推理能力,为药物研发领域带来了革命性的变化。它不仅提高了研发效率,还降低了研发成本,为科学家们提供了一个强大的工具。希望TxGemma能够帮助科学家们加速药物研发进程,为人类健康事业做出更大的贡献。
八、项目地址
项目官网:https://developers.googleblog.com/en/introducing-txgemma
模型下载:https://huggingface.co/collections/google/txgemma
技术论文:https://storage.googleapis.com/research-media/txgemma
(文:小兵的AI视界)