
这不就是
GPT-5前夜的预演吗?
OpenAI 又又又发新模型了。
这次不是炸场式炫技,也不是 GPT-5 正式登场。
而是一组以“实用主义”为导向的更新 —— 4 月 15 日凌晨,GPT-4.1 系列模型正式发布。
如果说约 2 个月前(2 月 27 日)发布的 GPT-4.5 是个“花架子”,那么这次的 GPT-4.1 就是主打一个:能干活。
而且,不止能干活,还便宜。
什么?有小可爱问,为什么 GPT-4.5 先发布,而 GPT-4.1 后发布?
很简单,4.1 = 4.10,4.10 > 4.5。

以上是开玩笑。
实际上,GPT-4.5 只是一个在当时不得不搬出来发布的“残次品”,参数量太大,性能却和参数不匹配;同时又是算力消耗怪兽,性价比接近于零。
据爆料,OpenAI 已准备逐步停用 GPT-4.5 的 API 访问,并于 7 月 14 日完全下架。
而本次的 GPT-4.1,就是来接班的。
01|什么是 GPT-4.1?它和你熟悉的 GPT-4o 有什么区别?
简单来说,GPT-4.1 是 GPT-4o 的“能力完全体”,主打三个关键词:超长上下文、编码、复杂指令理解。
-
GPT-4.1支持 100 万 tokens 上下文(GPT-4o只有 128K)。 -
GPT-4.1最大输出长度也翻倍,达 32K tokens(GPT-4o是 16K)。 -
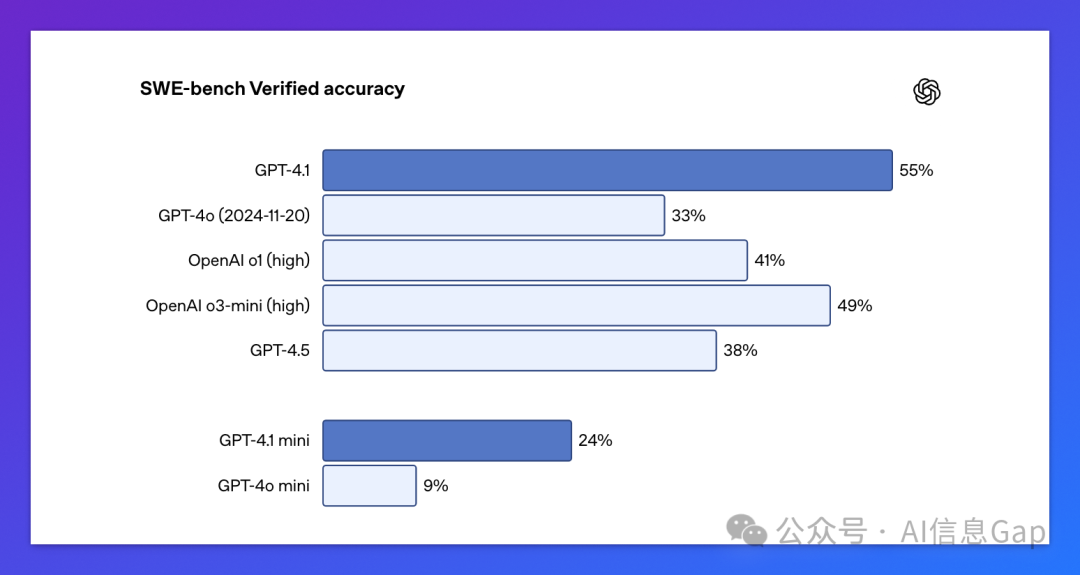
在 SWE-bench(真实软件工程任务)中得分 54.6%,完爆 GPT-4o的 33.2%。 -
多模态能力也大幅提升,视觉理解精度刷新多个基准。
在 SWE-bench 基准测试中,GPT-4.1 甚至把 o1 和 o3-mini 这样的推理模型都比下去了,这你能信。
而 GPT-4.1 还分为三种版本:
-
GPT-4.1(旗舰):性能全开,适合复杂任务 -
GPT-4.1 mini:更轻、更快,延迟减半,成本降 83% -
GPT-4.1 nano:极致性价比,适合大规模部署
价格对比如下(单位:每百万 token):
|
|
|
|
|
|---|---|---|---|
GPT-4.1 |
|
|
|
GPT-4.1 mini |
|
|
|
GPT-4.1 nano |
|
|
|
相比之下,GPT-4o 价格是 2.5 和 10 美元,GPT-4.1 简直是 “性能-价格” 双降维打击。

02|百万上下文是噱头还是真香?
一直以来,上下文长度一直都不是 OpenAI 模型擅长的领域。
GPT 系列模型的上下文保持 128K tokens 已经很久了。
而 GPT-4.1 系列模型全面支持最多 100 万 tokens 的输入,约等于一次性读进 750,000 个英文单词 —— 差不多 10 本《活着》堆一起。
这意味着什么?
-
一次性处理整部代码库,不用分段输入 -
长篇合同、研究论文直接丢进去,总结归纳一步完成 -
对话历史可保留长达几小时,做 AI 代理不再“失忆”
当然,也不是没有代价:
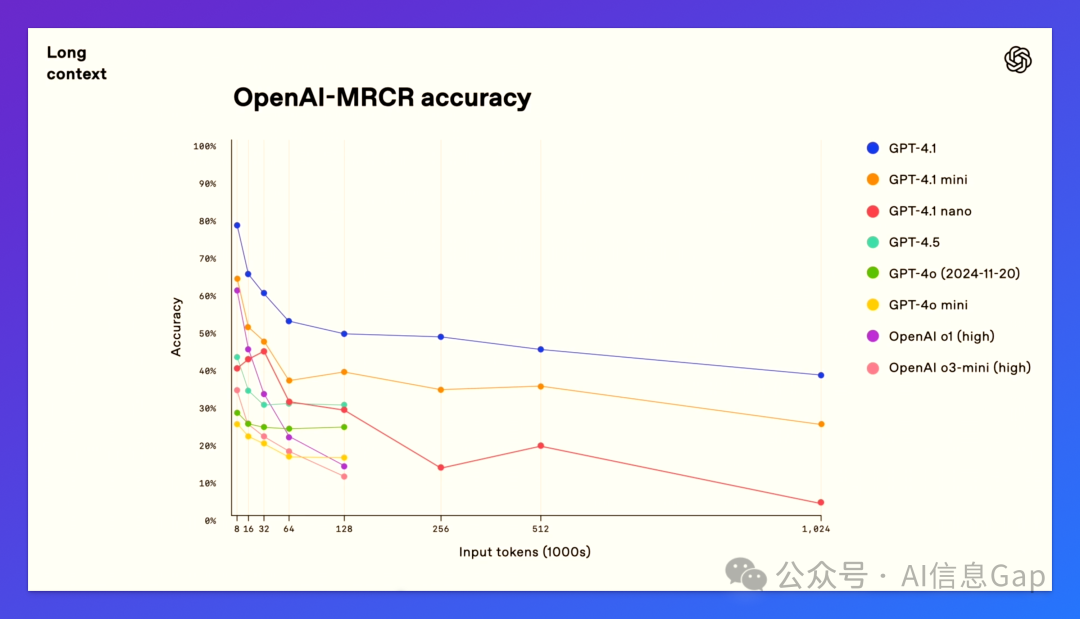
-
在 OpenAI 内部的 MRCR 测试中,模型在 8K token 输入时准确率是 84%,到了 1M token 降到 50% -
所以,如果你真要跑百万级上下文,提示设计很关键:关键信息放首尾,结构尽量清晰
03|“写代码”成了 GPT 的主业?
百万级上下文是 OpenAI 在和谷歌 Gemini 抢占高地,编码能力的提升就是在和 Anthropic 的 Claude 掰手腕了。
相较而言,GPT-4o 像是个“文艺型”通才,而 GPT-4.1 是个 “工科生出身的项目经理”。
它的编码能力,是真的有提升:
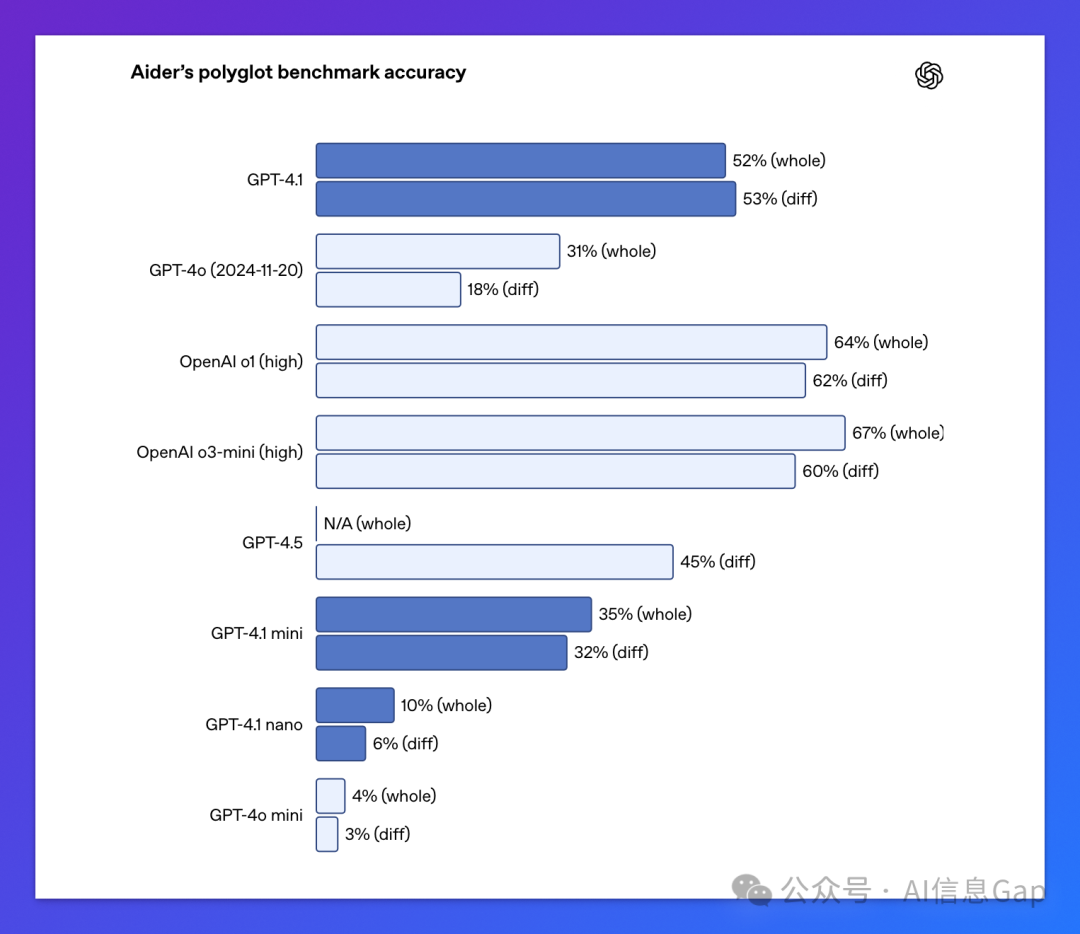
-
SWE-bench Verified 基准成绩 54.6%,远超 GPT-4o的 33.2%,也高于GPT-4.5的 28% -
在前端开发任务中,80% 的人工评分员更喜欢 GPT-4.1生成的网站 -
代码 diff 输出精度高,冗余编辑从 9% 降到 2%
这意味着什么?
开发者们,尤其是用 AI 编程工具 的小可爱,要准备迎接“
4.1编码引擎”了。
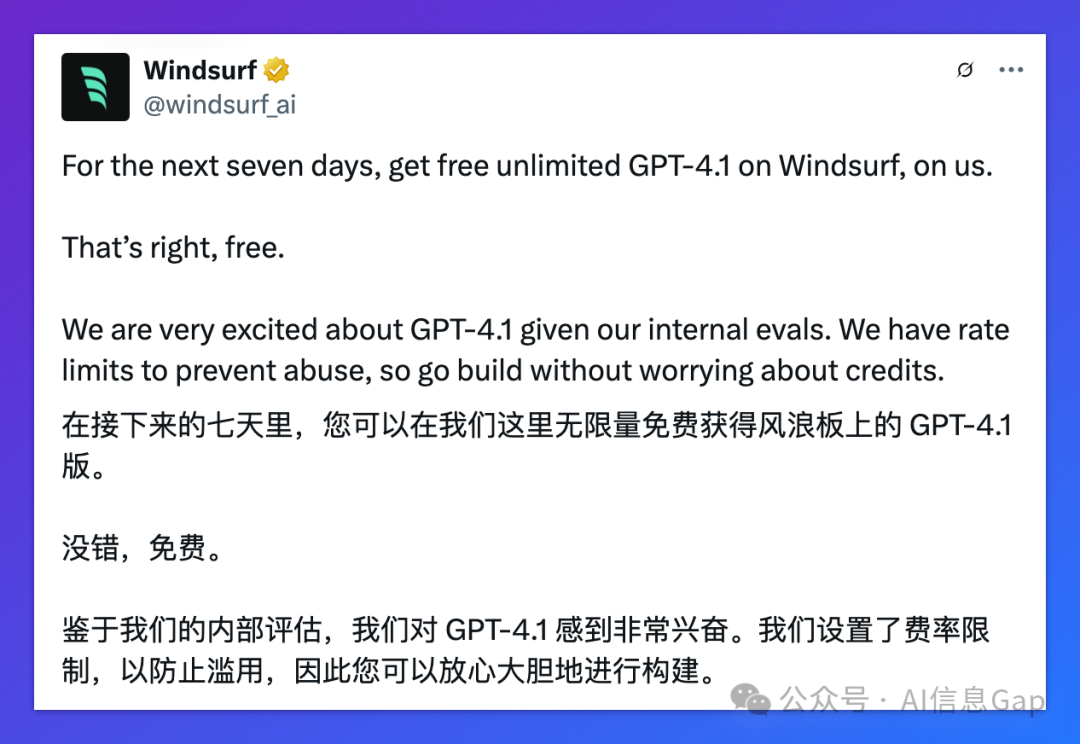
WindSurf 和 Qodo 的测试显示:
-
代码评审一次通过率 +60% -
工具调用效率提升 30% -
无用编辑行为下降 50%
同时,WindSurf、Cursor 纷纷宣布,未来一周内 GPT-4.1 模型通通免费。

04|长记忆 + 精准理解,“懂事的 AI 助理”?
一个被忽视的事实:GPT-4.1 在“复杂指令执行”上,也变得更可靠。
-
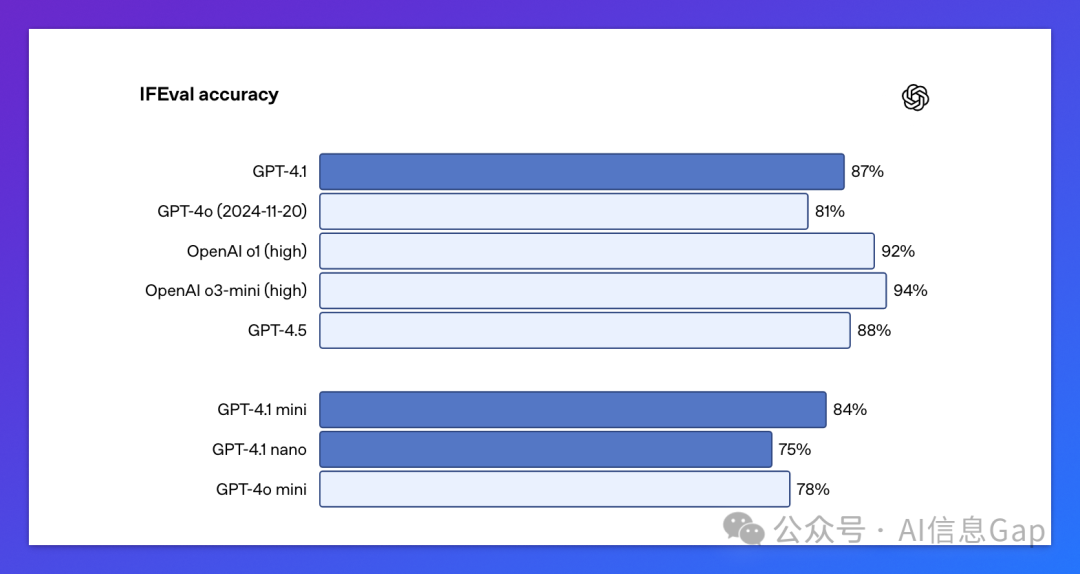
MultiChallenge 基准中得分 38.3%,比 GPT-4o高 10.5 个百分点 -
IFEval 上达到 87.4%,能正确理解格式、否定语气、顺序要求等复杂 prompt -
在结构化输出(如 YAML、Markdown)方面也更加稳定
这直接影响到两个方向:
-
AI 文档助手:生成规范格式的文档摘要、图表解析、跨文档归纳 -
AI 工作代理人:在工具堆栈中执行多步任务,如客服流程、财报归纳等
05|但,它也不是“万能模型”
GPT-4.1 的进化很猛,但也别忘了,它还不是“全能体”。
-
GPT-4.1 没有 GPT-4o 那种“多模态秒回语音”的体验 -
它的推理能力在一些基准上仍略逊于 Claude 3.7、Gemini 2.5 Pro -
对输入越多的任务,稳定性越受挑战(尤其 1M token 临界场景)
所以,不是所有人都适合用 GPT-4.1 ,选模型时依然要看需求:
-
你要“理解复杂任务+接长活”?用 GPT-4.1 -
你要“语音交互+多模态回复”?用 GPT-4o -
你要“推理优先+文采加成”?试试 Claude、Gemini
GPT-4.1 虽强,但也不是“天下第一”。
来看看最新的 LiveBench 大模型排行榜你就知道了。

06|GPT-4.1 可用性与接入指南
说个扎心的现实:GPT-4.1 系列模型目前不在 ChatGPT 里开放,别翻了,你找不到的。
它只开放给“搞开发的”和“能接 API 的”。
目前主要的使用方式是:
-
OpenAI API 平台:官方直供,保质保量,三款型号 ( GPT-4.1/mini/nano) 都能选,适合做产品商用。 -
Azure OpenAI:OpenAI 早期的金主爸爸微软,不仅能用,还支持微调。
搞不到 OpenAI 的 API,或者懒得折腾的小可爱怎么办?
太简单了,直接和我这个公众号聊天就行:GPT-4.1 凌晨刚发布,我连夜接入公众号!免费开放,无限畅聊!
官方 API、免费用、无限聊。
后面可能由于某些不可抗力因素,随时下架,且聊且珍惜。
结语:这是“干正事”的模型
GPT-4.1 不高调,不花哨,每一项改进都很实在。
-
百万上下文 -
编程能力 -
指令跟随能力
这波,真能用得上。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)