
Datawhale干货
作者:Datawhale开源项目团队,文末送书
一、开源初衷
2024年度图灵奖颁发给强化学习的两位奠基人Richard Sutton和Andrew Barto,既表彰其数十年的开创性研究,也标志着强化学习作为DeepSeek、ChatGPT等AI突破的核心技术,重塑了AI发展进程。
如何快速掌握这一关键技术?Datawhale的“蘑菇书”一直是强化学习入门的经典选择,自出版以来获得无数读者的喜爱,豆瓣评分8.3,被李宏毅、周博磊、李科浇、汪军、张伟楠、李升波、胡裕靖等强化学习领域大咖联袂推荐,还被牛津大学墨顿学院图书馆馆藏收录。
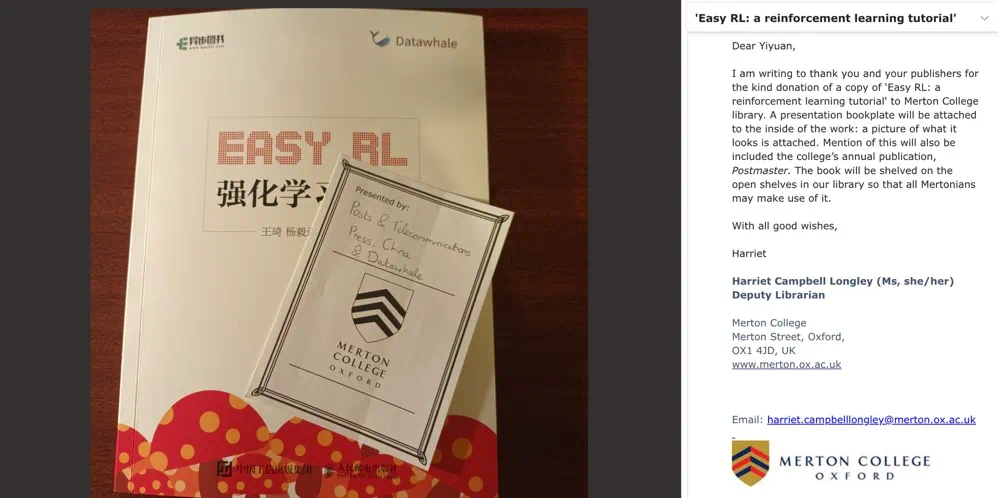
后来,作者团队发现读者在将理论应用到实践的过程中似乎遇到了一些困难。
首先,很多已经有人工智能知识基础的读者只是想用强化学习来做一些其他方面的交叉研究,但由于强化学习理论错综复杂,这类读者很难在短时间内快速把握重点,并且容易陷入一些与实践关系不大的小知识点的陷阱中。
其次,有一些读者很难将强化学习中的公式和实际代码对应起来,例如策略函数的设计等,并且对算法的各种超参数调整也不知从何处入手。
因此,“蘑菇书”原作者、开源组织 Datawhale 的成员江季、王琦和杨毅远针对读者的痛点,历时1年多,全新打造了这本更深入、实践性更强的《Joy RL:强化学习实践教程》。


与“蘑菇书”不同,本书对强化学习的核心理论进行提炼,并串联知识点,重视强化学习代码实践的指导而不是对理论的详细讲解。本书适合具有一定编程基础且希望快速进入实践应用阶段的读者阅读。

Datawhale坚持“开源协作+纸质出版”的知识生产模式,比如《Easy RL:强化学习教程》源自星标超10.8k的“蘑菇石 Easy RL”开源项目,《深度学习详解》源自星标超14.9k的“LeeDL-Tutorial”开源项目,这些项目发起过大规模学习活动,吸引了众多爱好者参与。
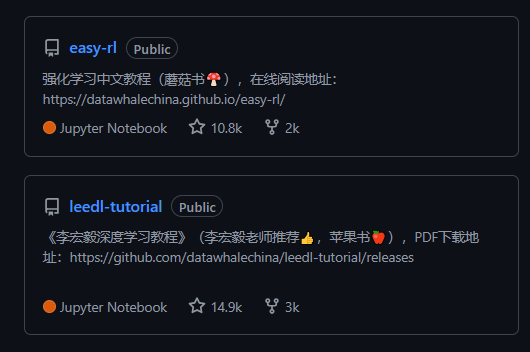
本书同样延续这一模式,作者团队在GitHub上发布了“Joyrl-book”开源项目,提供一套开源代码框架JoyRL,包含大量实际应用中的技巧和经验,带你深入掌握DQN、PPO等核心算法的实现精髓,让读者快速掌握工业级RL开发能力。
同时,这也是在人民邮电出版社的支持下,继“南瓜书”“蘑菇书”“熊猫书”“蝴蝶书”“苹果书”之后,推出的第6本系列纸质书。
二、从开源到出版
从李沐开源的《动手学深度学习》,邱锡鹏的《神经网络与深度学习》,再到Datawhale的《南瓜书》、《熊猫书》、《蘑菇书》、《蝴蝶书》、《苹果书》出版,让知识回归大众,让大众有机会和行业精英一样为社会做出贡献,是Datawhale开源内容的探索性意义。
从开源到出版,带来的收入其实不高,但让开源贡献者被大众认可是促使开源良性循环的重要一环,会促使国内的开源氛围变好,让更多人受益。
三、感谢老师们的鼓励和支持
感谢吴飞、俞勇 、李升波 3位AI领域大咖老师的亲笔认可和推荐。
——吴飞
浙江大学本科生院院长、人工智能研究所所长
在人工智能蓬勃发展的当下,强化学习作为关键技术,推动了像 DeepSeek 这样的前沿模型实现强大推与决策能力。本书以清晰的逻辑和生动的语言,系统讲解了从基础理论到前沿算法的强化学习知识,并通过实战案例和开源代码框架“JoyRL”,让读者快速上手实践。无论是初学者还是进阶学者,都能从中获得从理论到应用的全方位指导。它不仅帮助读者快速掌握核心技术,更为探索类似 DeepSeek 的先进模型奠定坚实基础。相信这本书将成为强化学习领域极具价值的学习指南,助力每一位读者在 AI 领域启智增慧,迈向未来。
——俞勇
上海交通大学特聘教授、ACM 班创始人、
伯禹教育创始人
强化学习作为机器学习的核心范式之一,其通过模拟人类与环境的交互机制,实现了智能体在复杂环境中的自主决策与策略优化,是通向通用人工智能的重要路径。近年来,以 DeepSeek 为代表的新一代人工智能模型突破性地采用强化学习范式,成功克服了传统大语言模型过度依赖监督学习的局限性,展现出更强大的智能涌现能力,这进一步彰显了强化学习在人工智能发展进程中的战略价值。本书不仅系统性地阐述了强化学习的理论基础与算法框架,更创新性地结合丰富的实战案例与开源代码框架“JoyRL”,让读者实现从理论到实践的无缝衔接。无论是强化学习领域的入门者,还是致力于前沿探索的研究者,都能从中获得深刻的洞见与实践指导,为未来参与 AI 模型的创新研发奠定坚实的理论与技术基础。
——李升波
清华大学车辆与运载学院长聘教授、博士生导师
首先,拿捏强化学习的“变与不变”
强化学习的发展是迅速的,首先要把握好强化学习的“变与不变”。
学习强化学习,初期是不涉及深度神经网络相关知识的,这一部分通常称为传统强化学习。虽然这部分的算法在今天已经不常用,但是其中蕴含的一些思想和技巧是非常重要的,因此读者需要对这部分内容有所了解。所以,在学习深度强化学习部分之前,本书还梳理了需要了解的深度学习知识。
本书在第3章中还讲解了动态规划的思想及其在强化学习中应用的两个算法(策略迭代算法和价值迭代算法),这两种算法虽然目前很少用到,但是对于推导更复杂的强化学习算法起到了奠基的作用,建议掌握它们。


全书共12章,内容系统翔实,不仅涵盖经典强化学习的内容,还包括深度强化学习的重要成果,涵盖马尔可夫决策过程、动态规划、免模型预测、免模型控制、深度学习基础、DQN 算法、DQN 算法进阶、策略梯度、Actor-Critic 算法、DDPG 与 TD3 算法、PPO 算法等内容。对于每个算法,书中都提供了清晰的实现步骤和调参建议。
理论与实践经验结合,理解相关知识
本书的内容主要基于作者们的理论知识与实践经验,并融入了一些原创内容,例如针对策略梯度算法的两种不同的推导版本,以便让读者从不同的角度更好地理解相关知识。
全书始终贯穿强化学习实践中的一些核心问题,比如优化值估计的实践技巧、解决探索与利用的平衡等问题,这些都来自作者团队的真实项目经验。

同时,本书对理论部分删繁就简,并将其与实践紧密结合,搭配丰富的图、表、代码示例,帮助读者清晰梳理强化学习中各类方法的内在联系,将复杂理论拆解成通俗易懂的内容,搭配丰富实用的实践案例,让读者不知不觉就掌握了这门技术。
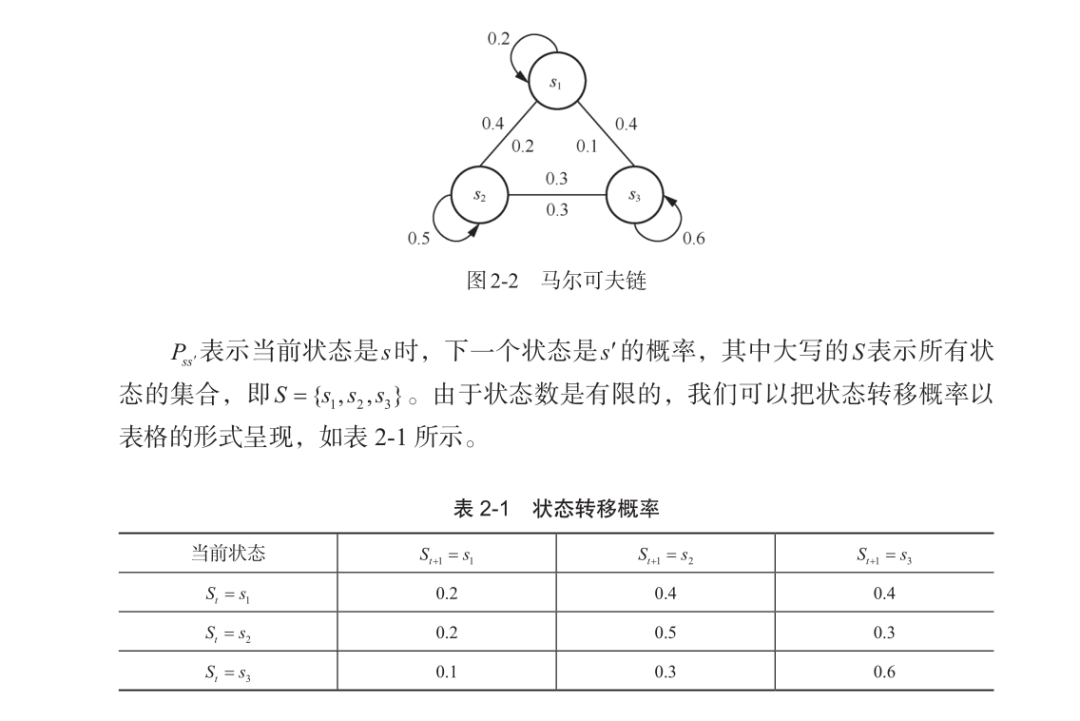

书中数学公式推导详细易懂,从根本理解强化学习概念
本书从第2章开始介绍强化学习中的基本问题模型,涉及的理论公式推导都有清晰的步骤。例如,马尔可夫决策过程(Markov decisionprocess,MDP)能够以数学的形式来表达序列决策过程。

由于本书意在让读者更加深入地掌握强化学习,因此在不同章节中还扩展了一些重要概念。例如,在第2章中讲解了马尔可夫性质、回报、状态转移矩阵、轨迹、回合等知识。书中还重点讲解了一些初学者很容易混淆的关键概念,例如状态价值函数和动作价值函数。

还重点对比了算法之间的差异,帮助读者更好地理解算法,例如时序差分方法和蒙特卡罗方法之间的差异。
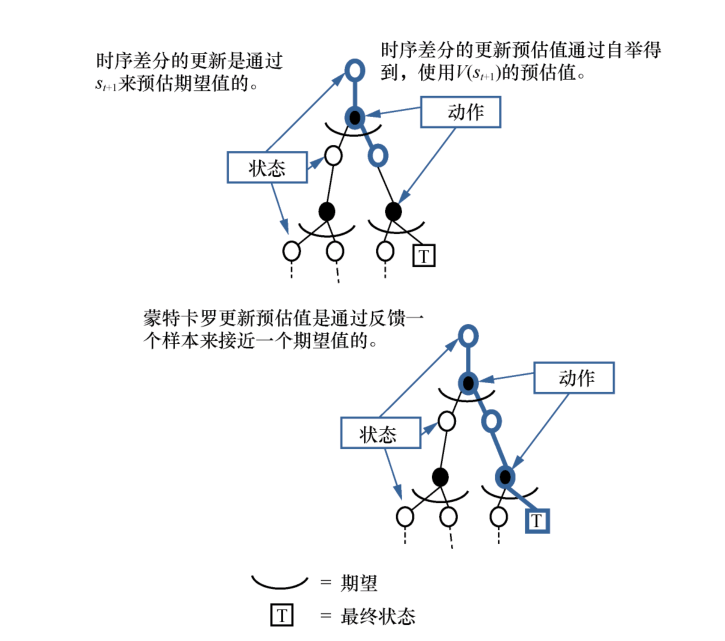
代码资源丰富,通过大量练习巩固学习成果
本书包含大量的算法和环境,例如SoftQ、RainbowDQN等,代码内容更偏向业界风格。
除了以Jupyter Notebook的形式呈现一些简单的配套代码之外,还提供一套“JoyRL”开源框架,便于读者应用到更复杂以及自定义的环境中,适合做交叉应用的读者。

每章末尾精心设计的练习题,则构成了完整的学习闭环。这些题目不仅能够检验读者对理论知识的掌握程度,更包含大量实践任务,确保读者能够真正学以致用。



Richard Sutton曾预测:“到 2030年,AGI(通用人工智能)有25%的可能性实现;到2040年,这一概率将升至50%。” 强化学习,无疑是推动这一进程的关键技术。
如果你想真正掌握强化学习,那么《Joy RL:强化学习实践教程》 是一本不可多得的实践指南,它既避免了纯理论的枯燥,又提供了丰富的代码示例,可以帮助读者从“知道”到“做到”,在强化学习的道路上走得更快、更稳!
目前是首批发行,限时最低优惠购买 ⬇️

最后,为了感谢各位读者的一直以来的支持,在Datawhale送出5本《Joy RL:强化学习实践教程》,依然是老规矩:评论区留言并点赞数前五的读者将直接送书。

(文:Datawhale)