
马斯克、苏姿丰同榜,中国 AI 终于有人杀进《时代》百大!
4 月 16 日,美国《时代》周刊公布了 2025 年“全球最具影响力 100 人”名单。

在这个被马斯克、苏姿丰、朱浩伟、诺娃等人包围的名单里,一个中文名字悄然出现 —— 梁文锋,DeepSeek 创始人兼 CEO,被归入 “Pioneers(拓荒者)” 一栏。
这不是象征意义的礼貌提名,而是实打实的行业认可。
《时代》的原文评价直接这样写道:
“DeepSeek 在资源受限的条件下,构建出性能媲美 ChatGPT 的生成式 AI 模型,打破了硅谷对先进 AI 的垄断。”
一句话,分量极重。
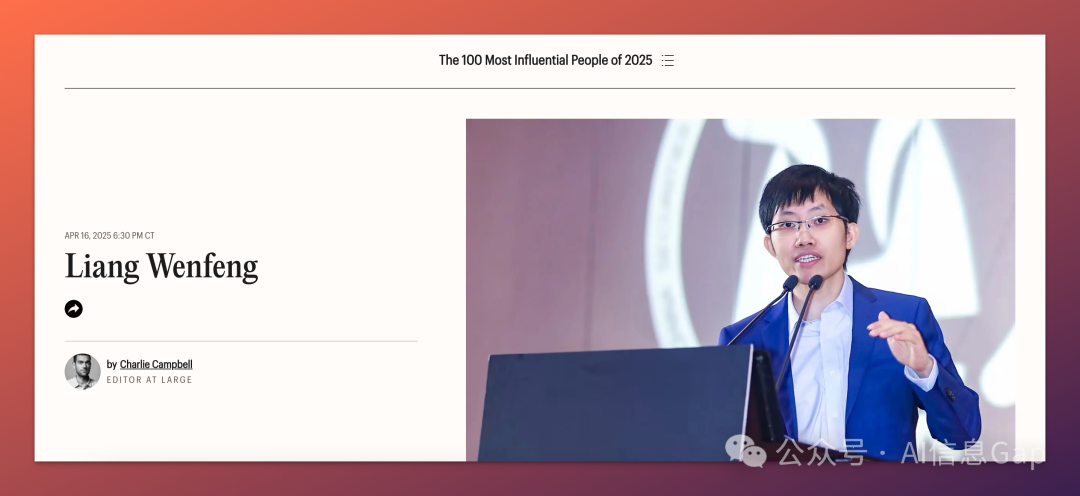
01|他不是马斯克,但他做到了马斯克做不到的事
“低调”“硬核”“不讲情绪值,只讲模型值”,这是圈内人对梁文锋的普遍印象。
如果说马斯克是科技界的 “段子手 + 话题制造机”,梁文锋就是那种话少但事做得漂亮的 “技术老炮儿”。
他并不是那种从少年编程天才一路走红的人物。相反,他的履历甚至有点 “跑题”:本科浙大, ,早期混迹量化投资圈,在幻方量化赚到了 “人生的第一个五亿”。

2023 年,他突然转身入局 AI,成立 DeepSeek,做了一件很多人觉得“不可能”的事:
在不到两年的时间里,带团队做出一套性能接近 ChatGPT、但训练成本不到 OpenAI 五分之一的中文大模型,还把核心模型 “RAG-7B” 直接开源,拉起了中国 AI 开源的旗帜。
是的,你没看错 —— 开源。白给那种。
这种反主流的操作,偏偏被全世界记住了。
02|DeepSeek,到底做对了什么?
先说一个冷知识:
ChatGPT 的训练成本有多高?业界估算大概是 1 亿美元左右,使用上万张 A100 显卡。
DeepSeek 的 R1 模型呢?仅用了不到 2000 张 H800 卡,训练了 55 天,成本约 550 万美元。

结果,在多个国际评测榜单上,DeepSeek 的表现不仅能 “摸到 GPT-4 的影子”,而且在一些中文任务中甚至更强。
更重要的是,它没有封闭。没有靠山、没有平台绑定,也不是 “某 AI 国家队” 项目。
它以一种极其 “民间”、极其草根的方式,把 AI 这场仗打到了世界舞台。
2024 年初,DeepSeek 在 Hugging Face 上开源的 RAG-7B 模型火速下载百万次,被海外开发者称为 “最值得上手的性价比大模型”。
到了 2025 年 2 月,DeepSeek 的 App 甚至一度登顶苹果应用商店的免费榜第一,超越了霸榜已久的 ChatGPT。

这就很微妙了。
当大多数人还在讨论“中国 AI 怎么追”,DeepSeek 用实绩说了一句 —— “我们已经赶上来了”。
03|为什么是梁文锋?
一个极简的推测:他做了很多大公司做不了的决定。
比如,大模型做不成就放弃 —— 他没有。
比如,性能不如 GPT-4 就先等一等 —— 他没等。
比如,等融资、等政策、等合作、等国际算力转包商 —— 他什么都没等。
他自己组队、自己压成本、自己招技术,做了个 “以小博大” 的中国 AI 实验室。
不是那种 “象牙塔研究型” 的 AI,而是真能跑起来、能落地、还能开源的 AI。
所以,才有了今天的《时代》百大拓荒者。
所以,有人说他是 “AI 圈的马斯克”。
我倒觉得,他是另一个维度的 “梁文锋” —— 一个用中国方式打 AI 仗的技术理想主义者。

04|AI 开源的背后,是一种对未来的选择
你可能会问:现在做 AI 的人那么多,开源的人那么少,为什么 DeepSeek 偏要走这条 “开源即燃烧自己” 的路?
梁文锋在 2024 年世界人工智能大会上说过一句话,足够回答:
“AI 不应该是少数巨头的玩具。我们真正需要的是普惠。”
也许正是这种理念,才让他成为《时代》榜单上少有的亚洲面孔,也成为硅谷之外,全球 AI 舞台上真正 “可被命名” 的中国创业者。
而开源,不只是一个策略。
它是一种姿态,也是一种野心。
结语
梁文锋入选《时代》百大,不只是他一个人的高光时刻,更是中国 AI 技术走上世界主场的象征。
DeepSeek 证明了,在没有 OpenAI 级别的资金、算力、资源背景下,中国人一样可以做出世界级 AI 模型。
这一刻,梁文锋不仅是技术人眼中的 “模型大神”,更是普通人心里那个 “打破垄断” 的代言人。
愿这不是结尾,而是一个开始。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)