
OpenAI的o1刚刚亮相,就被诟病起能力不行!
有人说它「不够好」,有人说是「没用好」,到底谁说得对?
实力到底如何?
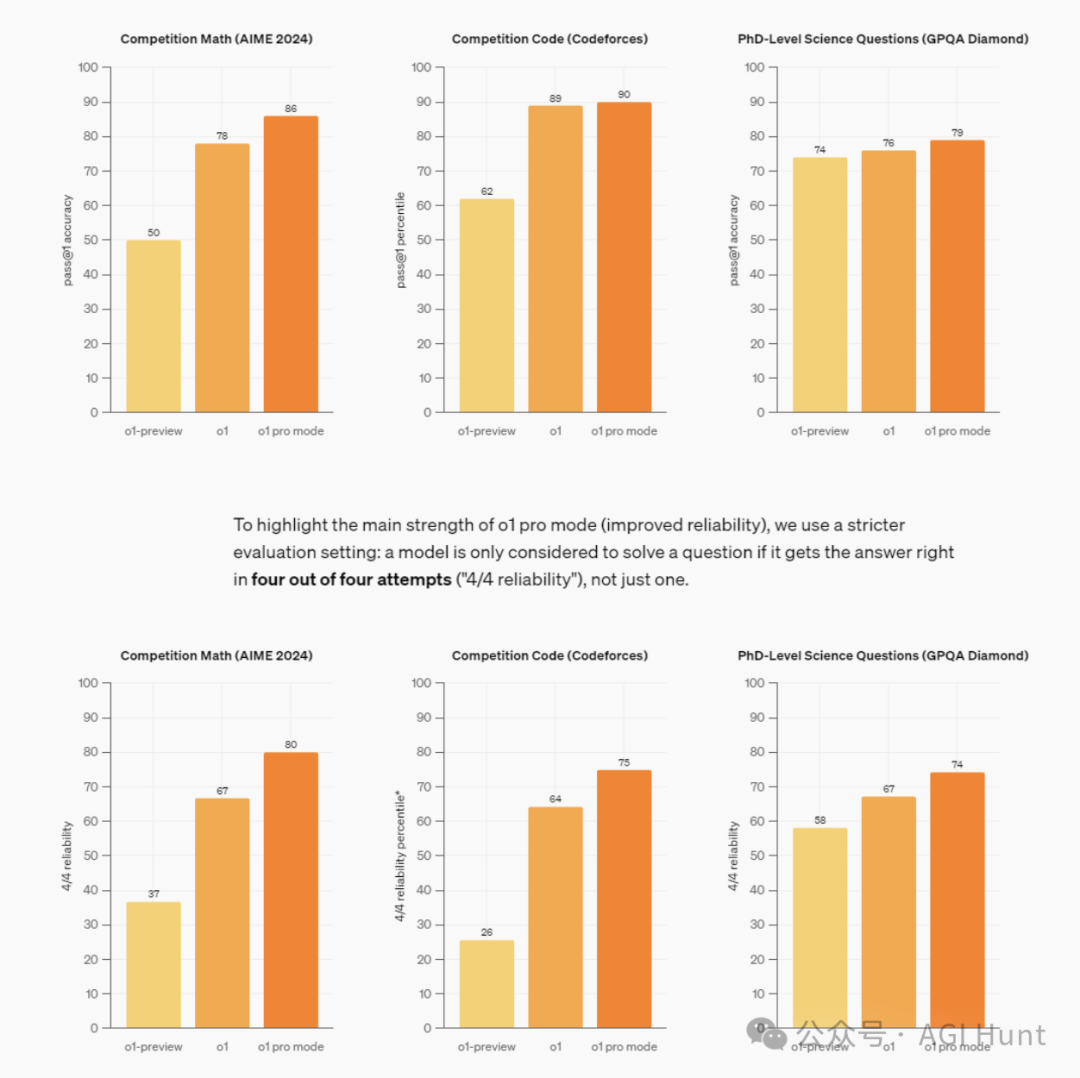
数据显示,在竞赛数学、竞赛代码和博士级科学问题上,o1都展现出了惊人的能力。特别是在pro模式下,其表现更是令人瞩目。
@Patrick’s AIBuzzNews直言:
「o1的智能水平已经超过99%的人类」。
这个评价虽然风格大胆如Sam Altman,但从测试数据来看,确实令人印象深刻。
@JE_Colors 给出了实测具体数据:
「o1在处理相同任务时,速度比之前快了4倍(19秒 vs 76秒)」。
争议从何而来?
但为什么还是有这么多人不满意呢?
原因似乎有很多:
技术认知的偏差:
-
很多人对o1的技术本质存在误解。@Adam Goldstein就纠正了一个重要概念:
o1使用的是测试时计算(Test-Time Compute),而不是测试时训练(Test-Time Training)
-
@arunabh补充说:
这其实是在语言领域的搜索,而不是测试时训练
这些技术细节的误解,往往会导致人们对o1的能力边界产生错误预期。
使用方式的问题:
-
@JE_Colors 指出:
很多人还在用对待GPT-4的方式来使用o1
-
@IA Latinoamérica更是直言不讳:
『不够好』其实等于『不知道如何使用这个工具』
期望过高:
-
@Jo认为:
这可能是因为OpenAI此前对Q/Strawberry的过度炒作*
-
@gerver Alvarez指出:
当Claude 3.5 Sonnet能达到相似效果时,人们就会质疑o1的优势
专业人士怎么看?
@Sithamet作为一线开发者指出了o1的具体问题:
在处理人类语言和代码混合的场景时,确实比GPT-4更容易混淆。
但他也强调:「批评能帮助实验室进步,因为他们无法在实验室环境中测试所有场景」。
@BeijingChef则从使用门槛的角度提出:
目前能真正测试o1能力的,可能只有拥有精英工作经历的博士或顶尖硕士。对普通用户来说,甚至都无法提出足够专业的问题来挑战它。
社区反思
@Sola对当前社区的风气提出了尖锐批评:
AI社区已经变成了一个只关注性能指标的有毒粉丝圈,像个黑洞一样只进不出,却很少有人真正专注于用现有工具创造有意义的产品和创新。
@Nifty则呼吁:「与其批评它的局限性,不如想办法更有效地利用它」。
未来可期
值得注意的是,@kimmonismus说到,o1还只是第一个版本,而且是在2023年10月才被发现的技术。
未来的o2、o3必然会带来更多惊喜。
@NeuralNet试图指出技术进步的本质:「进步是以迭代来衡量的,而不是期望。每一次循环都在完善系统,未来总会超越现在。这就是无限展开的方式」。
@Pollux更是预测:「明年的AI代理(agents)会让人们真正认识到这些模型有多智能」。
面对全新的AI模型,也许我们更应该做的是:如何更好地使用它,而不是抱怨它还不够完美。
好了,不说了,我要去充钱买o1 pro 了!
(文:AGI Hunt)