

新智元报道
新智元报道
【新智元导读】香港中文大学(深圳)的研究团队发布TASTE-Rob数据集,含100856个精准匹配语言指令的交互视频,助力机器人通过模仿学习提升操作泛化能力。团队还开发三阶段视频生成流程,优化手部姿态,显著提升视频真实感和机器人操作准确度。
随着具身智能的不断发展,机器人操作也逐渐融入到人们的日常生活中,可辅助完成物体抓取、倒水、表面清洁和整理等任务。
通过模仿学习,如今的机器人能够模仿视频演示中的动作,完成对应的任务。但要求操作环境与视频演示中的环境几乎完全相同,这限制了其在新场景中的泛化能力,比如:当被操作物体的位置或被操作物体本身发生变化时,机器人便无法准确地完成任务。
为解决机器人操作泛化能力不足的问题,近期研究将模仿学习与视频生成等生成模型结合,通过生成机器人-物体交互的演示视频来提升泛化能力。
但是,由于机器人数据难以采集,无法收集到大量的高质量数据,这类方法所提供的泛化能力仍然有限。
鉴于人手操作视频数据量庞大且采集难度低,一种更具扩展性的方案是生成「人手-物体」交互的演示视频,以实现更优的泛化效果。
此外,当前先进的策略模型已能够有效弥合人手与机器人操作之间的差异,通过模仿人手交互动作控制机器人执行任务,并展现出良好的应用潜力,进一步验证了该方案的可行性。
不过,由于缺乏高质量的人手-物体交互视频及其详细任务指令,当前通用视频生成模型在生成特定任务和环境下的交互视频时,仍然面临挑战。
为攻克现有挑战,香港中文大学(深圳)的研究团队推出了首个面向任务的大规模人手-物交互数据集TASTE-Rob,涵盖了100,856个匹配精准语言指令的第一视角交互视频。

论文地址:https://arxiv.org/abs/2503.11423
项目主页:https://taste-rob.github.io/
GitHub地址:https://github.com/GAP-LAB-CUHK-SZ/TASTE-Rob
区别于Ego4D,TASTE-Rob通过固定机位,独立拍摄单次的完整交互过程,确保了环境稳定、指令与视频精准对应等特性,为模仿学习等领域提供了高质量数据。
研究团队提出三阶段视频生成流程:先基于指令和环境图像生成初步演示视频,再借助运动扩散模型优化手部姿态序列以解决抓取姿态不稳定的问题,最后再根据优化后的姿态重新生成视频,显著提升了手物交互真实感。
实验证实,该数据集与三阶段流程的结合,在视频生成质量和机器人操作准确度上均大幅超越现有生成模型。


TASTE-Rob包含了100,856组视频及其对应的详细语言任务指令。为满足人手-物交互视频生成需求,TASTE-Rob旨在实现以下目标:1)所有视频采用固定机位拍摄,每个视频仅记录一段与任务指令高度匹配的动作;2)覆盖多样化的环境和任务类型;3)包含各类人手-物交互场景下的丰富手部姿态。
图1展示了数据集覆盖的环境包括厨房、卧室、餐桌、办公桌等场景;以及数据采集过程中,采集者需与各类常用物品进行交互,执行拿取、放置、推挪、倾倒等操作。
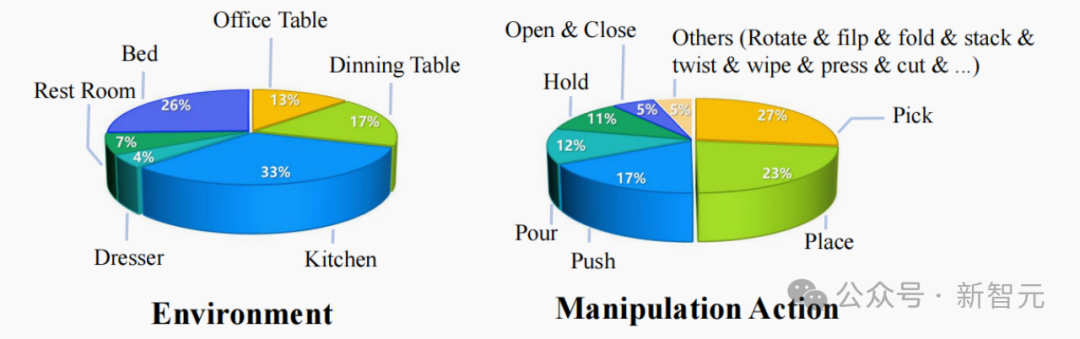
图1:TASTE-Rob场景及动作类型统计
图2展示了数据集中手部抓握姿态的分布,主要关注拇指、食指和中指的指间夹角与弯曲度。由于被抓取物体和执行动作类型的多样性,数据集覆盖了丰富的抓握姿态。
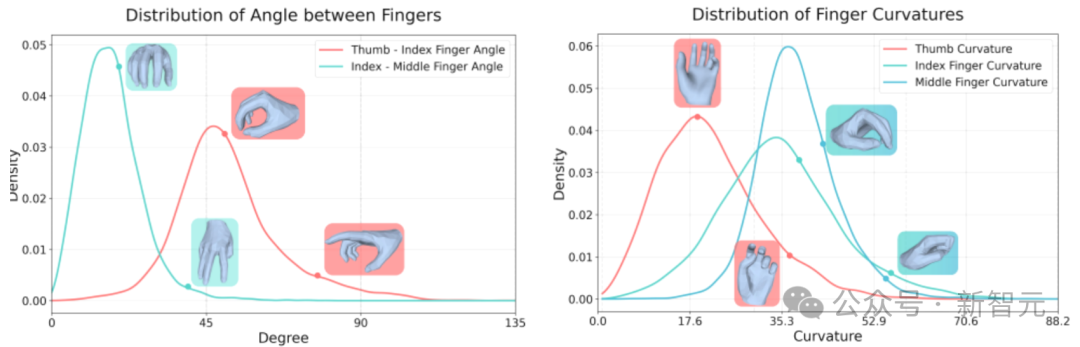
图2:TASTE-Rob手部抓握姿态统计
表1展示了TASTE-Rob数据集与现有的第一视角人手-物交互(HOI)视频数据集的对比情况,主要的区别体现在以下几点:
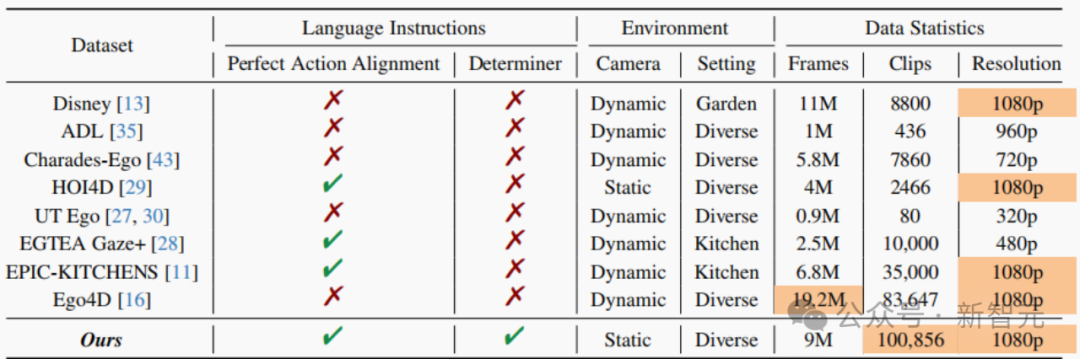
表1:TASTE-Rob与现有HOI数据集的对比
1. 相机视角及动作-指令匹配程度:考虑到模仿学习中的视频演示一般从固定的摄像机视角进行录制,并且仅包含一个与任务指令相匹配的单一动作,因此TASTE-Rob中用了同样的设置条件;
2. 语言指令的详细程度:为了进一步提升对语言指令的理解程度,TASTE-Rob在指令中融入了丰富多样的物体限定词,从而生成有效且准确的演示视频;
3. 数据量及数据质量:TASTE-Rob拥有最多的视频片段数量和1080p的视频分辨率。
当给定一张环境图像和一个任务指令描述,所生成的人手-物交互视频需满足:
1. 准确的任务理解:能正确理解要操作的物体以及操作方式;
2. 可行的手物交互:在整个操作过程中保持一致的手部抓握姿势。
如图3的第一阶段所示,在TASTE-Rob数据集上微调的视频生成模型所生成的视频虽然能准确理解任务,但在保持一致抓握姿势方面表现一般。
为了满足这两个要求,该研究团队在第二阶段从生成视频中提取手部姿态序列,并使用训练得到的运动扩散模型对其进行优化,并在第三阶段基于优化后的手部姿态序列,生成同时满足上述两个要求的高真实度人手-物交互视频。
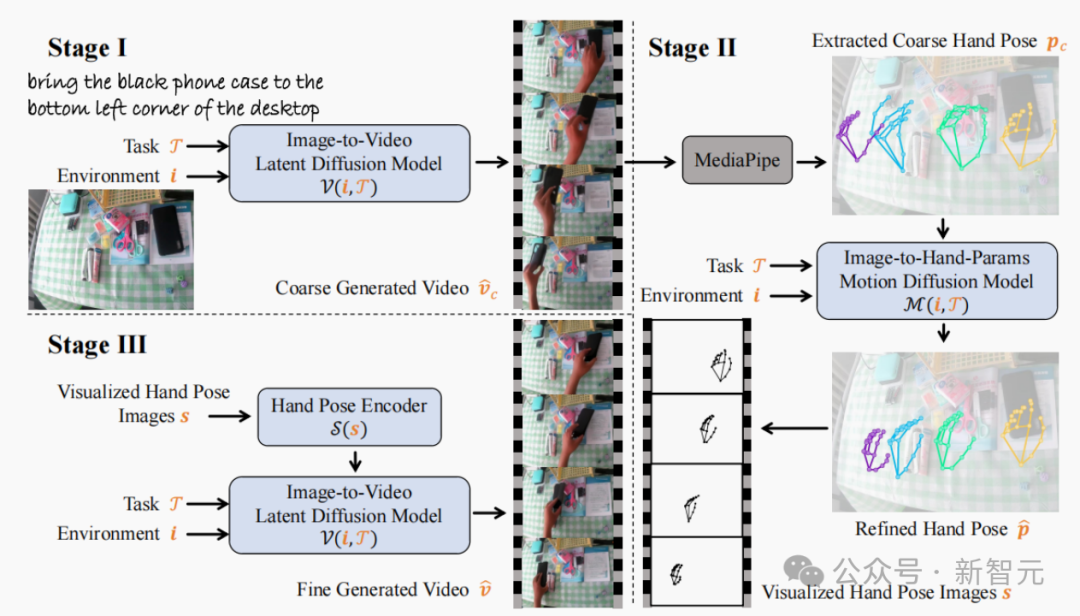
图3:三阶段视频生成流程

研究团队探索了TASTE-Rob对视频生成质量的帮助:对比了在TASTE-Rob数据集上微调(Coarse-TASTE-Rob)与在Ego4D数据集上微调(Ego4D-Gen)的视频生成性能,两者间唯一的区别在于所使用的训练数据集不同。
如表2和图4所示,TASTE-Rob数据集带来了更优的生成质量。

表2:在Ego4D/TASTE-Rob上微调视频生成模型的数值结果

图4:在Ego4D/TASTE-Rob上微调视频生成模型的可视化结果
研究团队从三个评估维度上探索了三阶段视频生成流程对视频生成质量的帮助:如表3的视频生成指标和图5所示,视频生成的宏观表现上,该流程能够生成更高质量的手物交互视频。
视频生成的细节表现上,表3中的抓握姿态一致性指标和图5的结果进一步验证了,该流程有效解决了抓握姿态不稳定的问题,成功帮助机器人实现更准确的操作。
此外,在机器人的模仿学习效果上,如图6和表3中的成功率指标所示,该流程有助于策略模型更准确地完成任务,显著提升了任务成功率。

表3:使用/不使用三阶段视频生成流程的数值结果

图5:使用/不使用三阶段视频生成流程在真实场景测试集的可视化结果
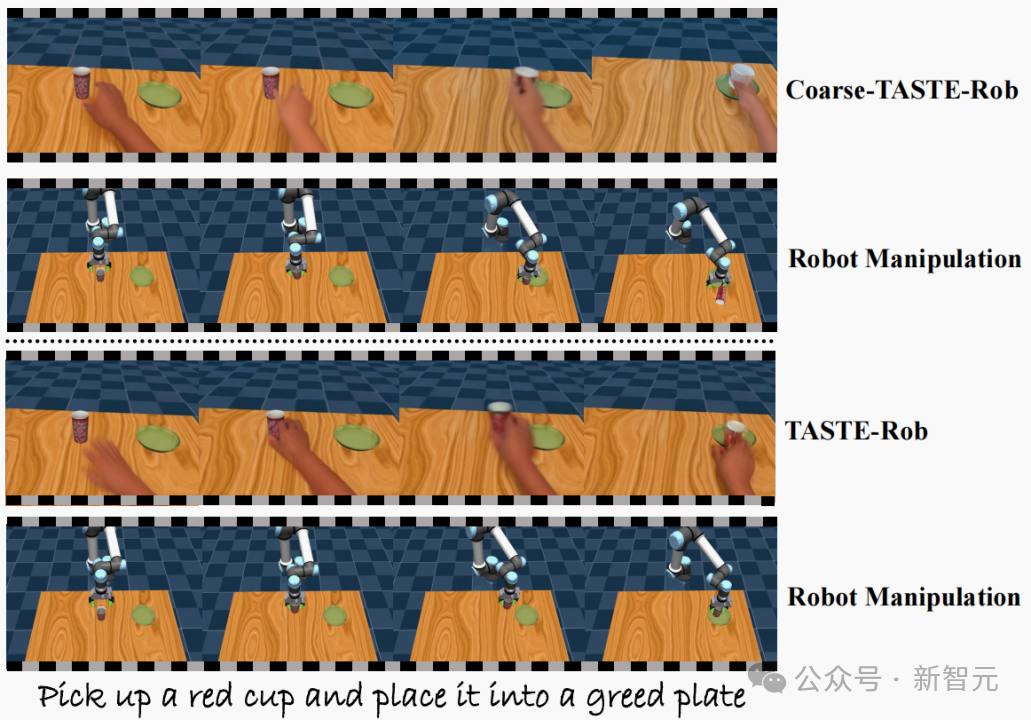
图6:使用/不使用三阶段视频生成流程在机器人仿真平台测试集的可视化结果
总的来说,TASTE-Rob将会为整个具身智能社区带来很多诸多可能性与挑战,更多数据集与实验细节请参阅原论文。
(文:新智元)