


在硬件层面,百度宣布正式点亮自研的昆仑芯P800的三万卡集群,并同步发布了昆仑芯超节点,昆仑芯超节点支持把64张昆仑芯AI加速卡放到同一个机柜,据悉,与以往方案相比,昆仑芯超节点能将单机训练性能提升10倍,单卡推理性能提升13倍,持续发力AI基础设施。

作为一年一度的AI开发者盛会,百度再次秀了一波AI大厂的综合实力。

在今天的大会开场演讲中,百度创始人李彦宏再次谈到AI应用的重要性。

超出市场预期,百度连发两款大模型:文心大模型4.5 Turbo和文心大模型X1 Turbo,主打多模态、强推理、低成本三大特性。
其中,文心大模型4.5Turbo,每百万token的输入价格仅为0.8元,输出价格3.2元,相比文心4.5,价格下降80%,仅为DeepSeek-V3的40%;文心大模型X1 Turbo,输入价格为每百万token1元,输出价格4元,相比文心X1,性能提升的同时价格再降50%,仅为DeepSeek-R1的25%。
李彦宏认为,当前开发者做AI应用的一大阻碍,就是大模型成本高、用不起,成本降低后,开发者和创业者们才可以放心大胆地做开发,企业才能够低成本地部署大模型,最终推动各行各业应用的爆发。
此外,文心大模型4.5 Turbo和X1 Turbo都进一步增强了多模态能力,在多个基准测试集中,文心4.5 Turbo多模态能力与GPT 4.1持平、优于GPT 4o。
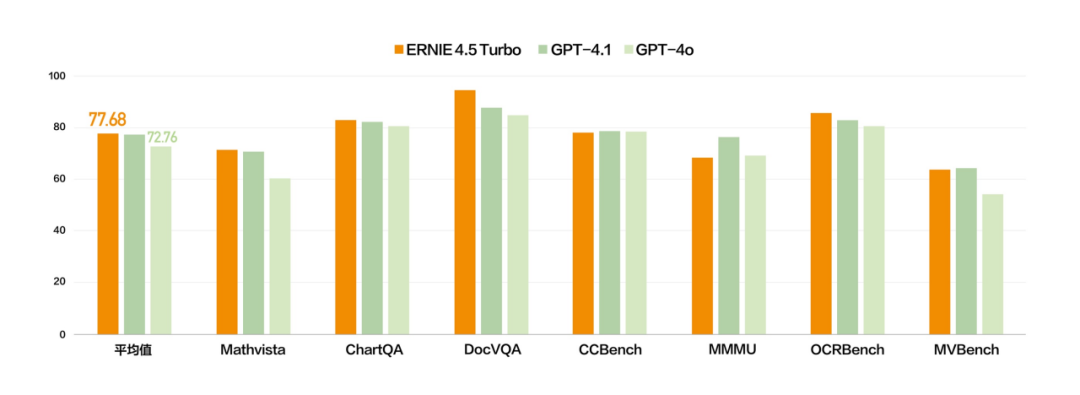

文心大模型X1 Turbo是基于4.5 Turbo的深度思考模型,性能提升的同时,具备更先进的思维链,问答、创作、逻辑推理、工具调用和多模态能力进一步增强,整体效果领先DeepSeek R1、V3最新版。
会上,李彦宏还正式发布多智能体协作APP心响,定位是可以一站式解决用户复杂问题的“通用超级智能体”,据悉覆盖了知识解析、旅游规划、学习办公等场景中200个任务类型。
为了迎接AI应用的井喷,百度搜索开放平台发布了“AI开放计划”,为智能体、H5、小程序、独立App等应用开发者提供流量和收益,为用户提供最新最全的AI服务。
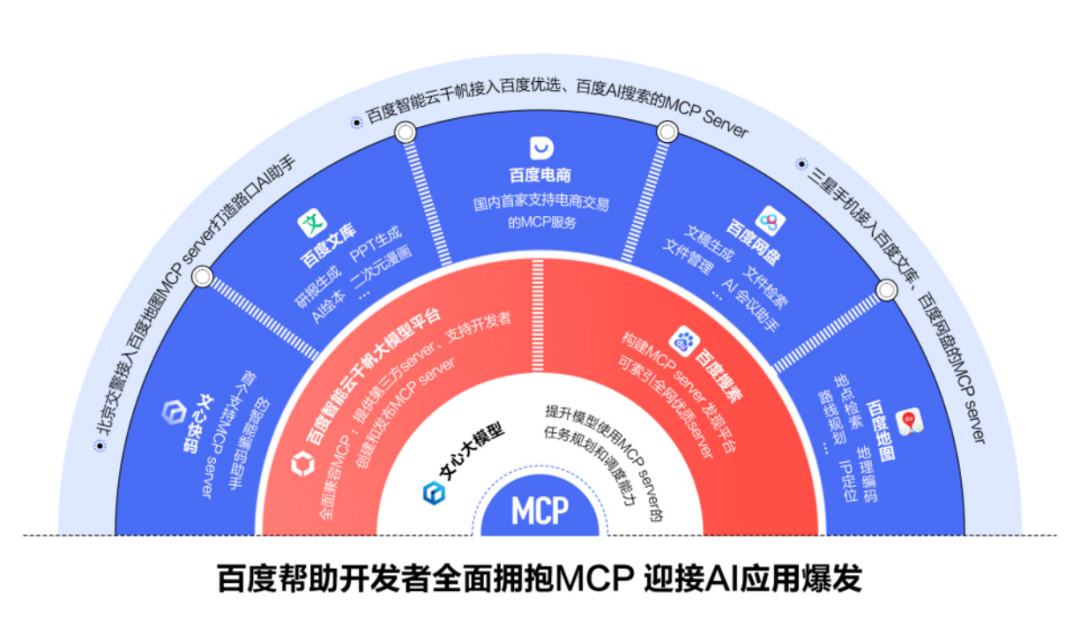
百度搜索还构建了MCP server发现平台,李彦宏表示,百度将帮助开发者全面拥抱MCP,并现场演示了千帆、搜索、电商、网盘等产品接入MCP的实际案例等。
百度首席技术官王海峰在会上对4.5 Turbo及X1 Turbo两大模型幕后的技术创新进行了分析,分享了百度在基础模型、后训练、深度思考和数据等方面做出的努力。
针对不同模态数据在结构、规模、知识密度上的差异,百度团队通过多模态异构专家建模、自适应分辨率视觉编码、时空重排列的三维旋转位置编码、自适应模态感知损失计算等技术,大幅提升跨模态学习效率和多模态融合效果,学习效率提高近2倍,多模态理解效果提升超过30%。
后训练方面,百度研制了自反馈增强的技术框架,基于大模型自身的生成和评估反馈能力,实现了“训练–生成–反馈–增强”的模型迭代闭环。
在训练阶段,研制了融合偏好学习的强化学习技术,通过多元统一奖励机制,提升了对结果质量判别的准确率,通过离线偏好学习和在线强化学习统一优化,进一步提升了数据利用效率和训练稳定性,并增强了模型对高质量结果的感知。
深度思考方面,突破了仅基于思维链优化的范式,在思考路径中结合工具调用,构建了融合思考和行动的复合思维链,模型解决问题能力得到显著提升。
数据方面,打造了“数据挖掘与合成 – 数据分析与评估– 模型能力反馈”的数据建设闭环,为模型训练源源不断地生产知识密度高、类型多样、领域覆盖广的大规模数据。
基于文心大模型的语言和代码能力,百度研制了代码智能体和智能代码助手——文心快码,目前已升级到3.5版本。

此外,百度的AI技术底座飞桨文心联合优化让文心4.5 Turbo训练吞吐达到文心4.5的5.4倍,推理吞吐达到8倍。飞桨框架3.0在自动并行、神经网络编译器、高阶自动微分等方面取得了不少创新突破,使得大模型分布式训练代码减少80%,帮助强化学习训练提速114%,模型端到端训练速度提升27%,并且支持适配国内外60多个系列芯片。截至目前,飞桨文心开发者数量超过2185万。
AI算力是当下行业最关心的话题之一,百度集团执行副总裁、百度智能云事业群总裁沈抖分享了百度在智能基础设施建设方面的进展。
沈抖表示,系统的价值,不仅是解决某一个问题,而是让企业拥有创造“创造的能力”,企业可以结合自己的数据、流程、逻辑,利用百度智能云的系统级能力打造企业专属AI基础设施。

百度智能云通过自研昆仑芯P800芯片及百舸大规模推理加速能力,可兼顾算力性能与成本。
本次大会上,百度正式点亮了昆仑芯P800的三万卡集群。据悉,昆仑芯P800算力已在国家电网、中国钢研等央企,同济大学、北京大学等高校及一批互联网企业进行规模化部署。
为了进一步降低算力使用成本,百度智能云正式发布昆仑芯超节点。

昆仑芯超节点支持把64张昆仑芯AI加速卡放到同一个机柜,实现单节点的超强性能,一个机柜就能顶过去100台机器。与以往的方案相比,昆仑芯超节点用更快的机内通信替代机间通信,可以有效降低带宽成本,最终实现卡间互联带宽提升8倍,单机训练性能提升10倍,单卡推理性能提升13倍。
在硬件之上,百度智能云还全面升级了百舸推理加速能力,可以大幅降低MOE模型推理的通信开销,提升GPU的有效利用率。
在应用开发上,百度智能云千帆平台升级了企业级Agent开发工具链,发布了全新推理式智能体——智能体Pro。
基于千帆Agentic RAG能力,企业可以让Agent结合企业自己的私域数据和企业知识库,可以基于对任务的理解去制定检索策略,大幅降低模型幻觉。同时,智能体Pro也支持Deep Research深度研究模式,能让Agent自主完成复杂任务的步骤规划、信息筛选和整理,结构清晰、内容丰富的专业报告。
百度智能云还发布了国内首个企业级MCP服务,据悉,第一批已经有超过1000个MCP Servers供企业及开发者灵活选择。
整体来看,在当下的AI市场竞跑中,单论技术层面,百度从AI算力、平台到应用的系统级能力具备非常强的竞争力,比较大的考验在于能否把技术优势很好地转化成商业成果,这对ALL in AI的百度来说非常关键。

(文:头部科技)