

新智元报道
新智元报道
【新智元导读】全球首个去中心化强化学习训练的32B模型震撼发布!无需授权,就能用自家异构计算资源参与其中,让编码、数学与科学领域的推理性能迈向新高度。
最近,全球第一个用去中心化强化学习训练的32B模型——INTELLECT-2正式发布!
任何人都能用自己的异构计算资源参与,无需授权。
这种全新的范式,让去中心化训练在编码、数学和科学领域,迈向前沿的推理性能。

INTELLECT-2是大规模去中心化强化学习的开端,他们的下一步计划是用强化学习训练端到端智能体。
去中心化强化学习正处于起步阶段,若能汇聚社区和各方贡献,开源AI有望超越闭源实验室。
AI社区对这项工作给出了非常积极的肯定。
随着OpenAI o1和DeepSeek R1的发布,出现了预训练以外的扩展范式,借助RL进行优化,让模型有更多时间进行推理。
之前发布的成果曾探讨,为何通过RL训练的推理模型,相比标准的LLM预训练,更适合去中心化训练。
INTELLECT-2将有力地证实这一观点。


过去一年,研究者致力于构建所有关键的开源组件,让INTELLECT-2具备前沿的推理性能,支持异构计算节点,并允许无需授权的贡献,能对32B参数模型进行去中心化RL训练:
-
prime-RL:新推出的开源库,用于完全异步的去中心化RL,基于具备容错的去中心化训练框架prime开发。
-
SYNTHETIC-1 & GENESYS:用于RL任务众包和验证环境的库。
-
TOPLOC:实现高效、可验证的推理方法,用于验证INTELLECT-2中所有去中心化rollout节点的计算。
-
协议测试网:提供基础设施和经济激励,用于聚合和协调全球计算资源,打造真正自主的开源AI生态系统。
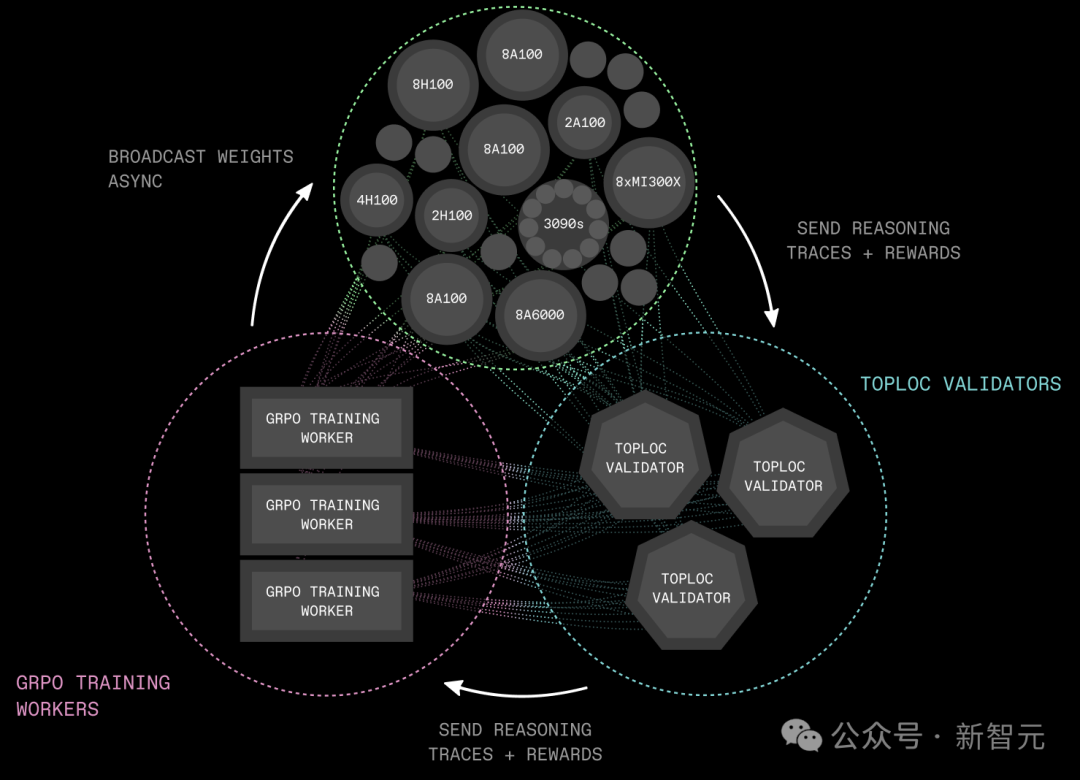
INTELLECT-2基础设施主要由三个组件构成:
-
推理采样节点(Inference Rollout Workers):一组去中心化节点,用最新的策略模型,从环境中收集推理轨迹(reasoning rollouts),并计算相应的奖励。
-
TOPLOC验证节点(TOPLOC Validators):负责高效验证无需授权的rollout工作节点的推理计算,打造无需信任的系统。
-
GRPO训练节点(GRPO Training Workers):从去中心化推理采样节点收集到新生成的数据后,采用DeepSeek的GRPO训练方法进行训练。训练完成后,这些训练节点会通过Shardcast库,将更新后的权重广播给所有推理节点,以启动下一轮数据收集。
该基础设施具备以下特性:
-
完全消除通信开销:通过异步强化学习,新策略模型的广播与正在进行的推理和训练完全重叠,通信不再成为瓶颈。
-
支持异构推理节点:允许任何人按自己的节奏生成推理轨迹(reasoning traces),跨节点处理速度没有统一要求。
-
资源需求低:在这种训练设置中,占计算资源大头的推理节点可以在消费级GPU上运行。例如,配备4块RTX 3090 GPU的机器,足以支持32B参数模型的训练。
-
实现高效验证:推理计算的验证过程,不会引入训练瓶颈。

RL在本质上比传统的LLM预训练更具异步性。在去中心化RL中,数据收集和网络训练可以分开进行。
多个节点在并行环境中运行,各自异步收集经验数据,中央学习器负责接收和处理这些数据。
由于经验数据到达的时间不同,且来自状态空间的不同部分,每个步骤的发生速率也有所不同。
异步强化学习在Tulu 3和Llama 4中得到了成功应用,采用单步异步强化学习方法,提升了训练效率。
消融实验表明,即使采用四步异步训练(即推理节点使用的策略模型落后四步),也能复现DeepScaleR的结果,且不会降低模型性能。
这样的异步程度,在去中心化RL训练中,即使全局互联较弱,也能将通信时间完全隐藏在计算过程中。
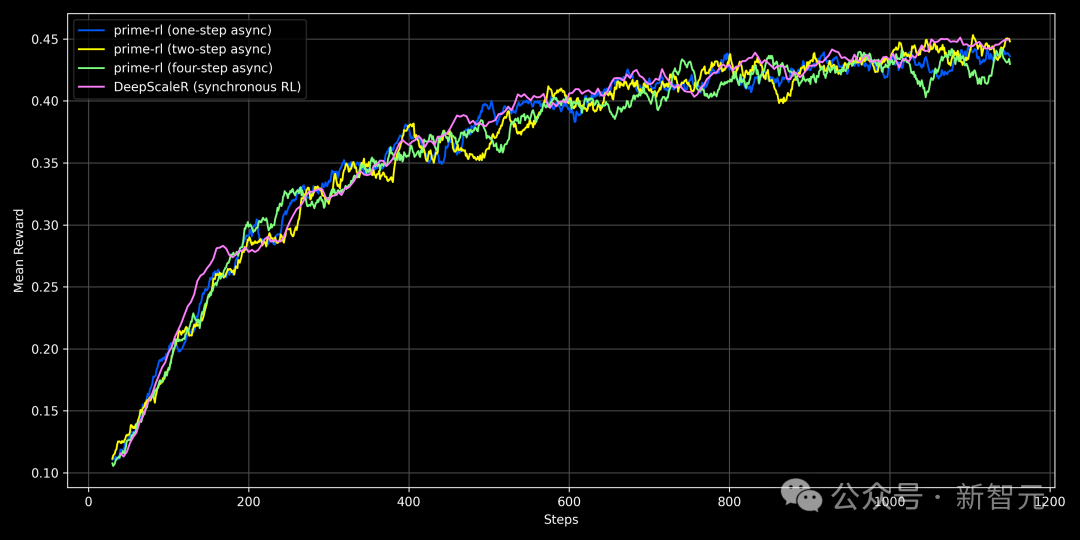
同步DeepScaleR训练与异步Prime-RL的比较:即使延迟增加(最多四步),Prime-RL的性能仍能与同步基线媲美
此外,异步强化学习不仅实现了去中心化训练设置,还通过分别优化训练和推理引擎,进一步提高了效率。
例如,在prime-rl库中,rollout节点可以利用vLLM,及全套推理优化技术。
完全异步的在线RL训练框架prime-rl已开源,任何人都能借此开启全球去中心化RL训练。
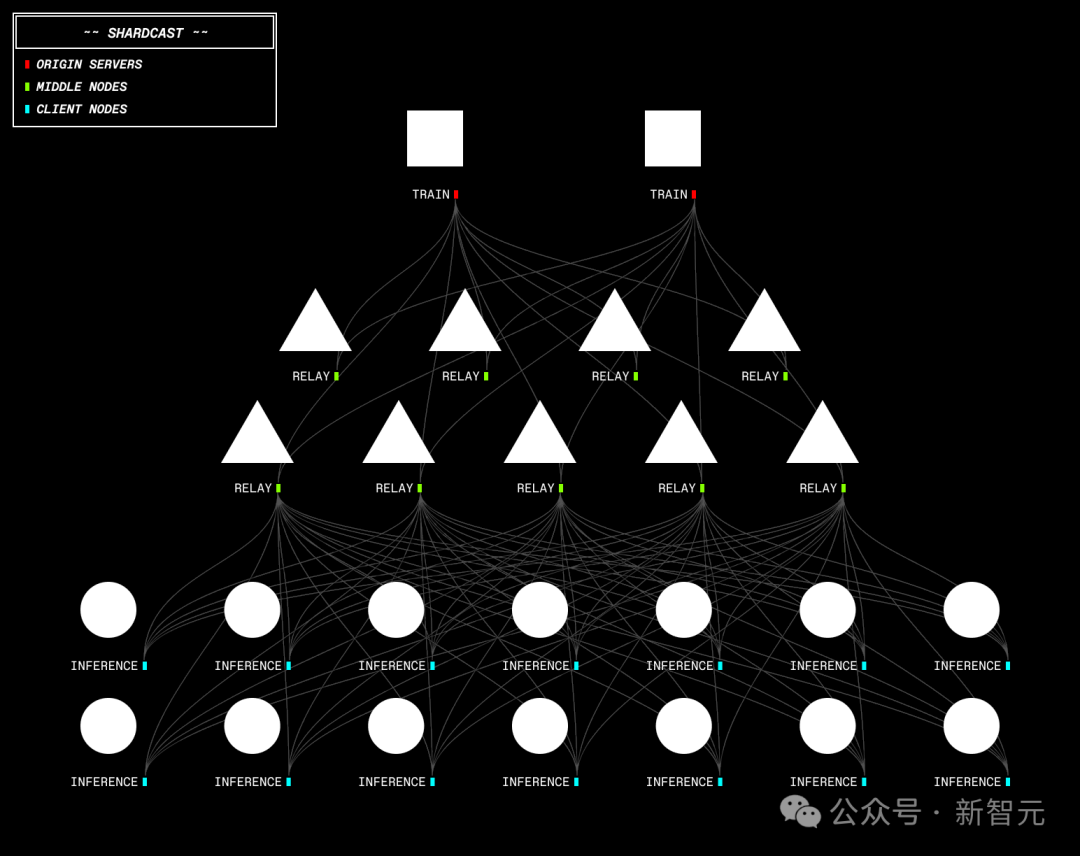
基础设施中的一个关键组件,Shardcast是能尽快将新策略模型从训练节点广播到所有去中心化推理节点的机制。
Shardcast是一个通过基于HTTP的树状拓扑网络分发大型文件的库,由以下部分组成:
-
源服务器(Origin Server):作为根节点,将大文件分片,并通过HTTP提供分片服务。
-
中间节点(Middle Nodes):作为中间服务器,从上游服务器下载分片,并以流水线方式转发。
-
客户端节点(Client Nodes):下载分片并重新组装成原始文件。
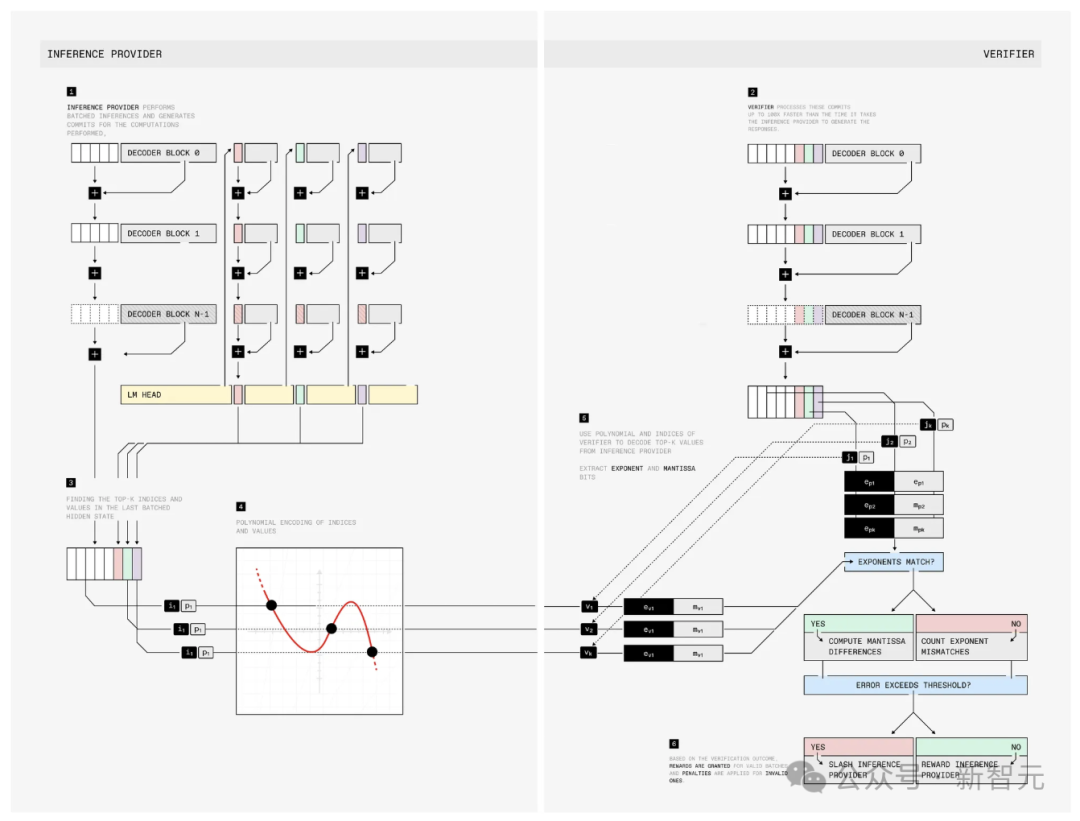
TOPLOC是一种用于可验证推理的局部敏感哈希方案,旨在检测推理过程中的恶意修改。
它能实现以下功能:
-
检测推理过程中对模型、提示或精度的修改。
-
有效应对GPU硬件的不确定性,这是可验证计算中的主要挑战之一。TOPLOC在不同类型的GPU、张量并行配置和注意力内核上都能可靠运行。
-
验证速度比生成速度快得多。
在INTELLECT-2中对TOPLOC进行生产环境测试,任何人都能以无需授权的方式贡献GPU资源。
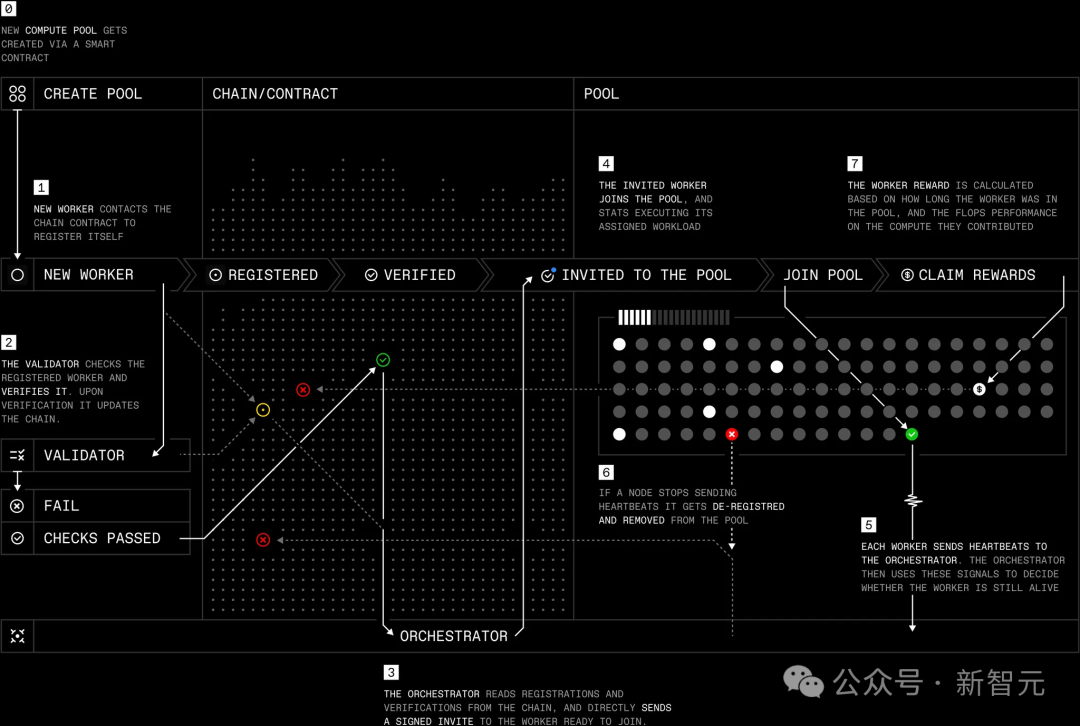
几周前,团队宣布了公共协议测试网的启动,旨在实现真正自主的开源AI生态系统。
今天,首个无需授权的计算池开放,任何人都能在自己的GPU上运行协议测试网节点。
注册、计算资源验证、对恶意行为的惩罚等操作,都在公共以太坊Base测试网上完成。这带来了诸多好处:
-
全球规模的计算资源聚合:节点设计允许任何人在全球任何计算设备上运行,加入去中心化网络,并最终因节点所做的贡献获得奖励。这有助于扩展规模,无授权地整合来自全球的数据中心资源。
-
为完全去中心化训练奠定基础:所有加入计算池的节点都以点对点(peer-to-peer)的方式进行通信和协调。这为完全去中心化、无授权地训练和微调开源模型奠定了基础,对构建真正自主的开源AI生态系统至关重要。
除了对基础设施进行多项改进,在协议层面也有其他关键进展。
-
检测和防范攻击与欺诈的机制:将TOPLOC验证集成到节点中,实现高效验证,有助于识别伪造GPU或污染数据集的行为。
-
鼓励诚实行为的激励:为减少不诚信行为,尝试采用经济激励,抑制伪造GPU或提交虚假数据等恶意行为。具体做法是要求节点预先抵押一定的资金,如果节点被认定存在不诚信行为,这些抵押资金将被扣除。
此外,团队为节点的工作设定了24小时的验证期,期间若发现问题,节点工作将被判定无效并扣除相应奖励。如果节点出现恶意行为或试图钻机制的空子,最多会扣除24小时的奖励。
INTELLECT-2的目标是训练出一个具有可控思考预算的前沿推理模型。
用户和开发者可通过系统提示词,指定模型在得出最终解决方案前,对一个问题应思考的token数量。
这种方法能让训练出的模型在实际应用中更加高效。
近期的研究(如ThinkPrune、L1和Deepscaler)表明,经过专门训练、在严格约束下进行推理训练的模型,几乎能解决所有无约束推理模型可解决的问题,且速度更快,推理成本也更降低。
通过提示控制推理预算,用户既能利用这一优势,又能在遇到极具挑战性的问题时,选择更长的推理时间。
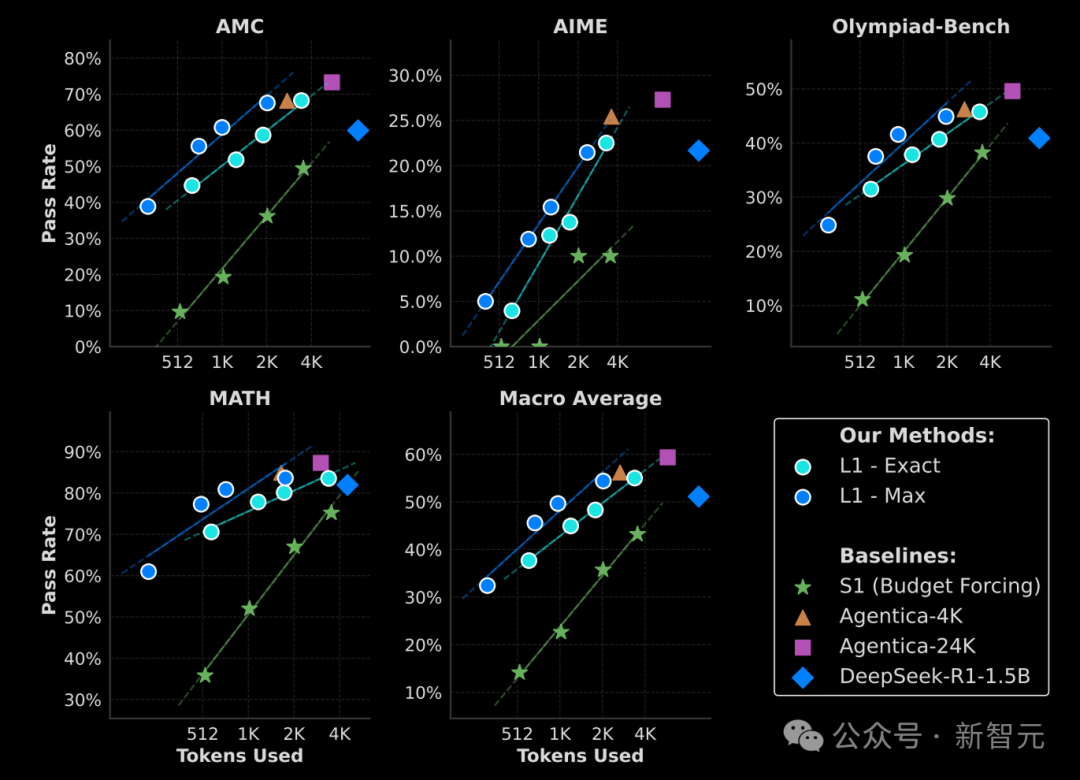
「L1:利用RL控制推理模型的思考时长」的研究结果表明,推理模型可以被训练来遵循其提示词中指定的token数量,且模型性能会随推理预算的增加而可预测地提升;团队用自研框架prime-rl独立复现了论文结果
为训练出这样的模型,团队以QwQ-32B为基模型,遵循Deepseek-R1的方法,应用GRPO算法,结合数学和编程领域的可验证奖励。
在初步实验中,以下几个部分对控制模型思考预算、提升模型性能起到了重要作用:
除了根据输出的正确性给予任务奖励外,还引入了长度奖励,以引导模型遵循提示词中指定的思维预算。
团队参考了L1的研究思路,从指定范围内采样目标长度,将其加入提示词,根据目标长度与实际响应长度的差异来分配奖励。
与L1不同,团队没有从一个连续的值范围中采样目标长度,而是从一小组预定义的值中采样,更有利于模型学习。
通过长度控制进行训练,不仅让模型更实用,还能更高效地利用异构推理硬件。
对于每个rollout过程,为GPU显存和算力较低的推理节点分配较小的思考预算,为计算能力更强的节点分配较大的思考预算。
这样,可以在较慢的节点设置较低的最大生成长度,从而在使用异构硬件时,各个rollout的处理时间基本一致。
实验中发现仔细筛选数据对模型性能至关重要。
用原始的Deepscaler数据集和方法训练DeepSeek-R1-Distill-Qwen-7B模型时,模型性能并未提升。
对数据难度进行严格筛选,只保留模型无法100%正确解答的问题。训练过程中的奖励增加,最终模型在数学基准测试中的表现也有提高。
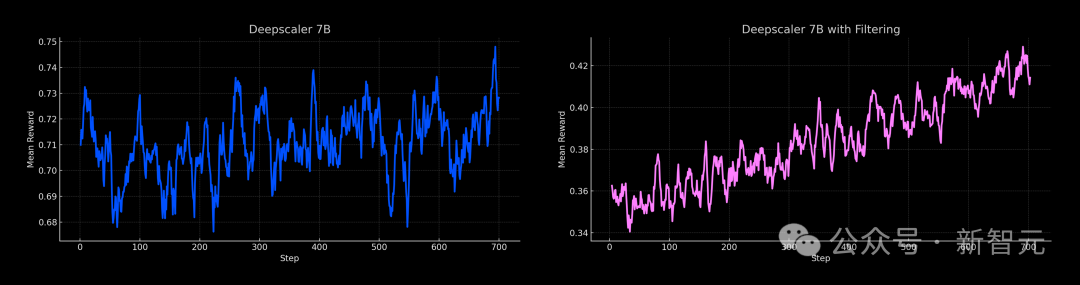
在Deepscaler数据集的未过滤版本(左)和经难度过滤版本(右)上训练DeepSeek-R1-Distill-Qwen-7B的奖励轨迹
为筛选INTELLECT-2的训练数据集,用DeepSeek-R1-Distill-Qwen-7B对所有问题进行8次采样,以评估问题的难度。为确保训练集中只保留具有挑战性的问题,仅采用解答率为75%及以下的问题。
在线优势过滤:训练过程中,如果所有完成结果都获得相同的奖励,这些问题就不会产生训练信号,因为其优势值(以及相应的损失)为零。
团队会过滤掉这些问题,继续进行推理,直到获得一整批具有非零优势的问题。
这提高了训练效率,避免在无意义的样本上浪费计算资源。此外,这意味着推理所需时间多于训练,因此非常适合用去中心化推理节点。
对于INTELLECT-2,团队主要关注可验证的数学和编程问题,从SYNTHETIC-1中选取了经过严格质量和难度筛选的任务子集。
完整的训练数据集可在Hugging Face上获取。
数据集地址:https://huggingface.co/datasets/PrimeIntellect/Intellect-2-RL-Dataset
INTELLECT-2是首个真正意义上允许任何人用自己的计算资源参与的项目。
由于大家的热情极高,计算池的容量早早就已经满了。
现在想要贡献算力,还得提申请排队才行。
当然,并不是随便什么算力他们都接受——
-
GPU必须是A100(80GB),H100(80GB),H200(141GB)
-
算力节点需要是4卡或者8卡为一组


训练进度和算力贡献情况长这样:

仪表盘:https://app.primeintellect.ai/intelligence
总结来看,INTELLECT-2的发布是大规模去中心化强化学习的开端。
基础架构现已搭建完毕,接下来需要共同努力,将其扩展到更具影响力的应用领域。
(文:新智元)