

大模型圈又要热闹了!
就在刚刚,阿里云正式发布了 Qwen(通义千问)系列大模型的最新成员 —— Qwen3。这次发布包含了 8 个不同规模的模型,其中最大的模型有 235B 参数。

重磅升级,对标顶级模型
Qwen3 的旗舰模型是 Qwen3-235B-A22B。这个模型在代码、数学和通用能力等方面的测试中,已经可以和 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等顶级模型一较高下。
Qwen3 系列包括:
-
2 个 MoE 模型:Qwen3-235B-A22B 和 Qwen3-30B-A3B

-
6 个标准模型:从 0.6B 到 32B 不等

亮点一:双模式思考能力
Qwen3 最大的创新是支持两种思考模式:
-
思考模式:模型会一步步推理,适合复杂问题。比如做数学题时,模型会像人类一样先分析问题,再逐步解答。
-
快速模式:模型直接给出答案,适合简单问题。比如问候、闲聊这类问题,模型会立即回应。
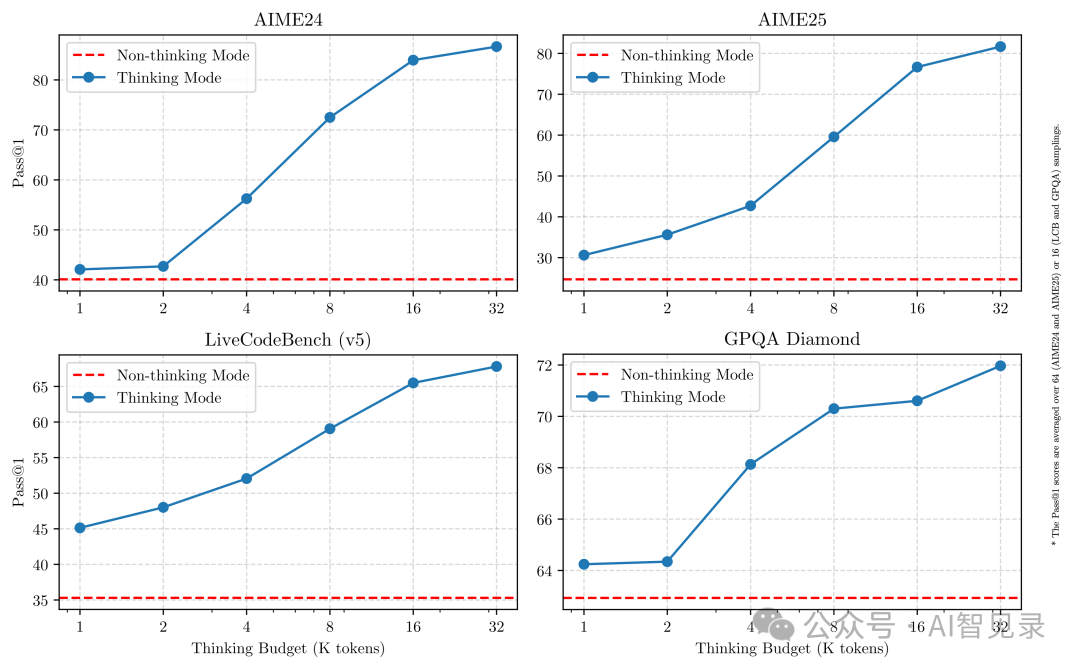
用户可以根据需要切换这两种模式。测试数据显示,在思考模式下,模型在 AIME(美国数学邀请赛)和 GPQA(通用问答)等任务上的表现会随着思考时间的增加而提升。
亮点二:超大规模预训练
Qwen3 的训练数据比上一代翻了一倍多:
-
Qwen2.5:18 万亿 token -
Qwen3:36 万亿 token
训练数据来源广泛:
-
网络文本 -
PDF 文档 -
教科书 -
代码库 -
数学题库 -
多语言语料
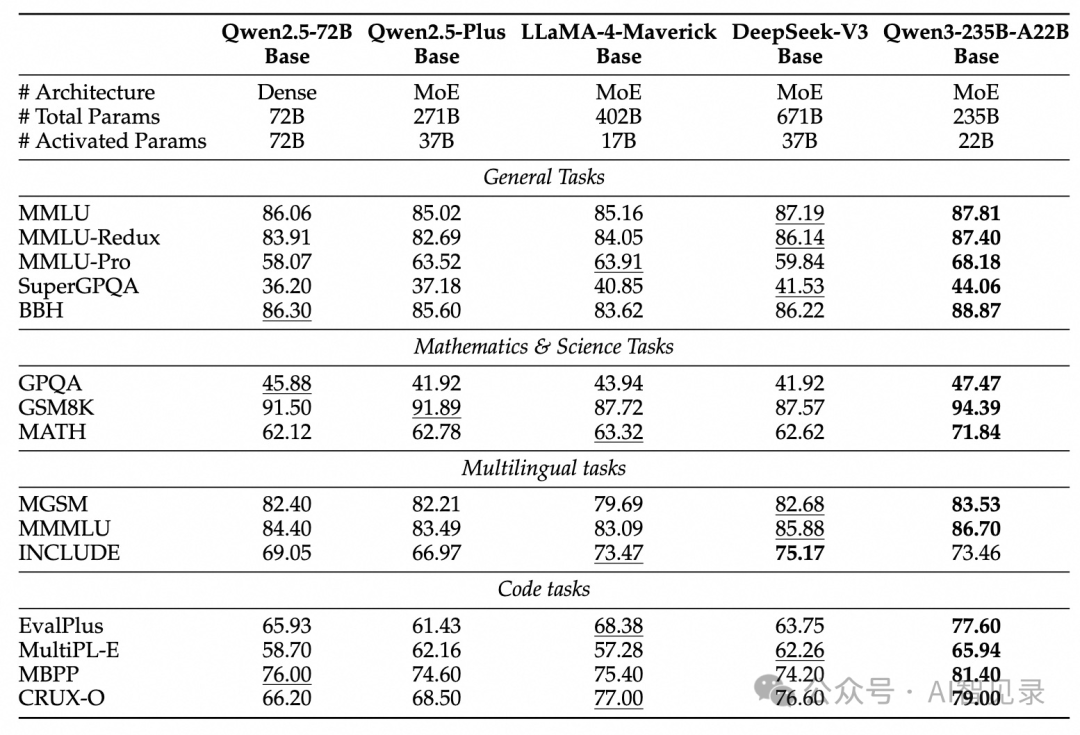
训练过程分三步:
-
基础训练:用 30 万亿 token 训练基础语言能力 -
专业训练:加入 5 万亿专业领域数据(STEM、编程等) -
长文本训练:把上下文长度扩展到 32K token
亮点三:创新的后训练方法
Qwen3 采用了四阶段后训练流程:
-
长文本冷启动:帮助模型适应长文本输入 -
推理强化学习:提升模型的推理能力 -
思维模式融合:把快速反应和深度思考能力结合 -
通用强化学习:在 20 多个领域进行能力训练

对于轻量级模型(如 Qwen3-4B/8B/14B),还使用了知识蒸馏技术,把大模型的能力传授给小模型。
亮点四:性能大幅提升
小模型也有大能力!Qwen3 的小型 MoE 模型 Qwen3-30B-A3B 只用了 QwQ-32B 十分之一的参数量,就取得了更好的效果。
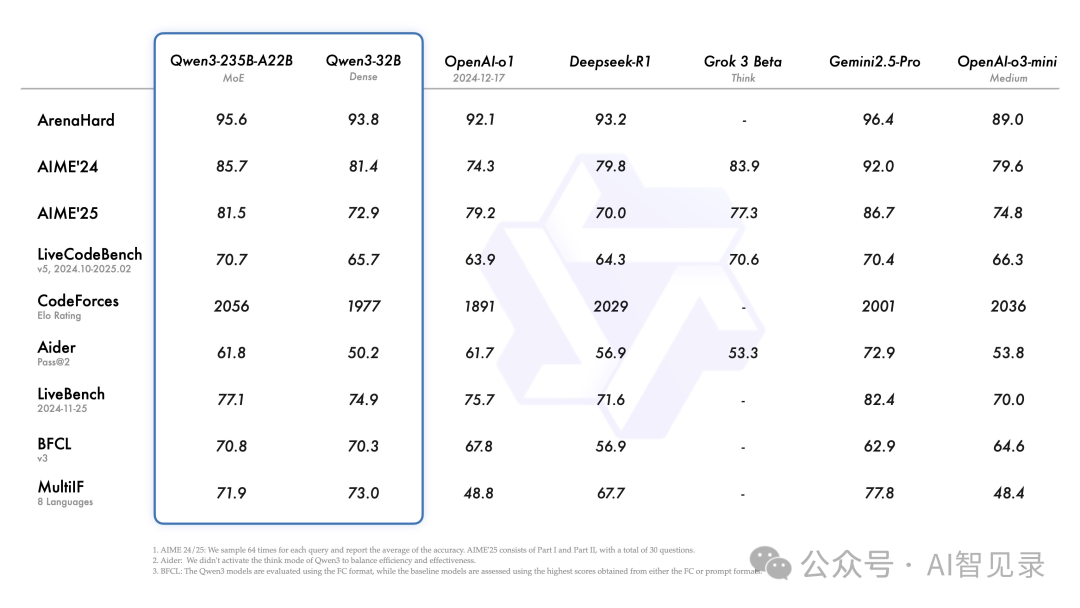
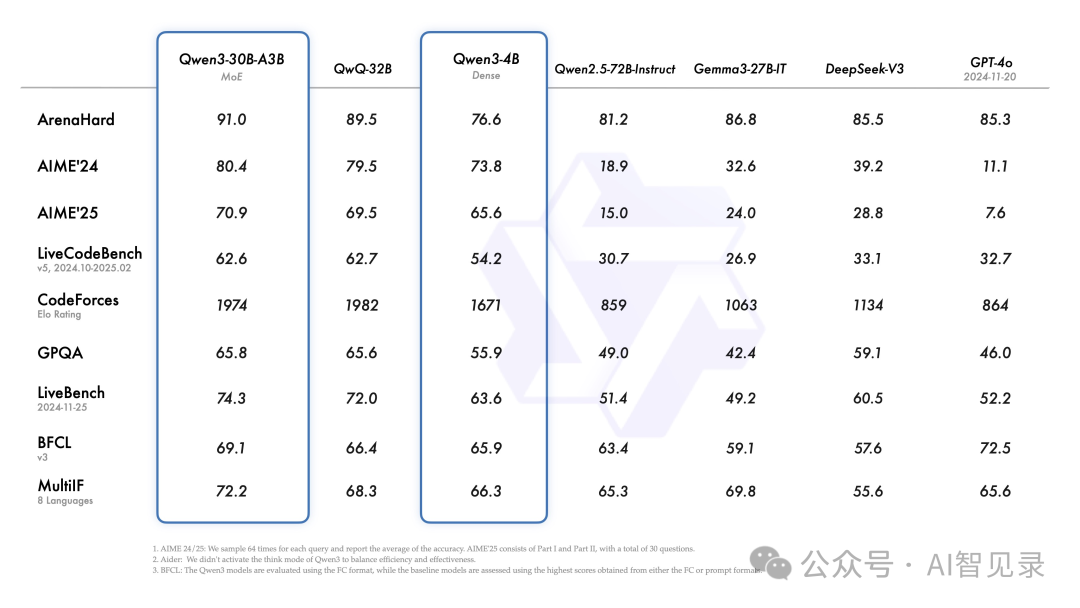
就连最小的 Qwen3-4B 模型,也能达到 Qwen2.5-72B-Instruct 的水平。
亮点五:开箱即用
Qwen3 现在已经登陆各大平台:
-
Hugging Face -
ModelScope -
Kaggle
开发者可以用多种方式部署 Qwen3:
-
云端部署:用 SGLang 和 vLLM -
本地部署:用 Ollama、LMStudio、MLX、llama.cpp 等工具
访问 https://chat.qwen.ai/ 在线体验。也可以在 App 上进行体验。

亮点六:多语言支持
Qwen3 支持 119 种语言,这让它可以服务全球用户。不管是中文、英文,还是小语种,Qwen3 都能应对自如。

大模型竞争加剧
就在 Qwen3 发布前,业内有爆料传出 DeepSeek R2 即将发布的消息。据说这个模型有这些特点:
-
1.2T 参数,78B 激活参数 -
比 GPT-4 便宜 97.3% -
5.2PB 训练数据 -
视觉能力强,COCO 测试达到 92.4% -
在华为 Ascend 910B 上利用率达到 82%
未来展望
大模型领域的竞争正在加剧。Qwen3 的发布表明:
-
中国大模型技术正在快速追赶 -
模型性能和效率都有明显提升 -
开源生态越来越完善
这个五一假期,大模型圈注定不会平静。让我们拭目以待更多精彩的发展!
参考
-
https://x.com/Alibaba_Qwen/status/1916962087676612998 -
https://github.com/QwenLM/Qwen3 -
https://huggingface.co/collections/Qwen/qwen3-67dd247413f0e2e4f653967f
(文:AI智见录)