
今天是2025年4月29日,星期一,赣州,晴。
Qwen3发布是今天大模型开源界的一个大新闻,之前大家在纠结R1过度思考等问题,做了许多工程化改造,但是Qwen3模型一更新,在这个技术洪流之下,又再次冲刷了之前的一些改造,实属又是一个“做不如等”的真实些写照了。这其实也是大模型时代下的魅力所在了。我们来看看里面提到的思考模式。
另一个,关于推理大模型,我们已经有了许多解读文章积累,我们做个专题指引,感兴趣的可以看看。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、从Qwen3再看混合思考模式
Qwen3发布,技术报告在:https://qwenlm.github.io/blog/qwen3/,modelscope模型在https://modelscope.cn/collections/Qwen3-9743180bdc6b48,github项目地址在:https://github.com/QwenLM/Qwen3,体验地址在:https://chat.qwen.ai
有两个特点,一个是MoE和非MoE。 MoE模型有Qwen3-235B-A22B(MoE,总大小235B,激活参数22B,上下文128K),Qwen3-30B-A3B(MoE,总大小30B,激活参数3B,上下文128K)。
Dense模型有Qwen3-32B,Qwen3-14B,Qwen3-8B,Qwen3-4B,Qwen3-1.7B,Qwen3-0.6B。
另一个是思考模式,推出了两个跟claude相似的思考开关。关于这块,我们在文章《近期RAG误区再认识及Claude3.7的混合模型推理机制解析》(https://mp.weixin.qq.com/s/dufuxz5_tLwMx0Zx1E9wIA),还是在2月份出来。
第一个问题,什么是混合推理模式。参见https://aws.amazon.com/cn/blogs/aws/anthropics-claude-3-7-sonnet-the-first-hybrid-reasoning-model-is-now-available-in-amazon-bedrock/,这个工作Claude3.7Sonnet采用了不同的模型思维方式。Claude3.7Sonnet不使用单独的模型(一个用于快速回答,另一个用于解决复杂问题),而是将推理作为核心功能集成到一个模型中。
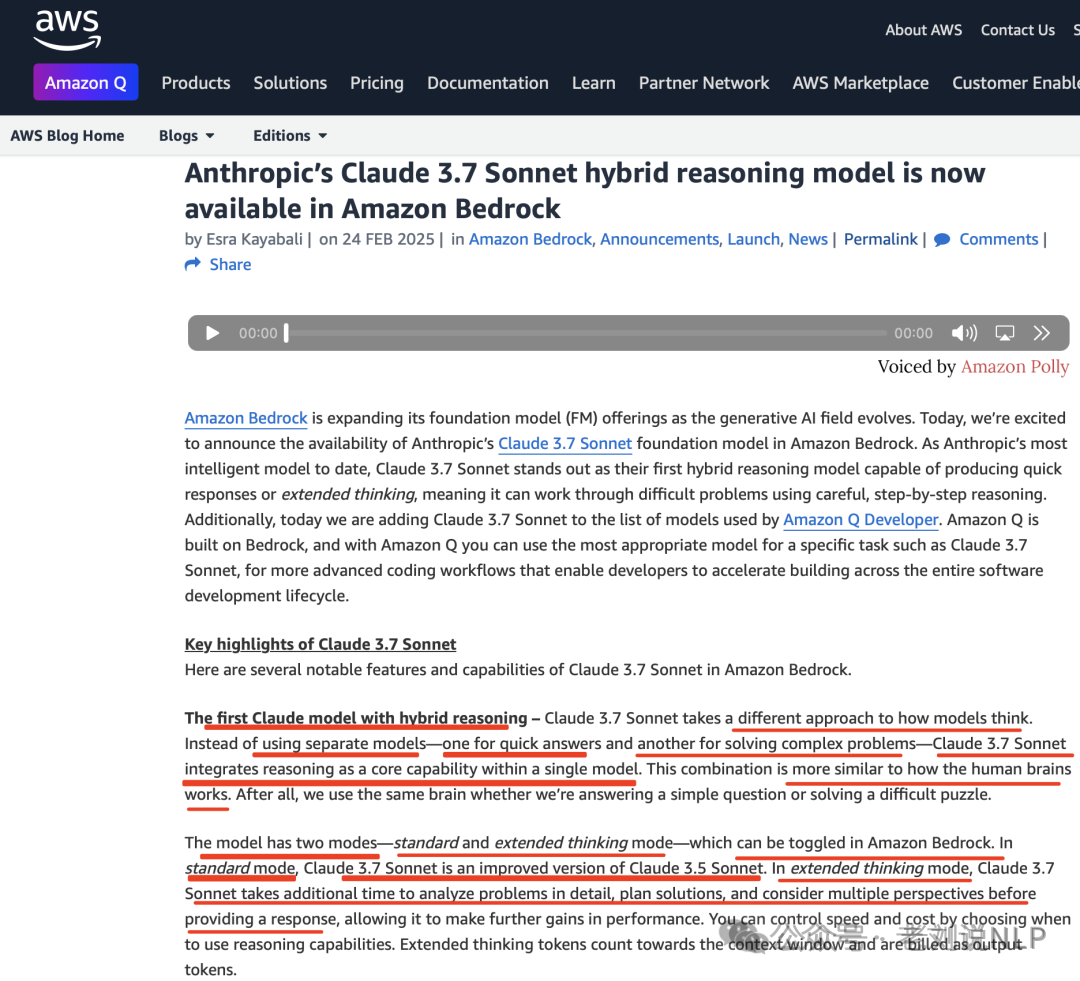
有两种模式-标准模式和扩展思维模式-可在AmazonBedrock中切换。
在标准模式下,Claude3.7Sonnet是Claude3.5Sonnet的改进版本。在扩展思维模式下,Claude3.7Sonnet需要更多时间详细分析问题、规划解决方案并考虑多个角度,然后再提供响应,从而进一步提高性能。您可以通过选择何时使用推理功能来控制速度和成本。扩展思维标记计入上下文窗口并作为输出标记计费。可以从官网:https://docs.anthropic.com/en/docs/build-with-claude/extended-thinking中找到使用说明。使用方式:
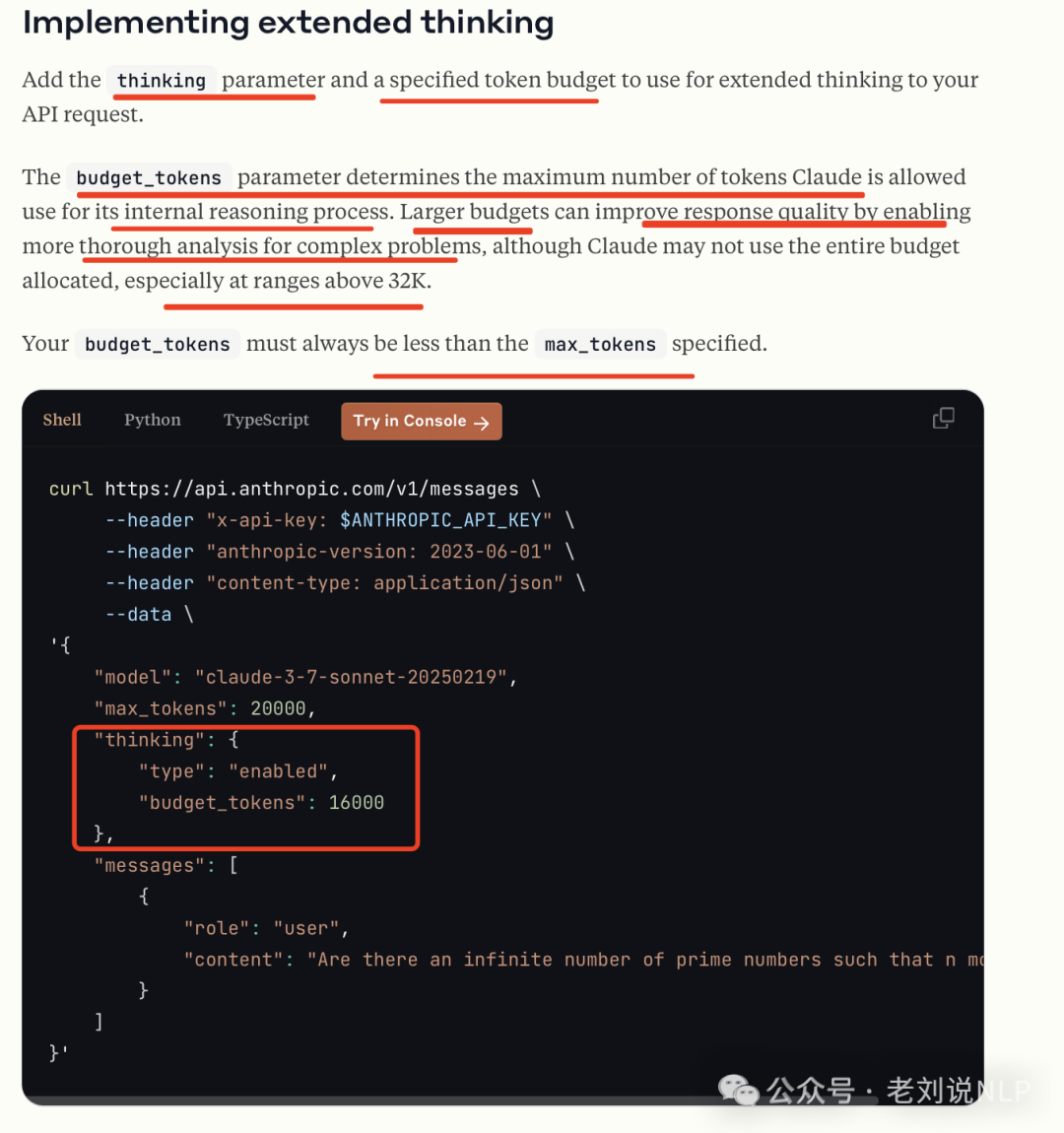
返回结果:

第二个问题,实现机制猜想?
所以,我们顺道来分析下这个机制,两个。一个是控制是否thinking,一个是thinking多久。思路可以猜想下,可能使用了特殊的token,在提示词最后加上这个token,模型就会开始推理模式回答,没有这个token,按旧有方式回答。
然后工程上进行 API 包装。限制长度的部分应该也只是工程上的处理,程序会观察输出内容是否超过budget,超过了就强行插入终止思考。
那么,问题来了,这个其实还是依赖于大模型自身的能力,大家要想的是,假设这是微调或者强化出来的结果,这个是如何微调的,但claude这种,似乎验证了可以通过微调来实现这种效果,路线可行? 首先是是否触发思考的问题。
既然有开关,那么在训练数据侧就应该会有一个token,标记出是否要thinking。如果有限制token,那么是否构造训练数据时,也会将这类限制写入到input 当中,大家感兴趣的,可以去做做实验。如果使用特殊token做开关的话,这样训练时可以分开训练,模型可以同时拥有两种甚至多种能力。互相之间不会干扰。
当然,如果将”
进一步想,如果Claude 3.7 采用的是s1同样的方法,也就是不会插入”wait”启发继续思考,而是插入””来提前结束思考。关于s1,可可以看看:https://mp.weixin.qq.com/s/r8yoXRMWnoh_rUbHjzjEsQ,以及工作
**S1《s1: Simple test-time scaling》(https://arxiv.org/pdf/2501.19393,https://github.com/simplescaling/s1)**,提到多种预算控制方案。

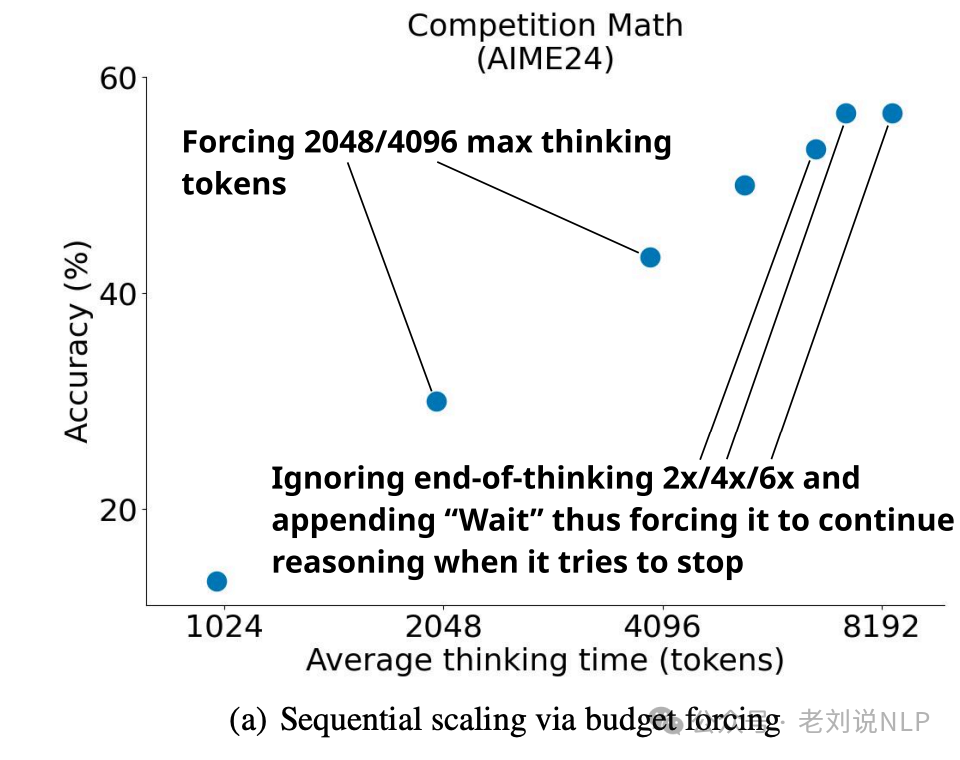
一种是条件长度控制方案,依赖于在提示中告诉模型它应该生成多长时间。例如可以执行多种粒度的控制,如token-条件控制,在提示中指定思考token的上限;
一种是步骤条件控制,指定思考步骤的上限,其中每个步骤大约为100个tokens;
一种是类-条件控制,编写两个通用提示,告诉模型思考一小段时间或很长一段时间。
相类似的,Qwen3也提供混合思维模式,搭载了thinking开关,可以直接手动控制要不要开启thinking。
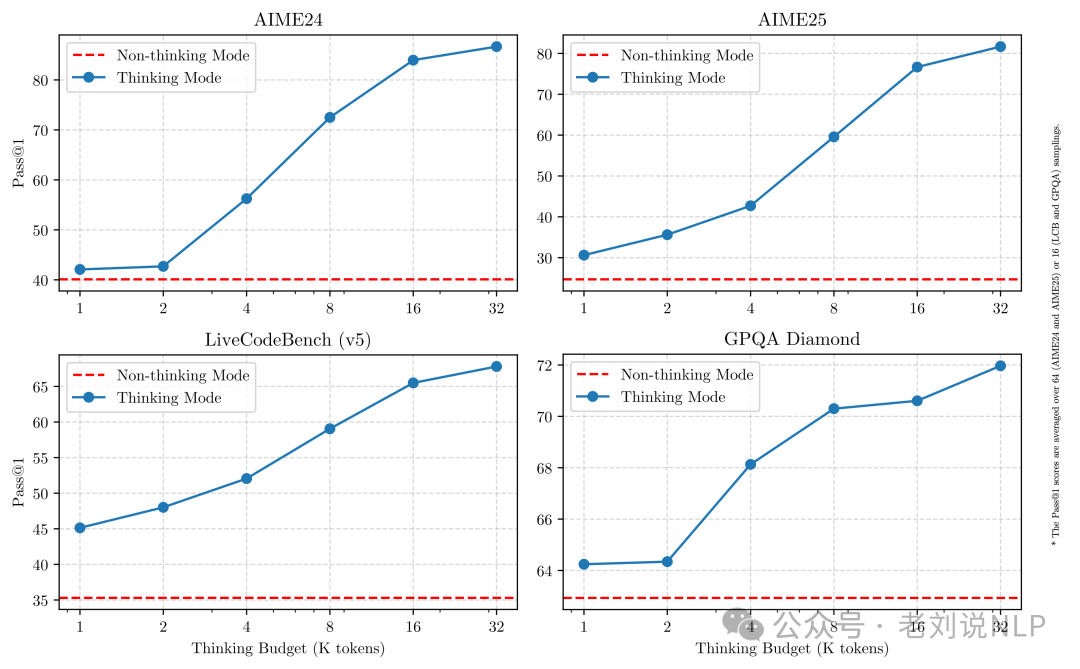
其中,思考模式模式下,模型会逐步推理,经过深思熟虑后给出最终答案,这种方法非常适合需要深入思考的复杂问题。
在非思考模式中,模型提供快速、近乎即时的响应,适用于那些对速度要求高于深度的简单问题。
使用方式有两种。
一种是基础用法,推荐使用SGLang和vLLM 等框架;而对于本地使用,像Ollama、LMStudio、MLX、llama.cpp 和 KTransformers 这样的工具也非常值得推荐。


一种是高级用法,允许用户在enable_thinking=True时动态控制模型的行为。具体来说,可以在用户提示或系统消息中添加 /think 和 /no_think 来逐轮切换模型的思考模式。在多轮对话中,模型会遵循最近的指令。
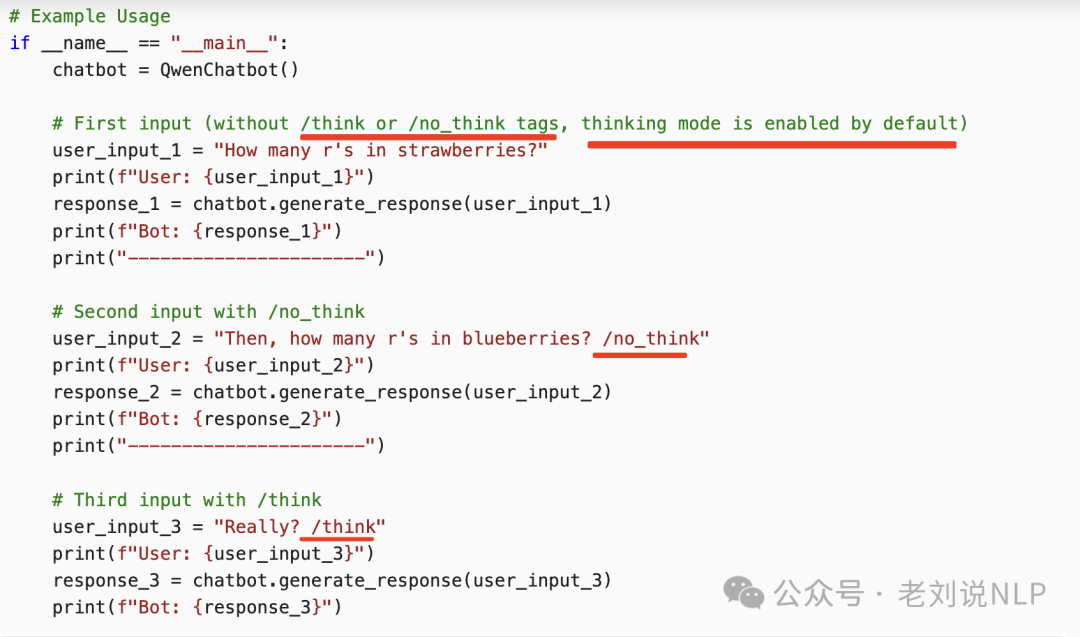
2、训练方式
实施了一个四阶段的训练流程,包括(1)长思维链冷启动,(2)长思维链强化学习,(3)思维模式融合,以及(4)通用强化学习。
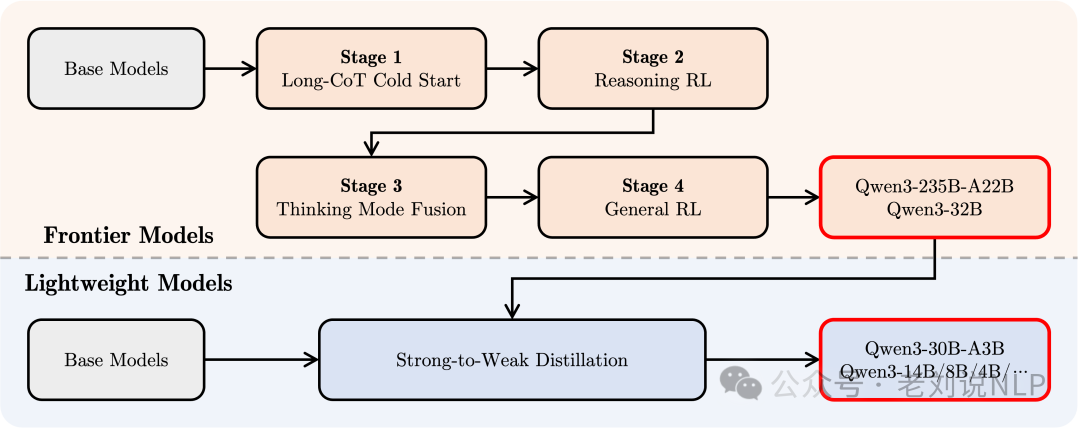
在第一阶段,使用多样的的长思维链数据对模型进行了微调,涵盖了数学、代码、逻辑推理和STEM问题等多种任务和领域,旨在为模型配备基本的推理能力。
第二阶段的是大规模强化学习,利用基于规则的奖励来增强模型的探索和钻研能力。
在第三阶段,在一份包括长思维链数据和常用的指令微调数据的组合数据上对模型进行微调,将非思考模式整合到思考模型中,所以这验证了通过微调进行处理的做法。
最后,在第四阶段,在包括指令遵循、格式遵循和Agent能力等在内的20多个通用领域的任务上应用了强化学习,以进一步增强模型的通用能力并纠正不良行为。
二、推理大模型专题指引
推理大模型的工作越来越多,但已经进入了一个新的阶段,从O1、R1出来之后,先后在多模态领域、垂直领域两个角度做了许多变体应哟个,并且从推理数据蒸馏、预算控制、课程学习、模型合并等多个子技术上开展了一些探索,这个可以形成若干个技术系列专题。
老刘说NLP技术社区,也形成了推理大模型专题,已经有了29篇解读,在https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzAxMjc3MjkyMg==&action=getalbum&album_id=3850672582919340033&

此外,对于多模态推理大模型,也构建起了一个专题,有11篇文章,地址在:https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzAxMjc3MjkyMg==&action=getalbum&album_id=3877614197382840333&scene=173

多看,多思考,看其实现技术与原理,能够对技术更有热爱和敬畏之心。
(文:老刘说NLP)