
我们打造了一个全新的开源权重推理模型:Phi-4,参数量为14B,基于约 140 万条精心策划的推理示例进行了监督微调(SFT),并进行了少量强化学习(RL)训练。这个模型表现惊人,简直是“小钢炮”。
就在我们还在热议Qwen3和DeepSeek V2等旗舰模型的表现时,微软悄然发布了一个轻量级但极具潜力的新模型:Phi-4 推理模型。
微软研究团队一直在 LLM 推理能力的研究上不遗余力。此次发布的 Phi-4 模型,仅有 14B 参数,但在诸如 AIME(美国数学邀请赛)、HMMT(哈佛-麻省理工数学竞赛)、OmniMath 等数学推理测试中,表现甚至超越了体量更大的 Qwen3-32B、DeepSeek R1-70B,以及一些闭源模型如 o1-mini 和 sonnet 3.7。
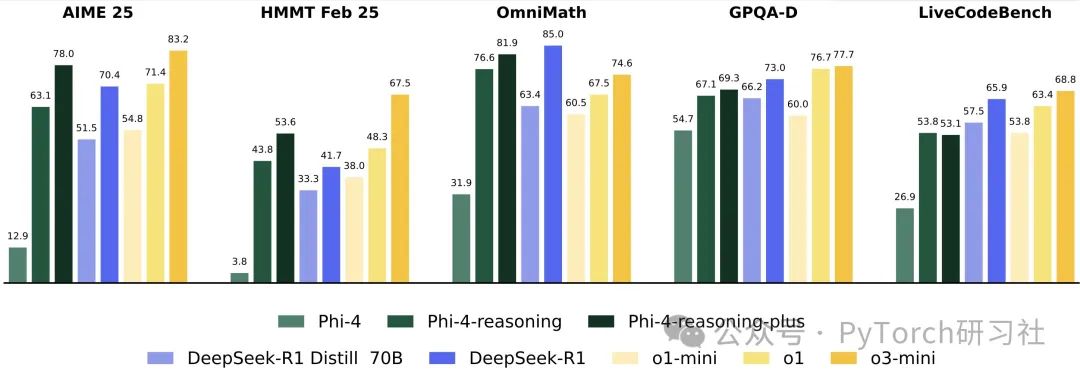
📊小模型,大表现
尽管参数体积较小,Phi-4 在 AIME、GPQA 等推理测试中,表现优于刚发布不久的 Qwen3-32B。虽然尚未完全对比完毕,但初步结果令人震撼。
Phi-4 不仅可以在配置较强的笔记本上运行,还能解决许多大型非推理模型无法解答的谜题——甚至通过了 DimitrisEval 测试。

🤯推理能力竟可迁移!
Reasoning seems to be a real, transferable, meta-skill, learnable even via SFT alone!!
令人惊讶的是,Phi-4 的推理能力似乎是一种可以迁移的元技能,甚至只通过监督微调(SFT)就能习得!
例证一:
即使没有显式训练非推理任务,Phi-4 在 IFEval、FlenQA 和内部的 PhiBench 上也实现了超过10分的提升。
此外,SFT 阶段的代码数据比例非常低(RL 阶段甚至完全没有代码数据),但模型在 LCB 和 Codeforces 上仍能达到与 o1-mini 相当的水平。值得期待的是,未来版本将重点优化编程能力。

例证二:
即便在 SFT 和 RL 阶段完全未训练的问题类型,如旅行商问题、迷宫求解、k-SAT 和受约束规划等,Phi-4 也展现出惊人的能力,远胜 GPT-4 与旧版 Phi 模型。

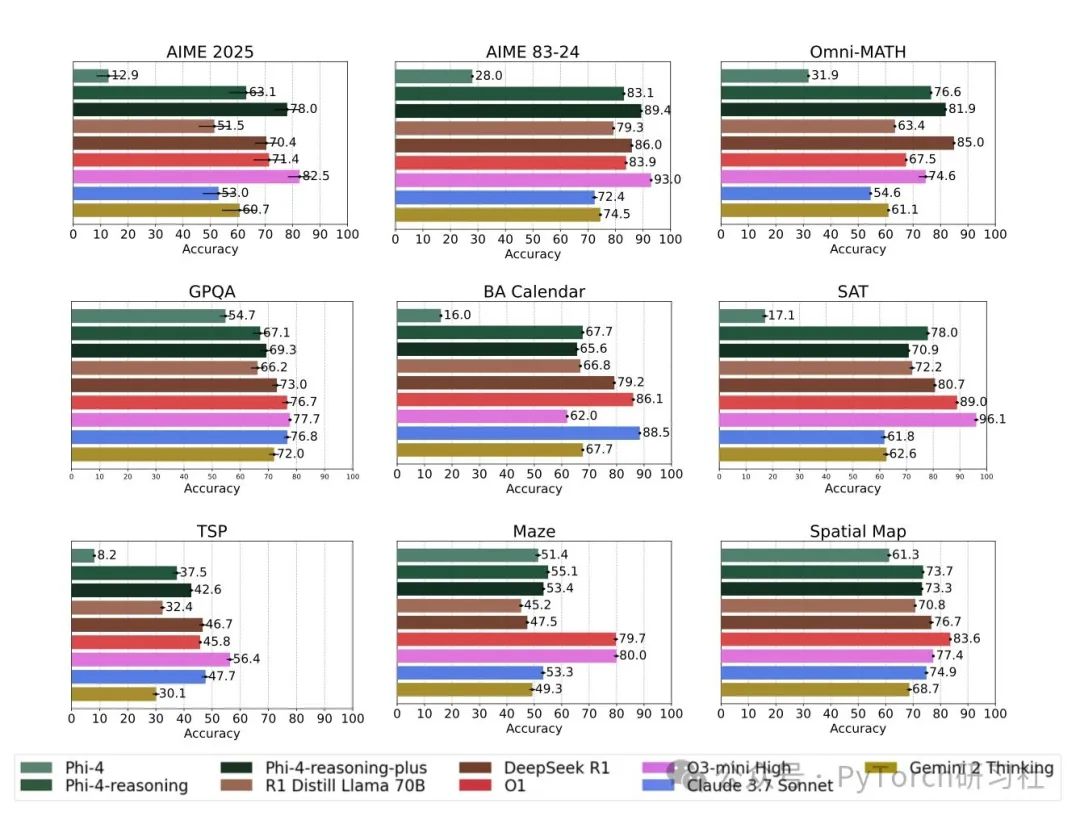
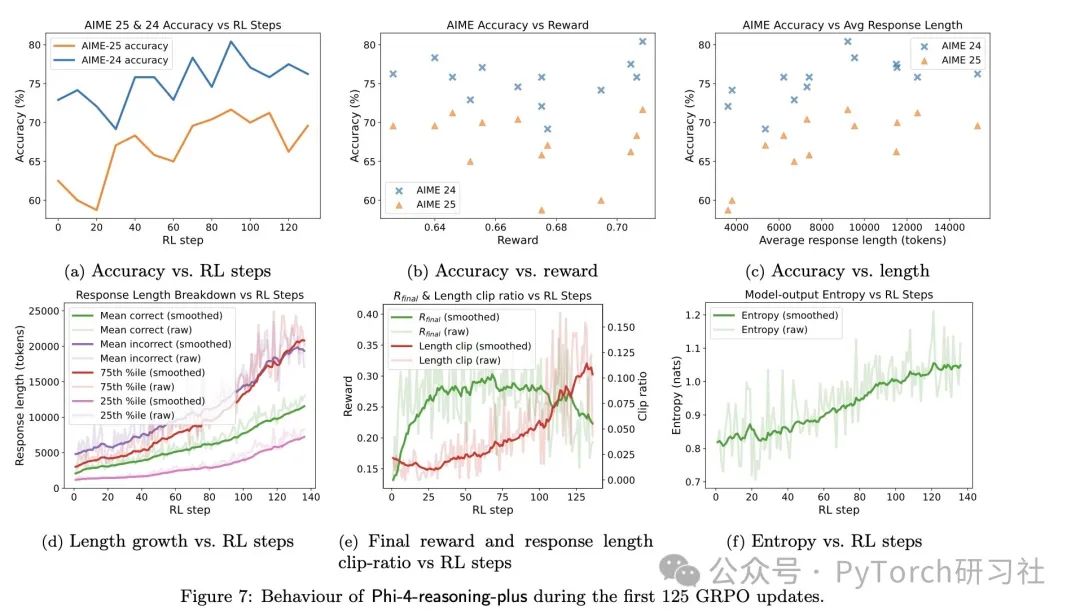
🔁6k 条 RL 样本 = 性能飞跃
Phi-4 仅用 6k 个示例(vs 140 万 SFT 示例)进行了简短的 RL 训练,结果令人震撼:
-
AIME/HMMT 准确率提升约 10%
-
在更难问题上的回答长度平均增长 50%
-
推理机制“锁定”后,回答分布更加集中,准确率更高
这也呼应了微软研究团队在《Self-Improvement in Language Models: The Sharpening Mechanism》中的发现:RL 可以精细化模型能力!
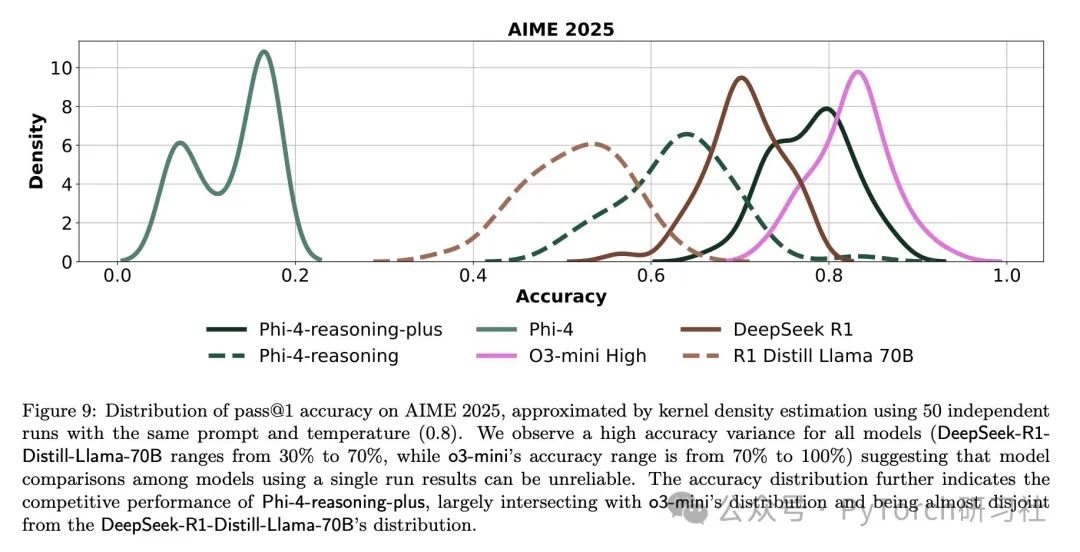
🚀“超越老师”的自我进化
Phi-4 多次在“pass@1”指标下超越了它的老师模型 o3-mini。
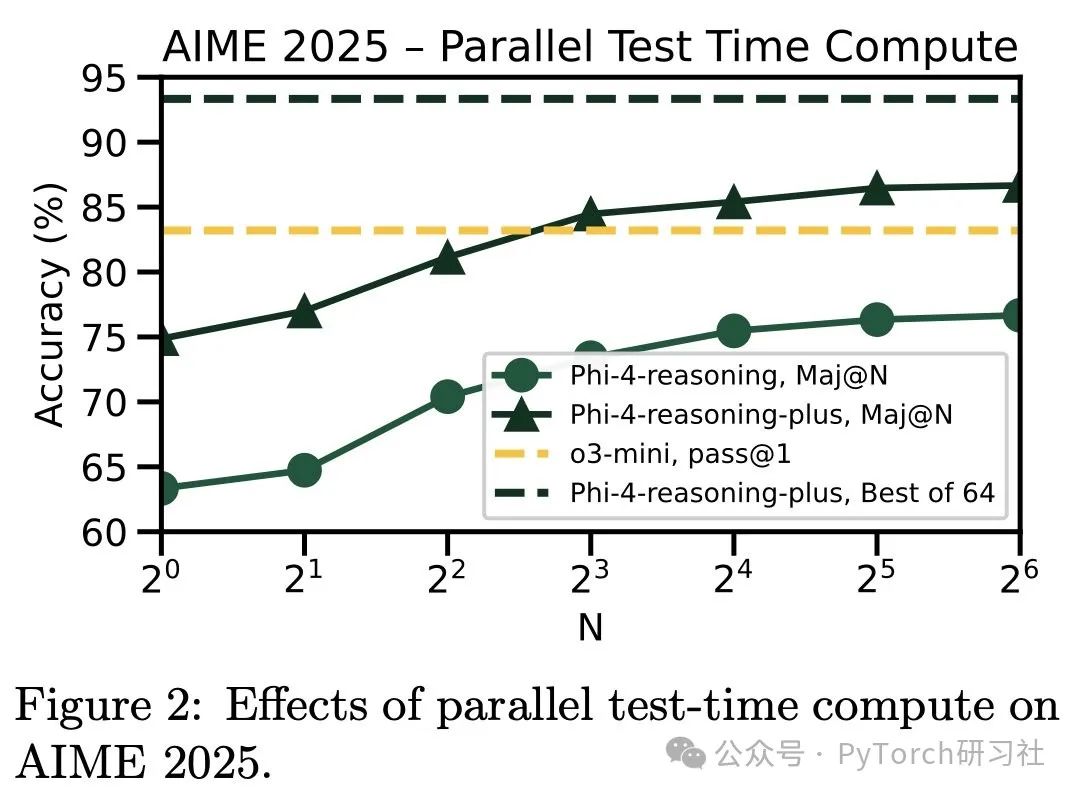
例如在 OmniMath 和 Calendar Planning 中。
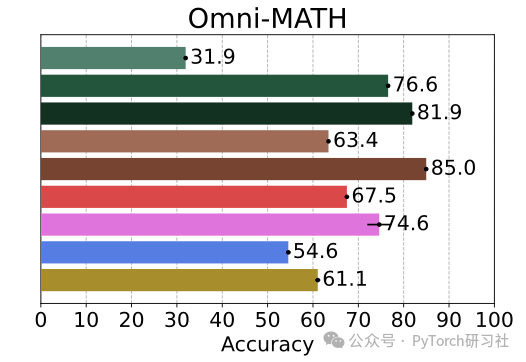
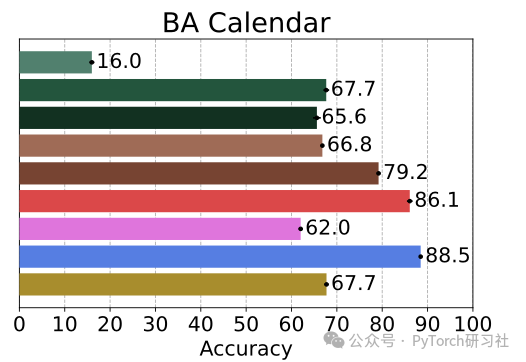
这种“优于教师”的现象,可能得益于良好的 prompt 设计与 RL 训练策略,使模型在学习的过程中产生“自我改进”。
🔍其他
-
回答越长 ≠ 越准:前 25% 长度的回答更容易出错,但整体而言,平均回答越长,准确率越高。
-
模型卡壳时会“唠叨”:测试时观察到模型在难题上会生成大量冗长内容(感谢 @AlexGDimakis 的观察)。
⚠️当前限制
-
尚未拓展/测试 32k token 以上输入能力
-
简单问题上容易“过度思考”
-
多轮对话能力尚未深入测试
📦模型信息与试玩地址
Phi-4 推理模型基于 MIT 许可,体积小、性能强,适合在普通 GPU 上进行微调或 RL,是生成高质量推理样本的绝佳工具。
-
👉 SFT 模型地址
https://huggingface.co/microsoft/Phi-4-reasoning
-
👉 SFT+RL 模型地址
https://huggingface.co/microsoft/Phi-4-reasoning-plus
(文:PyTorch研习社)