

藏师傅很多时候早上上班和洗澡之前都是听音乐的,虽然我喜欢看小说,但之前对那种 AI 生成的音频听书嗤之以鼻。
但是那天无意间用了一下起点新的听书功能,发现居然都这么牛了,前几天交流发现他们的语音生成服务居然是用的 MiniMax 的 Speech 模型,而且就是我最喜欢那个「说书先生」的角色。
最近发现他们更新的 Speech-02 音频模型,在Artificial Analysis 的 ELO 评价榜单上吊打 Open AI 和 ElevenLabs 一众海外音频模型,基本上霸榜了。Hugging Face上,不出意外,也是第一名的成绩。


感兴趣也可以看我去年年底对 Speech-01 的测评《海螺语音上线,这可能是国内最好的配音产品了》
主要升级内容
MiniMax在Github上传了语音模型的技术报告,我也看了一下 Speech-02 的技术报告看了一下主要的升级内容和创新点。
这次 Speech-02 最大的创新在于引入了可学习的说话人编码器,它能从参考音频中提取音色特征,无需音频转录。基于这个就可以实现很多能力,比如只需要一段十几秒的语言就能实现高质量的声音参考能力;
因为说话人编码器捕捉的是与语言无关的音色特征,还能实现将音色迁移到别的语言上,这个对于内容出海很有帮助;
Speech-02还带来了非常高的可扩展性,音色可以用在情感控制、文本到音色、专业语音参考等下游任务,不需要更换模型。
另外,论文里还提到了一个能力特性我很感兴趣。
Speech-02 可以结合用户的自然语言描述和结构化标签,用户可用文本描述生成任意音色。
这个对于复杂的长文编排太有帮助了,想象一下你听小说的时候每个角色的声音都符合他的人设,代入感直接提高一万倍。
目前,B端客户可以通过API接口来测试体验文生音色功能,个人用户还需要再等一等。

模型能力测试
Speech-02 依旧延续了 01 的传统优势,有丰富的预设音色选择,同时每个音色还有丰富的情感选项,基本上这些已有的音色+情感+其他选项调节能够搞出大部分需要的人设和音色。
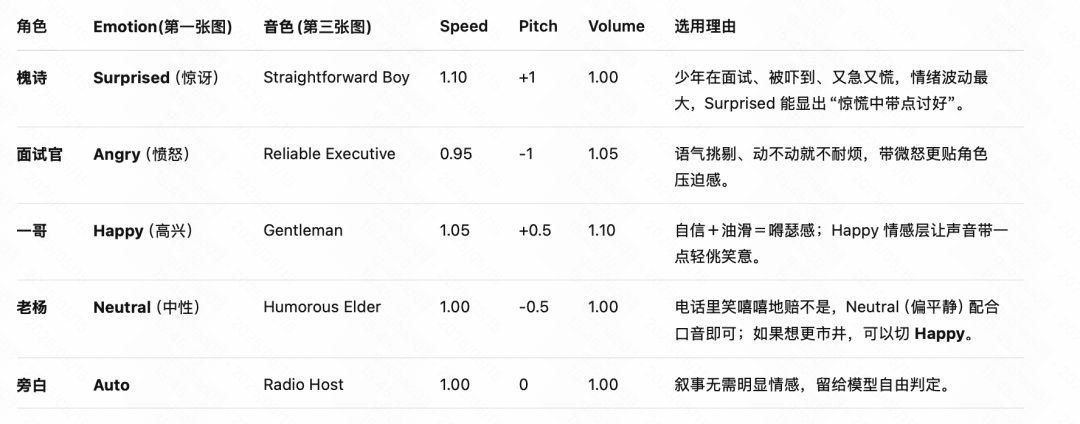
我这里整了个小活,找了一个小说中的对话,做了一个类似游戏的小场景,可以看到还是调整出来的还是非常符合人设的,比如 17 岁来应聘男公关的声音和 KTV 故作深沉准备压价的面试官。
是不是看Speech-02 丰富的音色不知道怎么选,这里有个小窍门,我让 o3 分析了小说人物的性格、对话内容和设定,给出了详细的音色设置,你要是用的话也可以参考这个提示词。
这个里面第三张图片是音色,每一个音色都有图 1 图 2这些选项,帮我给这几个角色找到合适的音色、情感设置和音色设置(搭配设置和音色截图)
之后是 Speech-02 最基本的准确率问题,大家听过 AI 语音的都知道,生僻字读音和多音字读音是非常难得事情,有的时候 AI 读错了真的很出戏。
我这次直接给了一个终极难题,搞了一段连贯的,但是包含非常多生僻字和多音字的内容,真的里面很多字我都得查拼音。
没想到 Speech-02 这次居然一个字都没错,太强了,你可以跟着下面的音频听一下。
另外,这代模型语言多样性也变强了,支持30多个语种;单语种的情绪、音色多样性表现在 01 版本的时候已经很强了,这里整个高难度的多语言混合文案。
里面主体是中文,包含了英语、西班牙语、日语、法语、俄语、德语,文案让 o3 生成的,非常离谱。
没想到 Speech-02 居然生成的还不错,虽然偶尔一两个读音不够特别标准,但已经强的没边了,让人在没准备的情况下读估计能搞定的没几个。
之后就是 Speech-02 的老牌强势能力 声音参考 了。
我这里上传了我自己的一段语音做了个自己的声音模型,然后找了一段自己之前的其他录音,转成文字之后让 Speech-02 生成了一下,做了个对比。
我找我周围的同事听了一遍,他们没有一个可以听出这是生成的声音,他甚至学到了我的说话停顿节奏和口癖,还有语气词,非常邪门。
下面是两段话的对比,你随便拿出生成的来问我,我要是不记得的话,自己都够呛能分清是不是我说的。
另外前面看技术报告的时候发现,现在 Speech-02 声音和语言是解耦的,也就是说可以用经过声音参考后的模型去生成别的语种的音频。
这里我随便找了一段英文推特文案让自己的模型读了一下,哈哈,真的有我自己读英语的那个味道,停顿节奏、语气也都能对上,这下是不是录视频的时候可以用字幕转英文视频内容了。
上面就是这次测试的全部内容了,期待那个通过提示词自定义音色的功能早日全量上线,感觉应用场景非常广泛。
音频内容生成一直是AI领域中较被低估的一环,但实际上它的重要性不可忽视。在日常生活中,我们有相当多的时间只能通过听觉来获取信息;而在视频创作中,高质量的音频同样是决定内容质量的关键因素。
MiniMax敏锐地抓住了这一市场需求,通过持续迭代已经在技术表现上超越了ElevenLabs和OpenAI等国际平台。与通用LLM不同,高质量的中文音频生成需要深度的本土化研发,这正是我们的技术发展优势所在。
如果你觉得教程对你有帮助的话可以帮我点个赞👍或者喜欢🩷,也可以推荐给你需要的朋友们!
(文:归藏的AI工具箱)