
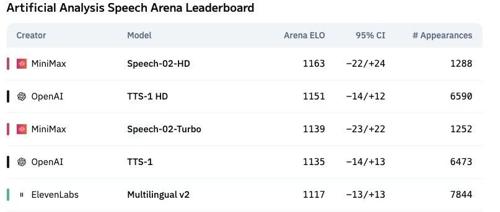
近期,语音AI领域迎来了一场全球性的震撼:MiniMax 旗下 Speech-02语音模型 ,一跃成为全球TTS双榜第一!
不仅登顶了Artificial Analysis Arena榜单,力压OpenAI和ElevenLabs,成为全球第一的语音AI模型!
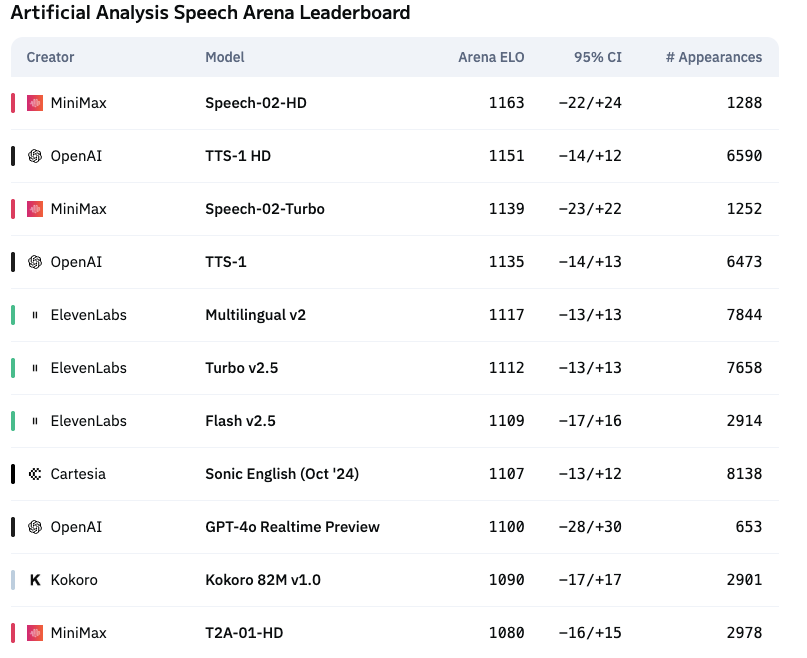
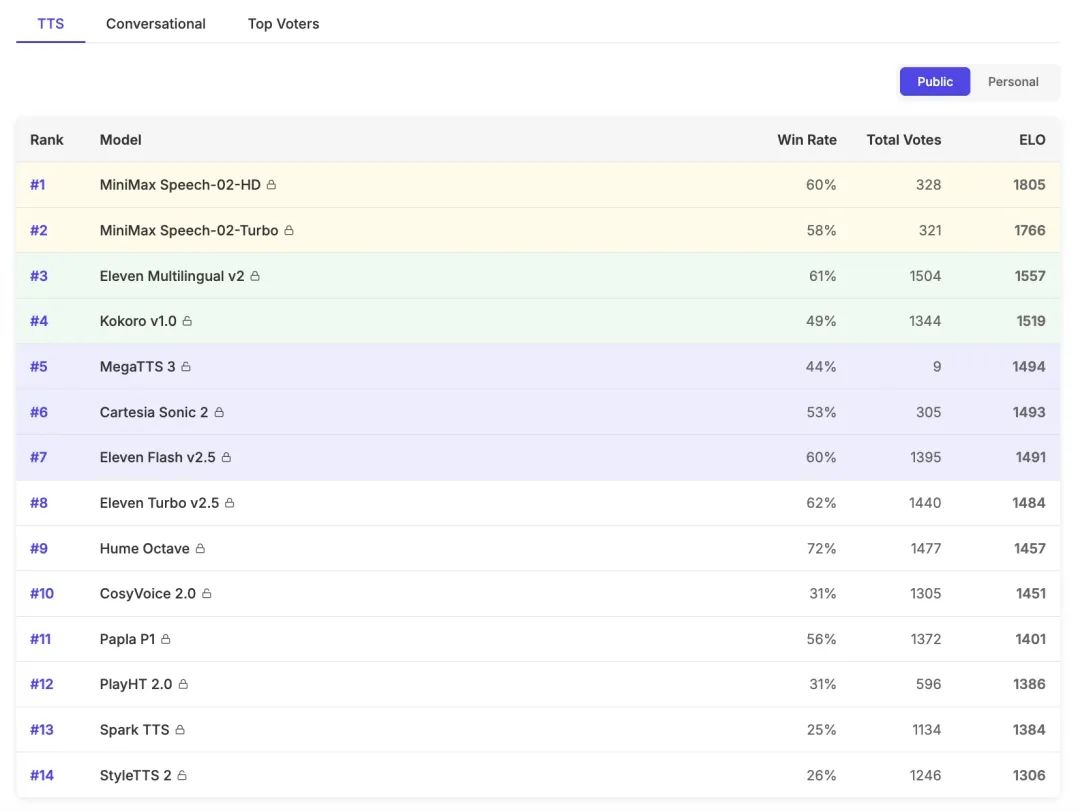
Speech-02 是 MiniMax 全新升级的一款AI语音模型,也是全球第一个真正实现多样化、个性化定义的语音模型。
这让人不免感叹,AI语音的Her Moment已经到来,个性化语音交互将迎来临界点。
个性化体现在它具备强大的 声音参考能力(即语音克隆),只需要提供一小段示范音频或者直接对着模型说几句话,就可生成具备情感、语速、音高等灵活控制的目标音色。而且在没有参考音色的情况下,模型可以实现通过对音色的文字描述生成对应音色,是业内首个实现“任意音色,灵活控制”的模型。
而其多样化体现在不仅可以支持32种不同的语言,即使在同一段语音里,也可以轻松实现多个语种间的自如切换。
比如普通话+粤语:老铁啊,多谢晒你送我呢本,广州话正音字典,咁好嘢喎!我呢个大老爷们儿学广州话真系好难㗎!成日都分唔清声调啊。嗱,而家有咗呢本书,什么都好啦。
其在模型架构上做了诸多技术创新,比如:可学习的说话人编码器,该创新让 Speech-02 能够以零样本方式生成具有高度表现力的语音;还有 Flow-VAE混合架构,集成了VAE和流模型,用以增强VAE编码器的信息表示能力,可以显著提高 Speech-02 合成音频的整体质量。
值得一提的是,相较于ElevenLabs, Speech-02语音模型在性价比方面处于断层领先,定价不到ElevenLabs的四分之一。
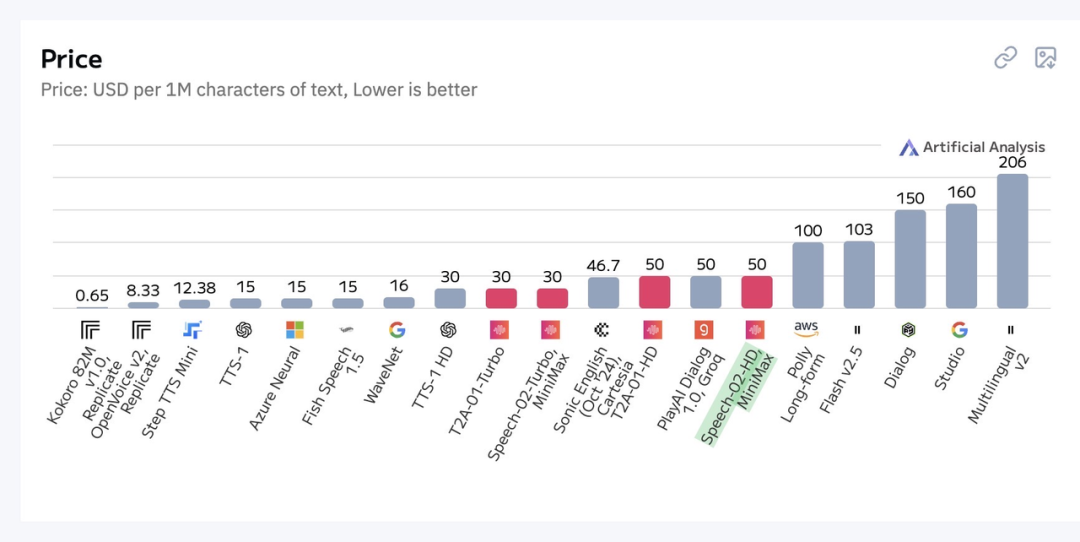
其实从智能助手到有声书制作,从企业客服到多语言播客,从软件到硬件(AI玩偶/手办/学习机),Speech-02 在大众及一些新兴行业已经落地,它以其超凡的技术实力和全球化的应用表现,彻底改写了AI语音的竞争格局。
Speech-02 技术解读
Speech-02 语音模型的成功,源于其在技术上的极致追求。根据官方技术报告显示,Speech-02支持单次输入高达20万个字符,覆盖30+语言,语音合成达到99%的人声相似度,彻底解决了传统语音模型节奏卡顿的问题。
零样本语音克隆(声音参考)
Speech-02 引入了可学习的说话人编码器,能直接从参考音频中提取音色和韵律特征,完全摆脱对文本转录的依赖。
这种 “内在零样本” 模式通过纯音频输入定义说话人身份,避免了「文本-语音」语义不匹配的问题,释放了更灵活的韵律生成空间,合成语音自然度和多样性显著提升。
我们拿一个比较有特色的说话人参考音频,「徐志胜」的声音比较有辨识度,找了10s的声音克隆,再听听TTS效果。
Text:我这个人特别实在,别人说什么我都信,就像别人说我帅,我就真的以为自己靠脸吃饭了!
可以听出来说话情绪是比较Happy的,语速会比平时说话快些,这些情绪、语速、语调都是可控制调节的,以达到更佳的自然度和情感表现。
如果在长文本表现下能够更加凸显,Speech-02在错误率上会比真人更低,比真人更稳定;而在相似度/表现力上和真人一样,不仅情绪细腻、音色、口音、停顿,甚至口癖习惯上都和真人相差无二。
跨语言语音合成
其次多语言支持及跨语言合成,也是Speech-02语音模型的一大特色,主打一个多样性。
Speech-02 可以支持32种不同的语言,为了评估其多语言性能,官方也构建了一个包含 24 种语言的专用测试集。
对于每种语言,包括 100 个不同的测试句子。测试集中的合成语音是使用每种语言的两名说话者(一名男性和一名女性)的克隆语音生成的。以下是 Speech-02 与 ElevenLabs v2 模型在多语言合成中的性能表现。
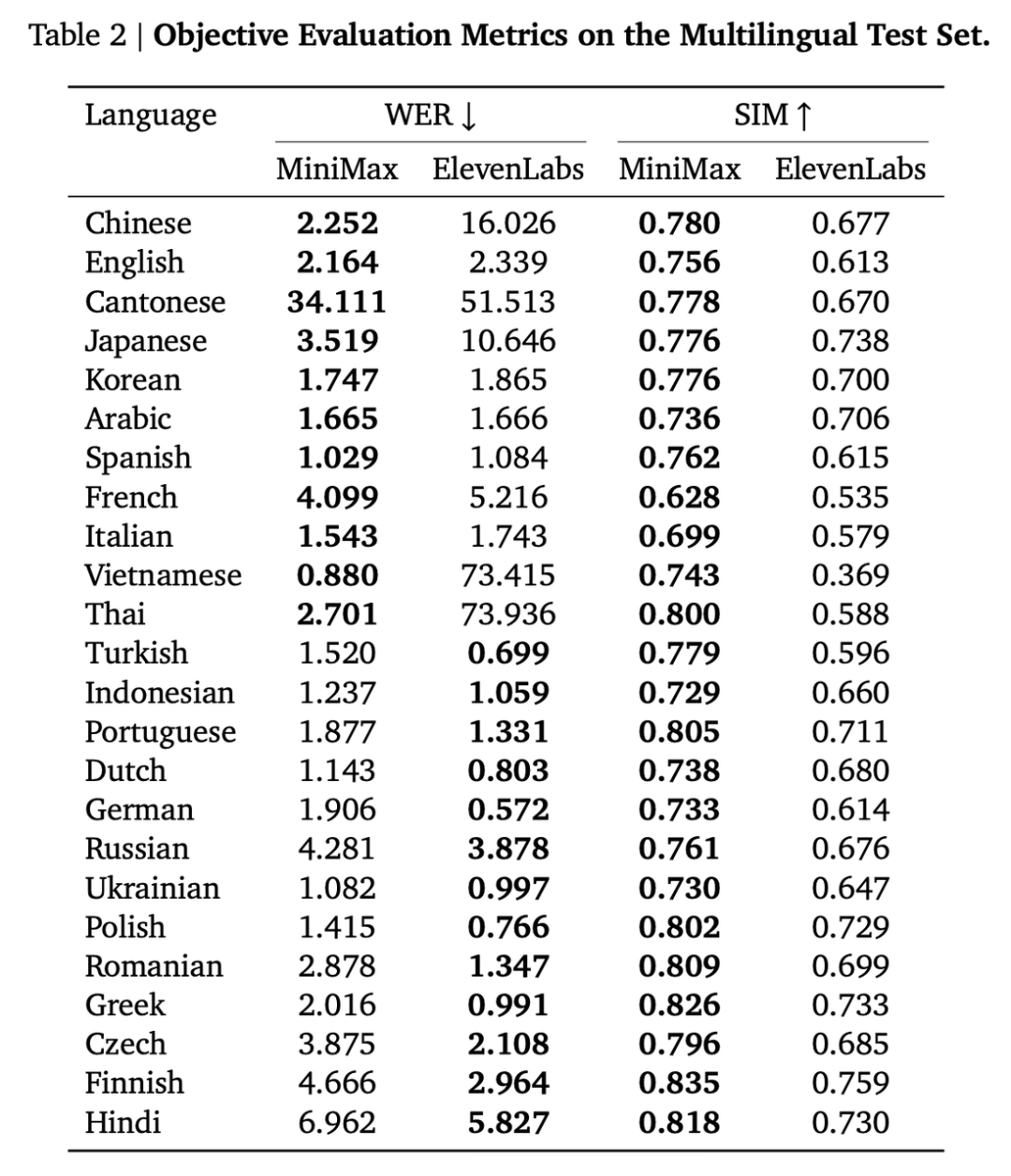
可以发现 MiniMax 在中文、粤语、日语、越南语、泰语等语种表现优异,在相似度上(SIM),全部都优于ElevenLabs;字错率上(WER),也大都低于ElevenLabs。
Tips:相似度越高越好,字错率越低越好
可以听一听下面中文+英文跨语言合成的效果。
Text:The people said, 桂林’s scenery is the first under heaven.Yet in my opinion, 阳朔 scenery is better than 桂林。群峰倒影山浮水,无水无山不入神。
其语音流畅、富有感情且带有一些原始口音。没有出现以往那种呆板的AI语音特点,比较的真实,符合实际人的语言音色风格。
关键技术:Flow-VAE
Flow-VAE 是 MiniMax 用以提升音频质量与特征表示的创新性流匹配混合模型。

传统流匹配模型依赖梅尔频谱图作为中间表示,存在信息损失。
MiniMax 创新地采用 Flow-VAE,将 VAE 的端到端训练优势与流模型的复杂分布拟合能力结合,直接对音频波形的潜在特征建模,避免了梅尔频谱图的瓶颈限制。
你可以把 Flow-VAE 当成一个超专业的语音 “化妆师”,专门负责把语音变得又好看(高质量)又像(高相似度)。它由两部分组成,VAE 和流模型,这两部分携手合作,各显神通。
VAE 可以想象成一个有初步化妆能力的助手,它能把语音数据进行初步处理,就像给语音 “化了个基础妆”,能抓住语音里一些关键的特点,但是这个基础妆它比较标准化,缺乏真实感,没办法还原出每个人语音里的独特细节。
这是由于传统的 VAE 就像一个只会按固定模板工作的工具人。它在处理语音数据时,有个很大的问题,就是假设潜在空间是标准正态分布。简单来说,不管什么语音数据,它都用这个统一的标准去处理。但实际中每个人的语音都有独特之处,比如有的人说话声音尖,有的人声音粗,还有不同的说话节奏和韵律。
而 流模型(Flow) 就像是一个更厉害的“高级化妆师”,它能对 VAE 处理后的语音进行更精细的调整,它能根据每个人的不同的脸部特征进一步修饰,让五官更精致、妆容更贴合、更自然。之前经过 VAE 处理后,语音都被“标准化”了,丢失了很多个人特征。而流模型则会去挖掘这些被忽略的细节,让语音数据原本的特点重新显现出来。
以便能够更精准地还原原始语音数据,把每个人语音里独特的音色、韵律等细节都还原出来,让合成的语音更真实、更有个性。
通过他们俩的协同工作(一个负责打粉底,另一个负责精挑细琢的修饰上妆),才让语音更准确地呈现出我们想要的样子,合成的语音质量更高,和原声的相似度也更高。
实验显示,Flow-VAE 在波形重建误差、说话人相似度(SIM)和语音可懂度(WER)上均优于传统 VAE,合成音频质量更接近真实人声。

这也是 Speech-02 能够登顶 Arena 榜单,超越OpenAI和ElevenLabs的关键性突破技术之一。
高效的语音合成算法与多语言优化,以及低延迟,更低的WER(字错误率)、更高的语音自然度和多语言适应性,才有了如今的 Speech-02 王朝。
适用场景
Speech-02 在教育、有声书、陪伴等行业的应用已经非常成熟了,下面例举几个适合 Speech-02 在新兴行业落地的场景,也许大家很感兴趣!说不定在平时的生活中已经见过了!
场景一:游戏NPC语音对话实时生成
根据玩家选择动态合成对话,实现动态剧情,千人千“声”
原音色:DNF林纳斯+王者芈月+DNF赛丽亚
随机台词:时间就是金钱,我的朋友!;请你逞英雄需要多少钱,你的丧葬费又是多少钱?;你的是我的,我的还是我的!
场景二:AI玩伴互动
通过语音合成模拟宠物“语言”,结合传感器数据生成拟人化反馈,提升人宠情感联结。
这个场景其实 MiniMax 已经正式落地了!比如:爱小伴AI奶龙,为了精准还原奶龙标志性声线,特别接入MiniMax语音模型。

AI玩伴不止是陪伴,还能让它真正理解用户的需求,而不仅仅是回应用户的提问。以下是AI奶龙玩伴真实场景对话的模拟线上版本。
主人:“我今天想去成都吃兔头,你有什么推荐?”
AI奶龙玩伴:“嘿嘿,兔头巴适得很哦!”(奶龙兴奋地晃了晃头)“一般呢,成都的大街小巷都有卖兔头的摊摊,最正宗的还是双流老妈兔头哦!走,我们一路去吃!”
场景三:文化遗产保护:让历史“开口说话”
通过古籍描述+少量录音,合成李白吟诗、莫扎特讲话等场景,还原历史人物风采,让历史人物更加立体。
除了上述场景外,还可应用到智能汽车语音系统、门店导购语音定制(沉浸式零售)、医疗辅助提醒等新兴领域,相信未来强大的语音模型能够方便到千家万户去!
写在最后
在AI迅速发展的全球化浪潮下,多语言沟通需求呈指数级增长,而 Speech-02 模型支持 32 种语言的零样本合成能力,恰好击中了跨文化场景中 “语音克隆成本高、语言适配周期长” 的痛点。
这种 “技术平权” 效应,让中小企业也能轻松获得媲美大厂的语音定制能力,缺少人工智能基建资源的小语种国家也能享受到来自中国大模型的技术红利,推动语音交互从“奢侈品”变为“基础设施”。
更值得关注的是,模型开放的扩展接口,让开发者无需接触复杂的底层架构,即可基于预训练模型快速开发垂直场景应用,提升模型定制化能力,让内容生产增效。
最后想说一句,国产大模型还在不断演进中,总会带来一些不一样的惊喜!
官网地址(海外):https://www.minimax.io/audio
官网地址(国内):https://www.minimaxi.com/audio
项目地址:https://minimax-ai.github.io/tts_tech_report

(文:开源星探)