




文章题目为“深入解读DeepSeek-V3:AI架构的扩展挑战与硬件思考”,一如即往,全是干货。
DeepSeek-V3在2048块NVIDIA H800 GPU上完成训练,性能比肩业内顶尖模型,展示了硬件和模型协同设计如何有效应对算力硬件限制的难题,从而实现经济高效的大规模训练和推理。
所以,这篇论文不仅解读了DeepSeek-V3的创新之处,也采用硬件架构与模型设计的双重视角,探讨二者在实现低成本高效大规模训练和推理中的复杂相互作用,通过研究这种协同效应,旨在为高效扩展LLM提供可行的见解,尤其是为下一代人工智能优化硬件提供了路线图。

DeepSeek-V3/R1模型之所以成为开源之王,离不开一些关键创新工作。
在这篇论文中,他们重点探讨了三个方向:
1、硬件驱动的模型设计:分析FP8低精度计算、规模化扩展/分布式扩展网络特性等硬件特性,如何影响DeepSeek-V3的架构选择。
2、硬件与模型的相互依赖关系:研究硬件能力如何塑造模型创新,以及LLM不断演变的需求如何推动对下一代硬件的需求。
3、硬件发展的未来方向:从DeepSeek-V3中获取可行见解,指导未来硬件与模型架构的协同设计,为可扩展、低成本高效的AI系统铺平道路。
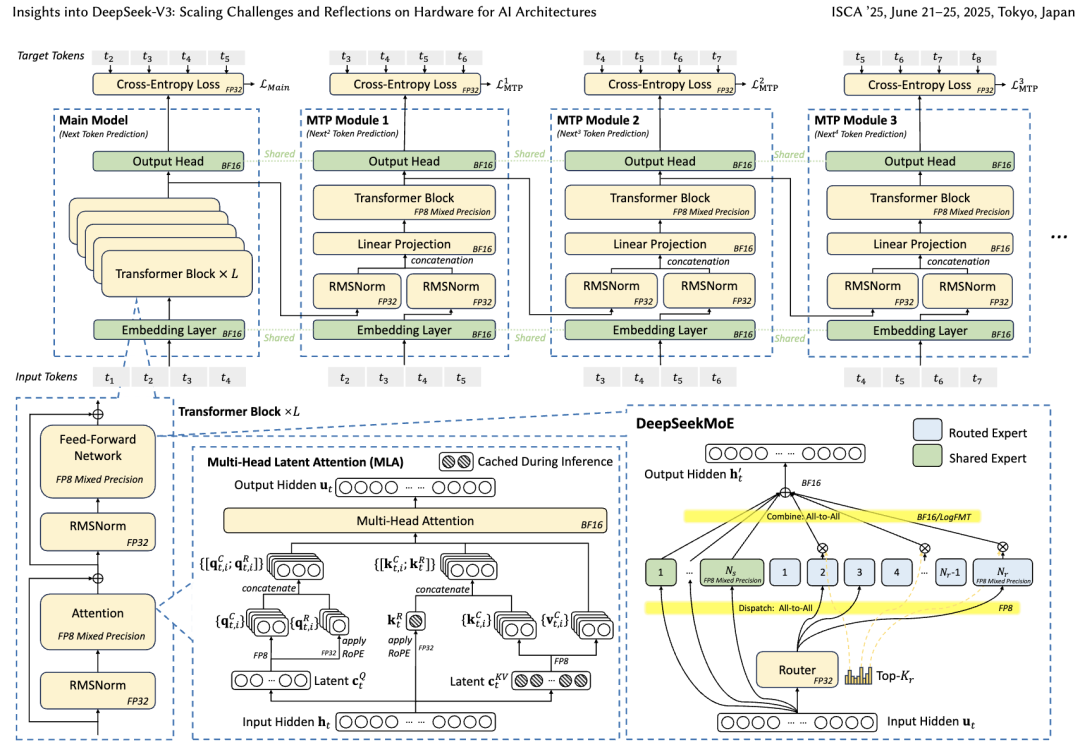
如图所示,V3架构基于DeepSeek-V2的多头潜在注意力(MLA)和DeepSeek-MoE构建,引入了多令牌预测模块(Multi-Token Prediction Module)和FP8混合精度训练,以提升推理和训练效率。
在模型架构之外,还通过部署多平面两层胖树(Multi-Plane Two-Layer Fat-Tree)网络替代传统的三层胖树拓扑结构,探索了具成本效益的AI基础设施,从而降低了集群网络成本。
论文里提到,大型语言模型(LLMs)通常需要大量内存资源,内存需求每年增长超过1000%,相比之下,高速内存(如HBM)容量的增长速度要慢得多,通常每年不到 50%。在LLM推理中,先前请求的上下文会被缓存到所谓的KV缓存中,KV 缓存通过缓存已处理Token的Key和Value向量,避免了后续Token的重复计算。
MLA技术,通过与模型联合训练的投影矩阵,将所有注意力头的KV表示压缩为更小的潜在向量,与存储所有注意力头的KV缓存相比,显著降低了内存消耗。
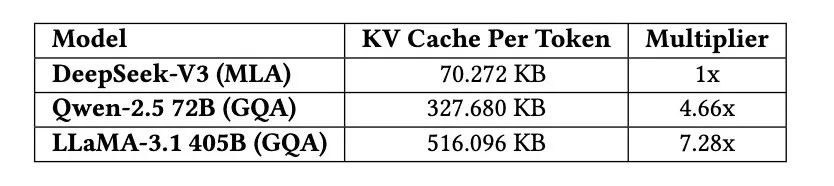
除MLA外,学术界和工业界还提出了其他减少KV缓存规模的方法,如共享KV、窗口化KV、量化压缩等方法,技术创新加持下,DeepSeek-V3的KV缓存规模显著降低,每个Token仅需70 KB,远低于LLaMA-3.1 405B的516 KB和Qwen-2.5 72B的327 KB。
尽管减少KV缓存规模是提升内存效率的有效方法,但基于Transformer的自回归解码固有的二次复杂度仍是一项艰巨挑战,近期业内研究还探讨了线性时间替代方案以及稀疏注意力等方法,DeepSeek团队表示期待与更广泛的社区合作,推动该领域的突破性进展。
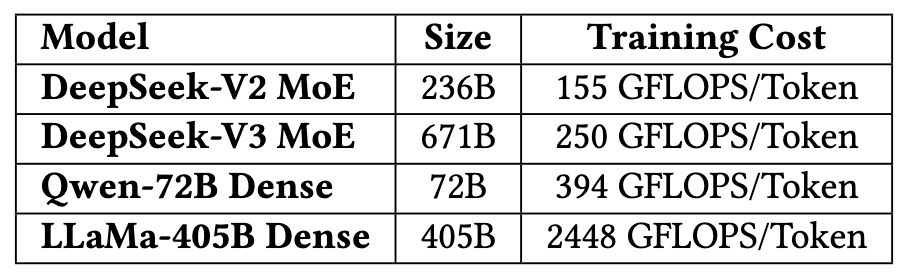
混合专家(MoE)架构的核心优势在于能显著降低训练成本,在消耗一个数量级更少计算资源的同时,能够实现与稠密模型相当甚至更优的性能。DeepSeek-V3的每Token总计算成本约为250 GFLOPS,而720亿参数的稠密模型需要394 GFLOPS,4050亿参数的稠密模型则需要2448 GFLOPS。
尽管FP8在加速训练方面潜力巨大,但要充分发挥其能力仍需解决若干硬件限制,Deepseek团队对未来设计提出了一些建议,包括提升累加精度以及原生支持细粒度量化。
在当前DeepSeek-V3架构中,DeepSeek对网络通信采用低精度压缩策略(LogFMT),还正在积极测试FP8、自定义精度格式以及FP8-BF16混合方案以进一步缩减通信量。
DeepSeek团队建议,未来硬件可考虑提供针对FP8或自定义精度格式的原生压缩/解压缩单元,这有助于最小化带宽需求并简化通信流水线,减少的通信开销在MoE训练等带宽密集型任务中尤其有用。
V3模型训练使用的NVIDIA H800 GPU SXM架构,但出于合规性要求,其FP64计算性能和NVLink带宽有所降低,因此V3纳入了多项与硬件优势和局限性相匹配的设计考量,包括避免张量并行(TP)、增强流水线并行(PP)和加速专家并行(EP)。
此外,DeepSeek-V3在专家选择策略中引入节点受限路由:将256个路由专家分为8组(每组32个专家),每组部署在单个节点上,在此基础上,通过算法确保每个Token最多被路由至4个节点,该方法缓解了IB通信瓶颈,提升了训练过程中的有效通信带宽。
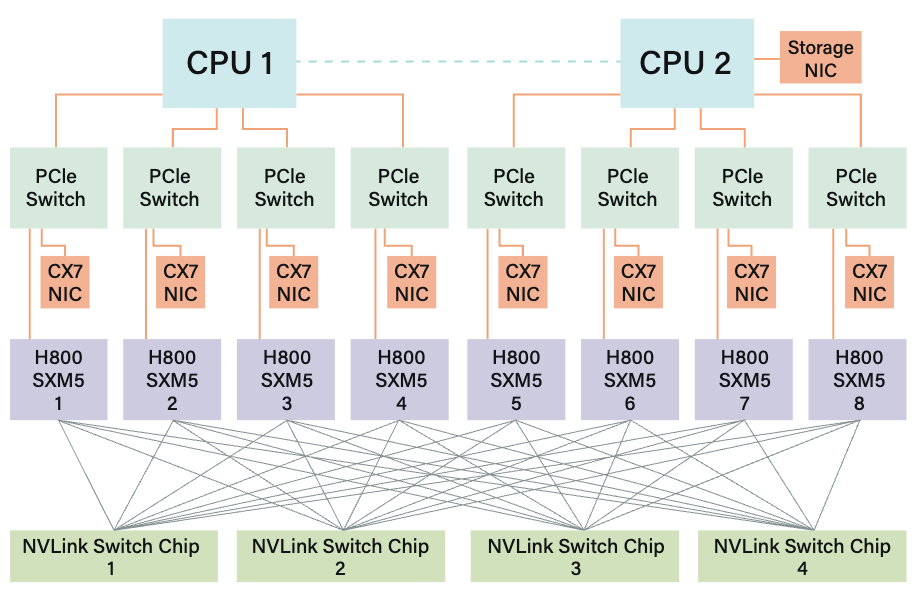
对于算力硬件,DeepSeek团队强烈建议未来硬件将节点内(纵向扩展)和节点间(横向扩展)通信集成到统一框架中。通过引入专用协处理器管理网络流量并在NVLink和IB域之间实现无缝转发,此类设计可降低软件复杂度并最大化带宽利用率。
同时,还要关注新兴的互联协议,如超以太网联盟(UEC)、超加速器链路(UALink),以及最近提出的统一总线(UB),这些都为纵向和横向扩展通信的融合提供了新思路。
在编程框架层面有待实现扩展融合:统一网络适配器、专用通信协处理器、灵活的转发广播和规约机制、硬件同步原语等,通过落实这些建议,未来的硬件设计能够显著提升大规模分布式AI系统的效率,同时简化软件开发流程。
此外,当前硬件缺乏在NVLink和PCIe上为不同类型流量动态分配带宽的灵活性。
建议:1、动态NVLink/PCIe流量优先级:硬件应支持基于流量类型的动态优先级分配;2、I/O Die小芯片集成:将网卡(NIC)直接集成到I/O Die 中,并与同一封装内的计算Die连接;3、纵向扩展域内的CPU-GPU互联:为进一步优化节点内通信,CPU和GPU应使用NVLink或类似的专用高带宽架构互联,而非仅依赖PCIe。
在大规模网络驱动设计方面,DeepSeek团队经过实验验证,多平面网络在保持与单平面多轨网络相当性能的同时,凭借其分层架构和流量隔离特性,为大规模集群提供了更优的可扩展性和成本效率,验证了其在分布式训练中的实用性和有效性。

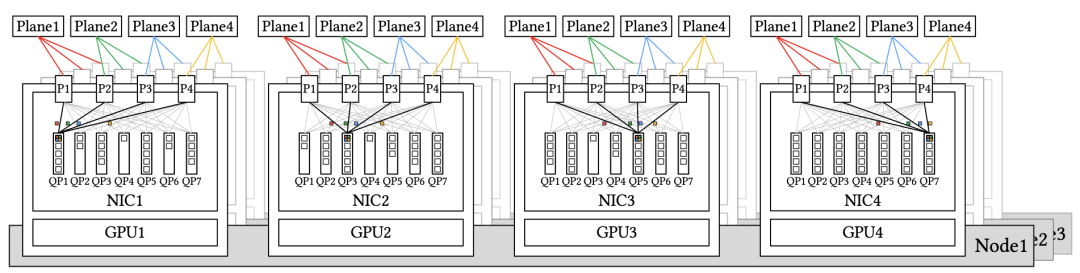
此外,RoCE有望成为IB的高性价比替代方案,但其当前在延迟和可扩展性方面的局限性使其无法完全满足大规模AI系统的需求,所以,针对RoCE改进提出了具体建议,包括:专用低延迟RoCE交换机、优化路由策略、增强流量隔离与拥塞控制机制等等。
通过专用硬件优化、智能路由策略和精细化流量管理,RoCE有望在成本与性能之间取得平衡,逐步成为大规模AI集群中IB的可行替代方案,尤其在推理场景和中小型训练集群中具备广泛应用潜力。
DeepSeek团队这篇论文的最后,勾勒了大规模AI工作负载的硬件设计未来方向,在上述建议基础上,提出更具前瞻性的硬件架构设计方向。
他们总结了目前算力硬件存在的一些问题,如互联故障、硬件异构性影响、故障恢复导致计算开销、单点硬件故障、静默数据损坏等存在鲁棒性挑战和局限性。
此外还指出,为降低静默数据损坏风险,未来硬件必须引入超越传统ECC的高级错误检测机制,硬件供应商应向用户提供全面的诊断工具包,使其能够严格验证系统完整性并主动识别潜在的静默数据损坏。这些工具包作为标准硬件组件的一部分,可增强透明度并支持全生命周期的持续验证,从而提升系统整体可信度。例如:内置压力测试工具、实时错误日志与预警系统等。
通过硬件层的深度优化,可从源头减少故障发生率,并提升系统在复杂AI工作负载中的容错能力,为长时间稳定训练和推理提供基础保障。

值得关注的是,CPU在大规模AI系统中仍是 “系统中枢”,其瓶颈解决需从互联架构革新(如NVLink替代PCIe)、内存技术升级(HBM/CXL)和核心设计优化(高频单核+弹性多核)三方面协同推进。
未来硬件应向 “CPU-GPU-网卡深度融合的异构计算单元” 演进,打破传统架构的层级壁垒,实现计算、存储、通信资源的统一调度与高效利用。
未来的互联技术必须同时将低延迟和智能网络作为优先发展方向,涉及共封装光学(CPO)、无损网络、自适应路由、高效容错协议、动态资源管理等等方向。
在内存语义通信与顺序问题讨论中,DeepSeek团队主张通过硬件支持为内存语义通信提供内置的顺序保证。这种一致性应在编程层面(如通过获取/释放语义)和接收方的硬件层面同时强制实施,从而在不增加开销的情况下实现按序传递。
最后还提出以内存为中心的硬件创新突破建议:
1、DRAM堆叠加速器:利用先进的3D堆叠技术,可将DRAM芯片垂直集成在逻辑芯片上方,从而实现极高的内存带宽、超低延迟和实用的内存容量。
2、晶圆级系统(SoW):晶圆级集成技术可最大化计算密度和内存带宽,满足超大规模模型的需求。
DeepSeek团队的贡献可能不仅仅是开源AI模型,他们团队基于自己的实践经验为下一代人工智能硬件优化提供了路线图,随着人工智能工作负载的复杂性和规模持续增长,这些创新发现和建议可能对于推动智能系统的未来发展至关重要。
此外,在当前英伟达高端AI芯片受限的情况下,DeepSeek这篇论文提出的观点很有现实意义,如果国内大模型优化和国产AI芯片能够深度协同设计创新,可能会使得差距进一步缩小,迸发出意想不到的创新突破。
-END-

(文:头部科技)