

(憋笑 ing)。
对,你没听错,婴儿马斯克讲财政政策的视频已经刷了数百万播放。
🐶:你没错,咱就是不一样,比如我不能在室内拉臭臭,但你可以……

TikTok、Instagram等平台带火了一系列AI婴儿爆款视频。
最近,Hedra 核心模型又升级到了最新一代:Character-3。
你可以把它理解为一个全栈 AI 角色生成器(类似 HeyGen ),只需要一张图片,它就能帮你「造出一个能演、能说、能表达的虚拟角色」。
具体有多强?
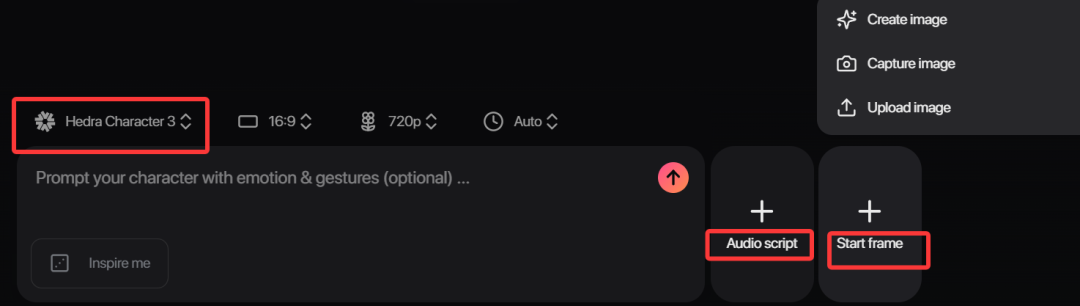 从图像、声音,到最终视频成片,你都可以在一个平台上搞定,不需要跳来跳去。
从图像、声音,到最终视频成片,你都可以在一个平台上搞定,不需要跳来跳去。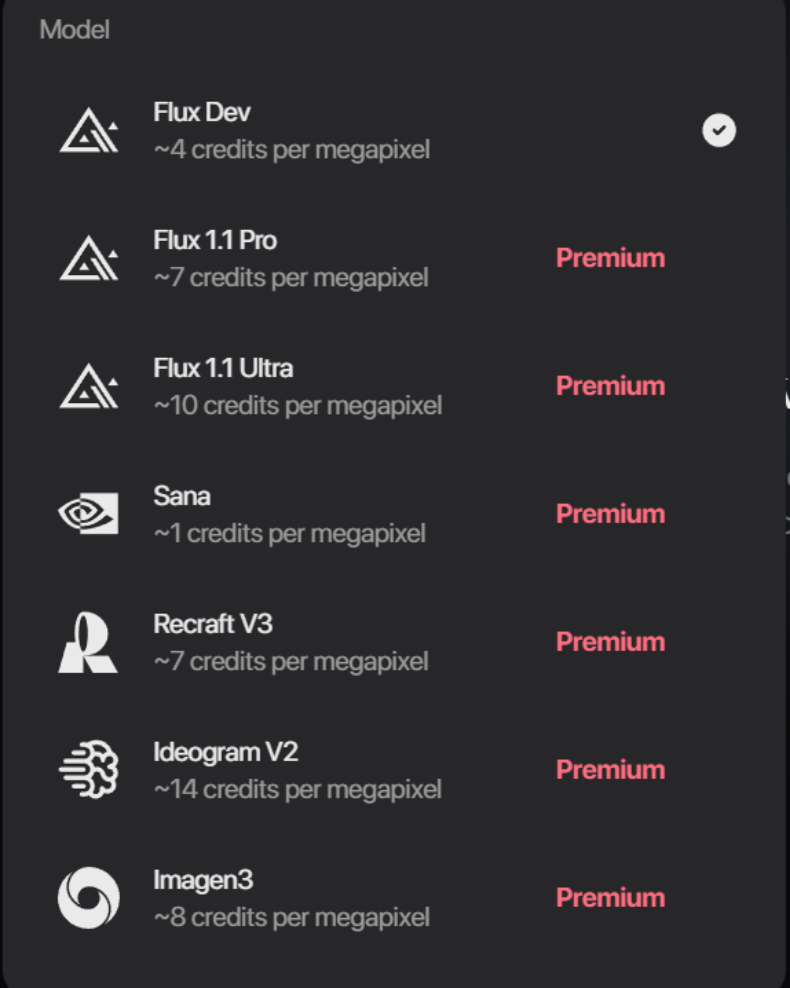 Hedra 提供多个图片生成器。
Hedra 提供多个图片生成器。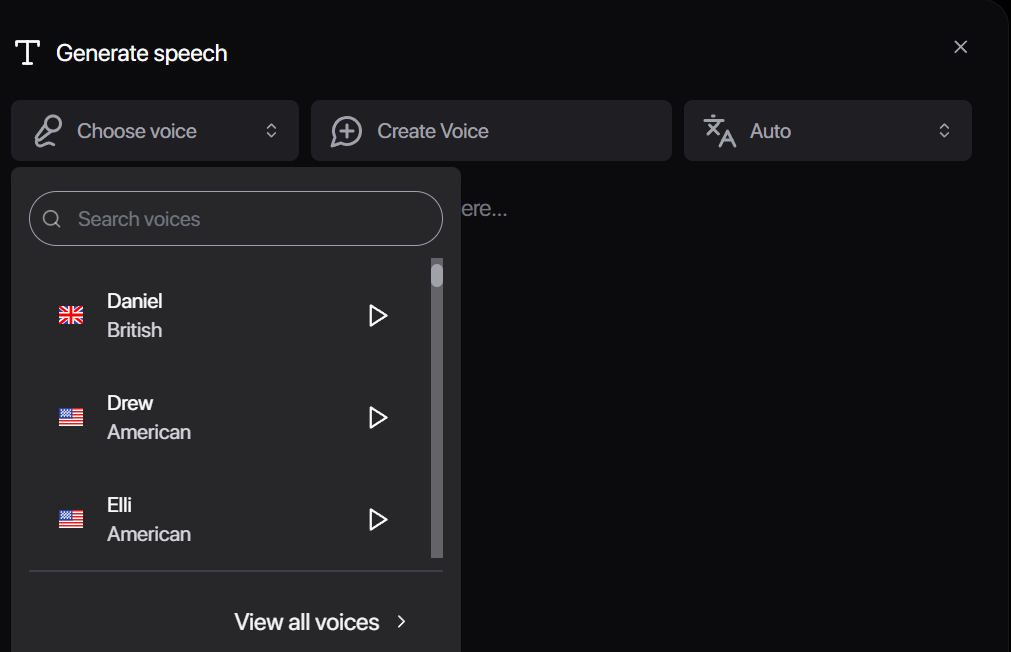 Hedra 提供的音频生成工具。
Hedra 提供的音频生成工具。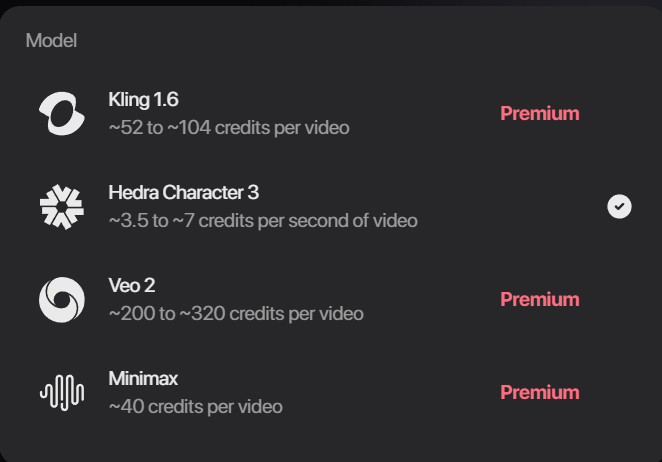 还可调用竞品的视频大模型
还可调用竞品的视频大模型说到这,我们也忍不住亲自上手整活儿——
这次,玩了把穿越 「Baby 宫崎骏专访老年宫崎骏」。两代「宫崎骏」同框对谈,讨论那部帮他拿下第二座奥斯卡奖杯的《苍鹭与少年》。
别急,这里正好说明了一下:
首先,脚本这事 Hedra 不管,它是个生成视频的工具,不是写段子的——所以,得靠其他内容工具。
其次,Hedra 更偏英文内容生态,尤其是音频部分,甚至连一个像样的中文声音选项都没有,咱得另觅他法。
-1-
生成脚本
你可以让 ChatGPT 、豆包、元宝、通义千问等工具写一篇约 4 分钟的播客脚本,讨论老爷子的这部电影。
但我们发现, 谷歌 NotebookLM 也很好用——

删掉一些内容,控制播客时间长度;根据自己的喜好,编辑文字。
– 2 –
AI 生图
Hedra 虽然也提供了不少图像生成器,比如 Flux、Imagen 3、Sana、Ideogram V2,但几乎都得付费。
于是我们干脆换了路线——直接上可灵,免费高效,效果也不赖。
这张 AI 生成的 Baby 照片,就是接下来视频的「起始帧」。
那宫崎骏小时候到底长啥样呢?不太知道。
我们找了张老爷子的照片做参考,结果一出来,同事们第一反应居然是:
「这不就是软银老板孙正义嘛!」「啊?我怎么觉得像大鹏……」
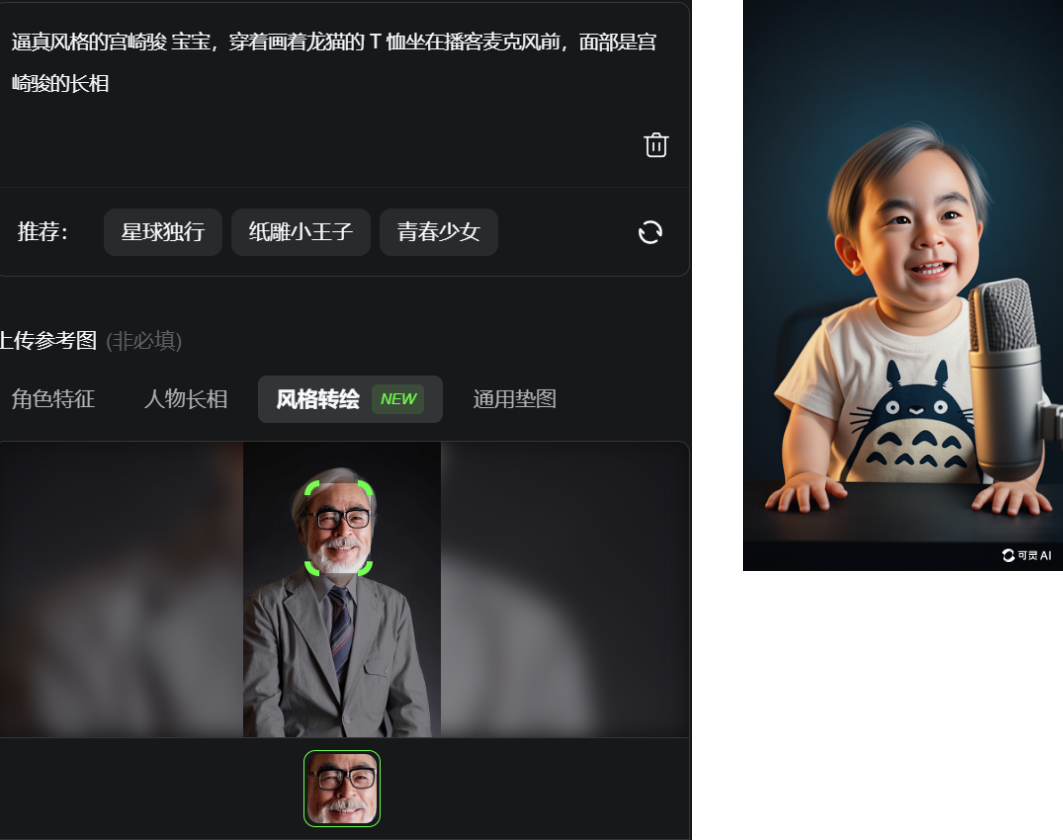
我用 Grok 3 编辑了图片。


– 3 –
中文人声
还得是 MiniMax Audio
要说最棘手的部分,其实是人声。
Hedra 虽然支持文字转语音,但用在中文上……只能说,效果堪比外国人念绕口令:
针对 Baby 宫崎骏和老年宫崎骏,我们采用了不同的方案,毕竟——儿童声音容易找,老人声音真不好配。
 Hedra 虽然支持文字转语音,但用在中文上效果很差。
Hedra 虽然支持文字转语音,但用在中文上效果很差。这时候,就轮到最近屠榜的语音生成神器——MiniMax Audio登场了。
一番对比后发现,它家的声音质量真是嘎嘎在线。
比如 Baby 宫崎骏这段,我们直接把脚本扔进去,选择「涵涵萌兽」的童声模型,几秒钟就生成一段自然又灵动的童音。
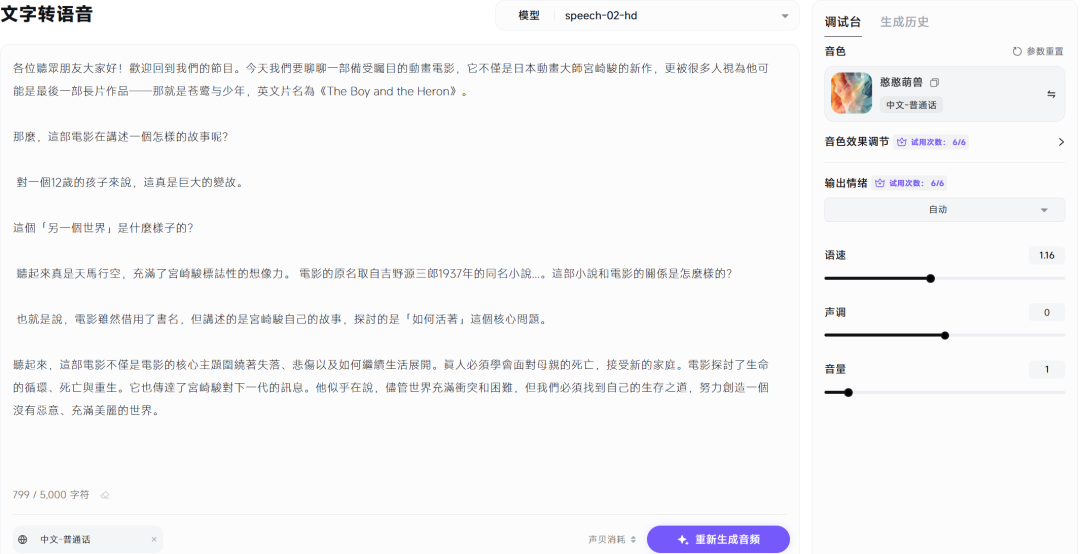
我们想到了克隆。


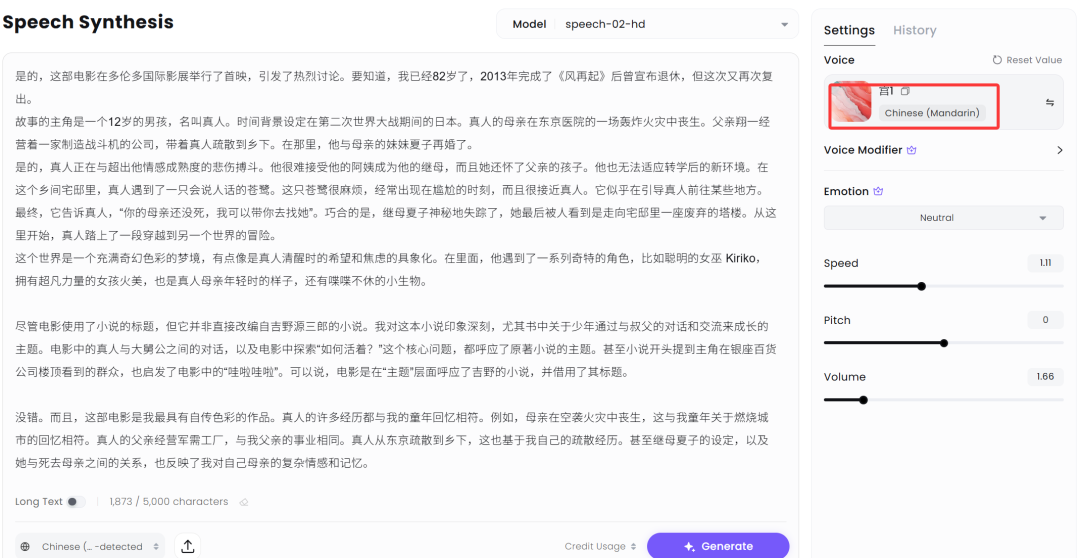
虽然远称不上「神还原」,但和现成 AI 工具自带的那些声音一比,还是强不少的。
不过嘛,也有明显短板:语气听起来像在念稿子,总感觉有点播音腔,不太像真·对话。
但你懂的,在目前这个阶段,能让「老年宫崎骏」说中文、还听得过去,已经挺不容易了。
– 4 –
Hedra
AI 视频,一气呵成
图片、音频都准备好后,接下来就是见证奇迹的时刻——直接把素材丢进 Hedra,生成完整视频!
除了 Hedra 自家的 Character-3,你还能调用别家的模型,比如 Veo 2、Kling 等。
你可以写一些提示词(prompt),控制主持人手势、眼神、语气变化,让视频表现力更上一层楼。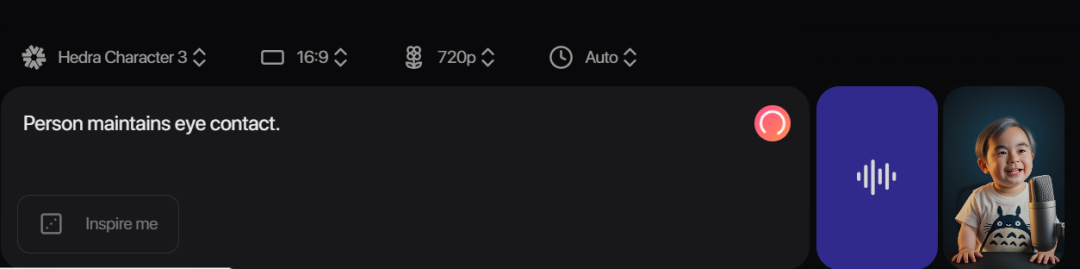
但 Hedra 真正强的地方在于它的「对齐力」:
我们输入的角色音频,老爷子那段将近 3 分钟,配图也只有一张。
结果输出视频中,嘴型对得严丝合缝、节奏精准还原,还有眼神变化。
几乎看不到那种「说话嘴没跟上」的尴尬情况,一气呵成。
– 5 –
剪辑
最后一步,就是剪辑环节啦!
打开剪映,把刚刚生成好的视频导入——
比如,按照脚本,把 Baby 宫崎骏视频拆成小片段,保存好;继续切分老人宫崎骏的视频。
根据脚本,依次导入这些切片,按顺序一来一回地拼接起来。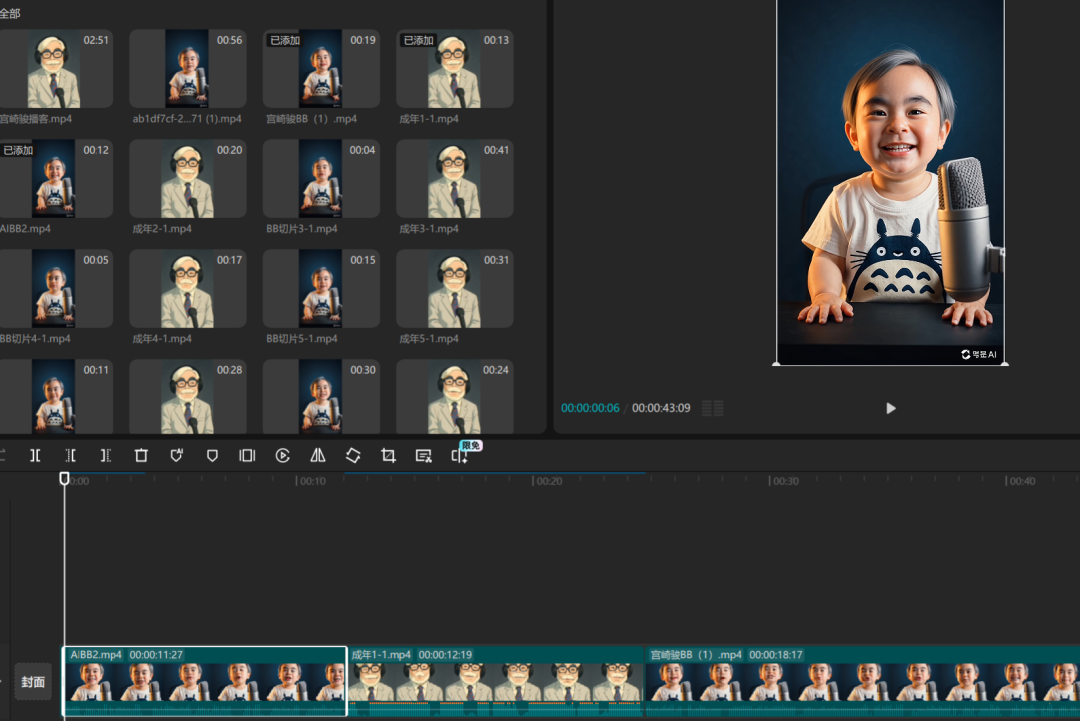
(文:AI好好用)