


写在前面
基于上述的两篇文章,我们已经了解了sglang的请求调度和forward 基本逻辑线。现在我们找一个相对轻松的部分—分布式,主要包括两块,一块是并行通信也就是tp,dp,ep/deepep/eplb(顺便看看deepep和eplb的实现),另一块比较小,是zmq 封装的进程间通信。本次我们不介绍pd 分离的架构,一方面鉴于sglang还没有开发完,另一方面pd分离涉及的开发细节比较多,值得单独写篇做比较(过来人觉得pd 分离值得好好盘一盘)。
先前的两篇文档 进击的Bruce:sglang 源码学习笔记(一)- Cache、Req与Scheduler(https://zhuanlan.zhihu.com/p/17186885141),进击的Bruce:sglang 源码学习笔记(二)- backend & forward 过程(https://zhuanlan.zhihu.com/p/18285771025)。
sglang 里通信域的类型有哪些
sglang 里通信域,包括两大类。
第一种,基于zmq 的通信,用于tokenizer,detokenizer,scheduler 之间进行通信,于并行计算无关。
第二种,基于torch.dist 的通信,用于tp,dp,ep并行计算交互部分。
当然随着pd 分离的实现,势必会引入第三种,因为基于torch 无法实现online的auto-scaling,这基本已经是业界的共识(凡真正做出来线上xpyd 的pd 分离的,都不是基于gloo或者nccl 实现的)。
柿子挑软的先捏,我们先介绍zmq的通信。
sglang 的第一层分布式通信-ZMQ
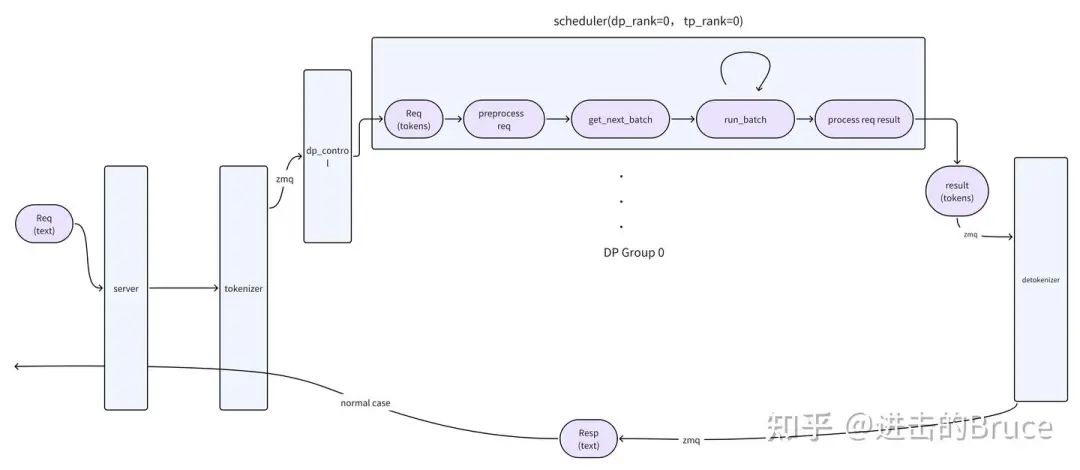
如下是一个简单的概念图,注意在scheduler 侧,zmq 通信方知有rank0,其他rank 通过torch.dist 被rank0 告知。另外注意httpserver 与 tokenizer 之间的通信就是普通函数调用,没有什么分布式的地方,这俩是同一个进程。具体的调用关系见_launch_subprocesses,调用关系如下:
engine->tokenizer
->mp.Process(target=run_scheduler_process) * tp_rank_nums
->mp.Process(target=run_detokenizer_process)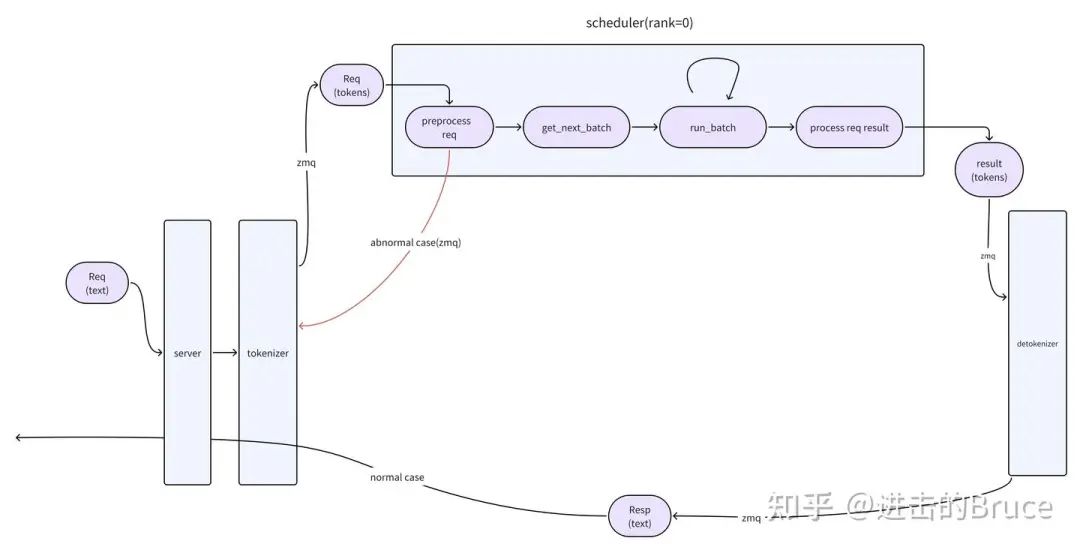
那么zmq 是什么?其实就是进程间 socket的封装,可以是ipc也可以是tcp等等,只要是socket 支持的模式就可以,
def get_zmq_socket(
context: zmq.Context, socket_type: zmq.SocketType, endpoint: str, bind: bool
):zmq 使用的时候主要注意socket_type和end_point 即可,socket_type 说明在这个socket 上是发送的一端(push)还是接收的一端(pull),endpoint 则可以理解为socket的端口地址(用于listen/connect,起到唯一标志的作用)。
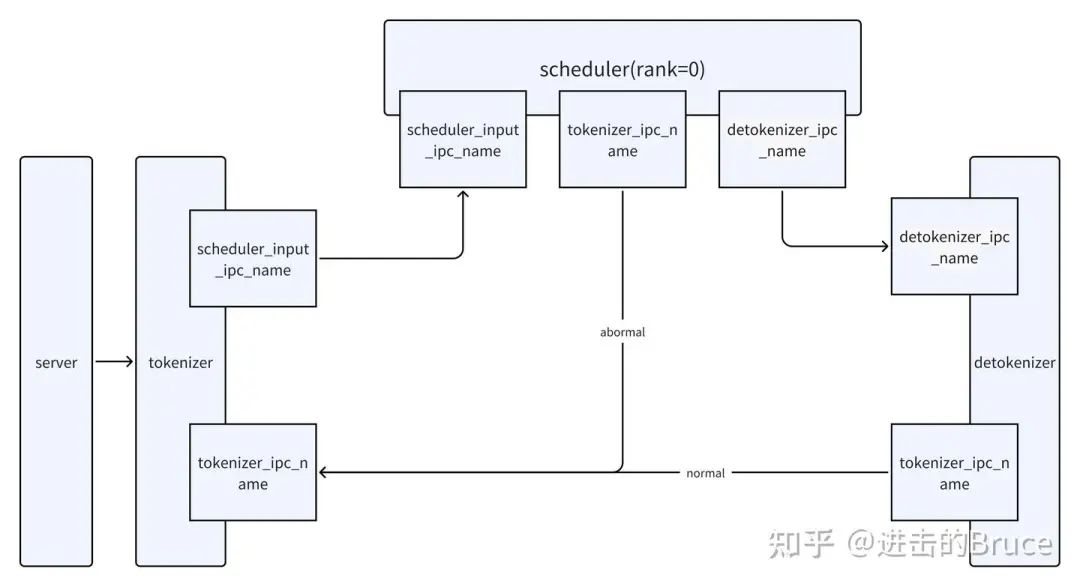
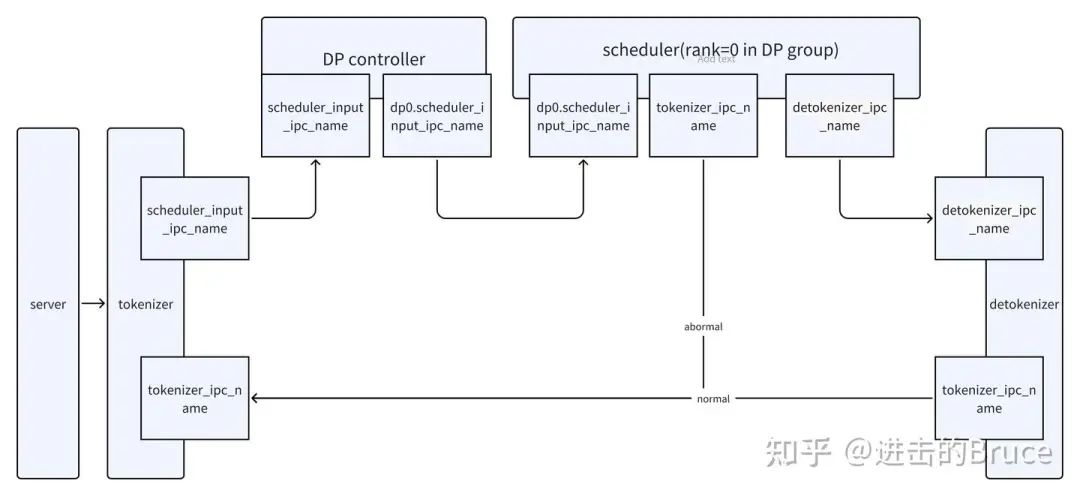
具体的通信规则,可以通过tokenizer,detokenizer,scheduler 的初始化中看到zmq的部分。如下是三个角色的zmq 初始化逻辑,注意下面的endpoint 参数名。
#Tokenizer
self.recv_from_detokenizer = get_zmq_socket(
context, zmq.PULL, port_args.tokenizer_ipc_name, True
)
self.send_to_scheduler = get_zmq_socket(
context, zmq.PUSH, port_args.scheduler_input_ipc_name, True
)
#Scheduler
if self.attn_tp_rank == 0:
self.recv_from_tokenizer = get_zmq_socket(
context, zmq.PULL, port_args.scheduler_input_ipc_name, False
)
self.send_to_tokenizer = get_zmq_socket(
context, zmq.PUSH, port_args.tokenizer_ipc_name, False
)
# Send to the DetokenizerManager
self.send_to_detokenizer = get_zmq_socket(
context, zmq.PUSH, port_args.detokenizer_ipc_name, False
)
self.recv_from_rpc = get_zmq_socket(
context, zmq.DEALER, port_args.rpc_ipc_name, False
)
#Detokenizer
self.recv_from_scheduler = get_zmq_socket(
context, zmq.PULL, port_args.detokenizer_ipc_name, True
)
self.send_to_tokenizer = get_zmq_socket(
context, zmq.PUSH, port_args.tokenizer_ipc_name, False
)这样我们就获得了三个组件之间的通信链路。到此,zmq 相关逻辑,我们就明白了,zmq 的通信是请求完整的生命周期触发的,简单明快,配合第一篇文章相信大家就可以理解了。
sglang的第二层分布式通信-torch.dist(WIP)
这一层需要重点分析。(先开坑,然后等人催,催就是写完的动力,摆烂ing)
Communicator 层的接口和基础实现
sglang 的communicator 大部分是从vllm 借鉴过来的,所以这里的基础逻辑,熟悉vllm communicator 设计的就不用看了。主入口在 python/sglang/srt/distributed/communication_op.py。相关调用逻辑如下,以all_gather 为例。
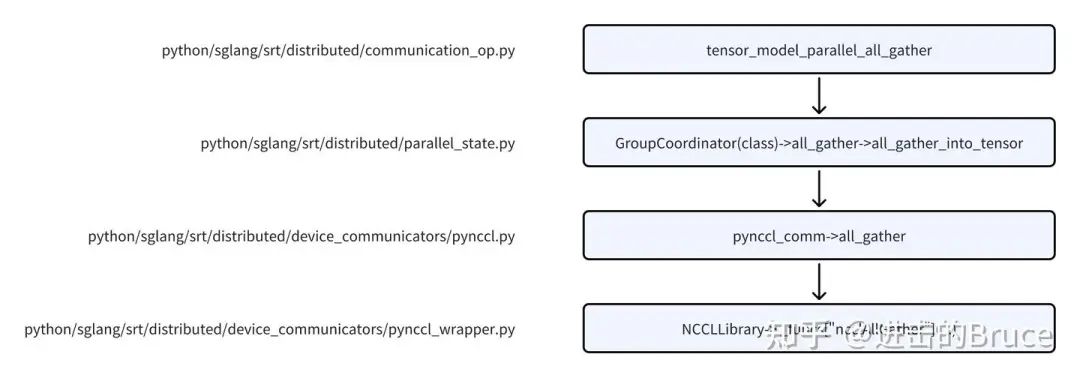
这里其实最关键的文件是python/sglang/srt/distributed/parallel_state.py, 关键数据结构是GroupCoordinator。
class GroupCoordinator:
"""
PyTorch ProcessGroup wrapper for a group of processes.
PyTorch ProcessGroup is bound to one specific communication backend,
e.g. NCCL, Gloo, MPI, etc.
GroupCoordinator takes charge of all the communication operations among
the processes in the group. It can route the communication to
a specific implementation (e.g. switch allreduce implementation
based on the tensor size and cuda graph mode).
"""
# available attributes:
rank: int # global rank
ranks: List[int] # global ranks in the group
world_size: int # size of the group
# difference between `local_rank` and `rank_in_group`:
# if we have a group of size 4 across two nodes:
# Process | Node | Rank | Local Rank | Rank in Group
# 0 | 0 | 0 | 0 | 0
# 1 | 0 | 1 | 1 | 1
# 2 | 1 | 2 | 0 | 2
# 3 | 1 | 3 | 1 | 3
local_rank: int # local rank used to assign devices
rank_in_group: int # rank inside the group
cpu_group: ProcessGroup # group for CPU communication
device_group: ProcessGroup # group for device communication
use_pynccl: bool # a hint of whether to use PyNccl
use_custom_allreduce: bool # a hint of whether to use CustomAllreduce
use_message_queue_broadcaster: (
bool # a hint of whether to use message queue broadcaster
)
# communicators are only created for world size > 1
pynccl_comm: Optional[Any] # PyNccl communicator
ca_comm: Optional[Any] # Custom allreduce communicator
mq_broadcaster: Optional[Any] # shared memory broadcaster这里最关键的是rank相关的几个字段,以及为了处理CPU/device(like GPU) 不同的通信链路而建立的ProcessGroup(具体processGroup 可以看进击的Bruce:源码阅读-PyTorch 如何调用到NCCL?(https://zhuanlan.zhihu.com/p/676558684))。
另外需要关注的是custom allreduce communicator,这里过会TP再讲。接下来让我们结合TP来理解这个数据结构的应用。
TP的实现
TP的初始化
TP 即tensor parallelism,是model parallelism的一种。其初始化过程展示了许多细节。
这里有两个关键函数:init_distributed_environment, initialize_model_parallel.
如下代码位于init_torch_distributed(self), 即属于model_runner 初始化过程。其中initialize_dp_attention我们先放一放,我们先考虑没有enable_dp_attention的情况。
init_distributed_environment(
backend=backend, # 在cuda下,backend = nccl
world_size=self.tp_size,
rank=self.tp_rank,
local_rank=self.gpu_id,
distributed_init_method=dist_init_method, #一个唯一标志符
timeout=self.server_args.dist_timeout,
)
initialize_model_parallel(tensor_model_parallel_size=self.tp_size)
initialize_dp_attention(
enable_dp_attention=self.server_args.enable_dp_attention,
tp_rank=self.tp_rank,
tp_size=self.tp_size,
dp_size=self.server_args.dp_size,
)init_distributed_environment
如下是核心函数源代码,可见默认backend 是nccl。这里我们需要对两个torch 接口做辨析:
init_process_group
必须首先调用:所有分布式操作(包括 new_group)必须在默认进程组初始化后进行
全局唯一:每个进程只需调用一次,定义整个分布式训练的基础环境。new_group
依赖默认进程组:必须在init_process_group之后调用,用于创建子组。
可多次调用:可根据需要创建多个子组,每个子组包含不同的进程集合。
之所以辨析这两个接口,是因为当我们分析通信初始化代码时,会发现init_distributed_environment里有init_process_group,而init_world_group以及initialize_model_parallel 通过构建GroupCoordinator实现,而GroupCoordinator初始化会调用new_group 创建子进程通信组。我们需要知道,model_parallelism 下的通信组都只是整个world的子组,一切都来源于基础的init_process_group。
def init_distributed_environment(
world_size: int = -1,
rank: int = -1,
distributed_init_method: str = "env://",
local_rank: int = -1,
backend: str = "nccl",
timeout: Optional[int] = None,
):
logger.debug(
"world_size=%d rank=%d local_rank=%d " "distributed_init_method=%s backend=%s",
world_size,
rank,
local_rank,
distributed_init_method,
backend,
)
# 这里只是一些参数检查
if not torch.distributed.is_initialized():
assert distributed_init_method is not None, (
"distributed_init_method must be provided when initializing "
"distributed environment"
)
if timeout is not None:
assert isinstance(timeout, (int)), "timeout must be a number"
assert timeout > 0, "timeout must be positive"
timeout = timedelta(seconds=timeout)
# this backend is used for WORLD
## most important:全局通信进程组的初始化
torch.distributed.init_process_group(
backend=backend,
init_method=distributed_init_method,
world_size=world_size,
rank=rank,
timeout=timeout,
)
# set the local rank
# local_rank is not available in torch ProcessGroup,
# see https://github.com/pytorch/pytorch/issues/122816
if local_rank == -1:
# local rank not set, this usually happens in single-node
# setting, where we can use rank as local rank
if distributed_init_method == "env://":
local_rank = int(os.environ.get("LOCAL_RANK", "0"))
else:
local_rank = rank
global _WORLD
if _WORLD is None:
ranks = list(range(torch.distributed.get_world_size()))
_WORLD = init_world_group(ranks, local_rank, backend)
else:
assert (
_WORLD.world_size == torch.distributed.get_world_size()
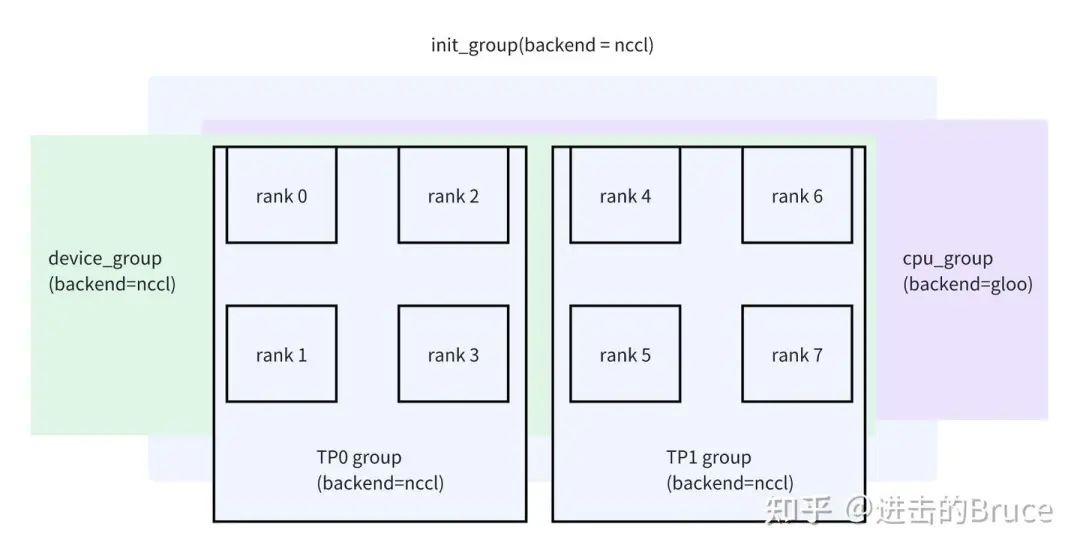
), "world group already initialized with a different world size"init_world_group这个函数实现非常平凡,入参基本都是False,所以基本不太参与通信任务,它主要是完成了两个大group的创建,基于上述默认进程组分别创建了device_group和cpu_group两个通信组,world_size和默认进程组一致(猜是为了方便管理,这样管理和其他TP/PP的group 拉平了,都在一个dict里)。
def init_world_group(
ranks: List[int], local_rank: int, backend: str
) -> GroupCoordinator:
return GroupCoordinator(
group_ranks=[ranks],
local_rank=local_rank,
torch_distributed_backend=backend,
use_pynccl=False,
use_custom_allreduce=False,
use_hpu_communicator=False,
use_xpu_communicator=False,
group_name="world",
)
##In class GroupCoordinator __init__():
## 注意这里的cpu group 用了gloo,而device_group 基于默认组的backend,cuda下就是nccl
## 注意这里虽然是一个循环,但是init_world_group的传参可见,group_ranks 的size 是1
## 而ranks 就是range(world_size)所得
for ranks in group_ranks:
device_group = torch.distributed.new_group(
ranks, backend=torch_distributed_backend
)
# a group with `gloo` backend, to allow direct coordination between
# processes through the CPU.
cpu_group = torch.distributed.new_group(ranks, backend="gloo")
if self.rank in ranks:
self.ranks = ranks
self.world_size = len(ranks)
self.rank_in_group = ranks.index(self.rank)
self.device_group = device_group
self.cpu_group = cpu_group
initialize_model_parallel
大环境有了,可以看tp的初始化了。首先是入参,可以看到,默认pp和tp 都是1,根据当前sglang的使用,只有tp的传参,还没有pp的,但后续会支持pp。
def initialize_model_parallel(
tensor_model_parallel_size: int = 1,
pipeline_model_parallel_size: int = 1,
backend: Optional[str] = None,
) -> None:
"""
Initialize model parallel groups.
Arguments:
tensor_model_parallel_size: number of GPUs used for tensor model
parallelism.
pipeline_model_parallel_size: number of GPUs used for pipeline model
parallelism.
Let's say we have a total of 8 GPUs denoted by g0 ... g7 and we
use 2 GPUs to parallelize the model tensor, and 4 GPUs to parallelize
the model pipeline. The present function will
create 4 tensor model-parallel groups and 2 pipeline model-parallel groups:
4 tensor model-parallel groups:
[g0, g1], [g2, g3], [g4, g5], [g6, g7]
2 pipeline model-parallel groups:
[g0, g2, g4, g6], [g1, g3, g5, g7]
Note that for efficiency, the caller should make sure adjacent ranks
are on the same DGX box. For example if we are using 2 DGX-1 boxes
with a total of 16 GPUs, rank 0 to 7 belong to the first box and
ranks 8 to 15 belong to the second box.
"""
# Get world size and rank. Ensure some consistencies.
# 先捞一波检查和元数据,比如world_size 是否匹配; backend 用device_group 的,实际上也就是用默认进程组的
assert torch.distributed.is_initialized()
world_size: int = torch.distributed.get_world_size()
backend = backend or torch.distributed.get_backend(get_world_group().device_group)
if world_size != tensor_model_parallel_size * pipeline_model_parallel_size:
raise RuntimeError(
f"world_size ({world_size}) is not equal to "
f"tensor_model_parallel_size ({tensor_model_parallel_size}) x "
f"pipeline_model_parallel_size ({pipeline_model_parallel_size})"
)
# Build the tensor model-parallel groups.
# 这里主要是基于tp 切分group,比如一共8卡,tp=2,就可以切成[0-3],[4-7]
num_tensor_model_parallel_groups: int = world_size // tensor_model_parallel_size
global _TP
assert _TP is None, "tensor model parallel group is already initialized"
group_ranks = []
for i in range(num_tensor_model_parallel_groups):
ranks = list(
range(i * tensor_model_parallel_size, (i + 1) * tensor_model_parallel_size)
)
group_ranks.append(ranks)
# 基本就是直接调用GroupCooridinator 构建,和init_world_group 差别不大
# 主要是入参许多改成了true(比如使用pynccl,使用mq等等)
# message queue broadcaster is only used in tensor model parallel group
_TP = init_model_parallel_group(
group_ranks,
get_world_group().local_rank,
backend,
use_message_queue_broadcaster=True,
group_name="tp",
)
# pp 同理,不过group 划分方式不同,比如world_size 为8, pp为2
# 此时会切割成几个group:[0, 4], [1, 5], [2, 6], [3, 7],
# 不过pp 现在没有实际实现完,可能会改,体会一下就行,结合上述tp的切分方式,可以感受到二者的正交性
# Build the pipeline model-parallel groups.
num_pipeline_model_parallel_groups: int = world_size // pipeline_model_parallel_size
global _PP
assert _PP is None, "pipeline model parallel group is already initialized"
group_ranks = []
for i in range(num_pipeline_model_parallel_groups):
ranks = list(range(i, world_size, num_pipeline_model_parallel_groups))
group_ranks.append(ranks)
# pipeline parallel does not need custom allreduce
_PP = init_model_parallel_group(
group_ranks,
get_world_group().local_rank,
backend,
use_custom_allreduce=False,
group_name="pp",
)
用一张图总结几个group的关系。这里没有画pp(因为感觉画不下),pp =1 的情况下,也是8张卡一个pp group。
scheduler 中的TP(模型无关的部分)
scheduler 这个东西我们之前讲解过,可以移步进击的Bruce:sglang 源码学习笔记(一)- Cache、Req与Scheduler(https://zhuanlan.zhihu.com/p/17186885141)。但之前我们更多是只讲了tp1 下的情况,在tp2 下scheduler 又多了一些细节。我们这里浅浅介绍一下。涉及到的数据结构主要是scheduler和logitsProcessor。
class Scheduler(...):
...
def recv_requests(self) -> List[Req]:
if self.attn_tp_size != 1:
attn_tp_rank_0 = self.dp_rank * self.attn_tp_size
work_reqs = broadcast_pyobj(
work_reqs,
self.attn_tp_rank,
self.attn_tp_cpu_group,
src=attn_tp_rank_0,
)
if self.tp_size != 1:
control_reqs = broadcast_pyobj(
control_reqs, self.tp_rank, self.tp_cpu_group
)
recv_reqs = work_reqs + control_reqs
elif self.tp_size != 1:
recv_reqs = broadcast_pyobj(recv_reqs, self.tp_rank, self.tp_cpu_group)
return recv_reqs
class LogitsProcessor(nn.Module):
....
def _get_logits(
self,
hidden_states: torch.Tensor,
lm_head: VocabParallelEmbedding,
logits_metadata: LogitsMetadata,
embedding_bias: Optional[torch.Tensor] = None,
) -> torch.Tensor:
....
if self.do_tensor_parallel_all_gather:
logits = tensor_model_parallel_all_gather(logits)
....我们解释一下这里的两段代码,顺便做和vllm的方案做一个简单的辨析。
|
|
|
|---|---|
|
2. 每一次forward,all gather logits,这样所有rank 都拿到了准确的完整logits,自己sampling就可以获得token,获得token后,所有rank 就获得了一致的新输入进行下一轮forward |
2. forward 完,rank0 gather 其他rank的logits,经过sampling,获得新token,与之前tokens 拼接获得完整新输入 3. forward 开始前,将rank0 的输入broadcast到其他rank 上 |
至于sglang 需不需要和vllm 采取接近的逻辑呢,小弟正在尝试搞pr看看有没有收益)
Linear 层里的TP(基本模型通用)– WIP
这一部分核心代码在python/sglang/srt/layers/linear.py。目前的架构中,linear 承担了很大一部分modelparallelism的功能,allreduce/allgather 发生在这一层比较多,而sglang 为此单独做了一些抽象。
在linear 中,我们主要研究三个类:ReplicatedLinear, ColumnParallelLinear, RowParallelLinear。他们分别有着不同的功能,也是基本上所有模型都会用到的类。
ReplicatedLinear
这是最简单的linear层,几乎没有什么特别操作,与linearbase(基类基本一致)。介绍它主要是好区分和另外两类的差别。如下是replicatedLinear的forward实现,主要就是quant_method,如果有量化策略选择,就会进行对应的量化,否则默认走的是UnquantizedLinearMethod。
def forward(self, x: torch.Tensor) -> torch.Tensor:
bias = self.bias if not self.skip_bias_add else None
assert self.quant_method is not None
output = self.quant_method.apply(self, x, bias)
output_bias = self.bias if self.skip_bias_add else None
return output, output_bias既然是Linear,自然可以给tensor 塑形,也简单看看初始化接口)这里的塑形(input_size -> output_size)主要通过quant_method完成。
class ReplicatedLinear(LinearBase):
"""Replicated linear layer.
Args:
input_size: input dimension of the linear layer.
output_size: output dimension of the linear layer.
bias: If true, add bias.
skip_bias_add: If true, skip adding bias but instead return it.
params_dtype: Data type for the parameters.
quant_config: Quantization configure.
prefix: The name of the layer in the state dict, including all parents
(e.g. model.layers.0.qkv_proj)
"""RowParallelLinear & ColumnParallelLinear
现在我们可以聊一聊和TP 行为有关的linear了。先来一个简单的RowParallelLinear。
class RowParallelLinear(LinearBase):
# 如下注释已经比较清晰,RowParallelLinear 是按input 的dim0 进行分割来并行的
"""Linear layer with row parallelism.
The linear layer is defined as Y = XA + b. A is parallelized along
its first dimension and X along its second dimension as:
- -
| A_1 |
| . |
A = | . | X = [X_1, ..., X_p]
| . |
| A_p |
- -
Arguments:
input_size: first dimension of matrix A.
output_size: second dimension of matrix A.
bias: If true, add bias. Note that bias is not parallelized.
input_is_parallel: If true, we assume that the input is already
split across the GPUs and we do not split
again.
skip_bias_add: This was added to enable performance optimization where
bias can be fused with other element-wise operations.
We skip adding bias but instead return it.
params_dtype: Data type for the parameters.
quant_config: Quantization configure.
"""
def __init__(
self,
input_size: int,
output_size: int,
bias: bool = True,
input_is_parallel: bool = True, # 默认True,基本用默认
skip_bias_add: bool = False,
params_dtype: Optional[torch.dtype] = None,
# 是否用allreduce 进行聚合,看layer 的需要,比如deepseek里moe里的linear就不用reduce,但mlp需要
reduce_results: bool = True,
quant_config: Optional[QuantizationConfig] = None,
prefix: str = "",
tp_rank: Optional[int] = None,
tp_size: Optional[int] = None,
use_presharded_weights: bool = False,
):
super().__init__(
input_size, output_size, skip_bias_add, params_dtype, quant_config, prefix
)
self.input_is_parallel = input_is_parallel
self.reduce_results = reduce_results
# Divide the weight matrix along the last dimension.
if tp_rank is None:
tp_rank = get_tensor_model_parallel_rank()
if tp_size is None:
tp_size = get_tensor_model_parallel_world_size()
self.tp_rank, self.tp_size = tp_rank, tp_size
self.input_size_per_partition = divide(input_size, self.tp_size)
assert self.quant_method is not None
self.use_presharded_weights = use_presharded_weights
# 包括权重加载,其实也是按rowparallel的方式加载的(
self.quant_method.create_weights(
layer=self,
input_size_per_partition=self.input_size_per_partition,
output_partition_sizes=[self.output_size],
input_size=self.input_size,
output_size=self.output_size,
params_dtype=self.params_dtype,
weight_loader=(
self.weight_loader_v2
if self.quant_method.__class__.__name__ in WEIGHT_LOADER_V2_SUPPORTED
else self.weight_loader
),
)
.....
# 根据并行方式分片加载权重,也可以减少显存需要,减少服务拉起的时间
def weight_loader_v2(self, param: BasevLLMParameter, loaded_weight: torch.Tensor):
# Special case for loading scales off disk, which often do not
# have a shape (such as in the case of AutoFP8).
if len(loaded_weight.shape) == 0:
assert loaded_weight.numel() == 1
loaded_weight = loaded_weight.reshape(1)
if isinstance(param, RowvLLMParameter):
# This `BasevLLMParameter` is defined in sglang/srt/layers/parameter.py,
# It supports additional parameters like tp_rank and use_presharded_weights.
param.load_row_parallel_weight(
loaded_weight,
tp_rank=self.tp_rank,
use_presharded_weights=self.use_presharded_weights,
)
else:
# `params` is defined in `vllm/model_executor/parameter.py`,
# It does not support additional parameters.
param.load_row_parallel_weight(loaded_weight)
# 核心执行函数forward, 这里只需要注意两个地方,输入的切分和reduce的部分
def forward(self, input_):
if self.input_is_parallel: # 基本上都走这边,默认上层模型层灰处理好
input_parallel = input_
else: # 否则需要自己切一下
splitted_input = split_tensor_along_last_dim(
input_, num_partitions=self.tp_size
)
input_parallel = splitted_input[self.tp_rank].contiguous()
# Matrix multiply.
assert self.quant_method is not None
# Only fuse bias add into GEMM for rank 0 (this ensures that
# bias will not get added more than once in TP>1 case)
bias_ = None if (self.tp_rank > 0 or self.skip_bias_add) else self.bias
output_parallel = self.quant_method.apply(self, input_parallel, bias=bias_)
# 对于mlp层,基本都需要进行allreduce,all_reduce 行为本身也不会增加显存,只是累加
if self.reduce_results and self.tp_size > 1:
output = tensor_model_parallel_all_reduce(output_parallel)
else:
output = output_parallel
output_bias = self.bias if self.skip_bias_add else None
return output, output_bias另一个对应的linear 是ColumnParallelLinear。下图是sglang对其的注释,其实row和column的区别就在于是按第dim 0 还是dim 1 进行分割。该class的参数与RowParallelLinear 类似。
class ColumnParallelLinear(LinearBase):
"""Linear layer with column parallelism.
The linear layer is defined as Y = XA + b. A is parallelized along
its second dimension as A = [A_1, ..., A_p].其forward 接口如下,逻辑也和上述类似。
def forward(self, input_):
bias = self.bias if not self.skip_bias_add else None
# Matrix multiply.
assert self.quant_method is not None
output_parallel = self.quant_method.apply(self, input_, bias)
# 我们尤其注意这个分支,在这里可能会进行一次allgather,进行tp之间的同步
# 不过默认gather_output为False,而且目前没有模型设置为True
if self.gather_output:
# All-gather across the partitions.
output = tensor_model_parallel_all_gather(output_parallel)
else:
output = output_parallel
output_bias = self.bias if self.skip_bias_add else None
return output, output_biascolumnParallelLinear 还有2个子类,MergedColumnParallelLinear 与 QKVParallelLinear。三者区别如下:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
不过,我们需要注意一点,RowParallelLinear 中的allreduce 不会增加显存占用,默认情况下columnParallelLinear 中all_gather 也不会用,所以TP 本身几乎不会增加显存占用,仅仅是logits all_gather 的部分存在一定的显存增加,不过相比kvcache,logits的占用是很小的(一般主要取决于vocab_table size)。
deepseek 里Linear TP
deepseek 模型架构含61层如下, 其中前3层layer 是传统结构,后58层 的MLP 转换成了MoE。另外需要关注架构里transfromer 无关的vocabParallelEmbedding 层,权重也会按tp 分开,也包含一层all_reduce。
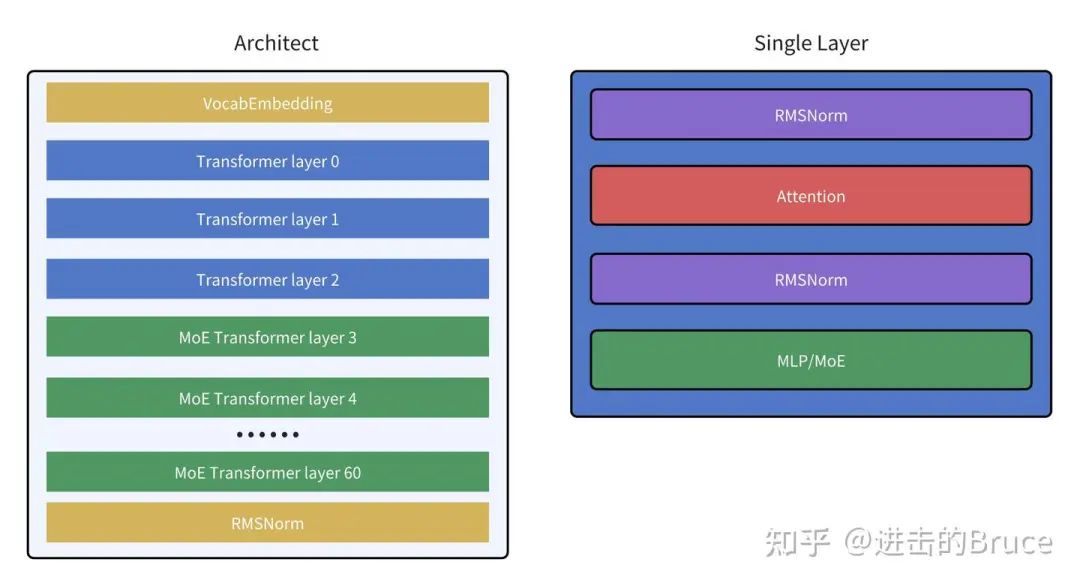
这里我们先不管两层layernorm,专注于Attention和MLP/MoE的部分。接下来我们分别看看MLP,MoE和Attention 中的linear层的结构,如下图,注意浅绿色的块说明不存在通信操作,仅仅与tp有关(比如weight 按tp 切分),蓝色说明与tp 无关,绿色说明包含通信操作且与tp 有关,注意在默认情况下,依据目前的代码,tp 只会引入allreduce 这一层通信操作,不会导致显存额外增加。与上图结合,可以发现一层layer 只会在layer 最末进行一次allreduce。

然而,上述只是input 没有根据tp scatter的情况,即所有tp 看到的都是一份完整的query,但是还有一种模式,即input query 也根据tp 进行了切分,此时便又多了一些细节。我们基于下述代码进行解读, 我们只关注tp 相关的代码。
def forward_ffn_with_scattered_input(
self,
positions: torch.Tensor,
hidden_states: torch.Tensor,
forward_batch: ForwardBatch,
residual: Optional[torch.Tensor],
zero_allocator: BumpAllocator,
) -> torch.Tensor:
....
# 注意这里虽然有all_gather 行为,但是实际使用的hiddenstates 显存还是对齐到完整的seqlen
# all_gather 的对象是tensor_split后的分片,组合在一起依旧只是一个完整的seqlen,之后同理
if self.attn_tp_size != 1 and self.input_is_scattered:
hidden_states, local_hidden_states = (
forward_batch.gathered_buffer[: forward_batch.input_ids.shape[0]],
hidden_states,
)
tp_all_gather(
list(hidden_states.tensor_split(self.attn_tp_size)), local_hidden_states
)
# Self Attention
hidden_states = self.self_attn(
positions=positions,
hidden_states=hidden_states,
forward_batch=forward_batch,
zero_allocator=zero_allocator,
)
if self.attn_tp_size != 1:
if self.input_is_scattered:
tensor_list = list(hidden_states.tensor_split(self.attn_tp_size))
hidden_states = tensor_list[self.attn_tp_rank]
# 累加后scatter 分片
tp_reduce_scatter(hidden_states, tensor_list)
if hidden_states.shape[0] != 0:
hidden_states, residual = self.post_attention_layernorm(
hidden_states, residual
)
else:
if self.attn_tp_rank == 0:
hidden_states += residual
tensor_list = list(hidden_states.tensor_split(self.attn_tp_size))
hidden_states = tensor_list[self.attn_tp_rank]
tp_reduce_scatter(hidden_states, tensor_list)
residual = hidden_states
if hidden_states.shape[0] != 0:
hidden_states = self.post_attention_layernorm(hidden_states)
else:
if hidden_states.shape[0] != 0:
hidden_states, residual = self.post_attention_layernorm(
hidden_states, residual
)
if not (
self._enable_moe_dense_fully_dp()
and (not self.info.is_sparse)
and hidden_states.shape[0] == 0
):
hidden_states = self.mlp(hidden_states, forward_batch.forward_mode)
# 如果是最后一层layer 额外进行一次allgather,组合成完整的seq
if self.is_last_layer and self.attn_tp_size != 1:
hidden_states += residual
residual = None
hidden_states, local_hidden_states = (
forward_batch.gathered_buffer[: forward_batch.input_ids.shape[0]],
hidden_states,
)
tp_all_gather(
list(hidden_states.tensor_split(self.attn_tp_size)), local_hidden_states
)
return hidden_states, residualDP的实现
在sglang中,DP 是另一个重要且成熟的并行策略。
DP 实现的架构
在DP 实现的架构中,存在另一个关键进程,DataParallelController。大家可以比较和没有dp(dp=1)下的差别,多了一层dp_controller的代理,dp_controller 承接tokenizer 过来的请求并dispatch 给dp 下的tp_worker(scheduler)。在dp = 1下,这层代理没有必要,所以没有这个进程。
dispatch_lookup = {
LoadBalanceMethod.ROUND_ROBIN: self.round_robin_scheduler,
LoadBalanceMethod.SHORTEST_QUEUE: self.shortest_queue_scheduler,
}同时dp 的dispatch 支持两种模式目前,分别是round_robin 和 SHORTEST_QUEUE。
dp的初始化
dp 的初始化实际上主要就是dp controller的初始化过程。scheduler 中也有部分逻辑,不过注意,一个sglang engine 全局只有一个 DataParallelController。
def run_data_parallel_controller_process(
server_args: ServerArgs,
port_args: PortArgs,
pipe_writer,
):
# 获取进程信息和设置logger
setproctitle.setproctitle("sglang::data_parallel_controller")
configure_logger(server_args)
parent_process = psutil.Process().parent()
try:
# 初始化
controller = DataParallelController(server_args, port_args)
# 初始化完成后进行同步
pipe_writer.send(
{
"status": "ready",
"max_total_num_tokens": controller.max_total_num_tokens,
"max_req_input_len": controller.max_req_input_len,
}
)
# while 循环等请求来
if server_args.node_rank == 0:
controller.event_loop()
# 进程退出的处理
for proc in controller.scheduler_procs:
proc.join()
logger.error(
f"Scheduler or DataParallelController {proc.pid} terminated with {proc.exitcode}"
)
except Exception:
# 异常后的捕获,注意是往父进程发sigquit,所以会停止整个sglang的进程
traceback = get_exception_traceback()
logger.error(f"DataParallelController hit an exception: {traceback}")
parent_process.send_signal(signal.SIGQUIT)
# Launch the data parallel controller
# 注意没有range(dp_size) 的循环,所以只调用一次,所以只有一个dp controller
reader, writer = mp.Pipe(duplex=False)
scheduler_pipe_readers = [reader]
proc = mp.Process(
target=run_data_parallel_controller_process,
args=(server_args, port_args, writer),
)
proc.start()
scheduler_procs.append(proc)接下来是dp controller 自己的初始化。其中zmq 通信环路的构建和进程关系是一个重点,这一部分直接看上面的架构图即可。
# 从配置信息处获取dp之间负载均衡的方法
self.load_balance_method = LoadBalanceMethod.from_str(
server_args.load_balance_method
)
# Dispatch method
self.round_robin_counter = 0
dispatch_lookup = {
LoadBalanceMethod.ROUND_ROBIN: self.round_robin_scheduler,
LoadBalanceMethod.SHORTEST_QUEUE: self.shortest_queue_scheduler,
}
self.dispatching = dispatch_lookup[self.load_balance_method]
# 每个dp controller,会负责拉起相对tp 数量的scheduler 进程
# 注意total_tp_size = dp_size * tp_size_per_dp,上述说的是tp_size_per_dp
# Launch data parallel workers
self.scheduler_procs = []
self.workers = [None] * server_args.dp_size
if server_args.enable_dp_attention:
dp_port_args = self.launch_dp_attention_schedulers(server_args, port_args)
self.control_message_step = server_args.tp_size
else:
dp_port_args = self.launch_dp_schedulers(server_args, port_args)
self.control_message_step = 1这里最关键的是launch_dp_schedulers,具体scheduler的进程(tp/pp worker)通过launch_tensor_parallel_group_thread完成,不过launch_dp_schedulers 里为不同的dp group 划分了通信空间(通过zmq)。
def launch_dp_schedulers(self, server_args, port_args):
base_gpu_id = 0 # 每个dp group 内的基础gpu id,用于计算dp 可用的gpu
threads = []
sockets = []
dp_port_args = []
ready_events = []
for dp_rank in range(server_args.dp_size):
# 注意PortArgs.init_new 这个接口,会生成一组新的port_args,所以不同dp group 用的port_args 不同
# 所以不同的dp group 所在的zmq 空间不同,不会互相干扰
tmp_port_args = PortArgs.init_new(server_args)
tmp_port_args.tokenizer_ipc_name = port_args.tokenizer_ipc_name
tmp_port_args.detokenizer_ipc_name = port_args.detokenizer_ipc_name
dp_port_args.append(tmp_port_args)
# This port is checked free in PortArgs.init_new.
# We hold it first so that the next dp worker gets a different port
sockets.append(bind_port(tmp_port_args.nccl_port))
ready_event = threading.Event()
ready_events.append(ready_event)
# Create a thread for each worker,可以看文章一scheduler 初始化的逻辑,基本一致
thread = threading.Thread(
target=self.launch_tensor_parallel_group_thread,
args=(server_args, tmp_port_args, base_gpu_id, dp_rank, ready_event),
)
threads.append(thread)
# 根据dp size 计算不同dp group的初始gpu_id
base_gpu_id += server_args.tp_size * server_args.gpu_id_step
# Free all sockets before starting the threads to launch TP workers
for sock in sockets:
sock.close()
# Start all threads
for thread in threads:
thread.start()
for event in ready_events:
event.wait()
return dp_port_argsdp 的使用
我们先关注dp controller的行为,主要是event_loop。controller 从 tokenizer 拿到请求后,如果是常规输入请求(TokenizedGenerateReqInput, TokenizedEmbeddingReqInput),会通过roundrobin 调度到合适的dp_group 上,如果是pd 分离,roundrobin 在上层就做好了,所以不需要dp controller 来决定具体去哪个dp group,用req.bootstrap_room 就行。如果是非常规的输入请求,会每个dp group 发一次请求。
def round_robin_scheduler(self, req: Req):
if self.server_args.disaggregation_mode == "null":
self.workers[self.round_robin_counter].send_pyobj(req)
self.round_robin_counter = (self.round_robin_counter + 1) % len(
self.workers
)
else:
self.workers[req.bootstrap_room % len(self.workers)].send_pyobj(req)
def shortest_queue_scheduler(self, input_requests):
raise NotImplementedError()
def event_loop(self):
while True:
while True:
try:
recv_req = self.recv_from_tokenizer.recv_pyobj(zmq.NOBLOCK)
except zmq.ZMQError:
break
if isinstance(
recv_req,
(
TokenizedGenerateReqInput,
TokenizedEmbeddingReqInput,
),
):
self.dispatching(recv_req)
else:
# Send other control messages to first worker of tp group
for worker in self.workers[:: self.control_message_step]:
worker.send_pyobj(recv_req)dp-attention 的实现
dp-attention 在初始化时,不会分割成多个dp group的空间,而是统一成一个DP group。该dp group内scheduler 再去按dp,tp的维度划分。
def launch_dp_attention_schedulers(self, server_args, port_args):
self.launch_tensor_parallel_group(server_args, port_args, 0, None)
dp_port_args = []
for dp_rank in range(server_args.dp_size):
dp_port_args.append(PortArgs.init_new(server_args, dp_rank))
return dp_port_args而scheduler 对dp attention的逻辑则为:
# Distributed rank info
self.attn_tp_rank, self.attn_tp_size, self.dp_rank = (
compute_dp_attention_world_info(
server_args.enable_dp_attention,
self.tp_rank,
self.tp_size,
self.dp_size,
)
)
# attn_tp_size 是tp_size 的一个相对偏移,可以理解为dp_attn 下dp_size 由scheudler 自己管理
def compute_dp_attention_world_info(enable_dp_attention, tp_rank, tp_size, dp_size):
if not enable_dp_attention:
return tp_rank, tp_size, 0
attn_tp_size = tp_size // dp_size
dp_rank = tp_rank // attn_tp_size
attn_tp_rank = tp_rank % attn_tp_size
return attn_tp_rank, attn_tp_size, dp_rankdp_attn 和 一般attn tp 并行的区别基本上就在这里,dp_attn 下world_size 更大。
非dp_attn scheduler 内nccl 通信的world_size = tp_size
dp_attn下,则为world_size = tp_size*dp_sizeEP 的实现-Deepseek 的例子(WIP)
ep 即 expert parallel。仅限于MoE的模型可用,想要了解ep 的一些概念和细节。可以参考我之前的进击的Bruce:速读 deepseek v2(二) —— 理解DeepSeekMoE(https://zhuanlan.zhihu.com/p/698803333)。本期我们主要介绍deepseekv3下的ep moe 逻辑。
在讨论差异之前,我们看看shared_experts的情况,我们知道deepseek的expert 包含两种expert,一种shared_experts,一种routed_experts,而ep 仅仅和后者相关,前者在实现上只是MLP而已,如下。
self.shared_experts = DeepseekV2MLP(
hidden_size=config.hidden_size,
intermediate_size=intermediate_size,
hidden_act=config.hidden_act,
quant_config=quant_config,
reduce_results=False,
prefix=add_prefix("shared_experts", prefix),
)而routed experts 则包含三种实现,默认FusedMoE,EPMoE是sglang内置的EP方式,DeepEPMoE 是集成了DeepEP(Deepseek EP 开源库)的方式。
MoEImpl = (
DeepEPMoE
if global_server_args_dict["enable_deepep_moe"]
else (EPMoE if global_server_args_dict["enable_ep_moe"] else FusedMoE)
)FusedMoe的情况
从简单的开始,最简单的事fusedmoe的情况,也就是没有ep的情况,然后我们可以比较ep 下的差异。
先看一下model 调用FusedMoE的姿势。
self.experts = MoEImpl(
# 专家总数量
num_experts=config.n_routed_experts + self.n_share_experts_fusion,
# 单token 激活的top_k 专家数量
top_k=config.num_experts_per_tok + min(self.n_share_experts_fusion, 1),
hidden_size=config.hidden_size,
intermediate_size=config.moe_intermediate_size,
renormalize=config.norm_topk_prob,
# 量化方法,如果没有量化,就是普通fusedMoE 的配置
quant_config=quant_config,
# 跨领域分组之间可以动态组合专家,可以增加模型表达能力
use_grouped_topk=True,
# 专家分组,可以使模型表现范畴更广,特别是需要一些低频预分组的情况
num_expert_group=config.n_group,
topk_group=config.topk_group,
correction_bias=self.gate.e_score_correction_bias,
routed_scaling_factor=self.routed_scaling_factor,
prefix=add_prefix("experts", prefix),
**(
dict(deepep_mode=DeepEPMode[global_server_args_dict["deepep_mode"]])
if global_server_args_dict["enable_deepep_moe"]
else {}
),
)接下来我们看看FusedMoE内部的几个关键函数。先看一下初始化,其他基本是赋值。
# 默认量化就是UnquantizedFusedMoEMethod,也是一种FusedMoE实现,基类是nn.module
ifquant_configisNone:
self.quant_method:Optional[QuantizeMethodBase]=(
UnquantizedFusedMoEMethod()
)
else:
# 实际上呢,deepseek 走的是Fp8MoEMethod,请大家注意这点,deepseek 默认fp8
self.quant_method=quant_config.get_quant_method(self,prefix)
assertself.quant_methodisnotNone
# 这里是量化方法赋权重
self.quant_method.create_weights(
layer=self,
num_experts=num_experts,
hidden_size=hidden_size,
# FIXME: figure out which intermediate_size to use
intermediate_size=self.intermediate_size_per_partition,
intermediate_size_per_partition=self.intermediate_size_per_partition,
params_dtype=params_dtype,
weight_loader=self.weight_loader,
)接下来我们看看Fp8MoEMethod。主要看看apply 接口就行,MoeMethod apply主体逻辑都比较接近。
def apply(
self,
layer: torch.nn.Module,
x: torch.Tensor,
router_logits: torch.Tensor, # 这里是gate获得的logits
top_k: int,
renormalize: bool,
use_grouped_topk: bool,
topk_group: Optional[int] = None,
num_expert_group: Optional[int] = None,
custom_routing_function: Optional[Callable] = None,
correction_bias: Optional[torch.Tensor] = None,
activation: str = "silu",
apply_router_weight_on_input: bool = False,
# inplace 用于高性能,outplace 用于训练等计算安全性比较高的场景,sglang选高性能inplace
inplace: bool = True,
# nocombine 即只融合计算过程,不融合计算结果,sglang 默认不用,融合计算结果更快
no_combine: bool = False,
routed_scaling_factor: Optional[float] = None,
) -> torch.Tensor:
from sglang.srt.layers.moe.fused_moe_triton.fused_moe import fused_experts
from sglang.srt.layers.moe.topk import select_experts
# 实现上,基于gate获得的router_logits和系统配置
# 选择合适的专家,然后送入fusedexpert 模块
# Expert selection
topk_weights, topk_ids = select_experts(
hidden_states=x,
router_logits=router_logits,
use_grouped_topk=use_grouped_topk,
top_k=top_k,
renormalize=renormalize,
topk_group=topk_group,
num_expert_group=num_expert_group,
custom_routing_function=custom_routing_function,
correction_bias=correction_bias,
routed_scaling_factor=routed_scaling_factor,
)
return fused_experts(
x,
layer.w13_weight,
layer.w2_weight,
topk_weights=topk_weights,
topk_ids=topk_ids,
inplace=inplace and not no_combine,
activation=activation,
apply_router_weight_on_input=apply_router_weight_on_input,
use_fp8_w8a8=True,
w1_scale=(
layer.w13_weight_scale_inv
if self.block_quant
else layer.w13_weight_scale
),
w2_scale=(
layer.w2_weight_scale_inv if self.block_quant else layer.w2_weight_scale
),
a1_scale=layer.w13_input_scale,
a2_scale=layer.w2_input_scale,
block_shape=self.quant_config.weight_block_size,
no_combine=no_combine,
)由于本次目的不是分析kernel,只是分析ep,所以仅仅再看看select_experts 的行为。select_experts 有不同的策略,deepseek 使用的是grouped_topk,所以我们直接看这一分支的实现。
@torch.compile(dynamic=True, backend=get_compiler_backend())
def grouped_topk(
hidden_states: torch.Tensor,
gating_output: torch.Tensor,
topk: int,
renormalize: bool,
num_expert_group: int = 0,
topk_group: int = 0,
n_share_experts_fusion: int = 0,
routed_scaling_factor: Optional[float] = None,
):
assert hidden_states.shape[0] == gating_output.shape[0], "Number of tokens mismatch"
scores = torch.softmax(gating_output, dim=-1)
num_token = scores.shape[0]
num_experts = scores.shape[1]
# 获得group 层面的score,因为deepseek 专家是分组的,先挑出合适的topk_group个组
group_scores = (
scores.view(num_token, num_expert_group, -1).max(dim=-1).values
) # [n, n_group]
# 选出topk_group 个分组
group_idx = torch.topk(group_scores, k=topk_group, dim=-1, sorted=False)[
1
] # [n, top_k_group]
# 做mask 过滤掉没被选中的group,获得新的scores
group_mask = torch.zeros_like(group_scores) # [n, n_group]
group_mask.scatter_(1, group_idx, 1) # [n, n_group]
score_mask = (
group_mask.unsqueeze(-1)
.expand(num_token, num_expert_group, scores.shape[-1] // num_expert_group)
.reshape(num_token, -1)
) # [n, e]
tmp_scores = scores.masked_fill(~score_mask.bool(), 0.0) # [n, e]
# 在留下的分组中选择topk 个expert(注意是全局选择,不是各组内选topk 然后融合)
topk_weights, topk_ids = torch.topk(tmp_scores, k=topk, dim=-1, sorted=False)
# 融合共享专家和归一化操作
if n_share_experts_fusion:
topk_ids[:, -1] = torch.randint(
low=num_experts,
high=num_experts + n_share_experts_fusion,
size=(topk_ids.size(0),),
dtype=topk_ids.dtype,
device=topk_ids.device,
)
topk_weights[:, -1] = topk_weights[:, :-1].sum(dim=-1) / routed_scaling_factor
if renormalize:
topk_weights_sum = (
topk_weights.sum(dim=-1, keepdim=True)
if n_share_experts_fusion == 0
else topk_weights[:, :-1].sum(dim=-1, keepdim=True)
)
topk_weights = topk_weights / topk_weights_sum
return topk_weights.to(torch.float32), topk_ids.to(torch.int32)EpMoE的情况
有了FusedMoE的理解,我们可以进一步理解EPMoE的逻辑了。类型初始化如下:
if params_dtype is None:
params_dtype = torch.get_default_dtype()
self.tp_size = (
tp_size if tp_size is not None else get_tensor_model_parallel_world_size()
)
self.tp_rank = get_tensor_model_parallel_rank()
# 注意:expert num 应该可以被tp_size 整除
self.num_experts = num_experts
assert self.num_experts % self.tp_size == 0
# 决定每个tp worker上能有多少expert,以及每个tp worker 上起始的expert id,结束的expert_id
self.num_experts_per_partition = self.num_experts // self.tp_size
self.start_expert_id = self.tp_rank * self.num_experts_per_partition
self.end_expert_id = self.start_expert_id + self.num_experts_per_partition - 1
self.top_k = top_k
self.intermediate_size = intermediate_size
self.renormalize = renormalize
self.use_grouped_topk = use_grouped_topk
if self.use_grouped_topk:
assert num_expert_group is not None and topk_group is not None
self.num_expert_group = num_expert_group
self.topk_group = topk_group
self.correction_bias = correction_bias
self.custom_routing_function = custom_routing_function
self.activation = activation
self.routed_scaling_factor = routed_scaling_factor
if quant_config is None:
self.quant_method: Optional[QuantizeMethodBase] = UnquantizedEPMoEMethod()
self.use_fp8_w8a8 = False
self.use_block_quant = False
self.block_shape = None
self.activation_scheme = None
else:
# deepseek 会走 Fp8EPMoEMethod
self.quant_method: Optional[QuantizeMethodBase] = Fp8EPMoEMethod(
quant_config
)
self.use_fp8_w8a8 = True
self.use_block_quant = getattr(self.quant_method, "block_quant", False)
self.block_shape = (
self.quant_method.quant_config.weight_block_size
if self.use_block_quant
else None
)
self.fp8_dtype = torch.float8_e4m3fn
self.activation_scheme = quant_config.activation_scheme
self.quant_method.create_weights(
layer=self,
num_experts_per_partition=self.num_experts_per_partition, #按tp切分后加载权重
hidden_size=hidden_size,
intermediate_size=self.intermediate_size,
params_dtype=params_dtype,
weight_loader=self.weight_loader,
)
self.grouped_gemm_runner = None初始化的部分没有太多特殊,接下来主要看forward接口,Fp8EPMoEMethod的quant_method apply没有实现, 固暂不细论。
def forward(self, hidden_states: torch.Tensor, router_logits: torch.Tensor):
assert self.quant_method is not None
# moe 计算采用 groupedgemm,所以先初始化groupedgemmRunner
if self.grouped_gemm_runner is None:
self.grouped_gemm_runner = GroupedGemmRunner(
hidden_states.device,
use_flashinfer=False, # TODO: use flashinfer
)
# 同fusedMoE的实现,注意group expert的处理就行
topk_weights, topk_ids = select_experts(
hidden_states=hidden_states,
router_logits=router_logits,
top_k=self.top_k,
use_grouped_topk=self.use_grouped_topk,
renormalize=self.renormalize,
topk_group=self.topk_group,
num_expert_group=self.num_expert_group,
correction_bias=self.correction_bias,
custom_routing_function=self.custom_routing_function,
routed_scaling_factor=self.routed_scaling_factor,
)
# 由于moe的实现采用了groupedGemm,select expert 获得的数组里 expert和token 数据排列不一定计算友好
# 所以需要进行一次重排,从token 连续的布局改成expert 连续的布局
reorder_topk_ids, src2dst, seg_indptr = run_moe_ep_preproess(
topk_ids, self.num_experts
)
gateup_input = torch.empty(
(int(hidden_states.shape[0] * self.top_k), hidden_states.shape[1]),
device=hidden_states.device,
dtype=(
self.fp8_dtype
if (self.use_fp8_w8a8 and not self.use_block_quant)
else hidden_states.dtype
),
)
if self.activation_scheme == "dynamic" and not self.use_block_quant:
max_value = (
torch.max(hidden_states)
.repeat(self.num_experts_per_partition)
.to(torch.float32)
)
self.w13_input_scale = max_value / torch.finfo(self.fp8_dtype).max
# PreReorder
pre_reorder_triton_kernel[(hidden_states.shape[0],)](
hidden_states,
gateup_input,
src2dst,
topk_ids,
self.w13_input_scale,
self.start_expert_id,
self.end_expert_id,
self.top_k,
hidden_states.shape[1],
BLOCK_SIZE=512,
)
seg_indptr_cur_rank = seg_indptr[self.start_expert_id : self.end_expert_id + 2]
weight_indices_cur_rank = torch.arange(
0,
self.num_experts_per_partition,
device=hidden_states.device,
dtype=torch.int64,
)
# 两次gemm 获得output,第一次计算gateup,第二次计算down,moe 每个expert也是mlp结构
# GroupGemm-0
gateup_output = torch.empty(
gateup_input.shape[0],
self.w13_weight.shape[1],
device=hidden_states.device,
dtype=hidden_states.dtype,
)
gateup_output = self.grouped_gemm_runner(
a=gateup_input,
b=self.w13_weight,
c=gateup_output,
batch_size=self.num_experts_per_partition,
weight_column_major=True,
seg_indptr=seg_indptr_cur_rank,
weight_indices=weight_indices_cur_rank,
use_fp8_w8a8=self.use_fp8_w8a8,
scale_a=self.w13_input_scale,
scale_b=(
self.w13_weight_scale_inv
if self.use_block_quant
else self.w13_weight_scale
),
block_shape=self.block_shape,
)
# Act
down_input = torch.empty(
gateup_output.shape[0],
gateup_output.shape[1] // 2,
device=gateup_output.device,
dtype=(
self.fp8_dtype
if (self.use_fp8_w8a8 and not self.use_block_quant)
else hidden_states.dtype
),
)
if self.w2_input_scale is None and not self.use_block_quant:
self.w2_input_scale = torch.ones(
self.num_experts_per_partition,
dtype=torch.float32,
device=hidden_states.device,
)
if self.activation == "silu":
silu_and_mul_triton_kernel[(gateup_output.shape[0],)](
gateup_output,
down_input,
gateup_output.shape[1],
reorder_topk_ids,
self.w2_input_scale,
self.start_expert_id,
self.end_expert_id,
BLOCK_SIZE=512,
)
elif self.activation == "gelu":
gelu_and_mul_triton_kernel[(gateup_output.shape[0],)](
gateup_output,
down_input,
gateup_output.shape[1],
reorder_topk_ids,
self.w2_input_scale,
self.start_expert_id,
self.end_expert_id,
BLOCK_SIZE=512,
)
else:
raise ValueError(f"Unsupported activation: {self.activation=}")
# GroupGemm-1
down_output = torch.empty(
down_input.shape[0],
self.w2_weight.shape[1],
device=hidden_states.device,
dtype=hidden_states.dtype,
)
down_output = self.grouped_gemm_runner(
a=down_input,
b=self.w2_weight,
c=down_output,
batch_size=self.num_experts_per_partition,
weight_column_major=True,
seg_indptr=seg_indptr_cur_rank,
weight_indices=weight_indices_cur_rank,
use_fp8_w8a8=self.use_fp8_w8a8,
scale_a=self.w2_input_scale,
scale_b=(
self.w2_weight_scale_inv
if self.use_block_quant
else self.w2_weight_scale
),
block_shape=self.block_shape,
)
# PostReorder
# 进行重排,从expert 连续布局改成token 连续布局,和输入的布局一致用于输出呈现
output = torch.empty_like(hidden_states)
post_reorder_triton_kernel[(hidden_states.size(0),)](
down_output,
output,
src2dst,
topk_ids,
topk_weights,
self.start_expert_id,
self.end_expert_id,
self.top_k,
hidden_states.size(1),
BLOCK_SIZE=512,
)
return output看完有点奇怪,看着是看完了,但是parallelism 体现在哪呢?定睛一看,这里所有计算过程中的expert_id 都是ep 初始化的时候定好的start_expert_id和end_expert_id。
DeepEPMoE的情况(WIP)
EPLB的情况(含对deepseek 冗余专家的讨论)
PP 的实现
– The End –

长按二维码关注我们
本公众号专注:
1. 技术分享;
2. 学术交流;
3. 资料共享。
欢迎关注我们,一起成长!
(文:GiantPandaCV)