

今天是2025年5月21日,星期三,北京,晴。
昨天(2025.05.20)晚上,我在计算机学会CCF中做了《文档智能+知识图谱驱动大模型推理落地的一些思考》的报告,内容信息量不少,把最近的一些感悟进行了总结性汇报,这也是从2022年以来,第三次作客,一年一次,来讲讲自己的一些思考。
另一个,在Embedding向量化、大模型推理及强化学习也出来了一些新东西,包括不同领域的Embedding向量化开源进展、大模型推理采样策略实验的对比等,都是值得关注的点。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、知识图谱落地大模型推理的一些思考
昨天(2025.05.20)晚上,我在计算机学会CCF中做了《文档智能+知识图谱驱动大模型推理落地的一些思考》的报告,内容信息量不少,把最近的一些感悟进行了总结性汇报,挺好的,这也是从2022年以来,第三次作客,一年一次。

下面择几个重点做记录。
实际上,知识图谱目前在工业界落地时很受挑战的,这个是大背景,所以,知识图谱要继续往后发展,就需要逐步找到其立足的小点,然后和业务研发中其他技术的一些不足的点去做。
最近一年,都在做文档智能的事情,在自研大模型、回归业务线之后,在尝试探索图谱在落地中的可能性。
我将这个归为三个点。
一个是文档智能解决领域知识图谱建设的初始化问题,一个是基于知识图谱来合成大模型推理(RAG)数据,一个是利用知识图谱规范化引导大模型推理。
1、文档智能解决领域知识图谱建设的初始化问题
文档智能目前因为RAG的应用而受到广泛关注,其本身是作为解决知识库的文本解析问题,从而用于召回的,但说到召回,那就会必然涉及到召回对象的单元化、关联化问题,所以,很自然的,文档智能就能够解决这种原始数据标准化、数据原子单位的抽取和关联构建问题。

例如:
文档Graph化-布局分析抽离图谱节点,目标检测任务,用于对文档进行区域划分,核心在于标签的定义:正文、标题、图片、图片标题、表格、表格标题、页眉、页脚、注释、公式等,也可以是化学式、分子结构式等;
图表Graph化-FlowChartParser,流程图解析,做多种任务处理操作,如文本转流程图、流程图转文本、流程图转markdown、流程图QA等;文档层级Graph化-DocGraph,经过布局分析,进行区域间关系(Inter-region relationship)抽取,如一个表格与其相应的标题、来源、引用段落、所属章节之间的关系;
层级逻辑关系包括标题、小节标题、段落等;文档层级Graph化-Doc2Toc,在接受文档阅读顺序之后,可方便对页面进行层级表示(Doc2TOC),如一级标题、二级标题、图表所属章节信息等;图文Graph化-FigureBackLink解决问题;文档在进行表述时候,图表会作为一个链接元素被引用于文本描述当中,在RAG中常常会出现这类情况:一个问题召回出来的片段里,有xxxxxx,详见表1。这种问题本质上属于多跳情况。解决方式,采用与知识图谱Entity-linking的方式,在原文中进行图表的链接。
2、基于知识图谱来合成大模型推理(RAG)数据
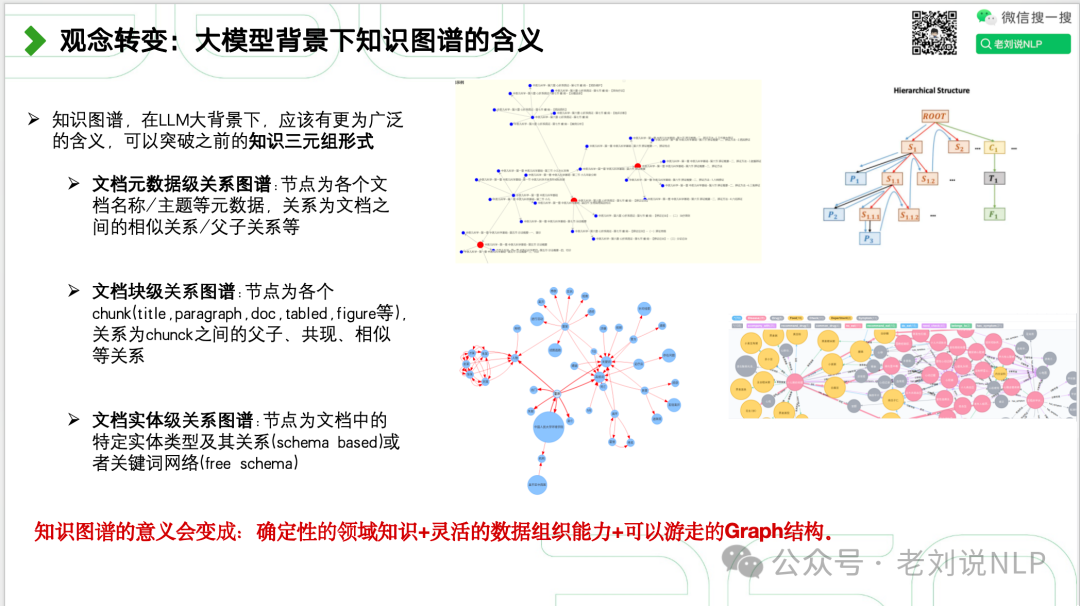
知识图谱,在LLM大背景下,应该有更为广泛的含义,可以突破之前的知识三元组形式,其需要发生变化,
例如:
文档元数据级关系图谱:节点为各个文档名称/主题等元数据,关系为文档之间的相似关系/父子关系等;
文档块级关系图谱:节点为各个chunk(title,paragraph,doc,tabled,figure等),关系为chunck之间的父子、共现、相似等关系;
文档实体级关系图谱:节点为文档中的特定实体类型及其关系(schema based)或者关键词网络(free schema);
基于这个点,知识图谱用于推理数据生成,其技术支撑逻辑在于:知识抽取与结构化表示、推理路径生成、多模态数据融合、动态数据合成、验证与纠错。因此,会有四种方案。
一种是Graph-RAG方案。将知识图谱与RAG结合,通过结构化的实体和关系来增强推理能力。涉及到从知识图谱中提取多跳关系和因果链,生成复杂的推理数据。比如,知识图谱能帮助模型在多个文档跳跃,并结合非结构化图谱信息,合成全局信息。
一种是QA对反推合成方案。MedReason,使用子图检索和CoT(Chain-of-Thought)合成数据合成,构建子图并设计推理路径作为训练数据。或者直接指定推理规则进行推理。
一种是多模态合成方案。 知识图谱用于增强数据标注、提升泛化能力和多模态融合。利用图谱中的实体关系对原始数据进行增强,生成多样化的推理样本。文本有的时候并不能完整地描述详尽信息,多模态大模型的存在,可以将文本形式信息和图像形式信息进进行link处理,从而提升推理性能。
一种是图谱控制式合成方案。基于知识图谱控制多跳、单跳,来控制多样化推理数据。
一种是融合COT+NLI+KG混合合成方案。强强联合去噪。
3、利用知识图谱规范化引导大模型推理
这个是在应用端,主要用知识图谱来规范化引导大模型推理,例如:
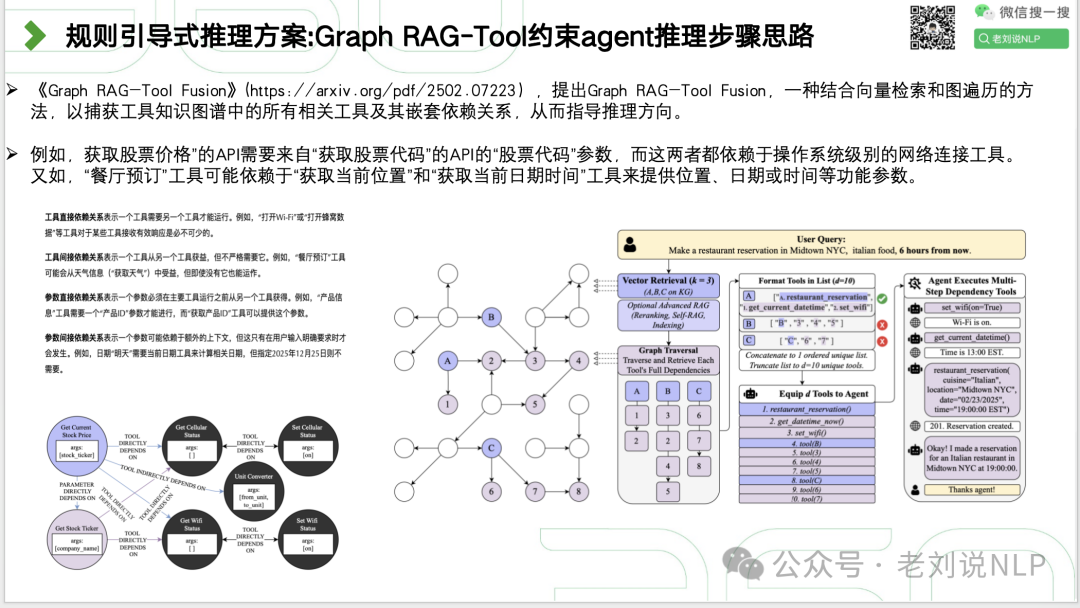
规则引导式推理方案:RuleRAG直接指定因果规则进行推理,核心在于规则库R:包含了用于指导检索和生成的规则,这些规则以自然语言形式表达,如“[实体1, r1, 实体2] 导致 [实体1, r2, 实体2]”;
Graph RAG-Tool约束agent推理,,结合向量检索和图遍历的方法,以捕获工具知识图谱中的所有相关工具及其嵌套依赖关系,从而指导推理方向。
4、进一步的思考
当然,这里也会有一些思考。关于知识图谱在参与知识推理数据合成的事情。
首先,从生成阶段看:
基于知识图谱进行上下文,无论是GraphRAG式、还是QA对式、还是多模态式,还是指定规则式,都可以提供一个知识锚点作用,搭建从KG路径到正确答案的一种多跳信息输入;
GraphRAG式等方式,可以分担知识图谱作为单一推理数据证据的风险,但可以提升知识图谱参与的紧密度;
合成的核心是剪枝不相关的路径以及链接的准确度,难点是无法确认这种推理路径是否真的直接促成了效果的提升;
高质量的知识图谱构建是核心,文档方面的工作需要重点关注,如何建立高质量的节点,如何构建相关的关系。也关注文档智能;
越是长尾的推理领域,推理越不可控,推理数据也越难,模型能力受限,人工校验的难度也越大;
其次,从生成结果上看:
这类数据的假设性很强,路径导致了答案,大模型用了路径,相关路径不等于因果路径,要区分因果性和相关性;
从推理的角度看,知识图谱中路径具有跳跃性,信息高度抽象,并不十分连贯,与大模型训练过程并不对齐,容易产生幻觉;
推理路径与答案之间的因果关系并不好界定,最短路径未必是真实有效的推理路径;
真实推理场景下,任务并不总是客观题,任务是否奏效,还需要进行验证。很多时候问题是有多个答案的;
推理数据除了定性,还需要定量。不一定要很多,不一定要很简单,需要考虑难度、长度、多样性等问题。
二、Embedding向量化、大模型推理及强化学习的一些新东西
1、不同领域的Embedding向量化开源进展
智源研究院发布三款向量模型:BGE-Code-v1(代码向量)、BGE-VL-v1.5(多模态向量)和BGE-VL-Screenshot(视觉化文档向量),这个几个工作,最大的亮点,其实还是在数据合成方面,这个是可以充分借鉴的点。
1)代码Embedding模型BGE_Coder,
BGE_Coder,《Towards A Generalist Code Embedding Model Based On Massive Data Synthesis》,https://arxiv.org/abs/2505.12697,基于CodeR-Pile合成数据集进行训练。
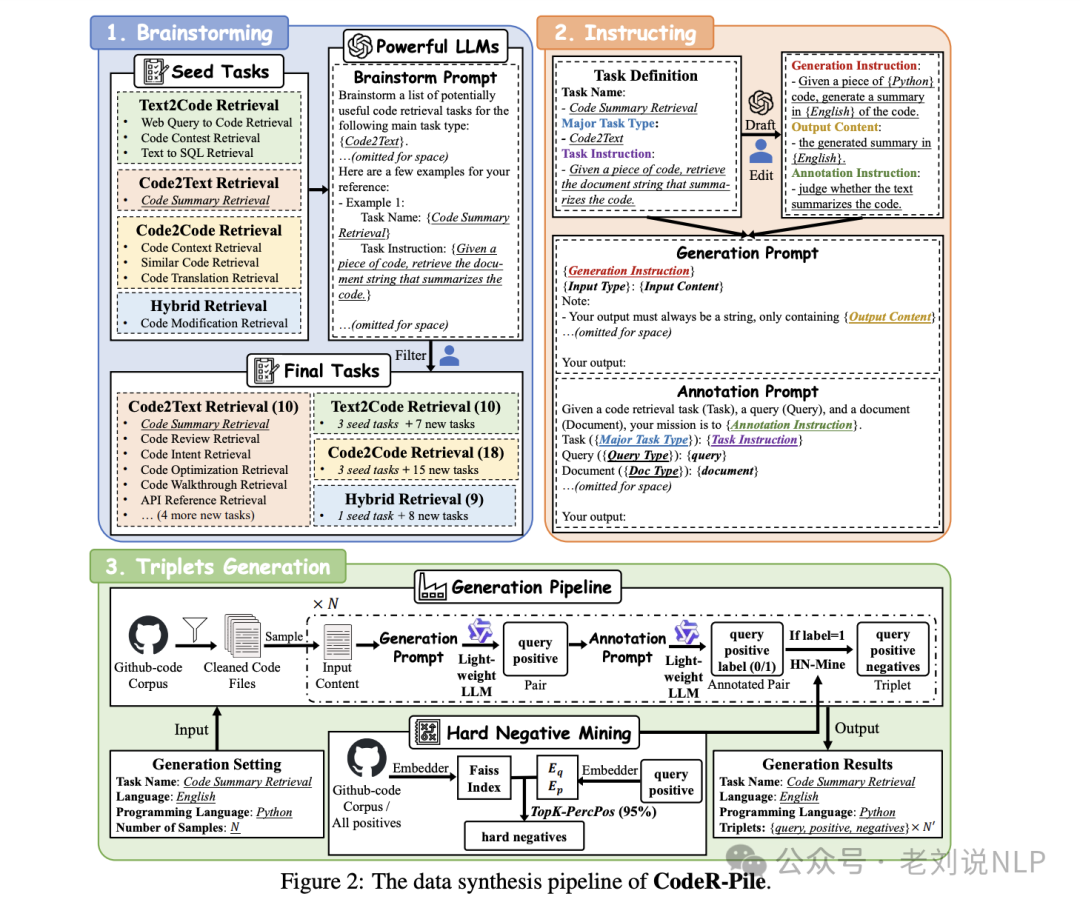
https://huggingface.co/BAAI/bge-code-v1,https://github.com/FlagOpen/FlagEmbedding/tree/master/research/BGE_Coder;
主要使用场景是RAG中的代码检索,支持代码检索、文本检索和多语言检索。支持英文、中文自然语言查询以及20种编程语言。
2)通用多模态检索embedding-BGE-VL-v1.5
《MegaPairs: Massive Data Synthesis For Universal Multimodal Retrieval》,https://arxiv.org/abs/2412.14475,主要核心点,是基于合成数据进行训练,MegaPairs 数据集包含超过2600万个三元组。
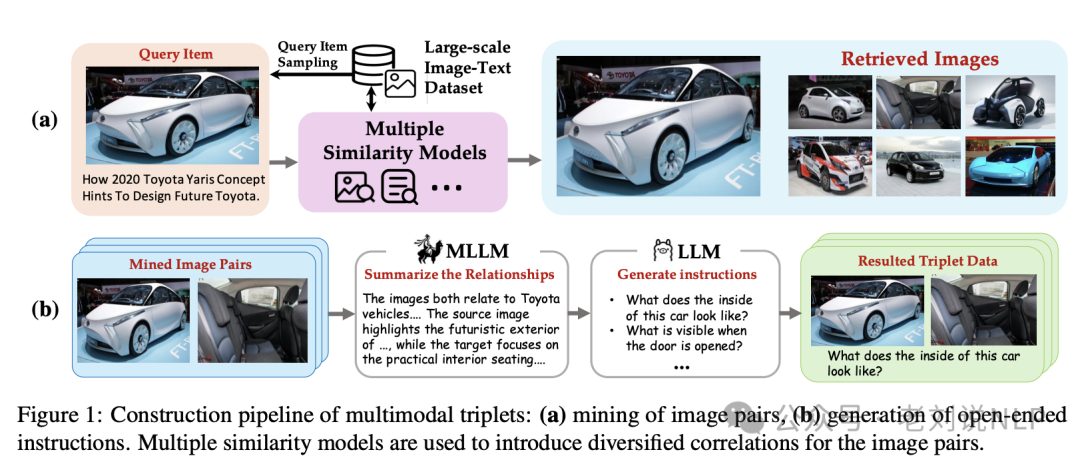
https://huggingface.co/BAAI/BGE-VL-v1.5-zs,https://github.com/FlagOpen/FlagEmbedding/tree/master/research/BGE_VL,主要使用场景是多模态检索。
3)屏幕图像embedding模型,BGE-VL-Screenshot, 《Any Information Is Just Worth One Single Screenshot: Unifying Search With Visualized Information Retrieval》。
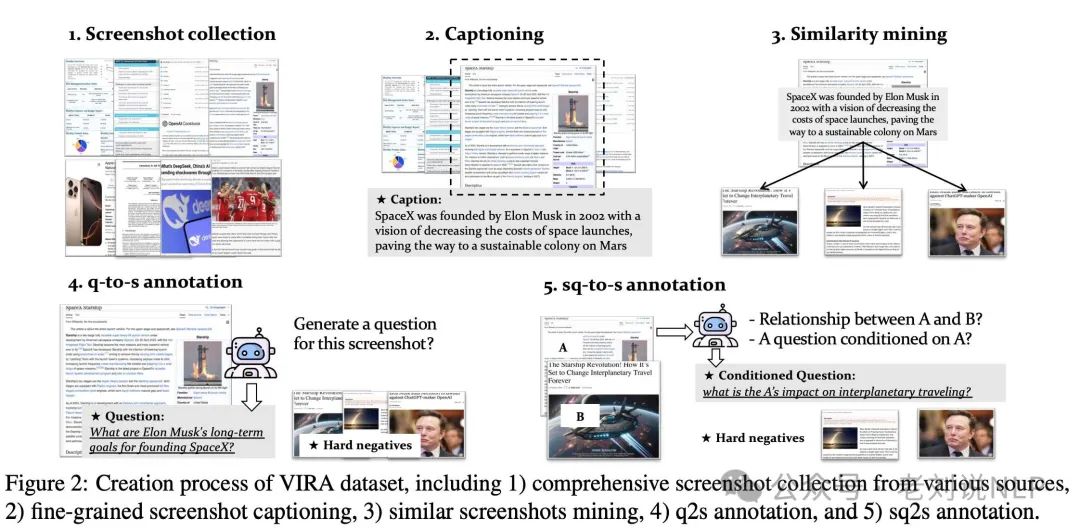
https://huggingface.co/BAAI/BGE-VL-Screenshot,https://github.com/FlagOpen/FlagEmbedding/tree/master/research/BGE_VL_Screenshot,https://arxiv.org/abs/2502.11431,
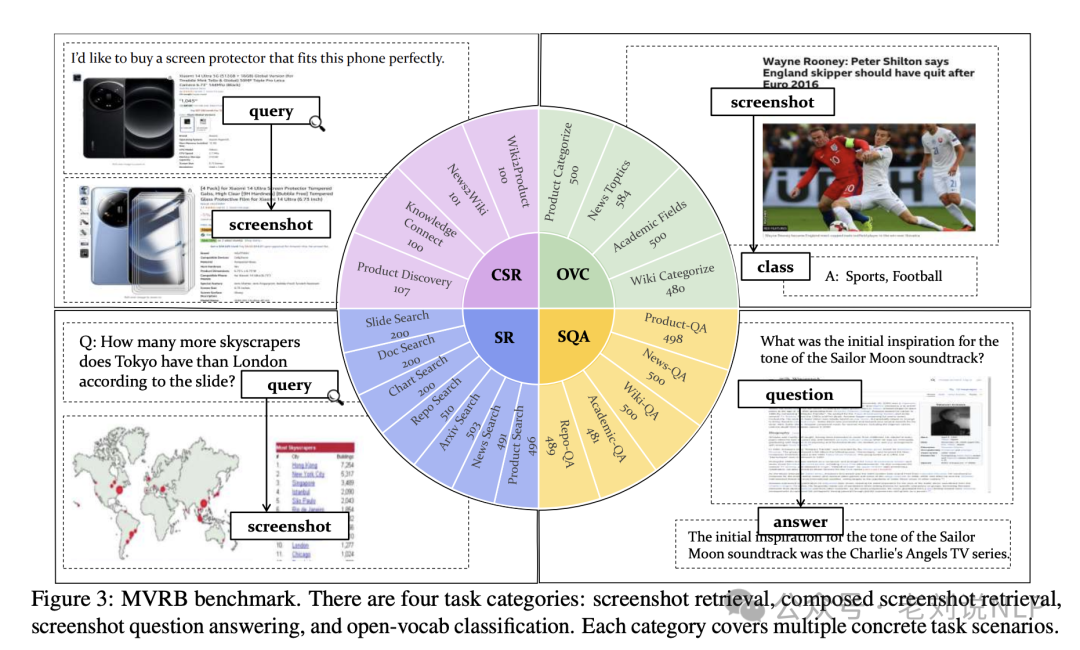
主要使用场景是**可视化信息检索(VisIR)**,其中,检索对象为多模态信息(例如文本、图像、表格和图表)等屏幕截图,提供统一可视化格式联合表示。
2、大模型推理采样策略实验的对比
1)大模型推理工具Cogitator
目前推理的策略也开始组件化,做成代码函数,通过代码接入的方式,可以快速方便进行推理性能调试。
最近有个工具Cogitator(https://github.com/habedi/cogitator) ,可以关注,包含多种热门CoT策略,Self-Consistency CoT (ICLR 2023)、Automatic CoT (ICLR 2023)、Least-to-Most Prompting (ICLR 2023)、Tree of Thoughts (NeurIPS 2023)、Graph of Thoughts (AAAI 2024)以及Clustered Distance-Weighted CoT (AAAI 2025),使用方式很简便:
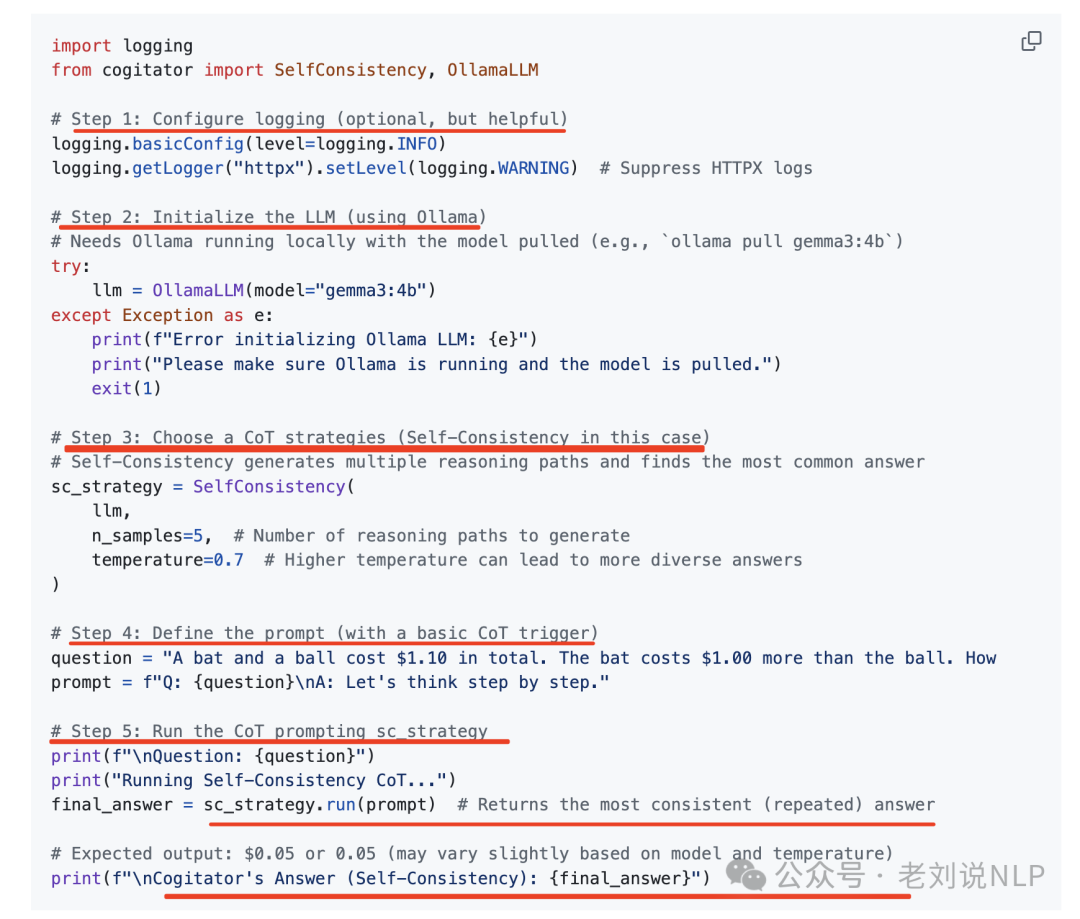
可以用来做模型实验对比,做模型策略选择。
2)关于大模型强化训练的监督信号BLEU
《BLEUBERI: BLEU is a surprisingly effective reward for instruction following》,https://arxiv.org/pdf/2505.11080,https://github.com/lilakk/BLEUBERI(代码是空的),这个发现挺有趣的BLEU(一种常用于机器翻译评估的指标) 在指令跟随任务中作为一种奖励机制,表现出有效性。

这个其实是个好思路,就像之前看Qwen3报告的时候,里面涉及到非确定性问题,如主观题答案的解法。
(文:老刘说NLP)