

试了一下谷歌昨晚发布的视频模型Veo3和AI视频创作产品FLOW,实在是太强了,这个模型会跟4o的图像模型一样将视频模型带到下一个时代。
先简单介绍一下 Veo3 和 FLOW 的特性:
Veo3 支持在生成视频的时候同时生成对应的环境音、语音,而且语音支持唇形同步,这个简直对一些剪辑软件、视频 Agent 和数字人产品是降维打击,视频生成的可用性一下提升了一大截。
在FLOW这里可以生成图片和视频,支持视频延长和剪短,最后可以将你挑选好的视频直接剪辑为完整的视频。
Veo 3 这个声音真的神来一笔一下子让视频生成多了很多应用场景,视频模型时代变了。
这篇文章我会发布我所有的一手 Veo3 视频模型测试结果和对应的应用场景,同时还会详细介绍 FLOW 这个产品如何使用。
Veo 3 测试
FLOW 里面只支持英文提示词,为了方便理解我会将提示词翻译为中文展示*
首先测试了一下他的语音生成和唇形同步能力,即使是小猫跟人不一样唇形同步也是很准确的,而且所有的音效都非常精准。
一只可爱的拟人化小猫刚刚进入学校,它背着自己的行李,好奇地打量着一切,嘴里还不停地嘀咕着
Veo 3居然可以准确的生成游戏的画面,里面的人物运动和游戏UI都是正确的,还能跟提示词对上,确实没少拿Youtube视频训练。
一位游戏直播者正在直播《堡垒之夜》,左上角是游戏画面,右下角是摄像头画面。他刚刚杀死了一名敌人,并兴奋地大叫着
这个场景主要考核复杂运动和声音的准确性,可以看到篮球落地的声音,运动的时候球鞋和地板摩擦的声音,球和篮筐的声音都非常准确。
室内篮球场上,一名身穿红色球衣的球员正在快速运球,不断做出佯攻和变向动作,试图突破对方蓝衣球员的防守。他突然停下,双腿高高跃起,身体在空中伸展,手腕一抖,将篮球投向远处的篮圈。球在空中划出一道高高的弧线,直奔篮网中央而去。场边的观众都站了起来,仔细观察着球的轨迹。
然后我突发奇想,这样是不是就能让古人给我们讲课了,类似汗青早期的AI Talk,没想到真的可以,现在可以让牛顿给你讲万有引力定律,爱因斯坦给你讲广义相对论。
在一部科普影片中,牛顿在一棵苹果树下向观众解释万有引力定律,右侧的便携式黑板上显示着公式,突然一个苹果掉了下来,砸到了牛顿的头上
上个例子我发现,它可以根据我的提示词在一段视频里面生成不同的分镜,于是我就想看看这个能力有多极限。
搞了一个5个分镜的提示词,而且这里面还得保证音频的准确,8秒5个分镜代表每个分镜不到两秒的时间。
结果Veo一次就搞定了,非常完美,而且保持了跨分镜人物一致性。
一系列快速变换的动态镜头:运动员在烈日下奔跑,大汗淋漓,汗珠从额头滴落;冲浪者乘风破浪;一群年轻人在户外音乐节上兴奋地跳跃。特写镜头显示冰镇饮料被打开,气泡升腾。最后,几个人举杯祝酒,脸上洋溢着满足而充满活力的笑容。画面定格在产品徽标上。
之后我又想到测试一下环境音,比如一天安静夜晚的各种声音,生成出来一听,这不就是ASMR视频吗?哈哈哈哈
没想到现在做ASMR视频的都要被AI卷到了。
同时在这个案例我还发现,Veo3 居然可以延长视频,而且延长出来的视频可以保证一致性,下面这个视频就延长到了16秒。
这下长视频生成也解决了,我们完全可以直接用Veo3生成一个几分钟的完整ASMR视频,这个太离谱了。
后面 FLOW 的部分会教大家如何延长视频。
透过被雨水打湿的窗户,可以看到夜色中的街道和不断落下的雨滴。房间里,一个人坐在书桌前,手指飞快地敲击着笔记本电脑的键盘。墙上挂着一个古董钟,钟摆有节奏地来回摆动。
最后试了一下视频播客场景,让他生成一个对谈的播客视频,对话内容也是连贯的。
这里有个很牛的是它可以多人唇形同步,这个在现在的数字人领域很难做到,没想到随便一翻身数字人也要被干死了。
播客录制现场,两名女主持人正在讨论有关法LLM训练主题的内容,其中一人提问,另一人回答
这里两人争吵的也可以看出来这个音频生成的强大,夸张表情加嘴部都能跟情绪和语音保持一致。
房间里,两名特工面对面站着,争吵着,互相指责对方任务失败的原因,他们的脸被强烈的愤怒涨得通红。他们用手指着对方,身体前倾,疯狂地挥舞着手臂。突然,其中一人猛地转身,大步走到门前,一把拉开门,头也不回地走了出去,“砰 ”地一声关上了身后的门。
最后是一个环境音,水流和切蔬菜的动画,对于物理表现和声音都有要求。
灯光明亮的厨房里,一个人正用菜刀在木质砧板上迅速而有节奏地切着五颜六色的蔬菜。旁边的水龙头开着,细细的水流不断流入水槽。他/她低着头,全神贯注,嘴唇偶尔微微蠕动。
FLOW 使用教程
谷歌一直没有一个给AI图像和视频创作者使用的产品,这次终于来了。
FLOW 支持生成图片和视频,而且支持对生成的视频进行编排和剪辑,最后导出完整的视频。
试了一下这个产品里面的小巧思还是挺多的,同时还有一些Bug需要规避一下,所以写一个使用教程吧。
你可以在这里使用FLOW:https://labs.google/fx/zh/tools/flow
目前只有美国IP用户可以用FLOW,我是Google AI Ultra会员,可以试试非Ultra会员能不能用。
首先进来以后我们需要新建一个项目,这个很容易理解,一个片子的所有素材都会在这里。
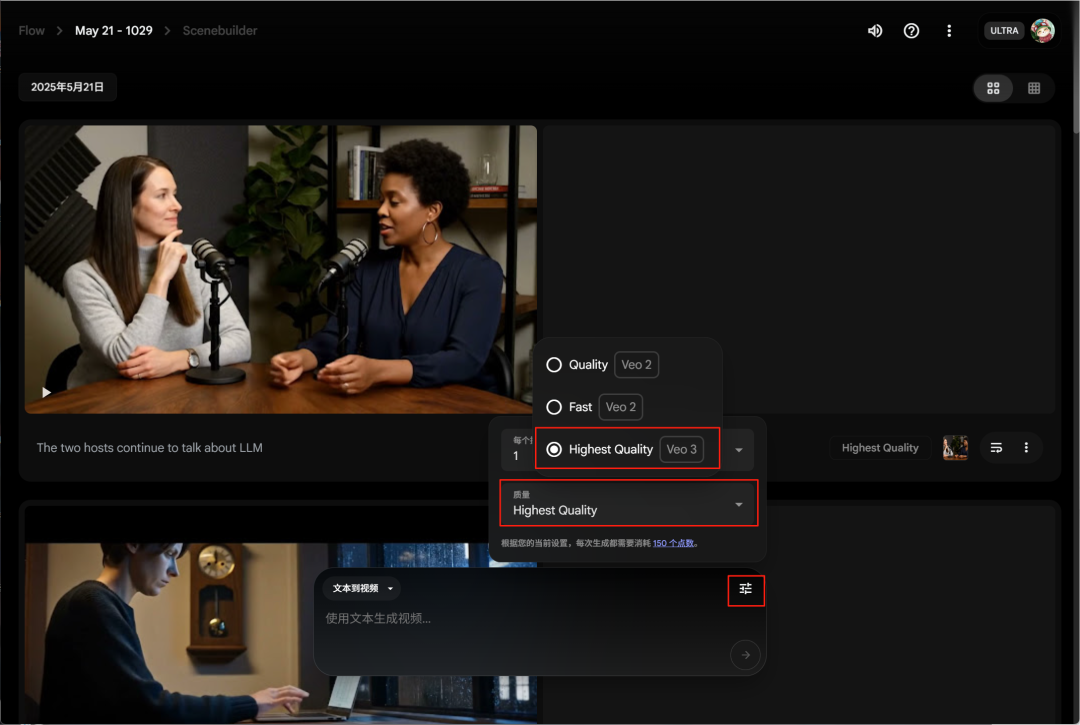
进来以后的界面很简单,一个输入框输入提示词的,这里你如果想要用 Veo 3,需要先改一个设置,在输入框设置里面选择Highest Quality的质量,这个才是Veo3。
如果你发现自己生成的视频没声音,看看改没改这里。
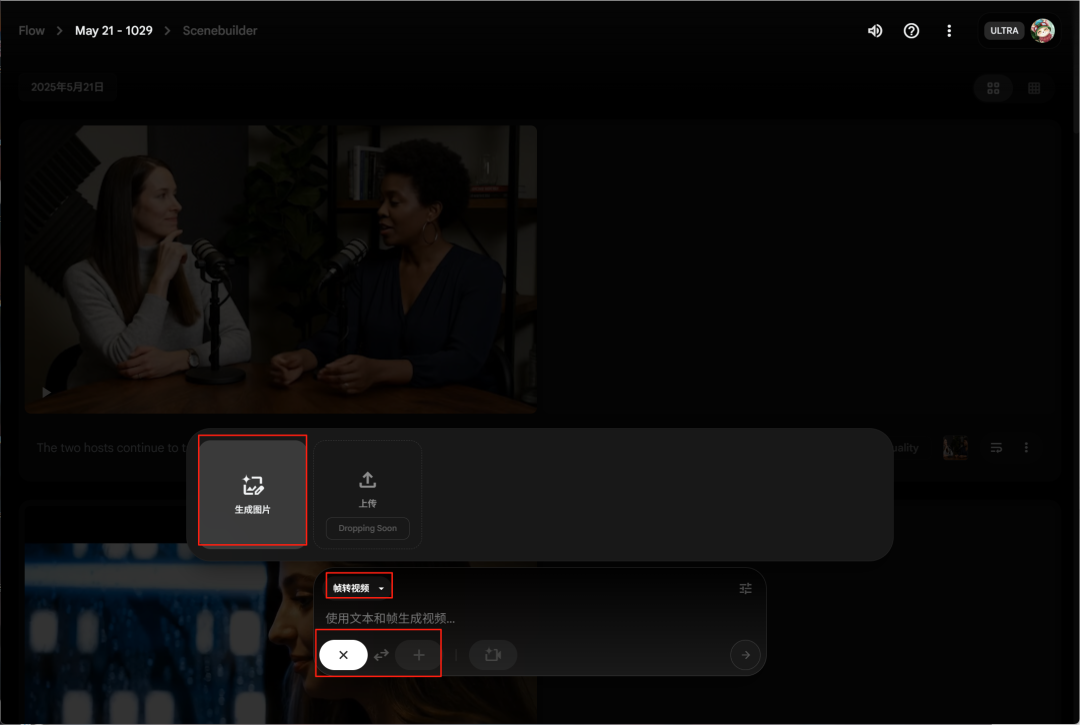
然后目前支持的视频方式主要是三种:
- 首先是文生视频,很好理解输入提示词就行,提示词只支持英语
- 然后是图生视频,这里支持单独的首帧、尾帧和首尾帧,另外目前不能上传图片,图片只能用Imagen模型生成
- 最后是素材转视频,感觉类似多图参考,可以上传三张图片提取内容,一张图片提取风格,搭配提示词生成视频,当然目前也不支持上传外部图片。
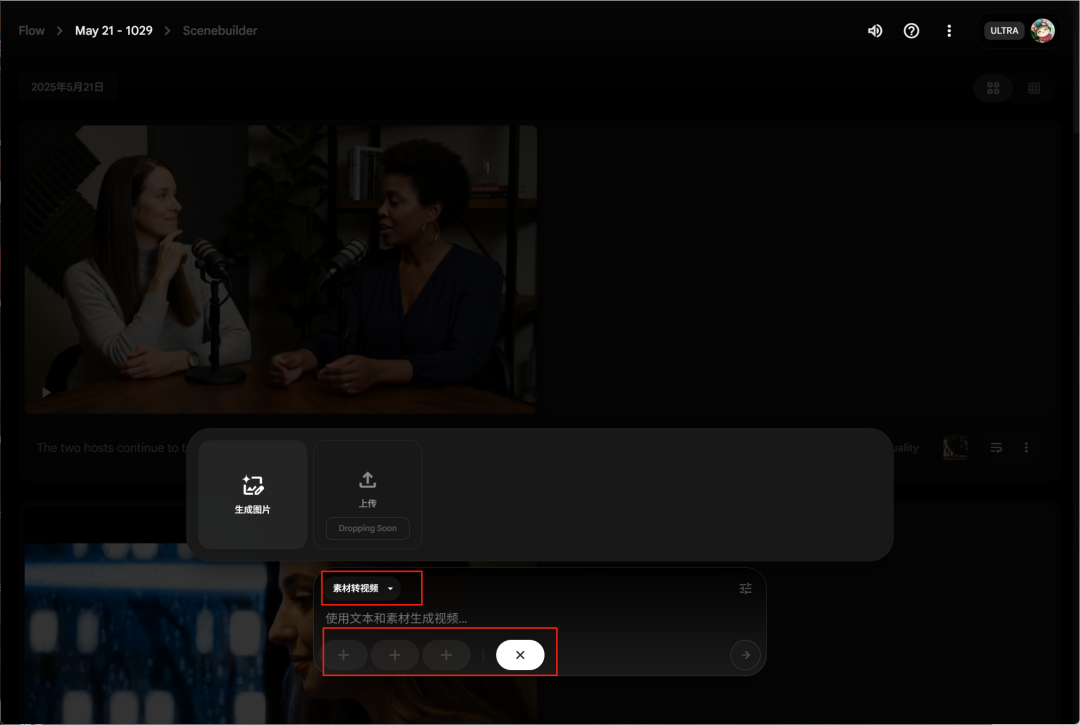
然后生成的结果会在上面展示,下载按钮这里支持将生成的视频超分到1080P。
另外注意:目前的下载按钮下载的视频会没有声音,你需要点击全屏按钮,之后在播放器右下角的三个点那里下载才会有声音。
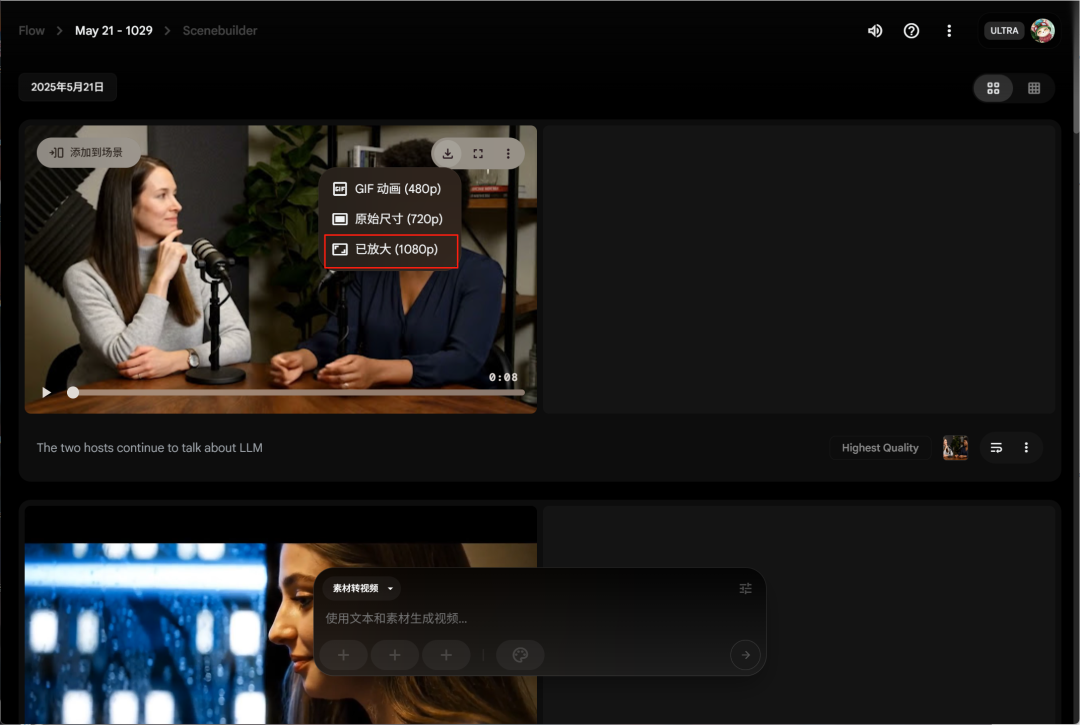

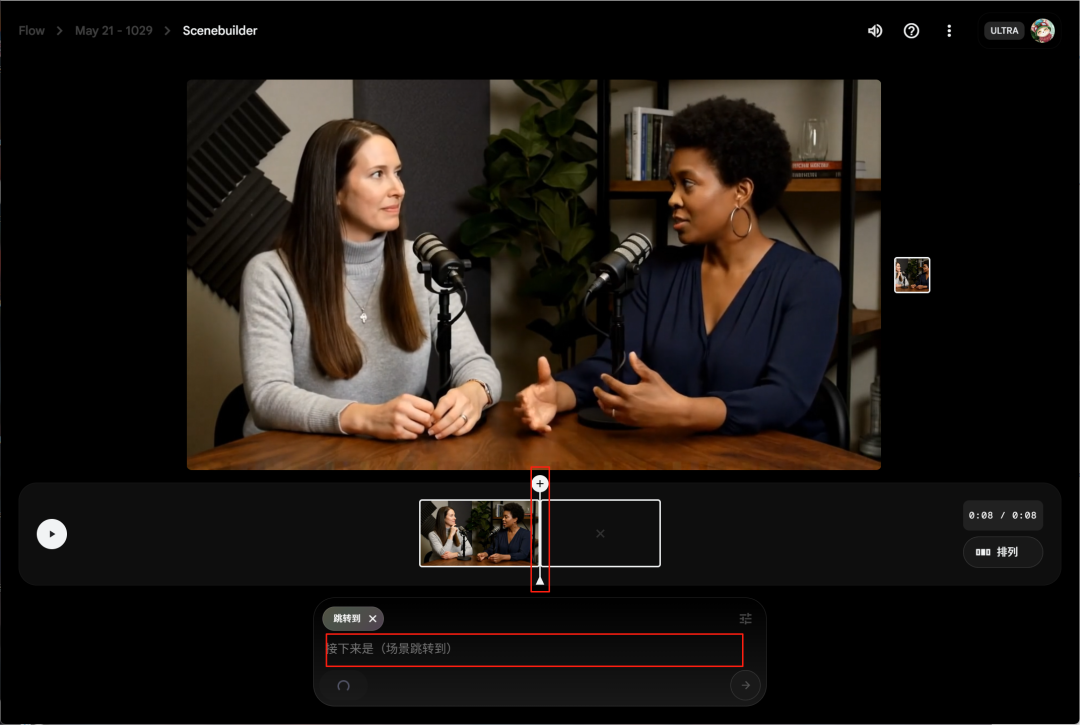
接下来你会在生成视频的右上角看到一个添加到场景的按钮,另外画面右上角也有Scenebuilder的按钮,从这两个位置都能进到素材剪辑页面。
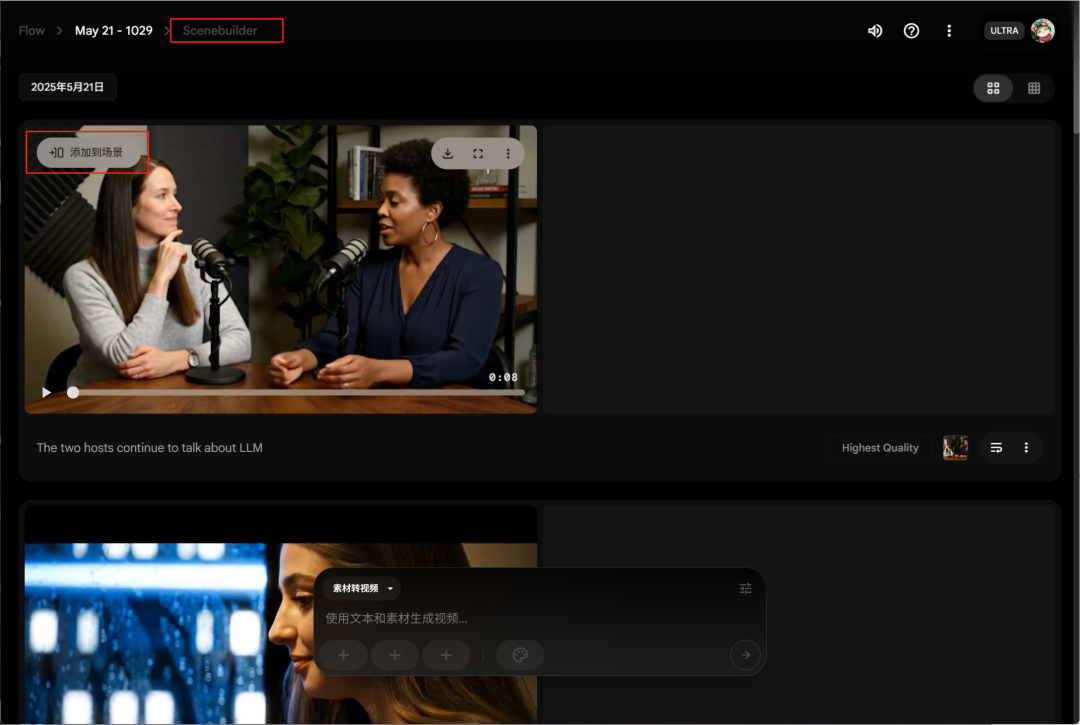
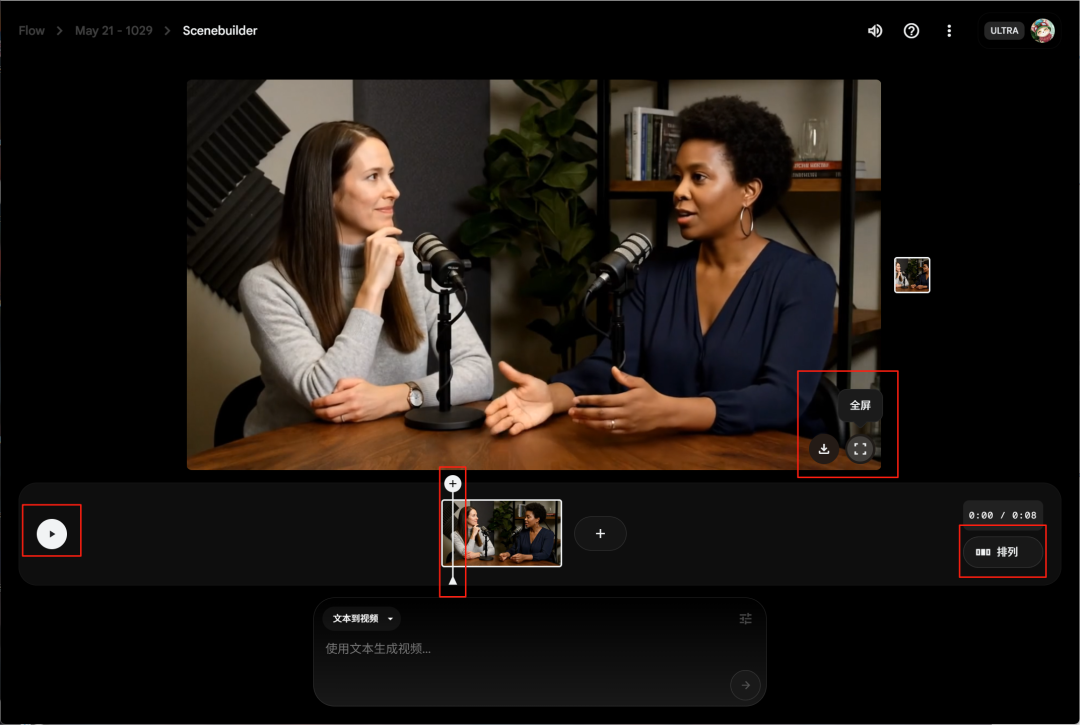
进到剪辑页面后注意,右边的排列按钮我们可以调整分镜顺序和删除分镜,中间的进度条拖动后的位置就是下一个视频生成后放的位置,最左边的播放就是预览按钮。
这里你可能会发现没有导出按钮,谷歌的交互真是一坨, 你需要放大预览画面,然后点三个点的下载这时候下载的就是编排好的完整视频。
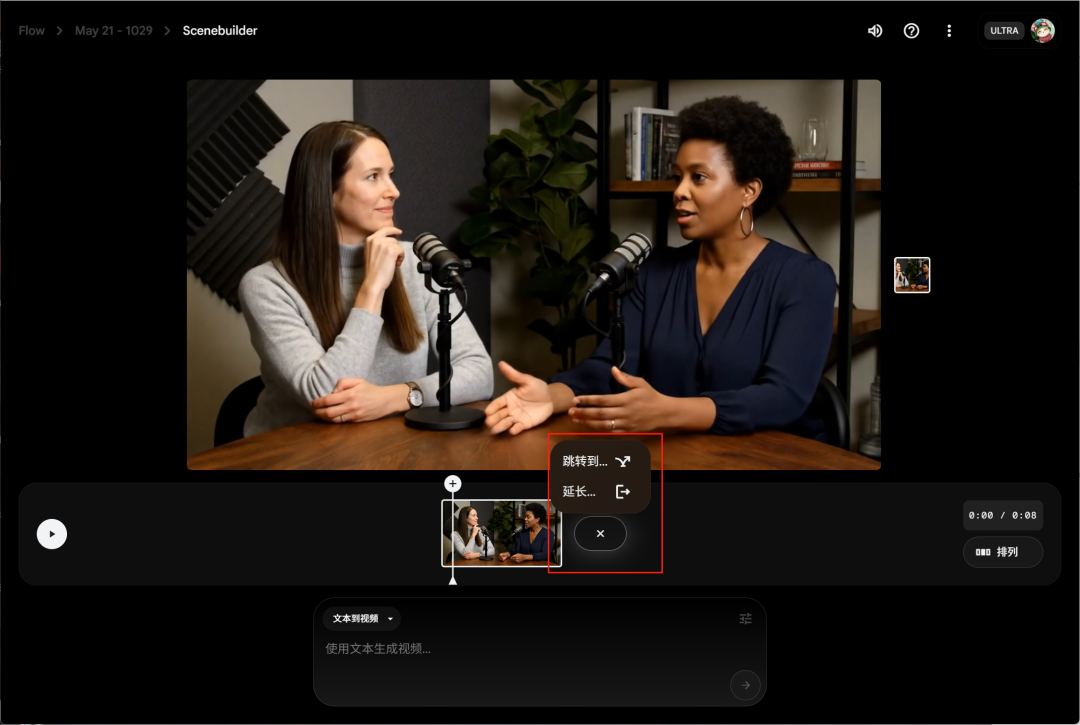
接下来教大家怎么在这里延长Veo3的视频,点击分镜后的加号我们可以看到两个按钮,跳转到和延长。
注意这里你如果点延长的话模型会自动切换会Veo2去生成。
所以我们的延长需要选跳转到,然后注意这是这时候你的播放光标一定要在视频最后一帧,因为这是通过首尾帧实现的,之后我们输入提示词就行。
最后注意的是,延长或者跳转到的时候不要回到编辑之前的素材库页面,可能会停止生成。
好了这次的测评和教程就到这里了,希望能给到你一些启发。
谷歌这次的视频模型升级将音效生成、语音生成以及唇形同步逻辑跟4o的图片生成一样,是将多种模型整合到了一整个完整的视频模型中,这样才能有这么完美的效果。
每一次Agent的模型化即使每个部分的模型本身质量没有升级也会带来非常多的应用场景和新的产品机会,4o图片发布之后的盛况大家也看到了。
期待大家能从我的内容获得启发,找到更多在你的行业上Veo3的应用场景。
如果你觉的教程对你有帮助的话可以帮我点个赞👍或者喜欢🩷,也可以推荐给你需要的朋友们!
(文:归藏的AI工具箱)