


随着人工智能技术的飞速发展,文本转语音(TTS)技术在众多领域得到了广泛应用,从智能语音助手到有声读物,再到播客和视频配音等。
然而,现有的TTS模型往往存在一些局限性,例如依赖大量目标说话人的语音数据进行训练,或者缺乏高效的推理加速框架。
为了突破这些限制,MYZY AI团队推出了一款名为Muyan-TTS的开源文本转语音模型,专为播客场景设计,能够在无需大量目标说话人数据的情况下实现高质量的语音合成,并支持说话人适配和个性化语音定制。

一、项目概述
Muyan-TTS是一款开源的文本转语音(TTS)模型,专为播客和长篇语音内容生成场景设计。该模型预训练了超过10万小时的播客音频数据,能够实现零样本语音合成,即无需大量目标说话人的语音数据,仅通过少量参考语音和文本即可生成高质量语音。此外,Muyan-TTS还支持说话人适配功能,可以通过少量目标说话人的语音数据进行微调,实现个性化语音定制。其合成速度快,仅需0.33秒即可生成1秒音频,适合实时应用,并且能够自然连贯地合成长篇内容,如播客、有声书等。
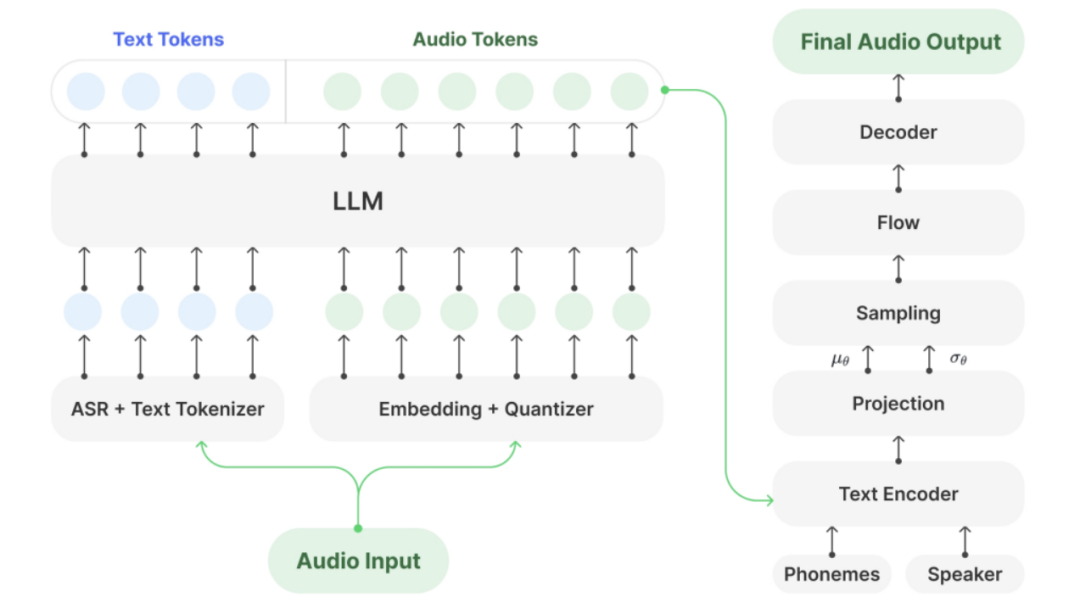
二、技术架构
(一)框架设计
Muyan-TTS的技术架构基于GPT-SoVITS框架,结合了预训练的Llama-3.2-3B作为语言模型(LLM),以及SoVITS模型进行音频解码。LLM负责将文本和音频token对齐,生成中间表示,而SoVITS模型则将中间表示解码为音频波形。这种架构设计既利用了LLM强大的文本语义理解能力,又通过SoVITS模型实现了高质量的音频生成。
(二)数据处理
Muyan-TTS的数据集包含超过10万小时的播客音频数据,经过多阶段处理,包括数据收集、清洗和格式化,确保数据的高质量和多样性。具体步骤如下:
1. 数据收集:从开源数据集和专有播客内容中收集音频数据,经过质量评估后,保留高质量音频。
2. 数据清洗:通过音乐源分离、去混响、去回声和降噪等技术,提升音频质量。
3. 数据格式化:将音频分割为单句,去除短于5秒的片段,并使用自动语音识别(ASR)模型将音频转录为文本,形成平行语料库。
(三)预训练与微调
LLM在平行语料库上进行预训练,学习文本和音频token之间的关系。在此基础上,通过监督微调(SFT),利用少量目标说话人的语音数据进一步优化模型,提高语音合成的自然度和相似度。
(四)解码器优化
Muyan-TTS采用VITS基础模型作为解码器,减少幻觉问题,提高语音生成的稳定性和自然度。解码器在高质量音频数据上进行微调,进一步提升合成语音的保真度和表现力。
(五)推理加速
通过高效的内存管理和并行推理技术,Muyan-TTS显著提高了推理速度,降低了延迟。模型支持API模式,自动启用加速功能,适合实时应用。
三、主要功能
(一)零样本语音合成
传统语音合成需大量目标说话人数据,门槛高。Muyan – TTS不同,它只需少量参考语音和文本,就能生成高质量语音。这一特性让语音合成不再受数据量限制,普通用户和小型企业也能轻松使用,大大拓宽了语音合成的应用范围。
(二)说话人适配
当下用户对语音个性化需求多样。Muyan – TTS通过少量目标说话人语音数据微调,可定制个性化语音。不管是甜美女声、沉稳男声,还是特殊风格语音,它都能精准实现,为用户带来符合期望的独特语音体验。
(三)快速生成
在快节奏的内容创作中,速度至关重要。Muyan – TTS合成速度惊人,0.33秒就能生成1秒音频。无论是实时场景还是批量生成,它都能快速响应,极大缩短了语音制作周期,显著提高了内容创作的效率。
(四)长内容连贯合成
传统TTS模型合成长篇内容时易出现衔接问题。Muyan – TTS凭借先进技术,能自然连贯地合成播客、有声书等长篇内容。它准确把握语义和情感,使语音在语速、语调、停顿上自然流畅,给听众带来良好的听觉享受。
(五)离线部署友好
在对数据安全要求高的场景,数据上传云端有风险。Muyan – TTS支持本地推理,可部署在本地设备。这样既能保证数据隐私,又能实现低延迟合成,快速响应用户需求,非常适合金融、医疗等领域。
四、应用场景
(一)播客和有声书
播客和有声书制作注重效率和质量。Muyan – TTS能高效生成内容,其合成语音自然连贯,能提升听众体验。创作者无需耗费大量时间精力录制,只需提供文本,就能快速获得高质量语音,提高创作产出。
(二)视频配音
视频行业发展快,对配音效率要求高。Muyan – TTS可快速合成英文脚本配音,并适配不同角色。通过调整音色、语调等参数,它能精准呈现角色特点,满足视频制作者高效、多样的配音需求。
(三)AI角色和语音助手
在智能设备中,AI角色和语音助手需有良好交互体验。Muyan – TTS可为其生成特色语音,根据角色性格定制语音风格。自然、个性化的语音能增强用户与设备的互动,让用户更亲近和认同设备。
(四)新闻播报
新闻讲究时效性,Muyan – TTS能高效将文本转语音。智能设备使用它可快速生成高质量新闻语音,满足新闻发布的时效要求。且其合成语音清晰准确、富有感染力,有助于提升新闻传播效果。
(五)教育和游戏
教育和游戏行业需要个性化语音提升体验。Muyan – TTS可生成教学语音,让课程更生动;也能生成游戏旁白,增添游戏氛围。它为教育和游戏提供了丰富多样的语音解决方案,提升了学习和娱乐的趣味性。
五、测评表现
(一)性能对比
在与CosyVoice2、Step-Audio、Spark-TTS、FireRedTTS和GPT-SoVITS v3等其他开源TTS模型的对比中,Muyan-TTS在合成速度上表现出色,仅需0.33秒即可生成1秒音频,是目前测试模型中最快的。在语音质量和自然度方面,Muyan-TTS也表现出色,其在LibriSpeech和SEED数据集上的测试结果显示,其在词错误率(WER)、说话人相似度(SIM)和平均意见得分(MOS)等指标上均达到了较高水平。

(二)零样本语音合成
在零样本语音合成测试中,Muyan-TTS在LibriSpeech测试集上取得了3.44%的WER,4.58的MOS和0.37的SIM,在SEED测试集上取得了4.09%的WER,4.32的MOS和0.41的SIM。这些结果表明,Muyan-TTS在语音合成的准确性和自然度方面具有很强的竞争力。
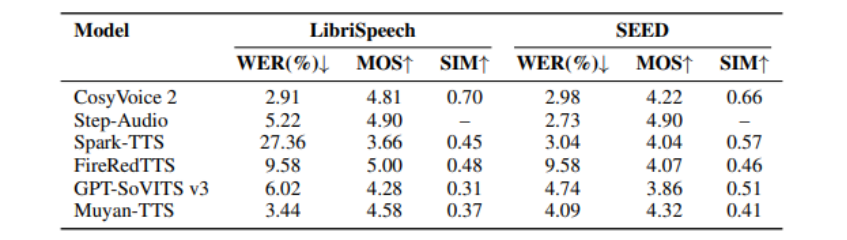
(三)监督微调(SFT)模型
通过在少量目标说话人数据上进行监督微调,Muyan-TTS-SFT在语音质量和说话人相似度方面进一步提升。在LibriSpeech测试集上,Muyan-TTS-SFT的WER为4.48%,MOS为4.97,SIM为0.46,相较于基础模型有显著提升。

六、快速使用
(一)环境准备
1. 克隆项目
git clone https://github.com/MYZY-AI/Muyan-TTS.gitcd Muyan-TTS
2. 创建并激活Python环境
conda create -n muyan-tts python=3.10 -yconda activate muyan-ttsmake build
3. 安装FFmpeg
如果使用Ubuntu系统,可以通过以下命令安装:
sudo apt updatesudo apt install ffmpeg
(二)模型下载
将Muyan-TTS、Muyan-TTS-SFT以及chinese-hubert-base模型下载到`pretrained_models`目录下,目录结构如下:
pretrained_models
├── chinese-hubert-base
├── Muyan-TTS
└── Muyan-TTS-SFT
(三)推理使用
以下是一个简单的推理代码示例:
async def main(model_type, model_path):tts = Inference(model_type, model_path, enable_vllm_acc=False)wavs = await tts.generate(ref_wav_path="assets/Claire.wav",prompt_text="Although the campaign was not a complete success, it did provide Napoleon with valuable experience and prestige.",text="Welcome to the captivating world of podcasts, let's embark on this exciting journey together.")output_path = "logs/tts.wav"with open(output_path, "wb") as f:f.write(next(wavs))print(f"Speech generated in {output_path}")
在使用时,需要指定`model_type`为`base`或`sft`,并提供参考语音路径`ref_wav_path`及其对应的文本`prompt_text`,以及需要合成的文本`text`。合成的语音将默认保存到`logs/tts.wav`。
(四)API使用
Muyan-TTS还支持API模式,通过以下命令启动服务:
# 启动API服务# 默认端口为8020python api.py
然后可以通过发送HTTP请求来调用API:
import timeimport requestsTTS_PORT = 8020payload = {"ref_wav_path": "assets/Claire.wav","prompt_text": "Although the campaign was not a complete success, it did provide Napoleon with valuable experience and prestige.","text": "Welcome to the captivating world of podcasts, let's embark on this exciting journey together.","temperature": 0.6,"speed": 1.0,}start = time.time()url = f"http://localhost:{TTS_PORT}/get_tts"response = requests.post(url, json=payload)audio_file_path = "logs/tts.wav"with open(audio_file_path, "wb") as f:f.write(response.content)print(time.time() - start)
API模式下,Muyan-TTS会自动启用加速功能,进一步提高推理效率。
七、结语
Muyan-TTS作为一款开源的文本转语音模型,以其零样本语音合成能力、快速生成速度和强大的说话人适配功能,为播客、有声书、视频配音等多个领域提供了高效、高质量的语音合成解决方案。未来,随着技术的不断进步和社区的持续贡献,Muyan-TTS有望在更多领域发挥更大的作用,推动文本转语音技术的发展。
八、项目地址
GitHub仓库:https://github.com/MYZY-AI/Muyan-TTS
arxiv技术论文:https://arxiv.org/pdf/2504.19146
(文:小兵的AI视界)