
项目简介
LandingAI 的 Agentic 文档提取 API 能够从视觉复杂的文档(如表格、图片和图表)中提取结构化数据,并返回带有精确元素位置的层次化 JSON。
此 Python 库封装了该 API,提供以下功能:
-
长文档支持 – 单次调用处理 100+ 页的 PDF -
自动重试/分页 – 处理并发、超时和速率限制 -
辅助工具 – 边界框片段、可视化调试器等
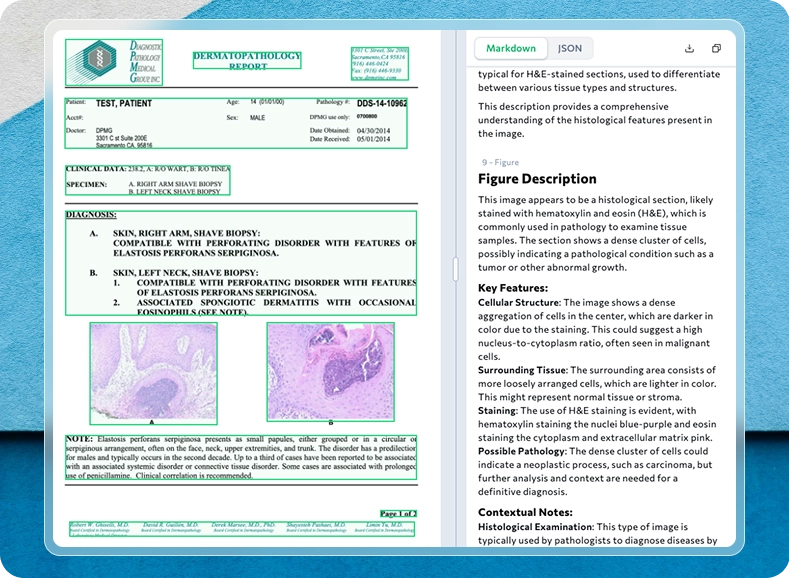
特性
-
📦 开箱即用安装: pip install agentic-doc– 无需其他依赖 → 参见 安装[1] -
🗂️ 支持所有文件类型: 解析任意长度的 PDF、单张图片或 URL → 参见 支持的文件[2] -
📚 长文档就绪: 自动拆分并并行处理 1000+ 页 PDF,然后合并结果 → 参见 解析大型 PDF 文件[3] -
🧩 结构化输出: 返回层次化 JSON 及可直接渲染的 Markdown → 参见 结果模式[4] -
👁️ 真实可视化: 可选的边界框片段和全页可视化 → 参见 保存定位为图片[5] -
🏃 批量并行处理: 输入列表;库管理线程和速率限制 ( BATCH_SIZE,MAX_WORKERS) → 参见 批量解析多个文件[6] -
🔄 容错性强: 对 408/429/502/503/504 和速率限制触发的请求进行指数退避重试 → 参见 自动处理 API 错误和速率限制[7] -
🛠️ 即用辅助函数: parse_documents,parse_and_save_documents,parse_and_save_document→ 参见 主要函数[8] -
⚙️ 通过环境变量/.env 配置: 调整并行性、日志风格、重试上限,无需修改代码 → 参见 配置选项[9] -
🌐 原生 API 支持: 高级用户仍可直接调用 REST 端点 → 参见 API 文档[10]
快速开始
安装
ounter(linepip install agentic-doc
要求
-
Python 版本 3.9、3.10、3.11 或 3.12 -
LandingAI Agentic AI API 密钥(获取密钥 此处[11])
设置 API 密钥为环境变量
获取 LandingAI Agentic AI API 密钥后,将其设置为环境变量(或放入 .env 文件):
ounter(lineexport VISION_AGENT_API_KEY=<your-api-key>
支持的文件
该库可从以下文件中提取数据:
-
PDF(任意长度) -
OpenCV-Python(即 cv2库)支持的图片 -
指向 PDF 或图片文件的 URL
基本用法
从单个文档提取数据
运行以下脚本从单个文档提取数据,并以 Markdown 和结构化块的形式返回结果。
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(linefrom agentic_doc.parse import parse# 解析本地文件result = parse("path/to/image.png")print(result.markdown) # 获取提取的 Markdown 数据print(result.chunks) # 获取提取的结构化内容块# 解析 URL 中的文档result = parse("https://example.com/document.pdf")print(result.markdown)# 传统方法(仍支持)from agentic_doc.parse import parse_documentsresults = parse_documents(["path/to/image.png"])parsed_doc = results[0]
从多个文档提取数据
运行以下脚本从多个文档提取数据。
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(linefrom agentic_doc.parse import parse# 解析多个本地文件file_paths = ["path/to/your/document1.pdf", "path/to/another/document2.pdf"]results = parse(file_paths)for result in results:print(result.markdown)# 解析并将结果保存到目录result_paths = parse(file_paths, result_save_dir="path/to/save/results")# result_paths: ["path/to/save/results/document1_20250313_070305.json", ...]
使用连接器提取数据
该库支持多种连接器,方便从不同来源访问文档:
Google Drive 连接器
前提条件:首先按照 Google Drive API Python 快速入门[12] 教程设置凭据。
Google Drive API 快速入门将指导您完成:
-
创建 Google Cloud 项目 -
启用 Google Drive API -
设置 OAuth 2.0 凭据
完成快速入门教程后,可以按以下方式使用 Google Drive 连接器:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(linefrom agentic_doc.parse import parsefrom agentic_doc.connectors import GoogleDriveConnectorConfig# 使用 OAuth 凭据文件(来自快速入门教程)config = GoogleDriveConnectorConfig(client_secret_file="path/to/credentials.json",folder_id="your-google-drive-folder-id" # 可选)# 解析文件夹中的所有文档results = parse(config)# 解析时过滤results = parse(config, connector_pattern="*.pdf")
Amazon S3 连接器
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(linefrom agentic_doc.parse import parsefrom agentic_doc.connectors import S3ConnectorConfigconfig = S3ConnectorConfig(bucket_name="your-bucket-name",aws_access_key_id="your-access-key", # 如果使用 IAM 角色则为可选aws_secret_access_key="your-secret-key", # 如果使用 IAM 角色则为可选region_name="us-east-1")# 解析存储桶中的所有文档results = parse(config)# 解析特定前缀/文件夹中的文档results = parse(config, connector_path="documents/")
本地目录连接器
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(linefrom agentic_doc.parse import parsefrom agentic_doc.connectors import LocalConnectorConfigconfig = LocalConnectorConfig()# 解析目录中所有支持的文档results = parse(config, connector_path="/path/to/documents")# 解析时过滤results = parse(config, connector_path="/path/to/documents", connector_pattern="*.pdf")# 递归解析目录中所有支持的文档(包括子目录)config = LocalConnectorConfig(recursive=True)results = parse(config, connector_path="/path/to/documents")
URL 连接器
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(linefrom agentic_doc.parse import parsefrom agentic_doc.connectors import URLConnectorConfigconfig = URLConnectorConfig(headers={"Authorization": "Bearer your-token"}, # 可选timeout=60 # 可选)# 解析 URL 中的文档results = parse(config, connector_path="https://example.com/document.pdf")
为什么使用它?
-
简化设置: 无需管理 API 密钥或处理低级别 REST 调用。 -
自动处理大文件: 将大型 PDF 拆分为可管理的部分并并行处理。 -
内置错误处理: 对常见 HTTP 错误自动重试,采用指数退避和抖动策略。 -
并行处理: 高效地同时解析多个文档,可配置并行度。
主要特性
通过此库,您可以实现一些仅使用 Agentic 文档提取 API 难以完成的功能。本节介绍该库提供的一些关键特性。
解析大型 PDF 文件
单个 REST API 调用一次只能处理一定数量的页面(参见 速率限制[13])。此库会自动将大型 PDF 拆分为多个调用,使用线程池并行处理这些调用,并将结果合并为单个结果。
我们已使用此库成功解析了 1000+ 页的 PDF。
批量解析多个文件
您可以通过此库一次性解析多个文件。库会并行处理这些文件。
注意: 可以通过设置
batch_size来调整并行度。
将定位保存为图片
该库可以提取并保存文档中每个内容块的视觉区域(定位)。这对于可视化文档中被提取的部分以及调试提取问题非常有用。
每个定位代表原始文档中的一个边界框,库可以将这些区域保存为单独的 PNG 图片。图片按页码和块 ID 组织。
使用方法如下:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(linefrom agentic_doc.parse import parse_documents# 解析文档时保存定位results = parse_documents(["path/to/document.pdf"],grounding_save_dir="path/to/save/groundings")# 定位图片将保存到:# path/to/save/groundings/document_TIMESTAMP/page_X/CHUNK_TYPE_CHUNK_ID_Y.png# 其中 X 是页码,CHUNK_ID 是每个块的唯一 ID,# Y 是块中定位的索引# 结果中每个块的定位将设置 image_pathfor chunk in results[0].chunks:for grounding in chunk.grounding:if grounding.image_path:print(f"定位已保存至: {grounding.image_path}")
此功能适用于所有解析函数:parse_documents、parse_and_save_documents 和 parse_and_save_document。
可视化解析结果
该库提供了一个可视化工具,可以创建带注释的图片,显示从文档中提取的每个内容块的位置。这对于以下情况非常有用:
-
验证提取的准确性 -
调试提取问题
使用方法如下:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(linefrom agentic_doc.parse import parsefrom agentic_doc.utils import viz_parsed_documentfrom agentic_doc.config import VisualizationConfig# 解析文档results = parse("path/to/document.pdf")parsed_doc = results[0]# 使用默认设置创建可视化# 输出图片为 PIL.Image.Image 类型images = viz_parsed_document("path/to/document.pdf",parsed_doc,output_dir="path/to/save/visualizations")# 或自定义可视化外观viz_config = VisualizationConfig(thickness=2, # 更粗的边界框text_bg_opacity=0.8, # 更不透明的文本背景font_scale=0.7, # 更大的文本# 为不同类型的块设置自定义颜色color_map={ChunkType.TITLE: (0, 0, 255), # 标题为红色ChunkType.TEXT: (255, 0, 0), # 常规文本为蓝色# ... 其他块类型 ...})images = viz_parsed_document("path/to/document.pdf",parsed_doc,output_dir="path/to/save/visualizations",viz_config=viz_config)# 可视化图片将保存为:# path/to/save/visualizations/document_viz_page_X.png# 其中 X 是页码
可视化显示:
-
每个提取块的边界框 -
块类型和索引标签 -
不同类型内容(标题、文本、表格等)的不同颜色 -
半透明文本背景以提高可读性
自动处理 API 错误和速率限制
REST API 端点对每个 API 密钥施加了速率限制。此库会自动处理速率限制错误或其他间歇性 HTTP 错误,并进行重试。
更多信息,请参见 错误处理[14] 和 配置选项[15]。
错误处理
此库实现了处理 API 失败的重试机制:
-
对以下 HTTP 状态码进行重试:408、429、502、503、504。 -
使用指数退避和抖动策略计算重试等待时间。 -
初始重试等待时间为 1 秒,之后按指数增长。 -
重试将在 max_retries次尝试后停止。超过限制会引发异常并导致请求失败。 -
重试等待时间上限为 max_retry_wait_time秒。 -
重试包含最多 10 秒的随机抖动,以分散请求并避免“惊群”问题。
解析错误
如果 REST API 请求在解析过程中遇到不可恢复的错误(无论是客户端还是服务器端),库会在最终结果的 errors[16] 字段中包含受影响页面的错误信息。每个错误包含错误消息、错误代码和对应的页码。
配置选项
该库使用 `Settings`[17] 对象管理配置。您可以通过环境变量或 .env 文件自定义这些设置:
以下是自定义配置的示例 .env 文件:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line# 并行处理的文件数,默认为 4BATCH_SIZE=4# 用于并行处理每个文件部分的线程数,默认为 5。MAX_WORKERS=2# 失败间歇性请求的最大重试次数,默认为 100MAX_RETRIES=80# 每次重试的最大等待时间(秒),默认为 60MAX_RETRY_WAIT_TIME=30# 重试的日志风格,默认为 log_msgRETRY_LOGGING_STYLE=log_msg
最大并行度
并行请求的最大数量由 BATCH_SIZE × MAX_WORKERS 决定。
注意: 此库允许的最大并行度为 100。
具体来说,增加 MAX_WORKERS 可以加速处理单个大文件,而增加 BATCH_SIZE 可以提高处理多个文件时的吞吐量。
注意: 您的任务的最大处理吞吐量可能会受到 API 速率限制的限制。如果速率限制不够高,可能会遇到速率限制错误,库将通过重试自动处理这些错误。
MAX_WORKERS 和 BATCH_SIZE 的最佳值取决于您的 API 速率限制和每个 REST API 调用的延迟。例如,如果您的账户速率限制为每分钟 5 个请求,每个 REST API 调用大约需要 60 秒完成,并且您正在处理单个大文件,则 MAX_WORKERS 应设置为 5,BATCH_SIZE 设置为 1。
您可以在日志中找到 REST API 的延迟。如果想提高速率限制,请安排时间与我们 会面[18]。
设置 RETRY_LOGGING_STYLE
RETRY_LOGGING_STYLE 设置控制库如何记录重试尝试。
-
log_msg: 将重试尝试记录为日志消息。每次尝试作为单独的消息记录。这是默认设置。 -
inline_block: 在同一行打印黄色进度块(’█’)。每个块代表一次重试尝试。如果不想看到详细的重试日志消息但仍想跟踪重试次数,可以选择此选项。 -
none: 不记录重试尝试。
故障排除与常见问题
常见问题
-
API 密钥错误:
确保 API 密钥已正确设置为环境变量。 -
速率限制:
如果触发 API 速率限制,库会自动重试请求。如果频繁遇到速率限制错误,请调整BATCH_SIZE或MAX_WORKERS。 -
解析失败:
如果文档解析失败,结果中将包含一个错误块,详细说明错误消息和页码。 -
URL 访问问题:如果无法从 URL 访问文档,请检查 URL 是否公开可访问并指向支持的文件类型(PDF 或图片)。
关于 include_marginalia 和 include_metadata_in_markdown 的说明
-
include_marginalia: 如果为 True,解析器将尝试从文档中提取并包含边注(页脚注释、页码等)。 -
include_metadata_in_markdown: 如果为 True,输出的 Markdown 将包含元数据。
这两个参数默认为 True。可以将其设置为 False 以从输出中排除这些元素。
示例:使用新参数
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(linefrom agentic_doc.parse import parseresults = parse("path/to/document.pdf",include_marginalia=False, # 从输出中排除边注include_metadata_in_markdown=False # 从 Markdown 中排除元数据)
项目地址
https://github.com/landing-ai/agentic-doc/blob/main/README.md
参考资料
安装: #安装
[2]支持的文件: #支持的文件
[3]解析大型 PDF 文件: #解析大型-pdf-文件
[4]结果模式: #结果模式
[5]保存定位为图片: #保存定位为图片
[6]批量解析多个文件: #批量解析多个文件
[7]自动处理 API 错误和速率限制: #自动处理-api-错误和速率限制
[8]主要函数: #主要函数
[9]配置选项: #配置选项
[10]API 文档: https://support.landing.ai/docs/document-extraction
[11]此处: https://va.landing.ai/account/api-key
[12]Google Drive API Python 快速入门: https://developers.google.com/workspace/drive/api/quickstart/python
[13]速率限制: https://docs.landing.ai/ade/ade-rate-limits#maximum-pages-per-document
[14]错误处理: #错误处理
[15]配置选项: #配置选项
[16]errors: ./agentic_doc/common.py#L75
[17]Settings: ./agentic_doc/config.py
会面: https://scheduler.zoom.us/d/56i81uc2/landingai-document-extraction
扫码加入技术交流群,备注「开发语言-城市-昵称」
(文:GitHubStore)