

阿里巴巴发布并开源了基于Qwen3大模型的 Qwen3 Embedding 与 Reranking 系列模型。该系列不仅在权威的 MTEB多语言嵌入任务上登顶榜首,其Reranker模型更是在多个基准上表现优异。其核心技术亮点在于,利用大模型自身能力“自我生产”训练数据,并提供了从0.6B到8B的全方位、可定制化模型矩阵,旨在从根本上解决AI应用中信息检索不准的难题。
AI应用的“最后一公里”,正在被重新定义
想象一个场景:你向公司的智能知识库提问:“上个季度欧洲市场的销售策略复盘报告在哪?” 几秒钟后,返回的却是一堆关于“欧洲旅游攻略”和“市场销售入门技巧”的无关文档。这种“答非所问”的尴尬,正是当前无数AI应用,尤其是 检索增强生成(RAG) 系统面临的普遍痛点——检索不准。
问题的根源,就出在这个被视为AI应用“心脏”的环节:语义表示与相关性排序。它决定了AI能否在浩如烟海的信息中,精准地“捞”出你真正需要的那根“针”。这是AI应用的“最后一公里”,也是决定用户体验的关键。
近日,阿里巴巴发布了一项重要的技术成果,直指这一核心领域。他们正式发布并开源了基于Qwen3基础模型的Qwen3 Embedding和Reranking系列。这并非一次常规的模型更新,而是通过引入新的方法,旨在将搜索精度推向新的高度。
模型矩阵与性能概览
在深入技术细节之前,我们先直观了解下Qwen3系列。阿里这次同时推出了两大核心模型系列:文本嵌入(Text Embedding)和文本重排(Text Reranking),并为每一类都提供了从0.6B到8B不等的多种尺寸,以满足不同场景的需求。
|
|
|
|
|
|
|
|
|
| 文本嵌入
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 文本重排
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
性能是检验模型的唯一标准。在被广泛认可的文本嵌入基准MTEB(Massive Text Embedding Benchmark)多语言排行榜上,Qwen3-Embedding-8B模型以70.58的高分登顶(截至2025.6.5)。
这一成绩表明,Qwen3在理解和表示全球多种语言的复杂语义上,达到了业界领先水平。
核心优势:性能、灵活性与多语言能力
Qwen3系列为真实世界应用设计了三个核心特性,展现了其强大的综合能力。
性能表现突出,数据是最好的证明
Reranker(重排模型)是提升搜索质量的关键步骤,它能在召回(Embedding)的基础上,对候选文档进行更精细的二次排序。我们来看Qwen3 Reranker的实战表现:
|
|
|
|
|
|
|
|
|
| Qwen3-Embedding-0.6B |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Qwen3-Reranker-0.6B |
|
|
|
|
|
|
|
| Qwen3-Reranker-4B |
|
69.76 |
|
|
|
|
14.84 |
| Qwen3-Reranker-8B |
|
|
77.45 | 72.94 | 70.19 | 81.22 |
|
表格数据清晰地显示,Qwen3-Reranker系列在多个基准上全面超越了现有的主流模型。尤其值得注意的是FollowIR指标,它衡量模型遵循指令进行检索的能力。Qwen3-Reranker-4B得分高达14.84,是其他同类模型得分的数十倍甚至更高,这体现了其在理解人类复杂、精细指令方面的卓越能力。
高度灵活,为不同场景量身定制
Qwen3提供了高度可定制的选项,赋予开发者前所未有的灵活性。
-
• 多尺寸选择(0.6B, 4B, 8B):开发者可以根据自己的业务场景和算力预算,自由权衡。轻量级端侧应用可以选择0.6B模型,而追求极致精度的大型企业搜索,则可以部署8B模型。
更核心的是两大定制化特性:
-
• MRL(Matryoshka Representation Learning)支持: 这一技术允许你训练一个高维度的嵌入模型,但在推理时可以根据需要截取任意低维度使用,且性能损失极小。这意味着**“一次训练,多场景部署”**,极大地提升了模型的部署效率和经济性。 -
• 指令感知(Instruction Aware): 这是一项关键特性。比如,对于模糊查询“苹果”,在没有指令时,模型可能会同时返回关于水果和公司的结果。但如果你加入指令 “为这条查询检索相关的电子产品”,模型就会精准地只返回苹果公司的相关信息。这种能力让通用模型具备了专用模型的能力,极大提升了在垂直领域的适配性。
支持百余种语言,打破跨语言信息壁垒
得益于Qwen3基础模型的多语言能力,Qwen3 Embedding系列支持超过100种语言,包括各种编程语言。这不仅是“能处理”多语言,而是具备强大的多语言检索(用中文搜中文)、跨语言检索(用中文搜英文资料)和代码检索(用自然语言描述找代码)能力。这对于构建全球化知识库或进行跨国业务的组织来说,意义重大。
技术解析:Qwen3是如何炼成的?
强大的性能背后,是模型架构和训练方法的双重创新。
模型架构:双编码器与交叉编码器的再进化
Qwen3系列沿用了业界成熟的架构,并基于强大的Qwen3基础模型进行了优化。
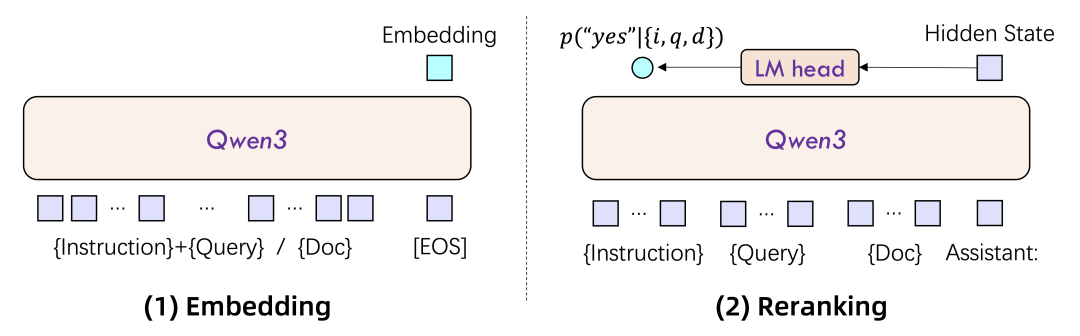
-
• Embedding模型采用双编码器(Dual-Encoder)架构。查询和文档分别编码成向量,再计算相似度。其优点是速度快,适合大规模召回。 -
• Reranker模型采用交叉编码器(Cross-Encoder)架构。查询和文档拼接后共同输入模型,进行深度交互分析。其优点是精度高,适合对少量候选集进行精细排序。
所有模型都采用了**LoRA(Low-Rank Adaptation)**进行微调,这是一种高效的参数微调技术,能在保留Qwen3基础模型强大通用文本理解能力的同时,注入特定于嵌入和重排任务的知识。
训练创新:当大模型开始“自我生成”数据
如果说架构是骨架,那么训练数据和方法就是灵魂。这也是Qwen3技术路径中最具启发性的地方。
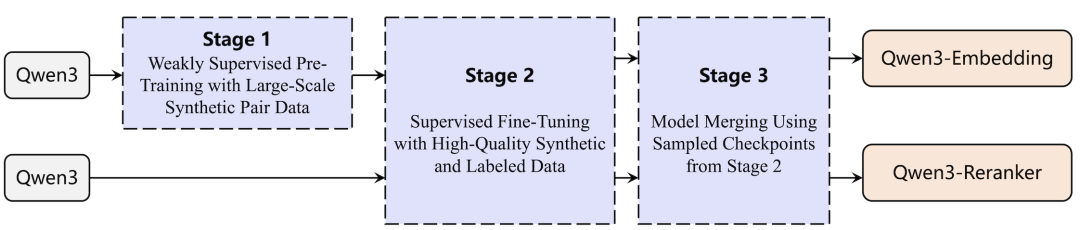
传统方法高度依赖于从网络社区挖掘问答对,或依赖已有的开源数据集,这些数据往往在数量、质量、场景和语言覆盖度上存在局限。
Qwen3团队提出了一个创新的思路:利用Qwen3大模型自身来生成训练数据。
他们开发了一套创新的多任务自适应提示系统,利用Qwen3基础模型的强大生成能力,动态地为不同任务类型和语言生成海量的弱监督文本对。这不仅是一个高效的数据获取策略,更是一种范式上的探索:大模型从一个被动的学习者,转变为一个能够为自我进化主动创造条件的主动参与者。
深度观察:4B模型反超8B?性能背后的信号
在Reranker性能表中,一个细节提供了值得深思的观察点:在MTEB-R和FollowIR这两个关键基准上,4B模型的表现超过了更大的8B模型。
-
• MTEB-R: 4B (69.76) vs 8B (69.02) -
• FollowIR: 4B (14.84) vs 8B (8.05)
在“模型越大越好”成为普遍认知的背景下,这个现象提示我们进行更深入的思考。
这背后可能有多重原因。一种可能是,对于某些特定任务,4B模型的参数规模已经达到了一个“甜点区(sweet spot)”,能够很好地捕捉任务所需的能力,而8B模型更多的参数可能带来了冗余。另一种可能是,4B模型在训练过程中更好地平衡了通用语义理解和特定任务(如指令遵循)这两项能力。
这个现象对所有AI从业者都提出了一个重要参考:在进行模型选型时,应停止盲目地“唯大是从”。 这组数据清晰地表明,“最合适的”远比“最大的”更重要。这意味着,有必要建立针对自身核心业务场景的评测基准(Benchmark),通过实际测试来选择性价比最高、效果最契合的模型。
未来展望:不止于文本,迈向多模态
Qwen3 Embedding系列的发布,是一个新的起点。根据其技术报告,未来的工作将聚焦于两点:一是持续优化,提升效率与性能;二是从文本走向更广阔的世界——建立跨模态的语义理解能力。
我们可以预见,当这种强大的语义表示能力从文本延伸到图像、音频和视频,一个全新的应用时代将被开启。未来的搜索将不再局限于文字:
-
• 你可以用一张赛博朋克风格的画,去搜索所有风格相似的设计作品。 -
• 你可以用一段激昂的旋律,去检索所有包含它的视频片段。 -
• 你可以用一句**“我想要一个能处理高并发用户登录的认证模块”**,直接在海量代码库中找到最匹配的功能实现。
这不仅仅是搜索的未来,更是AI与数字世界交互方式的演进。
开源开启新一轮创新浪潮
Qwen3 Embedding和Reranking系列的发布,是2025年AI领域一个重要的技术进展。它不仅通过扎实的性能数据再次提升了行业基准,更通过“数据自产”的训练范式和高度灵活的设计理念,为我们揭示了下一代AI基础设施的可能形态。
最重要的是,这一切都是开源的。这意味着,全球的开发者和研究者都可以基于这些强大的工具进行探索和创新。由Qwen3带来的这一轮“搜索精度”提升,其真正的潜力,将在整个社区的共同努力下被进一步激发。
推荐阅读
-
• Qwen3 Embedding GitHub仓库: 获取模型代码、技术报告和使用指南。 -
• 链接地址: https://github.com/QwenLM/Qwen3-Embedding -
• Hugging Face模型下载: 直接下载并体验Qwen3 Embedding系列模型。 -
• 链接地址: https://huggingface.co/Qwen
(文:子非AI)