

谷歌最新旗舰模型 Gemini 2.5 Pro 横空出世,官方数据显示其在多项关键基准测试中全面屠榜,尤其在代码、推理和事实性上表现惊人。它不仅带来了革命性的“Deep Think”深度思考模式,还延续了 100万 Token 的恐怖上下文窗口,堪称性能怪兽。
然而,在这场技术的“权力游戏”中,一线开发者社区却唱起了“反调”。大量实测反馈指出,尽管 Gemini 跑分无敌,但在处理复杂编程任务的“主观体感”上,却不如 Anthropic 的 Claude Opus 4 来得“优雅”和“可靠”。
这背后究竟隐藏着什么?是基准测试的“失灵”,还是谷歌在追求极致性能与用户体验之间的一次艰难取舍?本文将深入剖析 Gemini 2.5 Pro 的技术内核,揭开这场关于 AI 王座的“冰与火之歌”。
冰之篇章:冷酷的数字,无可匹敌的性能
谷歌每一次发布新模型,都像是在AI的竞技场上投下了一枚重磅炸弹。这次的 Gemini 2.5 Pro,其官方模型卡(Model Card)和性能报告,用一系列冰冷而强大的数字,宣告了新王的诞生。
架构与引擎:效率与力量的结合
Gemini 2.5 Pro 的核心,是经过精进的稀疏混合专家(MoE)Transformer 架构。这并非一个新概念,但谷歌的优化让它达到了新的高度。
-
• 智能“专家委员会”:想象一下,模型内部有无数个各有所长的“专家”。当一个任务(比如代码调试)到来时,路由网络会智能地只激活最相关的几个专家来处理,而不是让整个庞大的网络空转。这使得 Gemini 2.5 Pro 在保持巨大规模的同时,拥有极高的计算效率。 -
• 训练稳定性提升:模型卡中特别提到,通过对架构设计和优化方法的改进,显著提升了训练稳定性。这是谷歌能够在一个月内快速迭代(从 05-06到06-05版本)的关键,也是其能够持续探索AI能力极限的工程基石。

(图注:Gemini 家族不断壮大,Pro 版本是其中的旗舰)
“屠榜”的基准测试
让我们直面数据,看看 Gemini 2.5 Pro 究竟有多强。
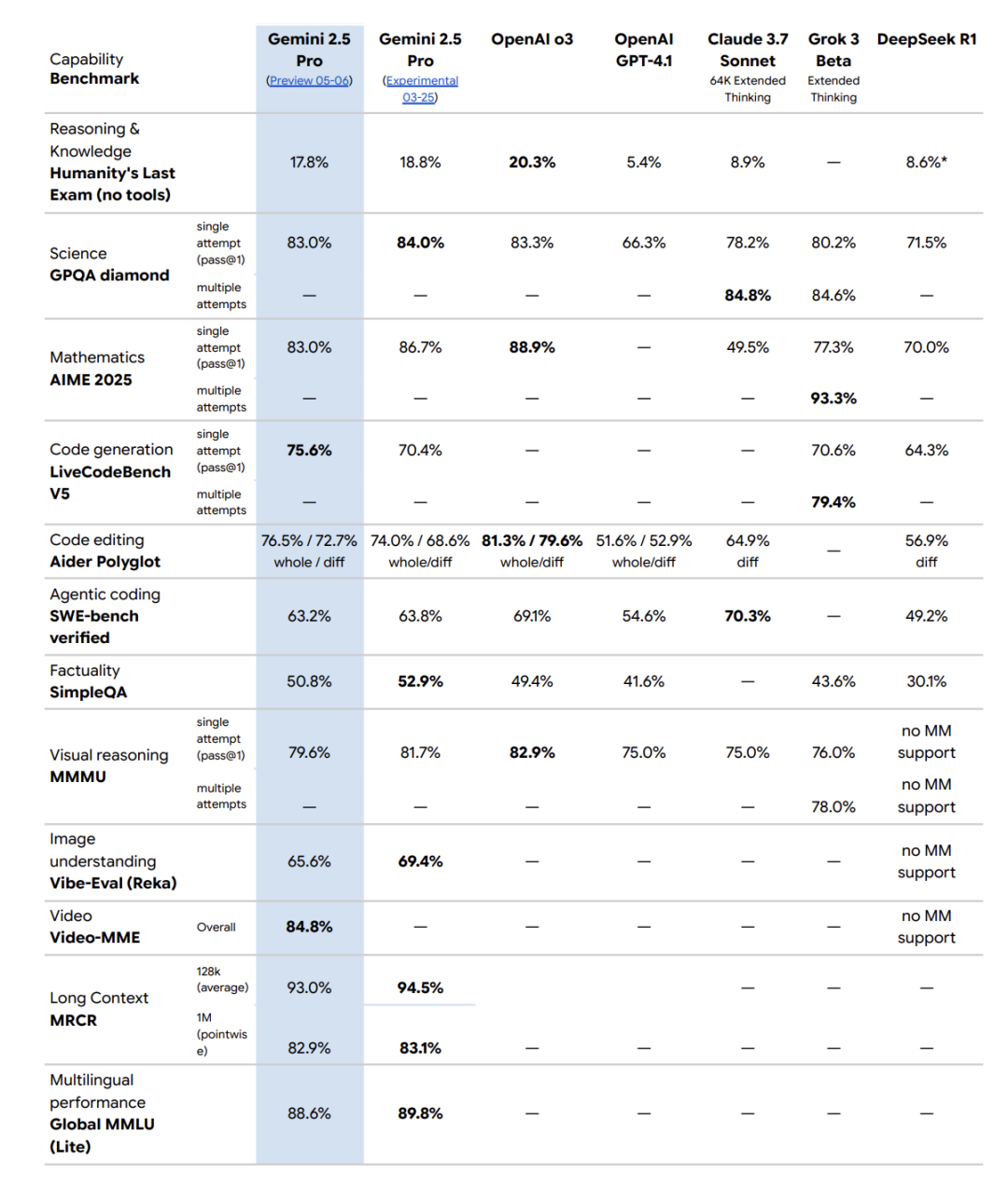
这张官方图表揭示了几个无可争议的事实:
-
• 代码能力登顶:在备受关注的“Aider Polyglot”代码编辑测试中,Gemini 2.5 Pro 以 82.2% 的高分,将 Claude Opus 4 (72.0%) 和 OpenAI o3 (79.6%) 甩在身后。 -
• 推理与事实性的王者:在考验模型综合知识与事实准确性的“Humanity’s Last Exam”和“FACTS grounding”测试中,其得分显著领先。 -
• 压倒性的性价比:在性能登顶的同时,其 API 输入价格($1.25/1M tokens)仅为 Claude Opus 4 的十二分之一,OpenAI o3 的八分之一。对于开发者和企业来说,这意味着可以用更低的成本获得最顶级的性能。
重磅新能力:超越数字的想象力
除了跑分,Gemini 2.5 Pro 还带来了两个足以改变游戏规则的新功能。
-
• Deep Think (深度思考):这不仅仅是“更快更强”,而是一种全新的工作模式。模型卡透露,它借鉴了并行思维(parallel thinking)等前沿研究。这意味着 Gemini 在给出答案前,会像一个顶尖顾问团,同时探索、评估多条推理路径,最终选择最优解。这对于解决需要深度逻辑和多步规划的复杂问题至关重要。 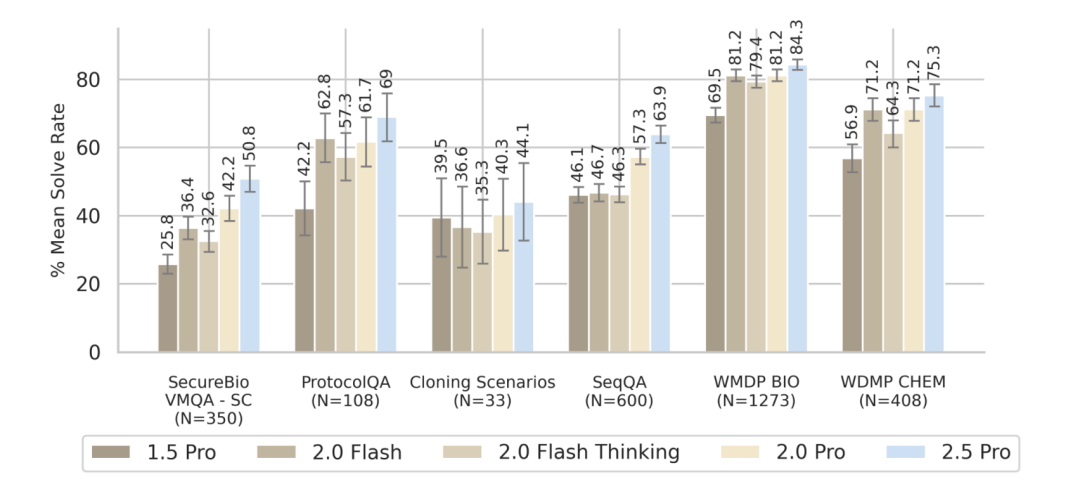
-
• 原生多模态与超长上下文:模型从底层就能理解和处理文本、图像、音频、视频的混合输入,并支持 100万 Token 的上下文窗口。这意味着你可以扔给它一部几个小时的电影、一整个代码库,或者海量财报,并要求它基于这些信息进行创作或分析。 -
-
(官方展示了其流畅的多语言原生音频输出能力)
火之篇章:炽热的反馈,开发者的“体感”
如果说官方数据是冰冷的北境,那么开发者社区的反馈就是炽热的龙焰。在这里,Gemini 2.5 Pro 的“王者”光环,遭遇了前所未有的挑战。
“跑分之王”的真实世界困境
一位资深开发者的帖子引爆了讨论。他分享了在处理复杂 TypeScript 问题时的经历:
“我感觉 Opus 完全是另一个层次的。面对一些恶心的 TypeScript 问题,Gemini 试了几次后就开始兜圈子,甚至(我从没见过这种情况!)直接放弃,说‘我做不到’。而 Opus 毫不费力地就解决了同样的问题。”
这个案例迅速引发了连锁反应,大量开发者分享了类似的“体感”差异。核心的批评指向了几个方面:
-
• 代码“品味”不佳:许多人认为 Gemini 的代码风格“冗长”、“业余”,倾向于用“笨办法”解决问题,而 Claude Opus 4 的代码则被赞为“优雅”、“简洁”,更像出自一位经验丰富的架构师之手。 -
• 上下文“失忆”:尽管拥有百万级的上下文窗口,但在连续的多轮对话中,Gemini 却频繁被指责“遗忘”了之前的讨论,这对于需要反复调试的开发工作流是致命的。 -
• 沟通效率问题:反馈称 Gemini 喜欢添加大量“# 我在这里加了个函数”之类的无用注释,增加了代码审查的负担。
技术解释:“体感”差异从何而来?
这种“跑分”与“体感”的割裂并非玄学,背后可能有深刻的技术原因。
-
• 训练数据的“烙印”:模型的“性格”和“品味”很大程度上由其训练数据决定。Claude Opus 4 可能在训练中接触了更多高质量、风格统一的开源代码库和技术文档,从而内化了一种更受资深开发者青睐的“编码哲学”。 -
• 基准测试的局限性:当前的基准测试(如 Aider Polyglot)虽然优秀,但它们测试的往往是“能否正确完成任务”,而无法衡量“完成任务的方式是否优雅、可维护”。这正是“体感”差异的核心所在。 -
• 指令微调的导向:模型的后训练阶段(RLHF等)对其行为有决定性影响。谷歌可能更侧重于任务完成率和事实准确性,而 Anthropic 可能在微调中加入了更多关于代码质量、简洁性和可读性的偏好。
冰与火的交融:如何选择你的AI战友?
Gemini 2.5 Pro 的发布,让我们清晰地看到,AI 的王座之争,已不再是单维度的性能竞赛。它变成了一场在性能、体验、成本和安全之间的复杂权衡。

(图注:Gemini 2.5 Pro 强大的代码生成能力,可以快速创建复杂的可视化应用)
-
• 选择 Gemini 2.5 Pro 的理由: -
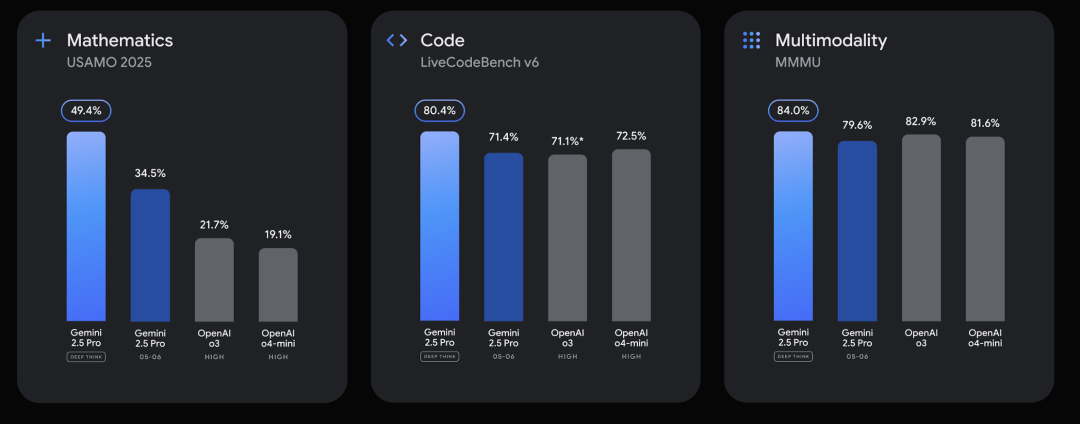
• 任务驱动:当你的工作是处理海量数据分析、进行大规模代码审查、或需要最高性价比时,Gemini 2.5 Pro 几乎是无与伦比的选择。 -
• 探索未知:如果你想利用“Deep Think”和原生多模态能力构建前所未有的应用,Gemini 2.5 Pro 提供了最强大的技术基座。 -
-
• 选择其他模型的考量: -
• 体验至上:如果你追求极致的开发体验,需要一个能与你“心有灵犀”、代码风格优雅的AI伙伴,那么 Claude Opus 4 可能是更合适的选择。 -
• 特定场景:有趣的是,在一些开发者心中,发布已久的 OpenAI o3 在特定场景下的代码质量和稳定性依然无可替代。
超越跑分的进化
Gemini 2.5 Pro 是一次毋庸置疑的技术飞跃。它在架构效率、推理深度和多模态融合上树立了新的标杆。然而,它引发的“口碑两极”现象,比其本身的技术参数更具启发意义。
它告诉我们,AI 的进化,正从一场追求“更快、更高、更强”的奥林匹克竞赛,转变为一场探索“更懂我、更合拍、更可靠”的艺术之旅。在这条路上,没有永远的冠军,只有不断进化的伙伴。
你,又会选择谁与你同行?
推荐阅读
互联网女皇”首份AI报告深度解读
-
“互联网女皇”首份AI报告深度解读:科技大爆炸前夜,谁主沉浮?
-
Gemini 2.5 Pro 官方模型卡: -
• 链接地址: https://storage.googleapis.com/model-cards/documents/gemini-2.5-pro-preview.pdf
(文:子非AI)