

新智元报道
新智元报道
【新智元导读】AI顶流Claude升级了,程序员看了都沉默:不仅能写代码能力更强了,还能连续干活7小时不出大差错!AGI真要来了?这背后到底发生了什么?现在,还有机会加入AI行业吗?如今做哪些准备,才能在未来立足?
Claude 4发布了,开发者解放了?
在Dwarkesh Patel主持的节目中,Anthropic的Sholto Douglas、Trenton Bricken等人,一起讨论了Claude 4是如何思考的。

三人私交甚好,聊了2小时20多分钟,主要集中在4个话题:
1. 过去一年中人工智能研究的变化;
2. 新的强化学习(RL)体系以及其可扩展性;
3. 如何追踪模型的思考过程;
4. 各国、劳动者和学生应如何为通用人工智能(AGI)做准备。

对于Sholto Douglas的「AI取代人类白领工作」观点,网友纷纷表现出了极大的兴趣。

另外值得一提的是,Sholto Douglas在清华大学交流学习过。

过去一年最大的变化是:强化学习(RL)终于在语言模型上真正奏效了。
这一点现在有了明确的证据:如果提供合适的反馈机制,确实找到了某种算法,能让模型表现出接近专家级人类的可靠性与性能。
目前,这种成果最明确地体现在两个领域——
程序设计竞赛(competitive programming)和数学推理。
任务的难度可以分为两个维度来理解:
一个是任务的智力复杂度(intellectual complexity),
另一个是任务所涉及的时间跨度(time horizon)。
现在已经证明,模型确实可以在多个维度上达到人类智能的顶峰。
当然,长期自主表现(long-running agentic performance)还欠佳,但它正在「蹒跚起步」。
预计到今年年底,我们将看到更明确的进展——
语言模型能完成实际工作,就像真正的软件工程师那样。

现在看到的真正限制,其实是:
-
缺乏上下文信息(lack of context),
-
难以处理复杂的、跨多个文件的变更(multi-file changes),
-
以及任务本身的模糊性或规模不清晰的问题(scope of change/task)。
LLM可以处理智力高度复杂的问题,但前提是问题上下文要明确、边界要清晰。
如果任务比较模糊,或者需要在环境中反复探索、试错、迭代,它们就会吃力。
只要你能为模型提供一个良好的「反馈闭环」(feedback loop),它通常就能做得不错;但如果这个闭环不清晰,它就容易「迷路」。
具体而言,就是「可验证奖励的强化学习」(RL from verifiable rewards)。
它的核心是:奖励信号必须是「干净」的,也就是说——它必须准确、明确、客观。
最早语言模型的调优方法是RLHF(Reinforcement Learning from Human Feedback,从人类反馈中强化学习),典型的形式是「成对反馈」(pairwise feedback),即:
人类对两段输出打分,告诉模型哪一段更好。
随着训练迭代,模型生成的输出越来越接近人类「想要的答案」。
但问题在于,这种方法并不能真正提升模型在「高难度问题」上的表现,因为人类其实不是很擅长判断「哪个答案更好」。
所以,更理想的是提供一种能客观判断模型输出是否正确的信号。
比如,数学题的正确答案;代码是否通过了单元测试。
这类都是典型的、非常干净的奖励信号(clean reward signal)。
比如说,完成诺奖级研究所涉及的任务,往往具备更多层次的「可验证性」。
相比之下,一部「值得获奖」的小说需要的是审美判断与文学品味,
这些就非常主观,难以量化。
所以模型很可能会更早地在科学研究领域实现「诺奖级突破」,而不是先写出一部能赢得普利策奖的小说。

普利策奖奖章
但至少两位创作者,已经用LLM写出了完整的长篇书稿。
他们都非常擅长为设计文章结构和提示(scaffolding&prompting)。
也就是说,关键不是模型不行,而是你会不会用。
本质上,「电脑操作智能体」(Computer Use Agent)和「软件工程」智能体没有多大区别。
只要能电脑操作把表示成token输入,LLM就能处理。
模型现在能「看图」,能画图,能理解复杂的概念,这些基本已经实现。
电脑操作唯一的区别是:比数学和编码更难嵌入反馈回路中。
但这只是难度更高,不代表做不到。
而且,大家低估了现在AI实验室到底有多「糙」。
外界以为这些实验室运转得像完美机器,其实完全不是。
这些大模型的开发流程,实则是在巨大的时间压力下仓促构建的。
-
团队人手严重不足
-
优先级很难排
-
每一步都是在「边干边补」的状态下推进的
实验室在疯狂招人、培训人,根本还没轮到把「AI操作电脑」当作重点。
相比之下,「编码」是更有价值、也更容易落地的方向。所以更值得优先集中资源突破。
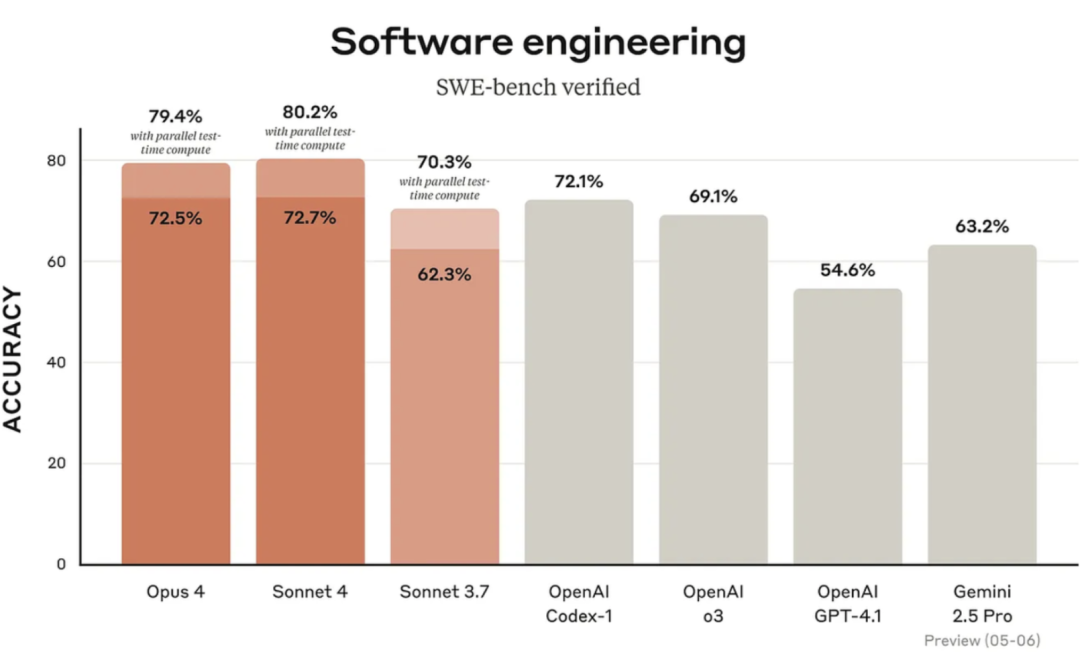
在软件工程基准测试SWE-bench中,Claude4与其他模型的比较
一旦模型能搞定代码,价值会呈超级指数级释放。 而电脑操作虽然也重要,但优先级自然就排后面了。
还有个被低估的因素:研究员们喜欢研究他们认同的「智能标准」。
为什么是数学、竞赛编程先突破?因为那是他们认可的「聪明」。
他们觉得:「要是模型能在AIME(美国数学竞赛)上赢我,那才是真的强。」
但你让它做Excel报表?无人在乎。
所以现在的局面是: 模型在他们心目中已经够聪明了,但大家还没把精力花在「电脑操作」这块上。
一旦资源倾斜过来,这块进展也不会慢。
Ai2的科学家Nathan Lambert,也认同这种观点:
RLVR没学会新技能,是因为投入的算力不够大。
如果投入算力总量的10%-25%,我猜模型会让人刮目相看。

如果未来一两年内,智能体开始上岗,软件工程实现自动,模型的使用价值将呈指数级增长。而这一切的前提,是海量算力的支持。
关键在于推理的算力问题,但这被严重低估了。
目前,全球大约有1000万张H100级别的算力芯片。
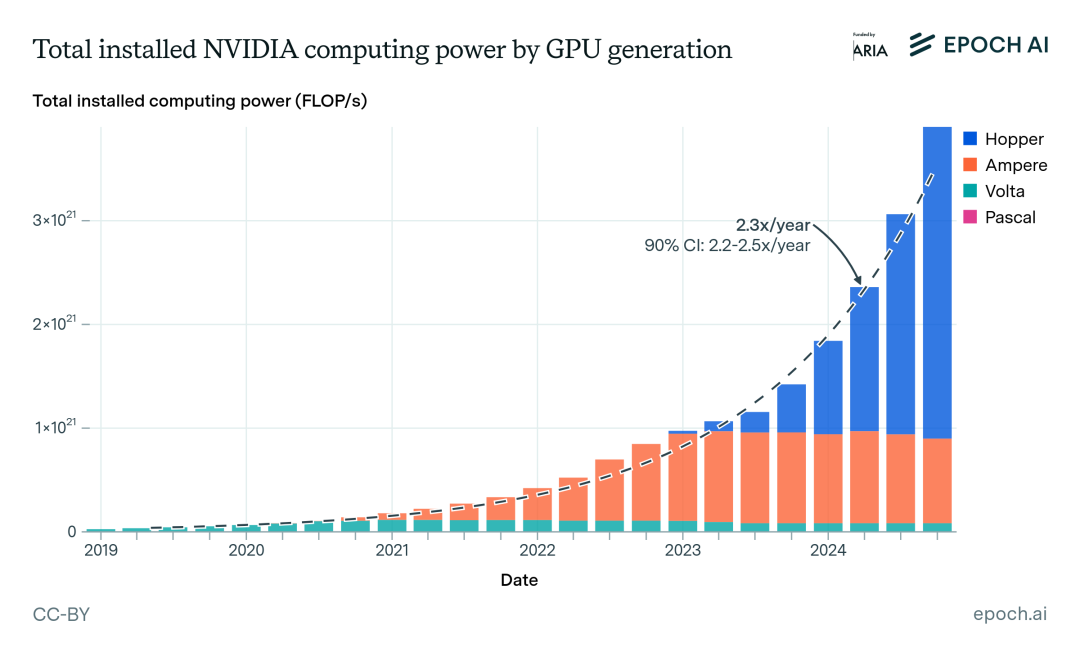
Epoch AI估算的GPU算力变化和趋势
有研究估算,一张H100的浮点运算能力,大致相当于一颗人脑。
如果以AGI达到人类推理效率为假设,这意味着今天的地球上,理论上已经能同时运行1000万个AGI。
这个数字到2028年预计将达到1亿张。但即便如此,可能仍不够。
因为人类正以每年2.25到2.5倍的速度扩张算力,但在2028年左右,将迎来上限:晶圆产能的物理瓶颈。
建厂周期很长,一旦触顶,算力增长就会放缓。
再者,有些人认为人类离真正拥有长上下文、一致意图、强多模态能力的AGI还很远。
这正是在「AGI实现速度」上,业内意见分歧的关键所在。
这背后有两个关键认知差异:
第一,业内很多专家认为——要在长上下文推理、多模态理解等方面实现突破,没那么快。
人类级别的推理能力,通常需要算力提升几个数量级才能支撑。
第二,芯片问题,还包括电力、GDP等限制等可能让算力增长停滞,而如果到2028或2030年还没实现AGI,那之后每年的实现概率,也许就会开始大幅下滑。
窗口期,稍纵即逝。
就AGI实现问题,Leopold Aschenbrenner写了Situational Awareness。

Leopold Aschenbrenner:专注于AGI的投资人,OpenAI超级对齐团队前成员
其中,有个小标题就叫做「This Decade or Bust」,大意为「这十年,不成则废」。
意思是:我们能不能搞定AGI,基本就看这十年了。
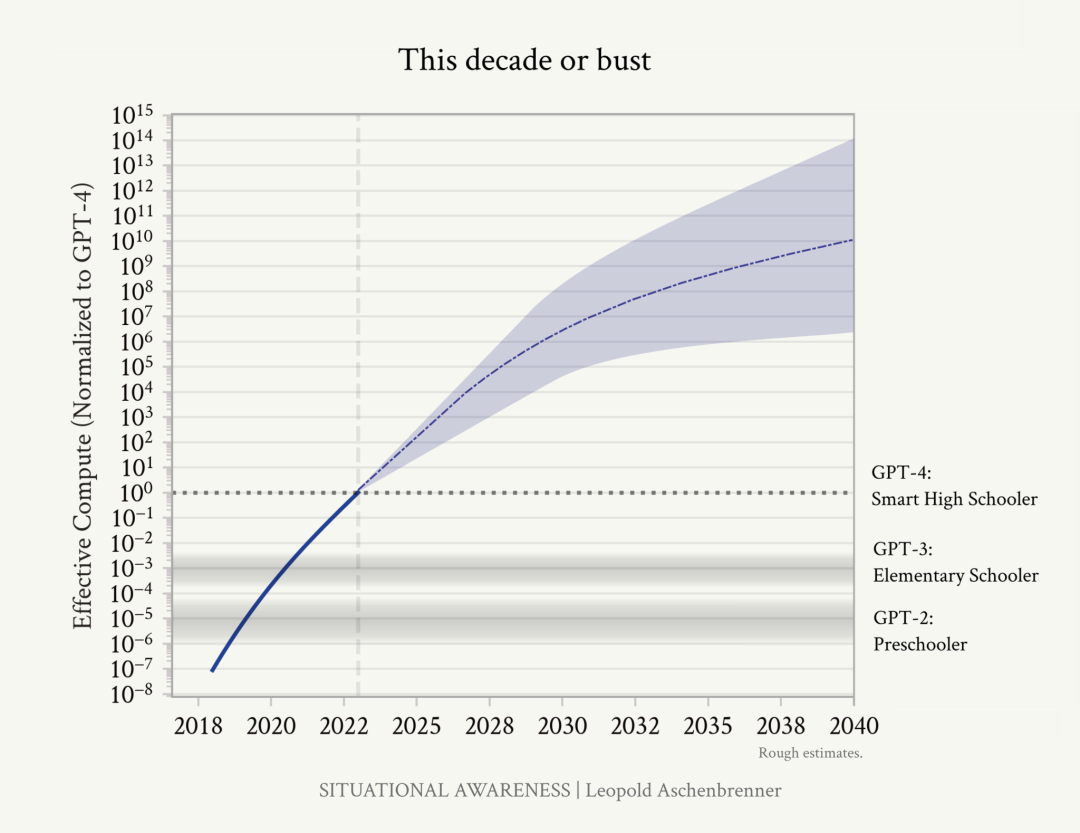
长文中对有效算力的预测
未来几年,还可以显著增加训练算力,特别是在强化学习(RL)上。
2025年,RL非常值得关注,因为往里面投入的算力会远超以往。
在RL阶段用,DeepSeek-R1和o1的是差不多的算力,所以年初它们之间差距不大。
但随着时间推移,算力差距会被逐渐放大,带来明显的结果分化。
但DeepSeek不断碰到非常底层的硬件限制,然后思考:
理想条件下,我们想表达的算法是什么?
在现实限制下,我们又能表达什么?
在不断试错中,DeepSeek一步步迭代出更优的「约束兼容解」。
而且最难得的是——
新方案通常非常简洁优雅,再加上超强的工程能力,效果就出来了。
还有一个有意思的地方:他们引入了Meta提出的「multi-token prediction」方法。
Meta当时发过论文,讲的是一次性预测多个token,而不是传统的逐token预测。

论文链接:https://arxiv.org/abs/2404.19737
这一思路挺聪明的。
但奇怪的是,Meta后来并没有把这个方法应用到Llama系列模型里,而DeepSeek却在他们的新模型论文中实现了。
具体原因无人知晓,但这个差异很值得玩味。
部分人觉得AI发展会很慢,比如说AlphaGo虽然厉害,但它离真正的通用人工智能(AGI)还很远:
你看看AlphaGo,它已经能主动探索,AlphaZero还能泛化到新的视频游戏,看起来拥有了一整套与世界互动的先验能力。
但显然,现在回头看,虽然现在深度学习还在使用其中很多方法,但AlphaZero本质上并不是「AGI雏形」。
所以关键问题是:
为什么LLMs比AlphaZero更接近AGI?
为什么只加一点点训练、注意力或结构调整,就可能达到「类人智能」?
AlphaZero所处的任务环境——双人对战、完全信息游戏
——对强化学习算法太「友好」了。
相比之下,要构建真正类似AGI的系统,你必须搞定的是:
-
对现实世界的「通用概念理解」
-
对语言的掌握
-
能从真实任务中提取奖励信号,而这些任务往往不像游戏那样容易定义
回顾过去十年的AI讨论,有一种传统看法是:
AI是线性尺度:先是「愚蠢的AI」,然后是AGI,最后是ASI(超级智能)。
但模型其实呈现出「锯齿状」特征:
它在某些环境里表现特别好(因为训练数据丰富),在另一些就不行。
那么问题来了:
我们还能把它们称为「通用智能」吗? 还是说,它们只是「训练在哪就聪明在哪」?
这和GPT-2时代的讨论很像。
当时大家发现:小模型只要在某个任务上做微调(fine-tune),效果就很强。
但到了GPT-4这种规模,用足够多样的数据、足够大的计算量去训练,它就能天然泛化到很多子任务上,而且比那些「专门训练的小模型」泛化得更好。
强化学习现在也在走同样的路径:
-
一开始模型的能力很「锯齿」
-
但当我们把RL的规模拉大,总算力足够大,就会看到从「专才」向「通才」过渡
现在我们已经看到了一些早期迹象,比如模型在推理类任务上的泛化能力,开始显现。
有一个很好的例子是:「回溯能力」的出现(backtracking)。
模型会尝试一条解法,然后「啊这不行」,重新走另一条路径。这种「反思式推理」正是RL训练难题过程中逐步显现出来的。
所以大家总说:「AI只擅长被RL训练过的任务」。
但别忘了,这些任务本身就是语言、科学、编码、心理状态等多种领域的融合。
要做好这件事,AI模型不仅要是个优秀程序员,还得能用语言清晰思考,甚至有点哲学家气质。
而它确实已经在从训练中泛化出这种混合能力了。
这才是我们真正接近「通用智能」的原因。
这并不是说AI一定会做某件事,或一定会朝某个方向发展。
但如果你问:「什么才是真正有经济价值的?」
现在的AI正在学会写代码。
而人类最有价值的能力,可能就是——
成为出色的机器人。
最后回到那个核心问题:AI智能体将开始实际使用电脑,完成白领工作,为什么是未来几年内的事?为什么不是几十年?
关键是:这种未来是不是即将到来?
我们该做的,是构建一个类似SWE-bench的评估系统。
不仅评估软件工程,还要扩展到所有白领工作。
把它们拆解成可衡量的任务,进行跟踪和测量。
比如:你能不能靠互联网赚钱?这是一个非常清晰的奖励信号。
但要做到这一点,需要一整套复杂行为组合。
如果用这种「容易判断的奖励信号」进行预训练,会非常有帮助。
例如:
-
网站能不能正常运行?
-
页面有没有崩?
-
用户喜欢吗?
这些信号都可以用来训练模型。
只要模型能完成这条「长路径」,它就能学到真正有用的能力。
相反,如果一直卡在
「每生成5个token就要给一次奖励」的模式, 训练过程会变得非常慢,效率也很低。
假设能用美国全部电脑的屏幕行为数据,只要预训练一次,就可以设计出完全不同的强化学习任务。
这是理解强化学习的关键思维方式:
只要能拿到最终奖励,长任务反而更容易评估效果。
比起只用互联网上现有的公开数据,这种训练方式会强得多,泛化能力也更好。
接触到的数据越多,设计的训练任务就越丰富。
我们需要构建连续分布的行为数据库。
但这也带来一个问题:
当模型处理的任务越来越长、越来越复杂,它拿到 第一个奖励信号 的时间也会越来越久。
这意味着:每完成一次任务,所需的算力也会显著增加。
所以整体进展的速度,可能会因此变慢。
因为你必须花更多计算资源,才能判断一次任务是否成功。
这个说法直觉上没错。
但别忘了,人类面对困难任务时,非常擅长拆解步骤、重点练习难点。
一旦模型把基础能力打牢,AI也可以像人一样:跳过简单部分,专练最难的环节。
没有什么通向AGI的神奇捷径。
你要想搞出真正通用的智能系统,
就必须扩规模、上大模型,愿意为此付出更多计算成本。
这就是「苦涩的教训」,必须接受。

图灵奖得主Richard S. Sutton提出了强化学习的「苦涩的教训」
当然,也不是说无脑堆大。
真正的科学问题是:
什么时候用RL最合适?
因为需要模型不仅能「学」,还能在稀疏奖励下自己「发现要学什么」:
如果模型太小——推理很快,但学不到什么有用的东西;
如果模型太大——学得快,但推理太慢,算力消耗太大,不划算。
所以这其实是一个「帕累托前沿」(Pareto Frontier)问题:
在当前这套模型能力+训练环境下:
-
哪种模型大小最优?
-
哪个点的学习效率和算力开销最平衡?
这就是现在大家都在做的「平衡的科学」。
尤其在强化学习中,模型要生成大量token,才能从中学习并获取反馈。
这部分对推理能力和执行效率的要求非常高。
训练再好,如果推理慢或太贵,也难以落地。
这就是「训练好」≠「实用性好」的现实挑战。
那如果你是大学生,或者刚开始职业生涯的人,现在该怎么办?
Sholto Douglas等人建议:
别只押注一个未来。
想象整个「可能世界的光谱」,提前为它们做准备。
最可能发生的情况是:你将拥有远超以往的杠杆能力。
其实,这已经开始了。
很多YC初创公司,已经靠Claude写出大部分代码。
想象一下:
-
如果你手边有10个工程师听你调度,你会做什么?
-
如果有一家AI公司听命于你,你能解决哪些问题?
-
以前够不着的事,现在突然「能做」了。
你要为这样的未来做好准备。
当然,这一切仍然需要技术深度。
也许某一天,AI会在所有领域全面超越人类。但在那之前,还有一个很长的「合作阶段」。
黄仁勋曾说过:「我身边有十万个通用智能, 但我依然有价值。 因为是我在告诉它们目标是什么。」
在未来很多年里,人类仍然非常重要。 只要那一天还没到,你就还有机会和价值。
所以,请做好准备,迎接多个版本的未来。
如果真的全被AI取代,那你做什么都无所谓;但在所有其他可能性中,你的选择非常重要。
更重要的是:认真想清楚,你最想改变世界的是什么?
你可以学,而且比任何时候都容易。
每个人都拥有了「无限完美的私人导师」。
别让你以前的工作方式或专业背景变成束缚。
短期内,需要认真思考:
-
现在做的哪些事,AI其实可以做得更好?
-
然后去试一试,动手探索。
现在还有太多「唾手可得」的效率提升空间。
很多人甚至连完整提示都没写过、没举过几个例子、没把AI接入工作流程,就放弃了。
人类本身就是生物意义上的通用智能。很多有价值的能力是通用的。
你以前学的专业、积累的经验,可能没你以为的那么限制你。
Anthropic的很多员工也不是「AI出身」。
但他们天赋强、动机足、脑子快,来自各个领域,却都能做得很好。
不需要什么「权威机构」的许可,才能进入AI领域。
只要你愿意开始、愿意尝试、愿意申请,你就可以参与,也能为AI做贡献。
(文:新智元)