
高效的提示词设计需要在“提供足够上下文让模型理解任务”与“保持提示简洁提高执行效率”之间找到恰当平衡。
此外,许多实际应用涉及处理长文档或复杂的多步骤任务,这往往会超出模型的上下文窗口。
掌握应对这些挑战的技巧,对于构建稳健的 AI 应用至关重要。
本教程将探讨在使用大语言模型时如何管理提示词的长度与复杂度。我们将重点关注两个方面:
1. 在提示词中平衡细节与简洁性
我们将介绍如何构造既有足够上下文又避免冗长的提示词。这包括:
-
使用清晰简练的语言
-
借助提示模板提高一致性和可复用性
2. 处理长上下文的策略
处理超长输入时,可采用以下方法:
-
分块(Chunking):将长文本拆分成较小的、可管理的段落
-
摘要(Summarization):对长文本进行压缩,同时保留关键信息
-
迭代处理(Iterative Processing):通过多次调用 API 逐步处理复杂任务
教程中将通过具体示例演示这些方法,借助 Qwen3 模型和 LangChain 库实现。
通过本教程的学习,你将掌握如何高效地管理提示词的长度与复杂度。这些技能将帮助你构建更高效、更稳定的 AI 应用程序,能够胜任各种文本处理任务。
平衡提示词中的细节与简洁性
我们先来看看如何在提示词中平衡信息的详尽程度与语言的简洁性。下面我们将对比一个详细提示词和一个简洁提示词所生成的回答。
详细提示词
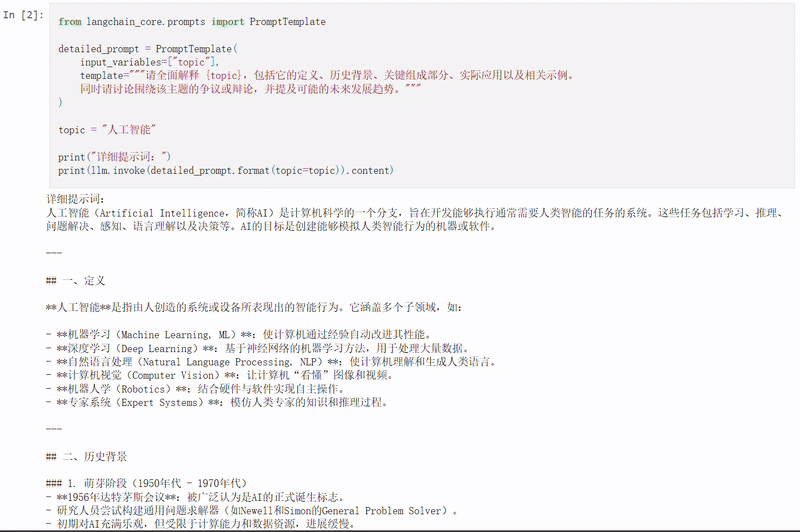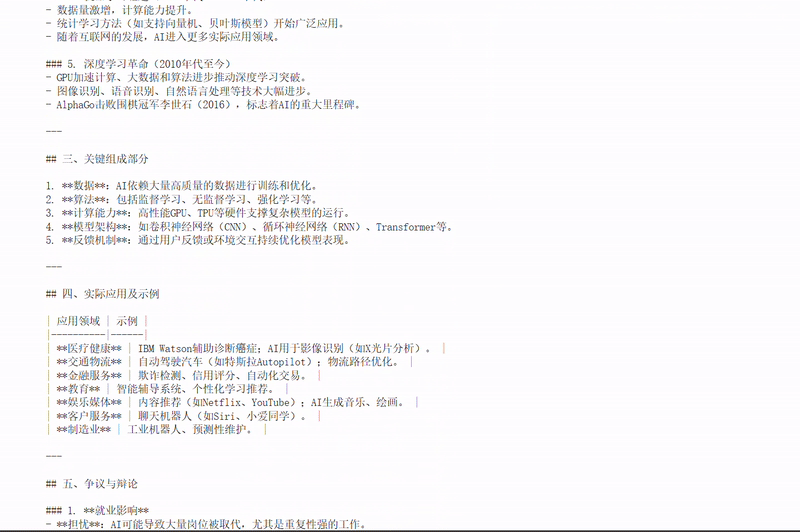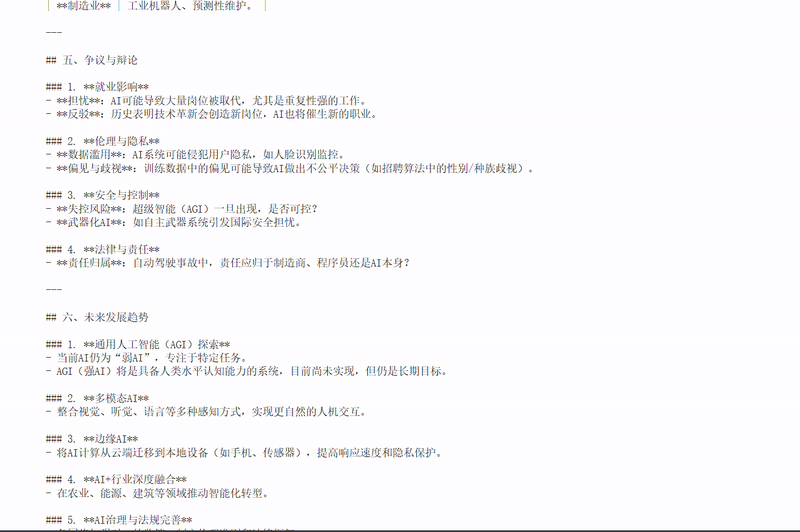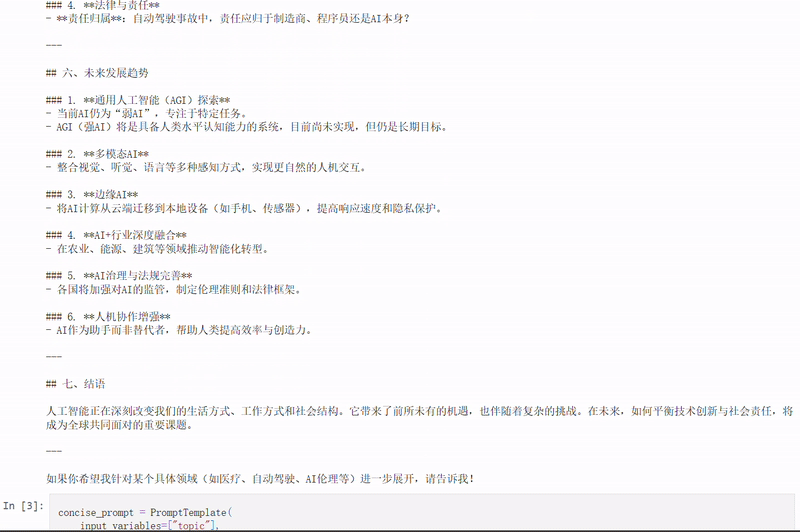
简洁提示词
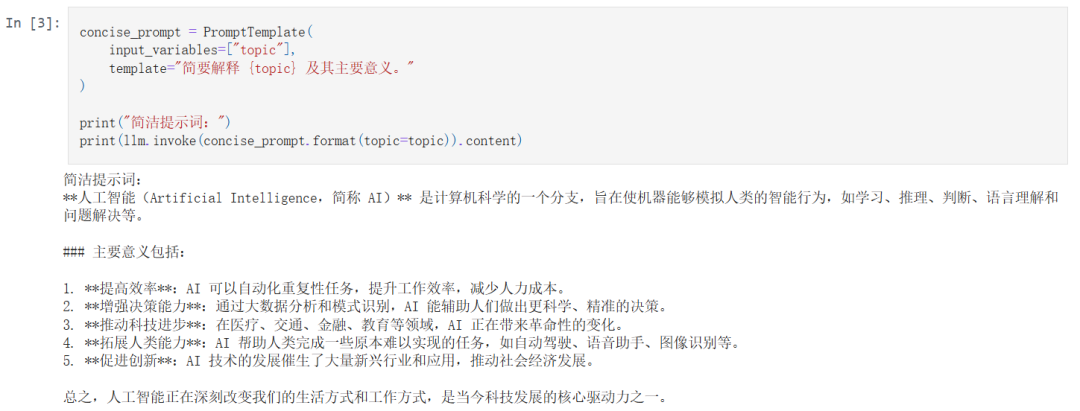
通过对比这两种风格的提示词,你可以更好地理解如何根据实际需求选择合适的提示结构,从而在细节丰富性与响应效率之间取得平衡。
提示词平衡性的分析
我们接下来要分析详细提示词和简洁提示词之间的差异,并探讨如何在实际使用中找到合理的平衡策略。

这种方法可以帮助你系统性地评估不同提示结构的优劣,进而优化你自己的提示工程策略。
处理长上下文的策略
接下来我们来探讨如何处理超出语言模型上下文窗口限制的长文本。以下是几种常见策略。
原始长文本内容示例:

1. 分块(Chunking)
分块是指将一段过长的文本切分为更小、更易处理的片段。我们以下面这段关于人工智能的长文为例,演示如何进行文本分块处理。
我们使用 LangChain 中的 RecursiveCharacterTextSplitter 来对文本进行分块:

这段代码将文本切分为若干块,每块长度约为 1000 字符,块与块之间重叠 200 字符,以保持上下文连贯。
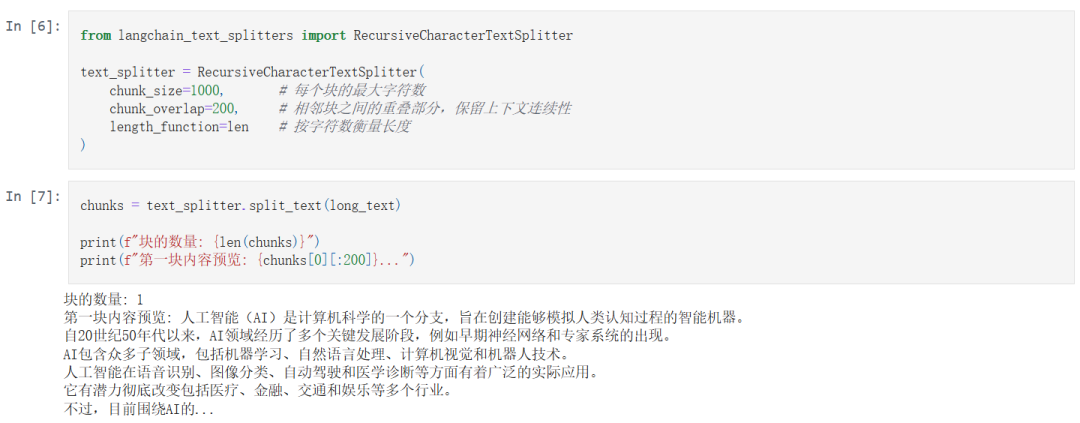
这种分块策略可以帮助你将超长输入分解为模型可接受的部分,并配合总结、问答、搜索等操作,逐步处理和提取信息。
2. 摘要(Summarization)
摘要是一种压缩长文本内容,同时保留关键信息的有效方法。下面我们将使用 LangChain 的摘要链(summarization chain)来演示这一过程。
首先,将之前分块得到的文本转换成 Document 对象,便于后续处理:
然后,使用 LangChain 提供的 load_summarize_chain 方法,选择 "map_reduce" 模式(适合处理较长文本):
最后,调用摘要链对文档块进行处理,并输出结果:
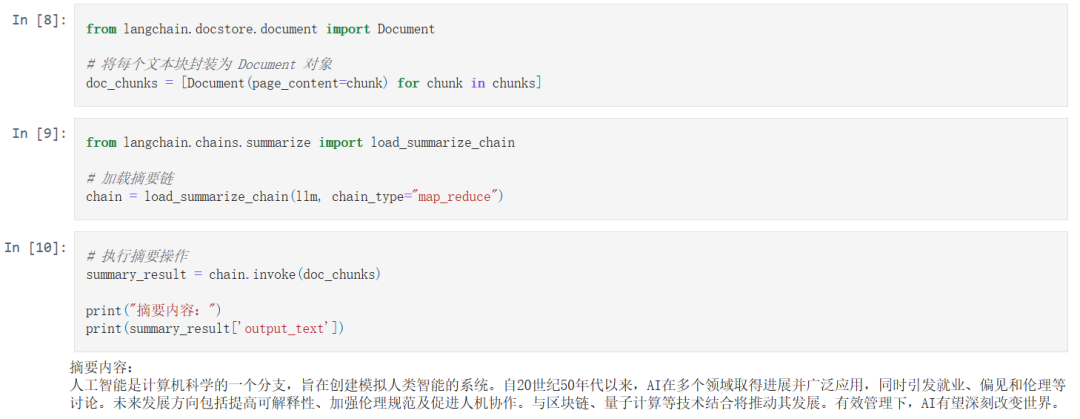
使用摘要链可以在不牺牲重要信息的前提下,大幅压缩文本长度,适合于:
-
报告生成
-
用户快速浏览
-
为后续问答或推理做准备
(文:PyTorch研习社)