
触觉在提升机器人的感知与交互能力方面占据关键地位。当前触觉领域主要聚焦于视觉和触觉模态,而对语言模态的探索较为有限。北京交通大学计算机学院联合北京邮电大学人工智能学院方斌教授团队、腾讯微信AI团队发布了首个大规模触觉、多粒度语言、视觉三模态数据集Touch100k,并提出TLV-Link预训练方法,为材料属性识别和抓取预测任务提供了高效的触觉表示能力,特别是在零样本触觉理解方面取得显著进展,为触觉领域注入了新的活力。论文[1]已被Information Fusion (SCI 1区,影响因子14.8)。

论文链接:https://doi.org/10.1016/j.inffus.2025.103305
项目主页:https://cocacola-lab.github.io/Touch100k/
▍Touch100K: 触觉、多粒度语言、视觉三模态数据集
基于视觉的触觉传感数据通常以触觉图像和视觉图像的形式呈现,相关研究主要聚焦于触觉与视觉模态的融合,而对语言模态的探索往往仅限于为传感数据附加类别标签。研究团队从多模态角度出发,旨在推动触觉感知从“看”和“摸”扩展“表述”,通过语言更细致地表达触觉信息。这一目标体现在Touch100k数据集的三重组成上:触觉图像、视觉图像与多粒度语言描述。其中,触觉图像和视觉图像来源于公开可用数据集Touch and Go[2]和VisGel[3]的接触帧,经过统一收集与处理获得;多粒度语言描述则通过人机协作的方式生成,涵盖了对触觉信号的词组级和句子级文本表述。

图 1 Touch100k数据集的示例数据
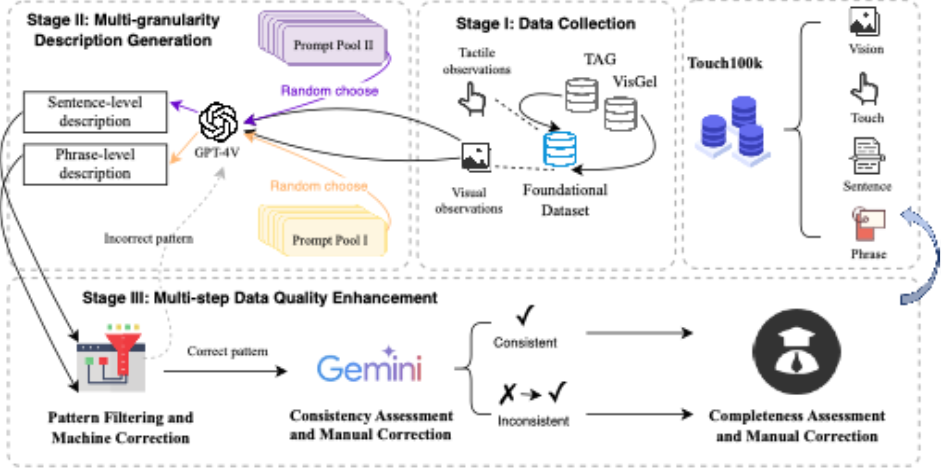
图 2 Touch100k数据集的构建过程
▍TLV-Link: 用于触觉表征的多模态预训练方法
基于Touch100k数据集,研究团队提出了一种用于GelSight触觉表征的多模态联合学习方法,名为TLV-Link。TLV-Link包括两个阶段:用于触觉编码的课程表示和模态对齐。在课程表示阶段,方法采用“教师-学生”课程范式,其中经过充分训练的视觉编码器作为教师模型,将知识传递给学生模型,即触觉编码器。具体而言,用于触觉编码的课程表示被定义为视觉表示和触觉表示的加权组合。最初,由于学生模型的能力有限,课程表示主要依赖于教师模型。随着预训练的进行,学生模型不断提升,教师模型的影响逐渐减弱。在模态对齐阶段,方法使用文本编码器对多粒度的文本描述进行编码,并将其融合以生成最终的文本特征,随后采用对比学习方法,实现课程表示与语言模态之间的对齐。
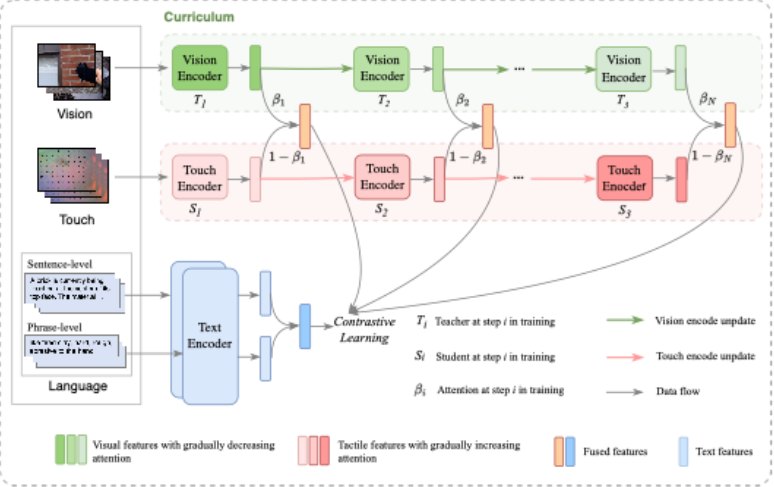
图 3 触觉表征的多模态联合学习方法TLV-Link
▍实验与分析
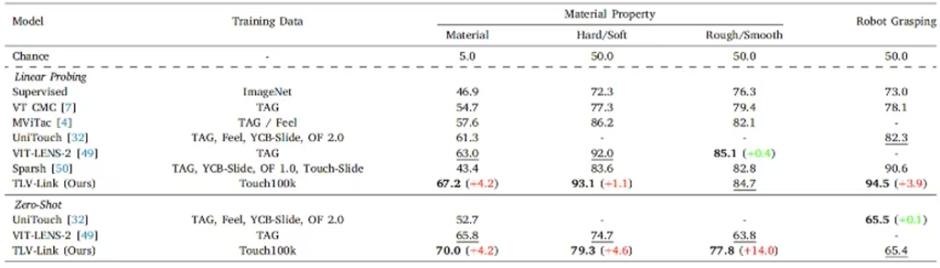
实验主要从触觉表征和零样本触觉理解两个角度展开,分别对应线性探测和零样本评估设置,在材料属性识别和机器人抓取预测两类任务上对TLV-Link进行评估。线性探测用于评估触觉编码器的性能,衡量触觉表示在特定任务中的表现;而零样本评估则更加严格,主要测试触觉编码器的理解能力和泛化能力。实验结果表明,Touch100k数据集具有良好的实用性,且TLV-Link 方法具有显著优势。
表1 在材料属性识别和机器人抓取预测任务上不同模型的性能
实验也对学习到的触觉表征进行分析,具体采用t-SNE [4]方法将学习到的触觉表示投影到二维空间中。从可视化结果可以看出,触觉表征在“硬/软”和“粗糙/光滑”分类任务中表现出色,能够有效地区分这两个子任务中的类别。对于涉及多分类以及数据分布差异显著的任务,其表示的泛化能力有所下降。这一现象揭示了当前方法在触觉多分类和机器人操作任务中的局限性,在提升鲁棒性方面仍需进一步发展。
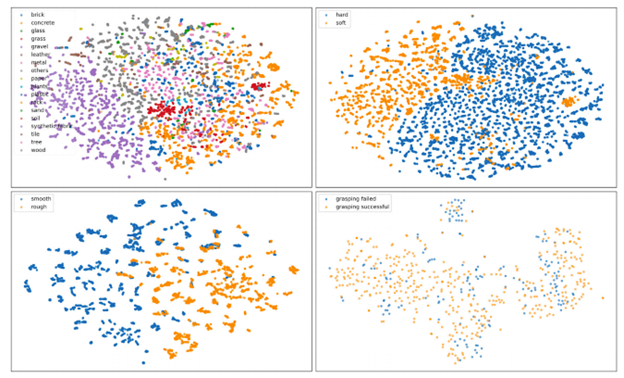
图 4 不同子任务学习到的触觉表示的 t-SNE 投影图
▍总述
本研究构建了首个包含多粒度触觉感知描述的触觉–语言–视觉配对数据集,并根据其规模命名为Touch100k 数据集,同时提出了一种基于Touch100k 的预训练方法TLV-Link,用于获取适用于 GelSight 传感器的触觉表示。该研究提升了触觉信息的建模能力,也为推动触觉表征学习在机器人感知、人机交互等领域的应用奠定了基础,展现出广泛的科学与技术影响潜力。
参考文献
[1] N. Cheng, et al., Touch100k: A large-scale touch-language-vision dataset for touch-centric multimodal representation, Information Fusion. (2025) 103305, https://doi.org/10.1016/j.inffus.2025.103305.
[2] F. Yang, et al., Touch and Go: Learning from human-collected vision and touch, Adv. Neural Inf. Process. Syst. 35 (2022) 8081–8103, URL: https://dl.acm.org/doi/abs/10.5555/3600270.3600857.
[3] Y. Li, et al., Connecting touch and vision via cross-modal prediction, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 10609–10618, http://dx.doi.org/10.1109/CVPR.2019.01086.
[4] L. Van der Maaten, G. Hinton, Visualizing data using t-SNE, J. Mach. Learn. Res. 9 (11) (2008) URL: https://www.jmlr.org/papers/v9/vandermaaten08a.html.
来源:CAAI认知系统与信息处理专委会
(文:机器人大讲堂)