

在现实世界中,数据并不总是整洁或结构化的。如果你曾经处理过图像、视频文件、音频记录或原始文本,你对此应该深有体会。这正是 vector databases(向量数据库)旨在解决的挑战。
随着人工智能(AI)和像 GPT-4 这样的大型语言模型(LLMs)的兴起,存储和搜索复杂数据的需求激增。Vector databases 应运而生,它们专为处理高维数据而设计,这是传统数据库无法企及的。
但面对众多新选项,你该如何选择适合的 vector database?本指南将介绍当前市场上十个最受欢迎的 vector databases,帮助你找到最适合项目的选择。
什么是向量数据库?
要理解 vector databases 的重要性,我们先来回顾一下。传统数据库(如 PostgreSQL)擅长存储结构化信息:行、列、清晰的条目。NoSQL 数据库(如 MongoDB)进一步扩展了功能,允许处理半结构化的 JSON 文档。
但人工智能的思维方式并非基于行和列。
机器学习模型将复杂数据分解为 vector embeddings(向量嵌入),即以数值形式捕捉数据含义或特征的表示。无论是句子、产品图像还是用户画像,都可以转化为高维向量。
Vector databases 专为高效存储和搜索这些向量而设计。它们不依赖关键词匹配,而是使用 similarity search(相似性搜索)根据含义而非仅文本来寻找最接近的匹配。
向量库与向量数据库:有什么区别?
在深入探讨工具之前,有一个重要的区别需要明确。
Vector libraries(向量库)通常是附加组件,为原本不具备向量搜索功能的系统带来这一能力。可以将其视为现有数据库或搜索引擎的插件。它们适用于静态数据集或数据变动不大的基准测试场景。
相比之下,vector databases(向量数据库)则是从头开始为这一任务设计的。它们优化了处理大量动态数据的能力,并支持快速、准确的 similarity searches(相似性搜索)。如果你需要构建动态应用,如实时产品推荐、语义搜索或基于图像的查询,专用 vector database 是更好的选择。
如果喜欢请点赞、转发、关注,感谢~
向量数据库如何悄然推动搜索的未来
Vector databases 并非只是另一个技术热词——它们正迅速成为各行业最先进应用的基础。凭借在 similarity search(相似性搜索)方面的优势,这些系统能够以传统数据库无法实现的方式识别模式、关系和匹配。我们来看看它们在现实场景中的影响。
1. 个性化购物体验
在快节奏的零售业中,个性化至关重要。Vector databases 通过理解产品、偏好和行为之间的深层关系,帮助为在线购物者提供量身定制的推荐。无论是推荐与你喜欢的夹克功能相似的款式,还是根据你的风格定制搭配,这些系统正在悄然塑造更智能、更人性化的购物体验。
2. 解锁金融洞察
金融行业依赖模式识别,而 vector databases 在此大放异彩。它们帮助分析师处理海量复杂数据,捕捉可能预示市场变化的细微趋势或异常。借助这一技术,金融机构可以更快、更自信地调整策略并做出投资决策。
3. 推进医疗精准化
医学正迈向个性化,vector databases 在这一进程中扮演关键角色。通过分析基因数据并识别海量数据集中的模式,这些系统帮助医生和研究人员为患者量身定制治疗方案。这是迈向更精准、有效和数据驱动的医疗的一步。
4. 驱动更智能的 NLP 应用
虚拟助手和聊天机器人越来越自然,vector databases 是背后的秘密武器之一。通过将文本转化为 vectors(向量)——本质上是含义的数值表示——这些系统帮助 AI 更好地理解和回应人类语言。像 Talkmap 这样的公司利用这一技术实现实时语言理解,带来更流畅的客户交互和更智能的数字助手。
5. 大规模解读视觉数据
从分析医学扫描到审查交通录像,准确比较图像往往至关重要。Vector databases 通过聚焦图像的意义特征(忽略噪声和不一致性)简化了这一过程。在公共安全和交通监控中,这意味着更快的分析和更好的决策,而无需让人类分析师不堪重负。
6. 在异常成为灾难前捕获
在网络安全和金融领域,识别异常与发现规律同样重要。Vector databases 擅长实时检测异常,无论是可能表明欺诈的异常消费行为,还是系统日志中暗示入侵的异常模式。它们的速度和准确性可能是预防与补救的区别。
什么让向量数据库真正高效?
Vector databases 面向未来构建。与依赖标签和标记的传统系统不同,这些平台能够直接利用原始内容理解非结构化数据——图像、视频、文档。以下是优秀 vector database 的关键特点:
1. 无缝扩展性
处理几千个数据点是一回事,但当应用扩展到数十亿数据点时会怎样?可靠的 vector database 必须能够跨节点轻松扩展并保持响应能力。无论是增加插入量还是查询负载,它都应适应不同工作负载和硬件,而不失效率。
2. 支持多租户和隐私
现代 vector database 不仅服务单一用户,而是同时安全地支持多个用户。优秀系统设计了隔离集合,确保用户数据隐私,除非明确共享。这在保护敏感信息的同时,维持高效的多用户操作,是企业解决方案的必备条件。
3. 开发者友好的 API 和 SDK
最佳工具应与现有技术栈无缝协作。因此,像 Pinecone 这样的领先平台提供了 Python、JavaScript、Go 等语言的 SDK。通过全面的 API 集,开发者可以轻松集成、管理和查询数据,融入现有工作流。
4. 简单易用的界面
强大技术不必复杂。优秀的 vector database 应提供直观的用户界面,帮助用户可视化、探索和管理数据,而无需深入研究复杂文档。简单性不应以控制力为代价。
现在我们已经了解了基础知识,下面介绍一些最优秀的 vector databases。它们未按排名顺序——每一种都带来独特价值。
1. Pinecone
🌐 Pinecone 网站[1] | 🔗 Pinecone GitHub[2] 836 ⭐
Pinecone 是一个完全托管的 vector database,专为处理高维数据的复杂性而设计。它是机器学习工程师和数据团队的首选,用于构建大规模 AI 应用的基础设施,追求快速、可靠的性能。
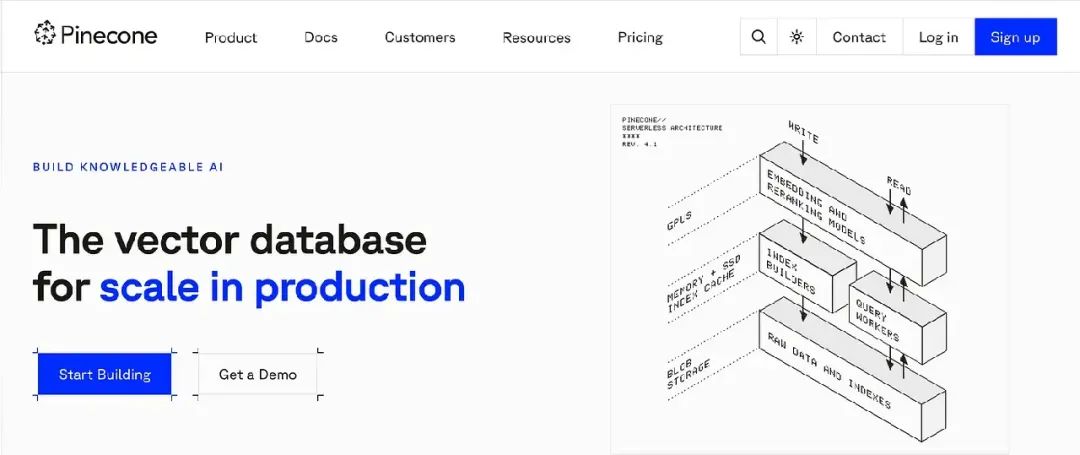
Pinecone 的独特之处在于其对速度和简便性的专注。无论是处理数百万个 embeddings(嵌入),还是需要极快的 similarity searches(相似性搜索),Pinecone 都能提供卓越性能,而无需通常的运营开销。
突出特点:
•完全托管,无需担心基础设施•随数据增长轻松扩展•支持实时数据摄取,适应动态工作负载•低延迟搜索,优化高维向量•与现代工具如 LangChain 集成良好,支持 LLM 应用
如果你正在构建生产级 AI 应用,需要一个“即插即用”的 vector store(向量存储),Pinecone 值得认真考虑。
2. Milvus
🌐 Milvus 网站[3] | 🔗 Milvus GitHub[4] 32.5k ⭐
Milvus 是一个强大的开源 vector database,专为处理海量数据集的快速、可扩展 similarity search(相似性搜索)而构建。无论你处理的是图像、自然语言还是科学数据,Milvus 都能简化大规模非结构化数据的搜索和管理。
Milvus 的吸引力在于其灵活性——它无缝适应不同环境,支持从 AI 驱动的图像搜索到分子结构匹配的多种用例。
开发者喜爱的原因:
•能在毫秒内搜索万亿向量•简化非结构化数据处理•为企业级工作负载提供无缝扩展•支持 hybrid search(混合搜索,结合向量和标量查询)•拥有活跃且不断增长的开源社区
如果你构建的应用依赖大规模向量搜索,Milvus 是最经受考验且社区支持最广泛的选项之一。
3. MongoDB Atlas
🌐 MongoDB Atlas 网站[5] | 🔗 GitHub[6] 27.1k ⭐
MongoDB Atlas 是开发者广泛使用的托管数据平台之一,现通过 Atlas Vector Search 进入向量搜索领域。基于核心 MongoDB 引擎,它提供了一种无缝方式,在同一平台上运行事务性和向量搜索工作负载。向量索引与现有数据紧密集成,但可独立扩展,兼顾集成性和灵活性。
为何是明智选择:
•结合传统数据库功能与内置向量搜索•支持数据库和向量索引独立扩展以提升性能•支持高达 16 MB 的文档,适合丰富数据结构•提供高可用性、事务完整性和强大的数据备份•强大的数据安全性和多层加密•支持 hybrid search(混合搜索),融合关键词和语义相关性
对于已使用 MongoDB 的团队,Atlas Vector Search 提供了一种强大的方式,无需更换数据栈即可扩展到 AI 和语义搜索领域。
4. Chroma DB
🌐 Chroma 网站[7] | 开源:是 (GitHub[8]) | GitHub 星标:19.9k ⭐
Chroma DB 是一个专为 AI 应用(尤其是大型语言模型 LLMs)设计的开源 vector database。它旨在让事实、文档和知识轻松被模型访问,帮助减少 hallucinations(幻觉)并使 retrieval-augmented generation(RAG,检索增强生成)更有效。
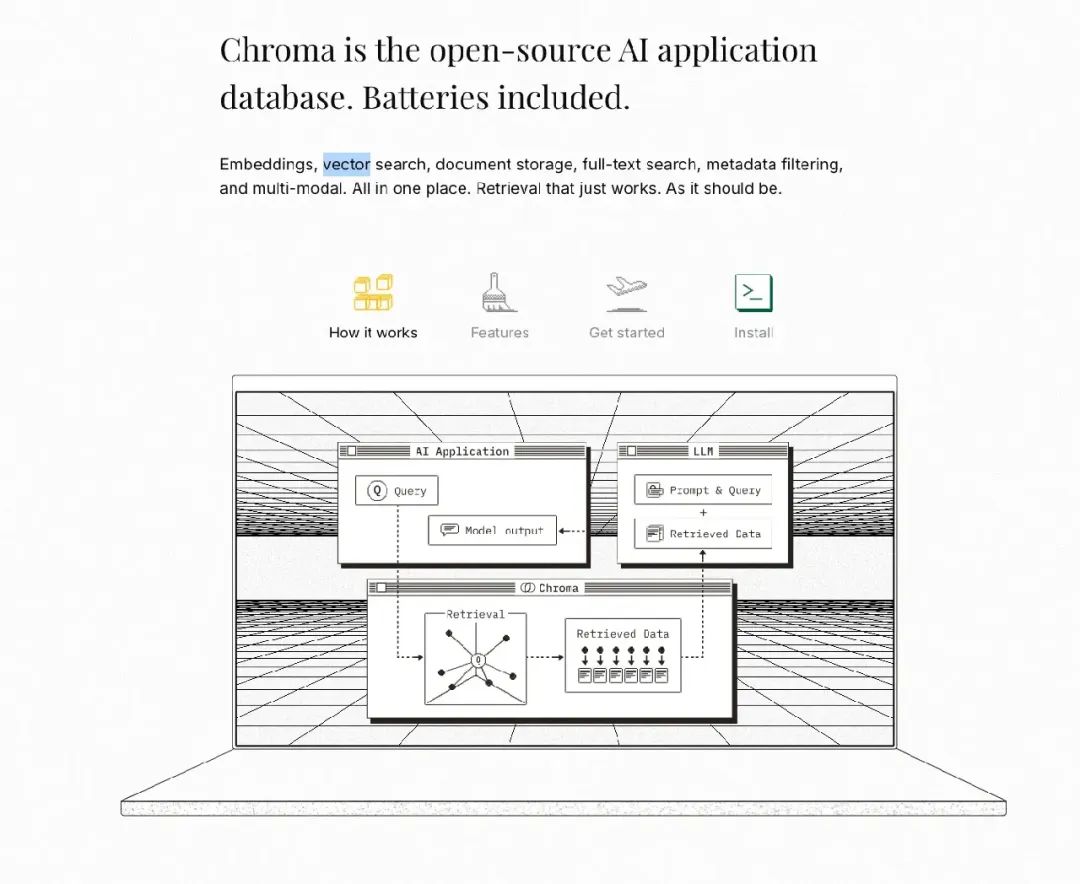
Chroma 的核心理念是实现开发者梦想中的“为我的数据打造 ChatGPT”。它作为基于嵌入的文档检索的支柱,简化了将现实数据接入 AI 工作流的过程。此外,它“开箱即用”,包含嵌入、存储和搜索数据所需的一切。
开发者为何兴奋:
•丰富的功能集:高级查询、过滤、密度估计等•轻松集成 LangChain(Python 和 JavaScript)、LlamaIndex 等框架•同一 Python API 从本地笔记本扩展到生产集群•专为现代 AI/LLM 管道设计
如果你正在构建 LLM 驱动的应用并需要快速、可靠的嵌入知识访问,Chroma DB 是最开发者友好的工具之一。
5. Qdrant
🌐 Qdrant 网站[9] | 开源:是 (GitHub[10]) | GitHub 星标:23.6k ⭐
Qdrant 是一个开源 vector database 和搜索引擎,注重速度、灵活性和生产级可靠性。凭借开发者友好的 API 和强大的过滤能力,Qdrant 非常适合语义搜索、分面导航和 AI 驱动的推荐系统等用例。

Qdrant 的独特之处在于其基于 payload(负载)的架构,允许在向量数据旁存储和过滤额外元数据,使搜索更具上下文性和准确性。它还设计为独立运行,无需依赖外部数据库或编排工具,简化了部署。
突出特点:
•基于 payload 的存储,支持丰富的元数据和细粒度过滤•处理多种数据类型和复杂查询条件•智能缓存加速重复查询•Write-Ahead logging(预写日志)确保意外关机时的安全性•完全独立,无需额外数据库层或编排工具
如果你需要一个易于集成且功能强大的生产级向量引擎,Qdrant 值得列入你的候选名单。
6. Elasticsearch
🌐 Elasticsearch 网站[11] | 开源:是 (GitHub[12]) | GitHub 星标:72.7k ⭐
Elasticsearch 是一个功能强大的开源搜索和分析引擎,全球开发者信赖它处理从全文搜索到日志分析的各种任务。它以速度、规模和灵活性著称,能够处理结构化、半结构化和非结构化数据。
凭借分布式架构和高可用性特性,Elasticsearch 便于部署健壮的大规模系统。无论是构建实时搜索功能、运行复杂分析,还是管理海量数据流,它都能以最小的麻烦提供快速结果。
团队选择它的原因:
•内置集群和自动故障转移,确保高可用性•水平扩展,轻松处理不断增长的数据量•支持跨集群复制和多数据中心设置•分布式设计,确保高压下的正常运行和可靠性
如果你的项目需要快速、灵活的大规模搜索和分析,Elasticsearch 是一个成熟且经受考验的解决方案。
7. ScaNN
🌐 ScaNN 网站[13] | 开源:是 (GitHub[14]) | GitHub 星标:35.6k ⭐
ScaNN(Scalable Nearest Neighbors,可扩展最近邻)是谷歌开源的高性能向量 similarity search(相似性搜索)解决方案。设计时注重速度和精度,ScaNN 引入了先进的压缩技术,在不牺牲性能的情况下提升准确性,是大规模搜索系统的首选。
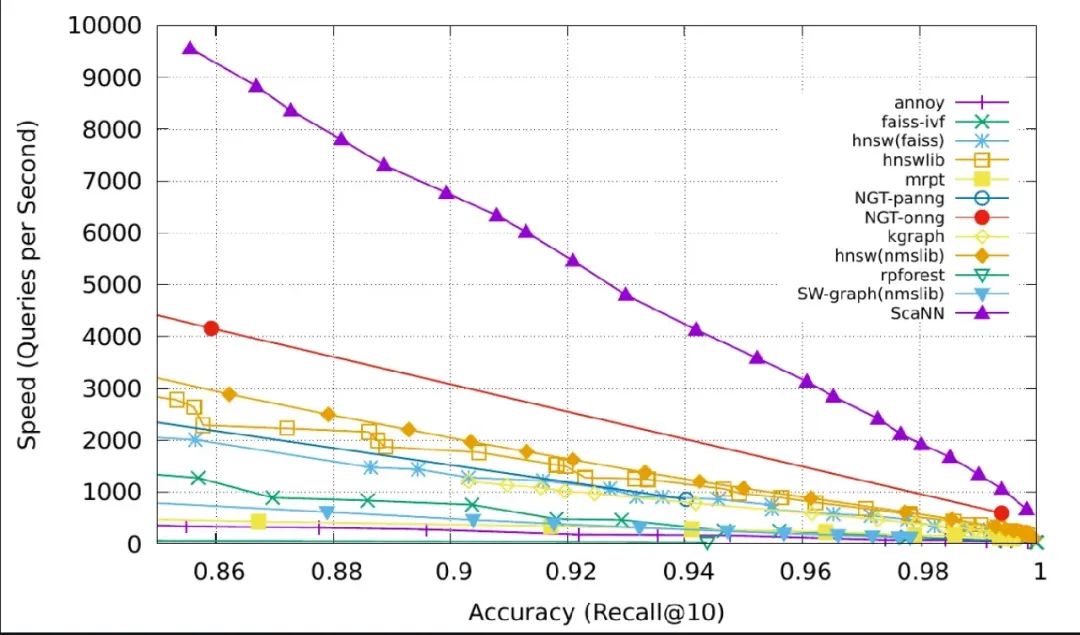
它特别适合 Maximum Inner Product Search(MIPS,最大内积搜索),同时支持其他距离度量(如 Euclidean distance,欧几里得距离),使其适用于广泛的 AI 和机器学习应用。
ScaNN 的突出特点:
•优化快速且准确的 similarity search(相似性搜索)•高级压缩方法提升大规模精度•非常适合 Maximum Inner Product Search 用例•支持多种距离函数,包括 Euclidean distance•由 Google Research 开发和维护
如果你在构建大规模推荐引擎或基于相似性的 AI 系统,ScaNN 提供了研究支持的生产级基础。
8. Faiss
🌐 Faiss 网站[15] | 开源:是 (GitHub[16]) | GitHub 星标:34.9k ⭐
Faiss 由 Facebook AI Research 开发,是一个高效的 similarity search(相似性搜索)和密集向量聚类库。它广泛应用于机器学习管道,尤其是在推荐引擎、图像识别或自然语言处理等需要速度和规模的场景。
Faiss 的多功能性在于其支持多种距离度量、基于磁盘的索引和批量处理。无论是处理几千个向量还是数百万个向量,Faiss 都能以优化的速度和准确性应对。
研究人员和工程师喜爱的原因:
•单次查询高效返回多个最近邻•支持批量处理大量向量•提供多种距离计算灵活性(如 L2、内积)•索引可存储在磁盘上,实现持久性和可扩展性
如果你需要一个轻量级、经受考验的快速向量搜索库,Faiss 是该领域最受信赖和广泛采用的选项之一。
9. ClickHouse
🌐 ClickHouse 网站[17] | 开源:是 (GitHub[18]) | GitHub 星标:40.7k ⭐
ClickHouse 是一个高性能、面向列的数据库,专为实时分析设计。凭借极快的查询执行速度,ClickHouse 通过强大的数据压缩和充分利用多核处理,高效处理海量数据集。
无论是运行复杂分析查询还是持续摄取新数据,ClickHouse 都能提供低延迟性能,并支持丰富的基于 SQL 的操作,成为需要无妥协速度的数据团队的首选。
ClickHouse 的突出特点:
•高级数据压缩减少存储需求并加速读取•超快查询性能,低延迟•优化用于多核 CPU 和分布式服务器环境•全面支持强大的 SQL 查询•通过高效索引处理持续数据摄取
如果你的项目需要对海量数据进行实时洞察,ClickHouse 是最可靠的生产级工具之一。
10. OpenSearch
🌐 OpenSearch 网站[19] | 开源:是 (GitHub[20]) | GitHub 星标:7.9k
OpenSearch 是一个灵活的开源搜索和分析套件,现包括强大的 vector search(向量搜索)功能,结合传统全文和日志搜索。它旨在将搜索、分析和 AI 驱动的智能整合到一个统一平台,适合需要词汇和语义理解的现代应用。
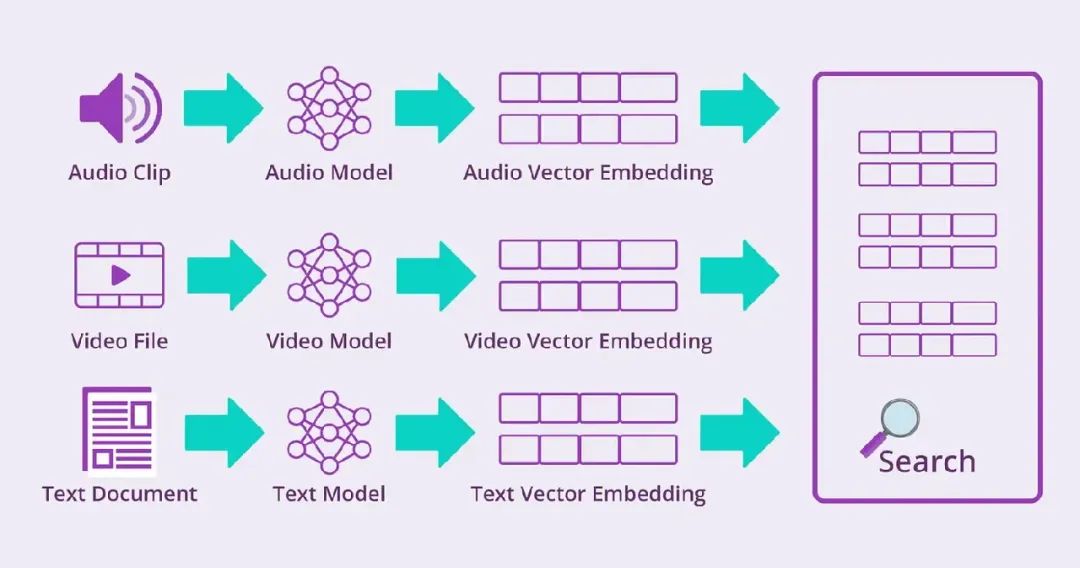
其向量功能支持从多模态和语义搜索到 AI 代理和生成应用的各种场景。使用 OpenSearch,你可以为产品、用户或特定领域数据创建有意义的 embeddings(嵌入),并利用 similarity search(相似性搜索)提升性能和数据质量。
OpenSearch 的优势:
•内置 vector search(向量搜索),支持语义、混合和 AI 驱动用例•支持多模态、视觉和生成 AI 集成•允许为用户、内容或产品创建自定义 embeddings(嵌入)•适用于相似性匹配和数据验证任务•完全开源,采用 Apache 2.0 许可证
如果你需要一个结合传统和 AI 增强搜索的成熟、可扩展平台,OpenSearch 提供坚实的基础。
总结
Vector databases 正迅速成为现代数据科学和 AI 工作流的基础。随着管理与搜索高维数据的需求增长,这些工具以速度、灵活性和精度应对新挑战。
本文探讨了 2025 年最具前景的 vector databases,每一种都有其独特优势。无论你是在构建 LLM 驱动的应用、实时推荐系统还是高级分析平台,这里都有一个解决方案帮助你自信扩展。
随着该领域的持续进步,关注这些技术及其实际应用将是保持领先的关键。
如果喜欢请点赞、转发、关注,感谢~
References
[1] Pinecone 网站:https://www.pinecone.io/[2]Pinecone GitHub:https://github.com/pinecone-io[3]Milvus 网站:https://milvus.io/[4]Milvus GitHub:https://github.com/milvus-io/milvus[5]MongoDB Atlas 网站:https://www.mongodb.com/atlas[6]GitHub:https://github.com/mongodb[7]Chroma 网站:https://www.trychroma.com/[8]GitHub:https://github.com/chroma-core/chroma[9]Qdrant 网站:https://qdrant.tech/[10]GitHub:https://github.com/qdrant/qdrant[11]Elasticsearch 网站:https://www.elastic.co/elasticsearch/[12]GitHub:https://github.com/elastic/elasticsearch[13]ScaNN 网站:https://github.com/google-research/scann[14]GitHub:https://github.com/google-research/scann[15]Faiss 网站:https://github.com/facebookresearch/faiss[16]GitHub:https://github.com/facebookresearch/faiss[17]ClickHouse 网站:https://clickhouse.com/[18]GitHub:https://github.com/ClickHouse/ClickHouse[19]OpenSearch 网站:https://opensearch.org/[20]GitHub: https://github.com/opensearch-project/OpenSearch
(文:PyTorch研习社)